-
YOLOv6 | 模型结构与训练策略详细解析
如有错误,恳请指出。
美团的yolov6发布已经2个多月,现在把他的改进和知识点稍微总结一下,用这篇博客记录。github地址:https://github.com/meituan/YOLOv6
下面主要分为模型与训练策略两个方面去介绍,最后再进行总结。
1. 网络结构改进
1.1 EfficientRep Backbone
参考了重参数结构化的实现,对多卷积分支的拓扑结构进行融合。其实yolov5中也有使用到,yolov5中对3x3卷积和bn层进行了融合。

接下来就是看yolov6的网络结构部分,可以看见这里提出了3个模块:RepConv,RepBlock,SimSPPF,由于这里没有论文直接看是什么东西,所以这里分别来看源码。SimSPPF
其实吧,通过源码分析,yolov6的代码很大部分是套用yolov5的代码结构的。所谓的
SimSPPF和SimConv本质上只是激活函数使用了ReLU而不是SiLU- SimSPPF类
class SimSPPF(nn.Module): '''Simplified SPPF with ReLU activation''' def __init__(self, in_channels, out_channels, kernel_size=5): super().__init__() c_ = in_channels // 2 # hidden channels self.cv1 = SimConv(in_channels, c_, 1, 1) self.cv2 = SimConv(c_ * 4, out_channels, 1, 1) self.m = nn.MaxPool2d(kernel_size=kernel_size, stride=1, padding=kernel_size // 2) def forward(self, x): x = self.cv1(x) with warnings.catch_warnings(): warnings.simplefilter('ignore') y1 = self.m(x) y2 = self.m(y1) return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 原yolov5的SPPF类
class SPPF(nn.Module): # Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13)) super().__init__() c_ = c1 // 2 # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c_ * 4, c2, 1, 1) self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2) def forward(self, x): x = self.cv1(x) with warnings.catch_warnings(): warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning y1 = self.m(x) y2 = self.m(y1) return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
RepConv
我最早接触参数重结构化这个词是看见了大佬丁霄汉发表的几篇论文:RepVGG,RepMLP,RepLKNet,这些构建新backbone的论文无一例外的全部使用了参数重结构化的思想。
RepVGG将3x3,1x1,identity分支的残差结果利用数学计算方法等价为一个3x3的卷积结构,实现训练与推断过程的解耦;RepMLP将局部的CNN先验信息加进了全连接层,使得其与MLP相结合等等。这里需要注意,重结构化层MLP结构也不是说变成Linear层,而是简化为1x1的卷积。(后续有机会把这几篇文章介绍一下,或者直接看大佬的知乎:https://www.zhihu.com/people/ding-xiao-yi-93/posts)
这里源码中是改写了RepVGG的代码,原理如下图所示:
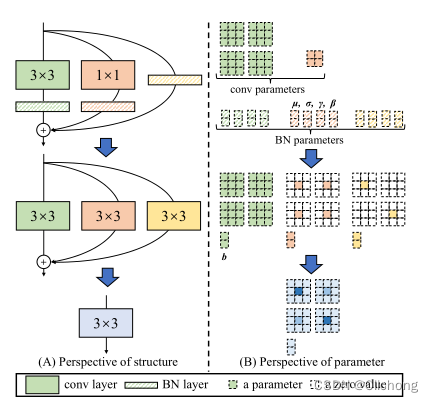
核心的思想是为了解耦训练过程与推理过程。训练过程中花的时间可以长点,缩短推理时间。在推理过程中,重结构化的网络拓扑结构会变得简单,加快推理速度。
相关的参数重结构化的技巧已经使用得比较的广泛,详细见参考资料3.
