-
【Golang】数组 && 切片
【Golang】数组 && 切片
1、数组
-
基本概念
数组是一个由固定长度的特定类型元素组成的序列,一个数组可以由零个或多个元素组成
因为数组的长度是固定的,所以在Go语言中很少直接使用数组
go语言中的数组是 值类型,赋值和传参会复制整个数组,因此改变副本的值,不会改变本身的值。 -
//1、默认数组中的值是类型的默认值 var array [3]int //2、使用 {}将数组中的每个元素初始化 var array [3]int = [3]int {1, 2, 3} //or array := [3]int {1, 2, 3} //推荐这种写法,书写高效方便 //3、初始化数组中指定下标的数据 array := [3]int {1:100} //数组内容是[0,100,0] //4、根据{}里面的元素数量推断数组大小 array := [...]int {1, 2, 3, 4}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
-
数组使用
var array := [10]int {8:100, 1:10} //1、通过下标访问 fmt.Printf("array[0] = %d", array[0])//0 fmt.Printf("array[1] = %d", array[1])//10 //2、简单for循环 for i := 0; i < len(array); i++ { fmt.Printf("array[%d] = %d \n", i, array[i]) } //3、for range 遍历 for k,v := range array { fmt.Printf("array[%d] = %d \n", k, v) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
注意:数组的长度是初始化的时候(编译时期)就确定好了,整个生命周期内不可改变
-
数组比较
只有两个数组类型相同(包括数组的长度,数组中元素的类型>)的情况下,我们才可以直接通过较运算符(
==和!=)来判断两个数组是否相等只有当两个数组的所有元素都是相等的时候数组才是相等的
不能比较两个类型不同的数组,否则程序将无法完成编译
a := [2]int{1, 2} b := [...]int{1, 2} c := [2]int{1, 3} fmt.Println(a == b, a == c, b == c) // "true false false" d := [3]int{1, 2} fmt.Println(a == d) // 编译错误:无法比较 [2]int == [3]int- 1
- 2
- 3
- 4
- 5
- 6
2、多维数组
-
概念理解
多维数组本质上还是一个一维数组,只不过这个一维数组中的每个元素也是一个数组
N维数组本质上是一个一维数组,这个一维数组的每个元素是N-1维数组,以此类推,直到访问到最底一层,能够直接处理数组中的元素
-
以二维数组为例总结使用
二维数组是最简单的多维数组,二维数组本质上是由多个一维数组组成的
/ 声明一个二维整型数组,两个维度的长度分别是 4 和 2 var array [4][2]int // 使用数组字面量来声明并初始化一个二维整型数组 array = [4][2]int{{10, 11}, {20, 21}, {30, 31}, {40, 41}} // 声明并初始化数组中索引为 1 和 3 的元素 array = [4][2]int{1: {20, 21}, 3: {40, 41}} // 声明并初始化数组中指定的元素 array = [4][2]int{1: {0: 20}, 3: {1: 41}}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
二维数组的使用
array := [2][2]int {{10, 30}, {-1. 90}} //1、使用下标访问 fmt.Println(array[1][0]) // -1 //2、使用 for range 遍历 for index,value := range array{ for k, v := range value { fmt.Printf("array[%d][%d] = %d \n", index, k, v) } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
只要类型一致,就可以将多维数组互相赋值
如下所示,多维数组的类型包括每一维度的长度以及存储在元素中数据的类型
// 声明两个二维整型数组 [2]int [2]int var array1 [2][2]int var array2 [2][2]int // 为array2的每个元素赋值 array2[0][0] = 10 array2[0][1] = 20 array2[1][0] = 30 array2[1][1] = 40 // 将 array2 的值复制给 array1 array1 = array2- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
