本文完成磁盘管理4层抽象中的最后一层抽象:目录与文件系统。达成的效果是整个磁盘抽象为我们日常所熟悉的目录树,这个树应当能够适配不同的操作系统(是一个独立子系统),通过 目录树/文件系统 对文件的组织,我们可以方便的访问我们需要的文件。
参考资料:
-
课程:哈工大操作系统(本部分对应 L31 && L32)
-
课本:《操作系统原理、实现与实践》- 李治军、刘宏伟
由于新学期课程开始启动,加入了学校的操作系统实践,所以后续本系列的实验更新也会变慢。不过幸运的是,能够在线下课程之前,更新完这系列的哈工大操作系统理论课程。
1. 第4层抽象描述:文件系统
经过了前3层的抽象,对磁盘的使用已经变成了对于文件的访问,而这已经很接*人们*时使用操作系统的图像了。但是这还不是最后我们眼中的系统模样,因为我们的系统中 有一个类似于文件树的多级文件结构(Ubuntu 下可用 tree 命令查看)。
而第4层抽象,就是建立文件树。
在第3层抽象中,一个文件对应一个盘块集合,通过抽象将磁盘的盘块变为用户眼中的字符流。
- 用户眼里文件的样子 —— 字符流;
- 磁盘上的文件的样子 —— 扇区集合;
- 磁盘文件抽象: 建立了以单个文件中字符流到盘块集合的映射关系。

实际生活中,我们不会只使用一个文件,我们见到的电脑中有数以万计的文件,而第四层抽象,就是从多个文件向一个文件系统的抽象,文件的物理存储位置是磁盘,这层抽象意味着对整个磁盘的抽象、组织。最终形成 我们所熟悉的文件树结构。
当然,我们会好奇这种抽象到底是如何实现的。
-
磁盘中存放文件系统的映射关系,操作系统用相关数据结构维护这些映射关系;
!这些映射关系也就是这层抽象的核心。!
-
当用户用文件树/文件系统访问文件、管理文件时,先使用这些映射关系定位到文件及文件操作,然后接入前3层抽象,向下读写磁盘。
可见,当磁盘组织为上述形式,理论上也就可以实现在不同操作系统下的适配。(即磁盘拆卸,放到不同系统的电脑上,可以继续使用)。

2. 目录:多个文件的组织结构
既然我们要使用多个文件,那么计算机如何安排多个文件呢?
- 最刚开始,所有文件都放在同一层面,这时查找目标文件就会十分麻烦。如下图所示。
- 紧接着优化一下,每个用户的文件分开,但还是不能避免上述难以查找的情况。

虽然这种优化很初级,但是基于这种分治的理念,就可以想到引入中间结构(文件夹),来管理不同层次的文件,也就是 目录树。每个目录下的文件大大减少,这样就便于查找。如下图所示:

上述引入了一个中间结构,用户常称之为文件夹,实际上也可称为 目录,表示一个文件及集合,用目录形成整个树状结构。这就是我们想要的多个文件的组织结构。
接下来的问题就是,目录这个上层抽象概念,如何对应盘块、磁盘;或是说,如何用盘块来实现目录。
3. 目录的实现思路和原理
3.1 目录的使用
有这样一个基本事实,用户对目录的使用,实际上都应当对应一些代码的执行。要弄清楚目录的实现原理,不妨看看目录在使用过程中都发生了什么。
用户想要打开 a 文件时,向下层 发出的信号 是 open 某个路径名,如 open("/my/data/a"),接着操作系统应当在目录树结构中定位 a 文件。
更准确地说,定位文件 a 意味着 要拿到文件 a 的 FCB / inode。
这里这个 “更准确的”,可以参见上一篇笔记最后的总结中的梳理。
也就是说,上层用户传下 路径名,操作系统拿到 文件的 inode,这就接上了前3层抽象,inode->盘块 -> 电梯队列 -> 解算CHS -> 磁盘控制器读写磁盘。这时,用户眼中的目录树就形成了。