RepBlock
这个就没什么好说的了,就是多个RepConv的堆叠,不过其中 RepBlock 的第一个 RepConv 会做 channel 维度的变换和对齐。
- RepBlock代码:
class RepBlock(nn.Module): ''' RepBlock is a stage block with rep-style basic block ''' def __init__(self, in_channels, out_channels, n=1, block=RepVGGBlock): super().__init__() self.conv1 = block(in_channels, out_channels) self.block = nn.Sequential(*(block(out_channels, out_channels) for _ in range(n - 1))) if n > 1 else None def forward(self, x): x = self.conv1(x) if self.block is not None: x = self.block(x) return x- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
1.2 Rep-PAN
结构示意图如下所示:

这里的1x1 Conv其实是1x1卷积的作为通道降维操作,Upsample是使用了反卷积nn.ConvTranspose2d(其实也是卷积的一种);3x3 Conv为了减半尺寸,RepBlock与backbone中的类似。直接看源码就比较清晰了:
class RepPANNeck(nn.Module): """RepPANNeck Module EfficientRep is the default backbone of this model. RepPANNeck has the balance of feature fusion ability and hardware efficiency. """ def __init__( self, channels_list=None, num_repeats=None, block=RepVGGBlock, ): super().__init__() assert channels_list is not None assert num_repeats is not None self.Rep_p4 = RepBlock( in_channels=channels_list[3] + channels_list[5], out_channels=channels_list[5], n=num_repeats[5], block=block ) self.Rep_p3 = RepBlock( in_channels=channels_list[2] + channels_list[6], out_channels=channels_list[6], n=num_repeats[6], block=block ) self.Rep_n3 = RepBlock( in_channels=channels_list[6] + channels_list[7], out_channels=channels_list[8], n=num_repeats[7], block=block ) self.Rep_n4 = RepBlock( in_channels=channels_list[5] + channels_list[9], out_channels=channels_list[10], n=num_repeats[8], block=block ) self.reduce_layer0 = SimConv( in_channels=channels_list[4], out_channels=channels_list[5], kernel_size=1, stride=1 ) self.upsample0 = Transpose( in_channels=channels_list[5], out_channels=channels_list[5], ) self.reduce_layer1 = SimConv( in_channels=channels_list[5], out_channels=channels_list[6], kernel_size=1, stride=1 ) self.upsample1 = Transpose( in_channels=channels_list[6], out_channels=channels_list[6] ) self.downsample2 = SimConv( in_channels=channels_list[6], out_channels=channels_list[7], kernel_size=3, stride=2 ) self.downsample1 = SimConv( in_channels=channels_list[8], out_channels=channels_list[9], kernel_size=3, stride=2 ) def forward(self, input): (x2, x1, x0) = input fpn_out0 = self.reduce_layer0(x0) upsample_feat0 = self.upsample0(fpn_out0) f_concat_layer0 = torch.cat([upsample_feat0, x1], 1) f_out0 = self.Rep_p4(f_concat_layer0) fpn_out1 = self.reduce_layer1(f_out0) upsample_feat1 = self.upsample1(fpn_out1) f_concat_layer1 = torch.cat([upsample_feat1, x2], 1) pan_out2 = self.Rep_p3(f_concat_layer1) down_feat1 = self.downsample2(pan_out2) p_concat_layer1 = torch.cat([down_feat1, fpn_out1], 1) pan_out1 = self.Rep_n3(p_concat_layer1) down_feat0 = self.downsample1(pan_out1) p_concat_layer2 = torch.cat([down_feat0, fpn_out0], 1) pan_out0 = self.Rep_n4(p_concat_layer2) outputs = [pan_out2, pan_out1, pan_out0] return- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
1.3 Decoupled Head
- 结构示意图:

咋一看可能也看不懂,其实其意思就是将解耦进行到底。为每一层的预测特征层都配置不一样的回归卷积,分类卷积,置信度卷积。按照一般的FPN结构是3层,那么现在就是每一层都会有其独立的卷积输出。整个detect head不共享任何的结构,参数完全是独立的。- 源码如下:
class Detect(nn.Module): '''Efficient Decoupled Head With hardware-aware degisn, the decoupled head is optimized with hybridchannels methods. ''' def __init__(self, num_classes=80, anchors=1, num_layers=3, inplace=True, head_layers=None): # detection layer super().