数组中每个元素都是一个值,所以可以独立复制某个维度
// 将 array1 的索引为 1 的维度复制到一个同类型的新数组里 var array3 [2]int = array1[1] // 将数组中指定的整型值复制到新的整型变量里 var value int = array1[1][0]- 1
- 2
- 3
- 4
3、切片
-
基本概念
切片(Slice)与数组一样,也是可以容纳若干类型相同的元素的容器与数组不同的是,无法通过切片类型来确定其值的长度
每个切片值都会将数组作为其底层数据结构,我们也把这样的数组称为
切片的底层数组切片(slice)是对数组的一个连续片段的引用,所以切片是一个**引用类型**这个片段可以是
整个数组,也可以是由起始和终止索引标识的一些项的子集,需要注意的是,终止索引标识的项不包括在切片内(左闭右开的区间)Go语言中切片的内部结构包含
地址、大小和容量,切片一般用于快速地操作一块数据集合
可以通过内置函数len()来获取切片的有效元素个数, 通过cap()来获取切片的容量 -
切片存在的形式
从连续内存区域生成切片
var a = [3]int{1, 2, 3} //a[1:2] 生成了一个新的切片 slice := a[1:2] fmt.Println(a, slice) // [1, 2, 3] [2]- 1
- 2
- 3
- 4
注意事项:
从数组或切片生成新的切片拥有如下特性:
- 取出的元素数量为:结束位置 - 开始位置;
- 取出元素不包含结束位置对应的索引;
- 当缺省开始位置时,表示从连续区域开头到结束位置
(a[:2]); - 当缺省结束位置时,表示从开始位置到整个连续区域末尾
(a[0:]); - 两者同时缺省时,与数组本身等效
(a[:]); - 两者同时为 0 时,等效于空切片,一般用于切片复位
(a[0:0]);
直接申明新的切片
/*语法结构: name 表示切片的变量名,Type 表示切片对应的元素类型。 var name []Type */ // 声明字符串切片 var strList []string // 声明整型切片 var numList []int // 声明一个空切片 var numListEmpty = []int{} // 输出3个切片 fmt.Println(strList, numList, numListEmpty) // 输出3个切片大小 fmt.Println(len(strList), len(numList), len(numListEmpty)) // 切片判定空的结果 fmt.Println(strList == nil) fmt.Println(numList == nil) fmt.Println(numListEmpty == nil)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
切片是动态结构,只能与 nil 判定相等,不能互相判定相等。声明新的切片后,可以使用 append() 函数向切片中添加元素。
var strList []string // 追加一个元素 strList = append(strList,"golang") fmt.Println(strList)- 1
- 2
- 3
- 4
使用make函数构造切片
/* 语法结构 make([]Type, size, cap) Type 切片的元素类型 size 为这个类型分配多少个元素 cap 预分配的元素数量,这个值设定后不影响 size, 只是能提前分配空间,降低多次分配空间造成的性能问题。 */ a := make([]int, 2) b := make([]int, 2, 10) fmt.Println(a, b) //容量不会影响当前的元素个数,因此 a 和 b 取 len 都是 2 //但如果我们给a 追加一个 a的长度就会变为3 fmt.Println(len(a), len(b))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
注意事项:
使用 make() 函数生成的切片一定发生了内存分配操作
但给定开始与结束位置(包括切片复位)的切片只是将新的切片结构指向已经分配好的内存区域,设定开始与结束位置,不会发生内存分配操作
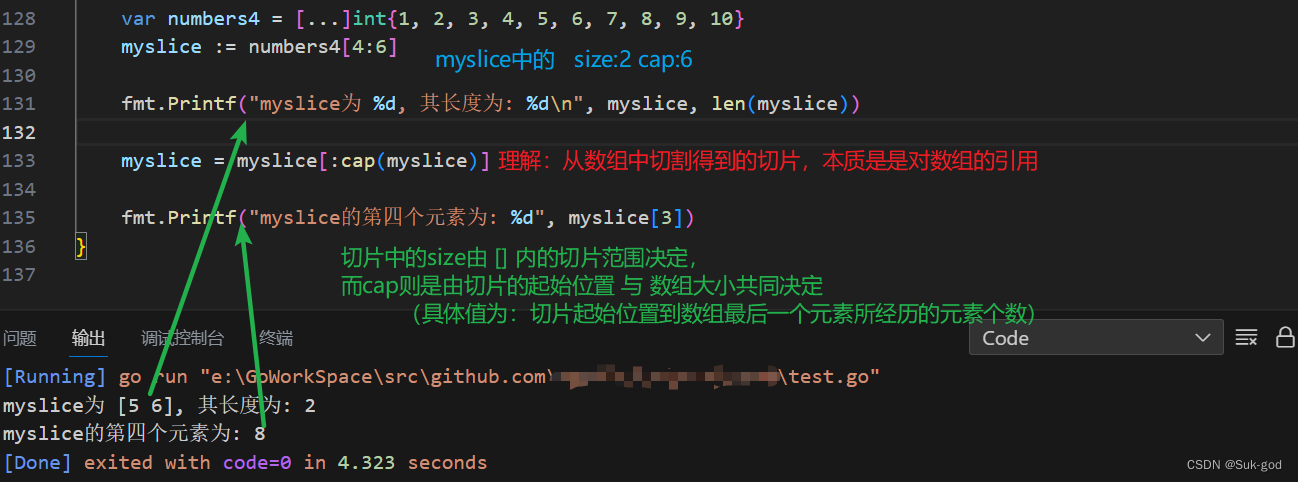
//小试牛刀 //问:下面的代码有什么问题吗?如果没有问题,请回答输出的结果是什么?? var numbers4 = [...]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10} myslice := numbers4[4:6] fmt.Printf("myslice为 %d, 其长度为: %d\n", myslice, len(myslice)) myslice = myslice[:cap(myslice)] fmt.Printf("myslice的第四个元素为: %d", myslice[3])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4、切片的本质
