-
Kafka与RabbitMQ:架构、性能和用例

如果您正在考虑Kafka还是RabbitMQ最适合您的用例,请继续阅读以了解这些工具背后的不同体系结构和方法,它们如何以不同方式处理消息传递,以及它们的性能优缺点。我们将介绍每种工具的最佳用例,以及何时更适合依赖完整的端到端流处理解决方案。
什么是ApacheKafka和 RabbitMQ?
apachekafka和RabbitMQ是两个开源的、商业支持的发布/子系统,很容易被企业采用。RabbitMQ是2007年发布的旧工具,是消息传递和SOA系统中的主要组件。今天,它也被用于流式处理用例。Kafka是一个更新的工具,发布于2011年,它从一开始就是为流媒体场景而构建的。
RabbitMQ是一个通用的消息代理,支持包括MQTT、AMQP和STOMP在内的协议。它可以处理高吞吐量的用例,例如在线支付处理。它可以处理后台作业或充当微服务之间的消息代理。
Kafka是为高入口数据重放和流而开发的消息总线。Kafka是一个持久的消息代理,它使应用程序能够处理、持久化和重新处理流数据。Kafka有一种简单的路由方法,它使用路由密钥将消息发送到主题。
Kafka vs RabbitMQ——架构差异
RabbitMQ体系结构
- 通用消息代理使用各种请求/应答、点对点和发布子通信模式。
- 智能代理/哑消费者模型向消费者提供一致的消息传递,速度与代理监视消费者状态的速度大致相同。
- 成熟的平台,支持良好,可用于Java、客户端库、.NET、Ruby、Node.js. 提供几十个插件。
- 通信可以是同步的,也可以是异步的。
- 部署场景提供分布式部署场景。
- 多节点集群到集群的联合不依赖于外部服务,但是,特定的集群形成插件可以使用DNS、api、Consul等。
Apache-Kafka体系结构
- 高容量发布订阅消息和流平台持久、快速和可扩展。
- 持久的消息存储类似于日志,在服务器集群中运行,它将记录流保存在主题(类别)中。
- 由值、键和时间戳组成的消息。
- Dumb broker/smart consumer模型不尝试跟踪消费者读取的消息,只保留未读消息。卡夫卡将所有信息保留一段时间。
- 在某些情况下需要运行外部服务。
Pull vs Push
Apache-Kafka:基于Pull拉的方法
Kafka使用拉模型。使用者从特定偏移量请求成批消息。Kafka允许长池,这可以防止在没有消息经过偏移量时出现紧循环。
对于Kafka来说,pull模型是合乎逻辑的,因为它是分区的。Kafka在没有争用者的分区中提供消息顺序。这允许用户利用消息的批处理来实现有效的消息传递和更高的吞吐量。
RabbitMQ:基于Push推的方法
RabbitMQ使用一个推送模型,并通过在使用者上定义的预取限制来阻止压倒性的使用者。这可用于低延迟消息传递。
推送模型的目的是分别快速地分发消息,以确保工作均匀地并行化,并且消息的处理顺序大致与它们到达队列的顺序一致。
他们如何处理消息?
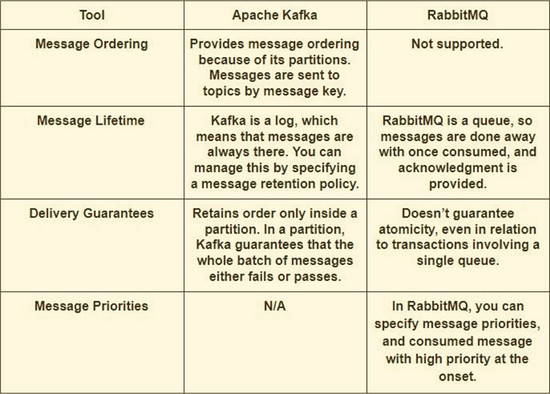
Kafka vs RabbitMQ性能
Apache Kafka:
Kafka提供了比RabbitMQ等消息代理更高的性能。它使用顺序磁盘I/O来提高性能,使其成为实现队列的合适选项。它可以用有限的资源实现高吞吐量(每秒数百万条消息),这是大数据用例的必要条件。
RabbitMQ:
RabbitMQ还可以每秒处理一百万条消息,但需要更多的资源(大约30个节点)。您可以将RabbitMQ用于许多与Kafka相同的用例,但是您需要将它与其他工具(如apachecassandra)结合使用。
最好的用例是什么?
ApacheKafka用例
apachekafka提供了代理本身,并且是针对流处理场景设计的。最近,它添加了Kafka Streams,这是一个用于构建应用程序和微服务的客户端库。apachekafka支持度量、活动跟踪、日志聚合、流处理、提交日志和事件源等用例。
以下消息传递场景特别适合Kafka:
- 具有复杂路由的流,吞吐量为100K/sec或更高,具有“至少一次”分区排序
- 需要流历史的应用程序,以“至少一次”分区顺序交付。客户端可以看到事件流的“重播”。
- 事件源,将系统的更改建模为一系列事件。
- 多级管道中的流处理数据。管道生成实时数据流的图形。
RabbitMQ用例
RabbitMQ可以在web服务器需要快速响应请求时使用。这样就不需要在用户等待结果时执行资源密集型活动。RabbitMQ还用于将消息传递给不同的接收者以供使用,或者在高负载(20K+消息/秒)下在工作者之间共享负载。
RabbitMQ可用于的场景:
- 需要支持遗留协议的应用程序,如STOMP、MQTT、AMQP、0-9-1。
- 对每个消息的一致性/保证集进行精确控制
- 到消费者的复杂路由
- 需要各种发布/订阅、点对点请求/回复消息传递功能的应用程序。
总结
本指南介绍了apachekafka和RabbitMQ之间的主要区别和相似之处。两者都可以每秒消耗数百万条消息,尽管它们的体系结构不同,而且在某些环境中性能更好。RabbitMQ几乎在内存中控制其消息,使用大集群(30+个节点)。相比之下,Kafka利用了顺序磁盘I/O操作,因此需要更少的硬件。
-
相关阅读:
Java之JS基础语法 ①(前端)
ARouter遇到的坑记录 There is no route match the path
WRF后处理/Python处理nc数据与可视化/极坐标网格绘制(Cartopy、netcdf4)——以北极雪水当量数据为例
剑指offer 52 两个链表的第一个公共结点
LibTorch之网络模型构建
【Golang】数组 && 切片
一文学会如何使用建造者模式
Android 性能优化—— 启动优化提升60%
Excel实战-帮业务人员做道Excel题
TCP三次握手及其相关问题
- 原文地址:https://blog.csdn.net/JavaShark/article/details/125597172