那么问题就在于,如何根据路径名,得到 FCB?
3.2 目录下寻找文件
如何在父文件夹下找到子文件(夹)呢?一个很直观的想法就是,在夫文件 my(可以把文件夹/目录 也视为 一个文件)中存放子文件 data、cont、mail 的 FCB。
而如果 父文件存放所有子文件的 FCB,操作系统在拿到路径名匹配子文件时,需要把父文件中的子文件信息全部读到内存中,说到这里大家可能都明白了,实际上我们只需要在父文件下匹配下一级目录的文件名,却需要读入所有记录着子文件全部信息的 FCB 来进行匹配。
磁盘读写很慢(相较于CPU来说),而且需要读入这么多的 FCB,FCB 中有大量的无效信息,所以这样文件系统的查找比较慢,效率比较低。
更简洁的方法就是,在父文件中 存放 子文件 FCB 的地址(也就是指针)。当然,地址/指针 是一个内存概念,在磁盘中应当是:父文件中存放子文件 FCB 的某种编号,根据这个编号可以计算子文件 FCB 的位置。
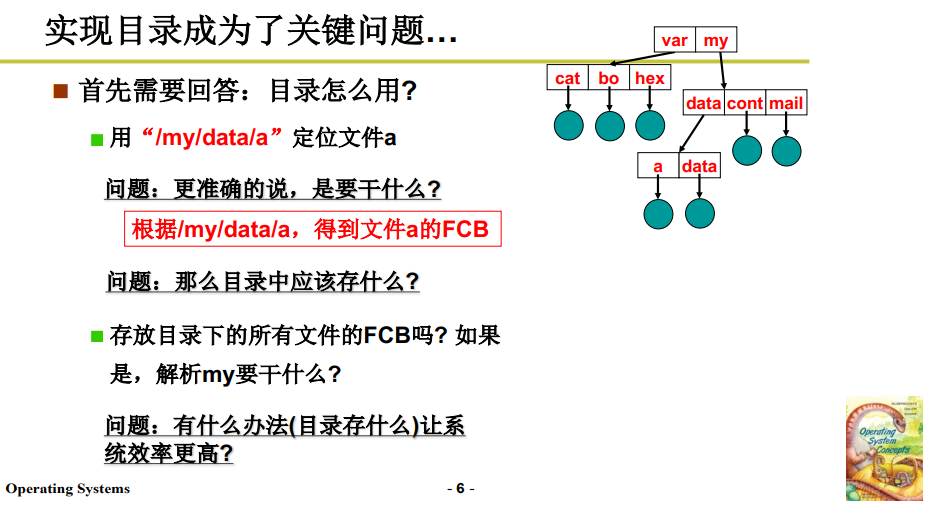
具体如何实现这个编号的操作呢?
- 父文件/目录 中存放 <文件名:索引值> ;如
- 让 FCB 在磁盘中来连续存放;也就是单独划一块连续磁盘区域存放各个文件的 FCB 。
- 这样 父文件的存储内容就少了很多,搜索时解析也更方便。
当我们找到 my 文件的 FCB,这也是一个目录,根据 FCB 找到 my 文件夹 的数据块,其中存放 my 目录下子文件的 FCB 编号,依次递推,就能找到最末端我们需要的文件。
整个流程:
- 根目录的 FCB 放在 FCB 数组的首位(一个固定的位置),这个固定的位置,或是说数组的基址,由下图中蓝色区域在磁盘初始化时记载在蓝色区域固定的位置。
- 根据父目录 的 数据块中的 索引项,可以找到子文件的 FCB 编号,据此访问 FCB数组中的 FCB,根据 FCB 找到文件的数据块;
- 同样的第二步过程,再向下搜索、匹配、解析。

3.3 文件系统自举
根据上面的流程梳理,很明显还有一个环节需要设计,那就是这个最开始根目录如何找到的问题,找到根目录后中间到末尾都可以递推得到。这就是自举。(自己能够很好的运作)
所以我们需要在别的地方设置根目录的位置。
-
将整个磁盘格式化为下图样子;
-
根目录 的 FCB 放在 FCB 数组的第一项(下图中的 i 节点区 的第一项)
-
盘块位图 区域 用于表示 盘块的空闲状态,并且表征 盘块大小。
-
inode 节点位图,用于表示 inode/FCB 区域的空闲状态,用于新建、删除文件时的状态判断。这里可以表征 操作系统支持的最多文件个数。
-
超级块,记录 自身大小、盘块位图区和 i 节点位图区 的大小 等信息;同时 根据 这三个区域的大小(以及超级块的起始位置),就可以推算 i节点区 的开始位置,即根目录的 FCB 位置。
-
拿到根目录,整个文件系统接下来递推,就实现了自举。
-
操作系统在使用磁盘时,需要将磁盘 mount 到系统上,mount 本质就是在读取 超级块,拿到位图信息和根目录。
-
-
引导块,存放磁盘启动和初始化信息。
这里位图的翻译不太直观,英文是 bitmap=bit map 用比特表示的映射。

3.4 总结
到这里四层抽象都介绍完毕了。这里来梳理一下整个磁盘抽象过程。
-
如下图所示。用户操作文件,如读取 test.c 中的一段字符流。
-
目录解析找到 test.c 文件的 FCB/ inode ;
=👆第4层,前3层👇=
-
根据 第 2 步 的 FCB 以及 所要访问的字符流 找到对应盘块789;
-
根据多进程图像,用电梯算法放入电梯队列;
-
从队列取出789盘块号,算出 CHS;
-
根据 CHS ,out 驱动磁盘控制器读写磁盘。