切片的本质就是对底层数组的封装。它包含了三个信息:底层数组的指针、切片的长度(len)、切片的容量(cap)
举个例子,现在有一个数组a := [8]int{0, 1, 2, 3, 4, 5, 6, 7},切片s1 := a[:5],相应示意图如下:

判断一个切面是否为空 始终使用len(xx) == 0来判断,不能使用 xx == nil 判断切片不能直接比较
- 切片之间是不能比较的,我们不能使用==操作符来判断两个切片是否含有全部相等元素。
- 切片唯一合法的比较操作是和nil比较。
- 一个nil值的切片并没有底层数组,一个nil值的切片的长度和容量都是0。但是我们不能说一个长度和容量都是0的切片一定是nil
5、切片的复制
Go语言的内置函数 copy() 可以将一个数组切片复制到另一个数组切片中,如果加入的两个数组切片不一样大,就会按照其中较小的那个数组切片的元素个数进行复制。
/* 语法说明 copy( destSlice, srcSlice []T) int srcSlice 数据来源切片 destSlice 复制的目标(也就是将 srcSlice 复制到 destSlice) 目标切片必须分配过空间且足够承载复制的元素个数,并且来源和目标的类型必须一致, 返回值 实际发生复制的元素个数 */ slice1 := []int{1, 2, 3, 4, 5} slice2 := []int{5, 4, 3} copy(slice2, slice1) // 只会复制slice1的前3个元素到slice2中 copy(slice1, slice2) // 复制slice2的3个元素到slice1的前3个位置- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
切片的引用和复制操作对切片元素的影响
重点理解:copy底层是新开辟了空间,二者之间是独立的, 引用是公用同一块空间,一方修改会影响另一方
package main import "fmt" func main() { // 设置元素数量为1000 const elementCount = 1000 srcData := make([]int, elementCount) for i := 0; i < elementCount; i++ { srcData[i] = i } // 引用切片数据 切片不会因为等号操作进行元素的复制 refData := srcData copyData := make([]int, elementCount) // 将数据复制到新的切片空间中 copy(copyData, srcData) srcData[0] = 999 // 打印引用切片的第一个元素 引用数据的第一个元素将会发生变化 fmt.Println(refData[0])//999 // 打印复制切片的第一个和最后一个元素 由于数据是复制的,因此不会发生变化。 fmt.Println(copyData[0], copyData[elementCount-1]) copy(copyData, srcData[4:6]) for i := 0; i < 5; i++ { fmt.Printf("%d ", copyData[i])// [5, 6, 2, 3, 4] } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
6、map
-
基本概念
map 是一种无序的
键值对的集合,其内部是使用散列表Hash实现的map 最重要的一点是通过 key 来快速检索数据,key 类似于索引,指向数据的值
map 是一种集合,所以我们可以像迭代数组和切片那样迭代它。不过,map 是无序的,我们无法决定它的返回顺序
map 是引用类型,必须初始化后才能使用
-
map的定义方式
/*[keytype] 和 valuetype 之间允许有空格。 var mapname map[keytype]valuetype mapname 为 map 的变量名 keytype 为键类型 valuetype 是键对应的值类型 在声明的时候不需要知道 map 的长度,因为 map 是可以动态增长的 未初始化的 map 的值是 nil,使用函数 len() 可以获取 map 中 键值对的数目 */ //另一种定义方式 make(map[keytype]valuetype) make(map[keytype]valuetype, cap)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
map 可以根据新增的 key-value 动态的伸缩,因此它不存在固定长度或者最大限制,但是也可以选择标明 map 的初始容量 capacity
当 map 增长到容量上限的时候,如果再增加新的 key-value,map 的大小会自动加 1,所以出于性能的考虑,对于大的 map 或者会快速扩张的 map,即使只是大概知道容量,也最好先标明
既然一个 key 只能对应一个 value,而 value 又是一个原始类型,那么如果一个 key 要对应多个值怎么办?
答案是:使用
切片例如,当我们要处理 unix 机器上的所有进程,以父进程ID作为 key,所有的子进程(以所有子进程的 pid 组成的切片)作为 value。
通过将 value 定义为 []int 类型或者其他类型的切片,就可以优雅的解决这个问题,示例代码如下所示
mp1 := make(map[int][]int) mp2 := make(map[int]*[]int)- 1
- 2
-
map的使用
遍历map------使用for range的方式
scene := make(map[string]int) scene["cat"] = 66 scene["dog"] = 4 scene["pig"] = 960 for k, v := range scene { fmt.Println(k, v) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
删除map中的某个元素
使用 delete(map, 键)
scene := make(map[string]int) // 准备map数据 scene["cat"] = 66 scene["dog"] = 4 scene["pig"] = 960 delete(scene, "dog") for k, v := range scene { fmt.Println(k, v) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
判断map中的某个key是否存在
v, ok := map[key]
如果key存在ok为true,v为对应的值;不存在ok为false,v为值类型的零值-
线程安全的map
上面介绍的map不是线程安全的,并发情况下读写 map 时会出现问题,代码如下:
// 创建一个int到int的映射 m := make(map[int]int) // 开启一段并发代码 go func() { // 不停地对map进行写入 for { m[1] = 1 } }() // 开启一段并发代码 go func() { // 不停地对map进行读取 for { _ = m[1] } }() // 无限循环, 让并发程序在后台执行 for { }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
运行代码会报错:fatal error: concurrent map read and map write
错误信息显示,并发的 map 读和 map 写,也就是说使用了两个并发函数不断地对 map 进行读和写而发生了竞态问题,map 内部会对这种并发操作进行检查并提前发现
需要并发读写时,一般的做法是加锁,但这样性能并不高,Go语言在 1.9 版本中提供了一种效率较高的并发安全的
sync.Map,sync.Map 和 map 不同,不是以语言原生形态提供,而是在 sync 包下的特殊结构sync.Map 有以下特性:
- 无须初始化,直接声明即可。
- sync.Map 不能使用 map 的方式进行取值和设置等操作,而是使用 sync.Map 的方法进行调用,Store 表示存储,Load 表示获取,Delete 表示删除。
- 使用 Range 配合一个回调函数进行遍历操作,通过回调函数返回内部遍历出来的值,Range 参数中回调函数的返回值在需要继续迭代遍历时,返回 true,终止迭代遍历时,返回 false。
使用示例如下:
package main import ( "fmt" "sync" ) func main() { //sync.Map 不能使用 make 创建 var scene sync.Map // 将键值对保存到sync.Map //sync.Map 将键和值以 interface{} 类型进行保存。 scene.Store("greece", 97) scene.Store("london", 100) scene.Store("egypt", 200) // 从sync.Map中根据键取值 fmt.Println(scene.Load("london")) // 根据键删除对应的键值对 scene.Delete("london") // 遍历所有sync.Map中的键值对 //遍历需要提供一个匿名函数,参数为 k、v,类型为 interface{},每次 Range() 在遍历一个元素时,都会调用这个匿名函数把结果返回。 scene.Range(func(k, v interface{}) bool { fmt.Println("iterate:", k, v) return true }) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
7、nil