4. 目录解析的代码实现
这里就来看看上面的 第2步 中的 目录如何解析。
还是从顶向下看。
4.1 open():建立路径名到inode链接
open 是一个系统调用,他就会触发目录解析。 要形成 路径文件名到 inode 的链条,实际上就是第四层抽象到第三层抽象的过程。如下图所示。而open()调用了sys_open()来执行,所以目录解析代码应当从sys_open 开始看。

// 这里跟书上不大一样,理解即可
//在linux/fs/open.c中
int sys_open(const char* filename, int flag)
{
//解析路径函数,参数分别为 文件名,内存存放inode的地址
i=open_namei(filename,flag,&inode);
...
}
//目录解析
int open_namei(...)
{
dir=dir_namei(pathname,&namelen,&basename);
....
}
//核心代码
static struct m_inode *dir_namei()
{ dir=get_dir(pathname); }
4.2 get_dir:完成真正解析
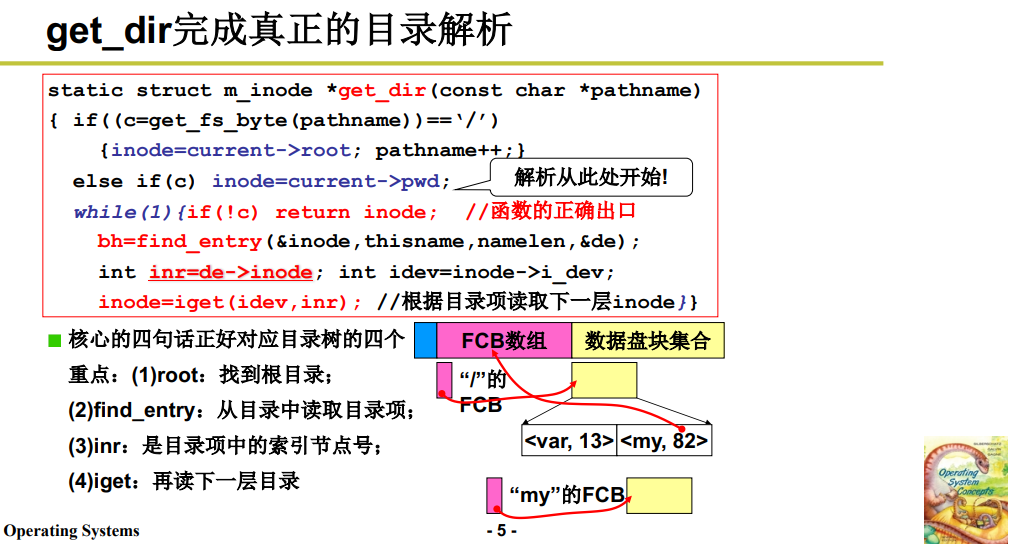
真正完成目录解析的是get_dir,它是整个目录解析的主控函数,有 4 个 比较重要的环节:
- root:找到根目录;
- find_entry:从目录中读取目录项;
- inr:目录项中的索引节点号 inode;
- iget:再读下一层目录;
// pathname 是路径名
static struct m_inode *get_dir(const char *pathname)
{
//如果是'/',从根目录开始
if((c=get_fs_byte(pathname))=='/')
{
/*
current->root 是根目录的FCB,
为什么这里根目录直接有inode呢?
这是因为所有进程都由原始shell父进程fork而来,
而操作系统初始化父进程时时
就初始磁盘得到了根目录的inode/FCB
所以root是一直都有的
(初始化代码后续还会再讲)
*/
inode=current->root; pathname++;
}
//解析从当前目录开始
else if(c) inode=current->pwd;
while(1)
{
if(!c) return inode; //函数的正确出口
//根据根目录的inode找到根目录下的目录项
bh=find_entry(&inode,thisname,namelen,&de);
// 相当于中的13
int inr=de->inode;
int idev=inode->i_dev;
//根据目录项读取下一层inode对应的目录项
inode=iget(idev,inr);
//不断循环,向下解析
}
}
4.3 mount_root:根目录的来源
4.2 中对于 inode = current -> root;的最长注释中,提到了根目录的初始化。下面看看根目录的 inode 是如何得到的。
inode=current->root;
void init(void)
{
// shell 进程会挂载磁盘
setup((void *) &drive_info);
...
}
//在kernel/hd.c中
sys_setup(void * BIOS)
{
hd_info[drive].head = *(2+BIOS);
hd_info[drive].sect = *(14+BIOS);
//挂载硬盘时将根目录挂进来
mount_root();
...
}
//在 fs/super.c 中
void mount_root(void)
{
// 根目录的挂载就是调用 iget,根据1号ROOT_INO
mi=iget(ROOT_DEV,ROOT_INO));
// 把根目录FCB读入进程PCB。
current->root = mi;
//接下来就是 子进程创建时fork继承这个root
...
}

4.4 iget():读入目录节点
看看 iget 如何将根目录读入,以及其如何将普通目录的 inode 读入。
struct m_inode * iget(int dev, int nr)
{
struct m_inode * inode = get_empty_inode();
inode->i_dev=dev; inode->i_num=nr;
//这个iget函数要做的事情就是 read_inode。
read_inode(inode); return inode;
}
static void read_inode(struct m_inode *inode)
{
//读取超级块,获得两个位图区的大小信息放到sb中,用以计算i节点的盘块号
struct super_block *sb=get_super(inode->i_dev);
lock_inode(inode);
//引导块占1个盘块,超级块1个盘块,所以从2开始计数
// i_map_block 和 z_map_block 就是两个位图区的大小
// 再加 inode->i_num-1,就是所要读的inode序号之前有几个inode块
// 这样就算出了 inode 的盘块号
block=2+sb->s_imap_blocks+sb->s_zmap_blocks+
(inode->i_num-1)/INODES_PER_BLOCK;
// 接下来调用bread,这就是从磁盘将对应盘块号内容读入内存
bh=bread(inode->i_dev,block);
//解析处理inode,因为一个盘块可能有多个inode,取出所需的。
inode=bh->data[(inode->i_num-1)%INODES_PER_BLOCK];
unlock_inode(inode);
}

- 根据这个图再敲一下黑板:inode 在磁盘上的位置 = 引导块大小 + 超级块大小 + s_imap_blocks大小 + s_zmap_blocks大小+它前面inode的大小
4.5 find_entry():读取数据块中目录项
函数 find_entry 根据目录文件的 inode 在其对应数据块中读取目录项数组,然后逐个目录项进行匹配,即 :
while(i
//de是是什么意思: directory entry(目录项)
#define NAME_LEN 14
struct dir_entry
{
unsigned short inode; //i节点号
char name[NAME_LEN]; //文件名
}
//================================
//在fs/namei.c中
static struct buffer_head *find_entry(struct m_inode
**dir, char *name, ..., struct dir_entry ** res_dir)
{
int entries=(*dir)->i_size/(sizeof(struct dir_entry));
//将目录项一项一项读入内存,这是一个索引磁盘并读入的过程
int block=(*dir)->i_zone[0];
*bh=bread((*dir)->i_dev, block);
struct dir_entry *de =bh->b_data;
//entries是目录项数,持续循环来进行匹配
while(i//#define BLOCK_SIZE 1024 一个盘块两个扇区
if((char*)de> = BLOCK_SIZE+bh->b_data)
{
brelse(bh);
block=bmap(*dir,i/DIR_ENTRIES_PER_BLOCK);
bh=bread((*dir)->i_dev,block);
de=(struct dir_entry*)bh->b_data;
}
//读入下一块上的目录项继续 match
if(match(namelen,name,de))
{
*res_dir=de;return bh;
}
de++; i++;
}
}
4.6 梳理总结
-
原始父进程--shell 进程,通过磁盘初始化得到了根目录的inode;
-
之后的子进程创建时拷贝这个inode信息;
-
当文件访问开始,首先使用 系统调用 open,open其实是包装函数,其具体代码在 get_dir 中实现;
-
get_dir 是整个过程的上层主控函数;
- 如果是根目录直接获取inode并开始解析根目录下的目录项,循环递归实现自举;
- 如果是普通目录,则也进行上述过程,不过需要解析 inode 所在的盘块号;
-
解析由 iget 来完成,有一个计算公式,mark 在 4.4 的结尾:
inode 在磁盘上的位置 = 引导块大小 + 超级块大小 + s_imap_blocks大小 + s_zmap_blocks大小+它前面inode的大小
-
拿到 inode,需要据此找到其对应的数据块,在其中的目录项中匹配下一层文件,这就是 最后 find_entry 做的事情;
-
一旦匹配,最后在 get_dir 返回的就是 inode,拿到具体文件的 inode 后,就接入前3层抽象;
-
根据具体的read or write 调用,应用前3层抽象完成整个磁盘的读写。
这也是整个文件系统的流程,只不过省去了前3层hhh。
5. 操作系统全貌
这是整个课程笔记的最后一篇,后续或许会更新实验笔记,现在总结一下:
-
多进程视图
-
CPU管理相关内容
- 进程切换;
- 进程同步与合作;
- 信号量和锁;
-
某些进程需要使用内存,涉及内存管理的相关内容;
- 段页式管理;
- 虚拟内存,换入换出;
-
需要使用文件,涉及外设、磁盘相关内容;
- open进行目录解析
- read write 读写磁盘;
文件视图
-
各个部分并行执行,彼此之间可能还有合作。’
-
-
再加上系统接口与系统启动,就可以实现一个完整的操作系统。