在Go语言中,布尔类型的零值(初始值)为 false,数值类型的零值为 0,字符串类型的零值为空字符串
"",而指针、切片、映射、通道、函数和接口的零值则是 nil但是go语言中的nil和其他语言的null是不同的,具体表现在:
- nil 标识符是不能比较的
package main import ( "fmt" ) func main() { //invalid operation: nil == nil (operator == not defined on nil) fmt.Println(nil==nil) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- nil 不是关键字或保留字
//但不提倡这样做 var nil = errors.New("my god")- 1
- 2
- nil 没有默认类型
package main import ( "fmt" ) func main() { //error :use of untyped nil fmt.Printf("%T", nil) print(nil) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 不同类型 nil 的指针是一样的
package main import ( "fmt" ) func main() { var arr []int var num *int fmt.Printf("%p\n", arr) fmt.Printf("%p", num) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- nil 是 map、slice、pointer、channel、func、interface 的零值
package main import ( "fmt" ) func main() { var m map[int]string var ptr *int var c chan int var sl []int var f func() var i interface{} fmt.Printf("%##v\n", m) //map[int]string(nil) fmt.Printf("%##v\n", ptr) //(*int)(nil) fmt.Printf("%##v\n", c) //(chan int)(nil) fmt.Printf("%##v\n", sl) //[]int(nil) fmt.Printf("%##v\n", f) //(func())(nil) fmt.Printf("%##v\n", i) //} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 不同类型的 nil 值占用的内存大小可能是不一样的, 具体的大小取决于编译器和架构
package main import ( "fmt" "unsafe" ) func main() { var p *struct{} fmt.Println( unsafe.Sizeof( p ) ) // 8 var s []int fmt.Println( unsafe.Sizeof( s ) ) // 24 var m map[int]bool fmt.Println( unsafe.Sizeof( m ) ) // 8 var c chan string fmt.Println( unsafe.Sizeof( c ) ) // 8 var f func() fmt.Println( unsafe.Sizeof( f ) ) // 8 var i interface{} fmt.Println( unsafe.Sizeof( i ) ) // 16 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
8、new && make
make 关键字的主要作用是创建 slice、map 和 Channel 等内置的数据结构
new 的主要作用是为类型申请一片内存空间,并返回指向这片内存的指针
- make 分配空间后,会进行初始化,new分配的空间被清零
- new 分配返回的是指针,即类型 *Type。make 返回引用,即 Type;
- new 可以分配任意类型的数据;
-
-
相关阅读:
【AI应用探讨】—知识图谱(KG)应用场景
如何使用pytorch定义一个多层感知神经网络模型——拓展到所有模型知识
【C++】多态“别太离谱!”
Cesium 根据飞机航线计算飞机的Heading(偏航角)、Pitch(俯仰角)、Roll(翻滚角)
137. 只出现一次的数字 II
离散数学 学习 之 一阶逻辑基本概念 ( 四 )
【电源专题】接地的类型
Spring Security应用详解(集成SpringBoot)
不是冤家不碰头:贝索斯和马斯克入选福布斯“全球最抠门亿万富豪”榜单
因子模型:协方差矩阵
- 原文地址:https://blog.csdn.net/Suk_god/article/details/133498413