__init__() assert head_layers is not None self.nc = num_classes # number of classes self.no = num_classes + 5 # number of outputs per anchor self.nl = num_layers # number of detection layers if isinstance(anchors, (list, tuple)): self.na = len(anchors[0]) // 2 else: self.na = anchors self.anchors = anchors self.grid = [torch.zeros(1)] * num_layers self.prior_prob = 1e-2 self.inplace = inplace stride = [8, 16, 32] # strides computed during build self.stride = torch.tensor(stride) # Init decouple head self.cls_convs = nn.ModuleList() self.reg_convs = nn.ModuleList() self.cls_preds = nn.ModuleList() self.reg_preds = nn.ModuleList() self.obj_preds = nn.ModuleList() self.stems = nn.ModuleList() # Efficient decoupled head layers for i in range(num_layers): idx = i*6 self.stems.append(head_layers[idx]) self.cls_convs.append(head_layers[idx+1]) self.reg_convs.append(head_layers[idx+2]) self.cls_preds.append(head_layers[idx+3]) self.reg_preds.append(head_layers[idx+4]) self.obj_preds.append(head_layers[idx+5]) def initialize_biases(self): for conv in self.cls_preds: b = conv.bias.view(self.na, -1) b.data.fill_(-math.log((1 - self.prior_prob) / self.prior_prob)) conv.bias = torch.nn.Parameter(b.view(-1), requires_grad=True) for conv in self.obj_preds: b = conv.bias.view(self.na, -1) b.data.fill_(-math.log((1 - self.prior_prob) / self.prior_prob)) conv.bias = torch.nn.Parameter(b.view(-1), requires_grad=True) def forward(self, x): z = [] for i in range(self.nl): x[i] = self.stems[i](x[i]) cls_x = x[i] reg_x = x[i] cls_feat = self.cls_convs[i](cls_x) cls_output = self.cls_preds[i](cls_feat) reg_feat = self.reg_convs[i](reg_x) reg_output = self.reg_preds[i](reg_feat) obj_output = self.obj_preds[i](reg_feat) if self.training: x[i] = torch.cat([reg_output, obj_output, cls_output], 1) bs, _, ny, nx = x[i].shape x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous() else: y = torch.cat([reg_output, obj_output.sigmoid(), cls_output.sigmoid()], 1) bs, _, ny, nx = y.shape y = y.view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous() if self.grid[i].shape[2:4] != y.shape[2:4]: d = self.stride.device yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)]) self.grid[i] = torch.stack((xv, yv), 2).view(1, self.na, ny, nx, 2).float() if self.inplace: y[..., 0:2] = (y[..., 0:2] + self.grid[i]) * self.stride[i] # xy y[..., 2:4] = torch.exp(y[..., 2:4]) * self.stride[i] # wh else: xy = (y[..., 0:2] + self.grid[i]) * self.stride[i] # xy wh = torch.exp(y[..., 2:4]) * self.stride[i] # wh y = torch.cat((xy, wh, y[..., 4:]), -1) z.append(y.view(bs, -1, self.no)) # Train: [1, 3, 80, 80, 25] [1, 3, 40, 40, 25] [1, 3, 20, 20, 25] # Eval: 0: [1, 19200+4800+1200, 25] # 1: [1, 3, 80, 80, 25] [1, 3, 40, 40, 25] [1, 3, 20, 20, 25] return x if self.training else (torch.cat(z, 1), x) def build_effidehead_layer(channels_list, num_anchors, num_classes): head_layers = nn.Sequential( # stem0 Conv( in_channels=channels_list[6], out_channels=channels_list[6], kernel_size=1, stride=1 ), # cls_conv0 Conv( in_channels=channels_list[6], out_channels=channels_list[6], kernel_size=3, stride=1 ), # reg_conv0 Conv( in_channels=channels_list[6], out_channels=channels_list[6], kernel_size=3, stride=1 ), # cls_pred0 nn.Conv2d( in_channels=channels_list[6], out_channels=num_classes * num_anchors, kernel_size=1 ), # reg_pred0 nn.Conv2d( in_channels=channels_list[6], out_channels=4 * num_anchors, kernel_size=1 ), # obj_pred0 nn.Conv2d( in_channels=channels_list[6], out_channels=1 * num_anchors, kernel_size=1 ), # stem1 Conv( in_channels=channels_list[8], out_channels=channels_list[8], kernel_size=1, stride=1 ), # cls_conv1 Conv( in_channels=channels_list[8], out_channels=channels_list[8], kernel_size=3, stride=1 ), # reg_conv1 Conv( in_channels=channels_list[8], out_channels=channels_list[8], kernel_size=3, stride=1 ), # cls_pred1 nn.Conv2d( in_channels=channels_list[8], out_channels=num_classes * num_anchors, kernel_size=1 ), # reg_pred1 nn.Conv2d( in_channels=channels_list[8], out_channels=4 * num_anchors, kernel_size=1 ), # obj_pred1 nn.Conv2d( in_channels=channels_list[8], out_channels=1 * num_anchors, kernel_size=1 ), # stem2 Conv( in_channels=channels_list[10], out_channels=channels_list[10], kernel_size=1, stride=1 ), # cls_conv2 Conv( in_channels=channels_list[10], out_channels=channels_list[10], kernel_size=3, stride=1 ), # reg_conv2 Conv( in_channels=channels_list[10], out_channels=channels_list[10], kernel_size=3, stride=1 ), # cls_pred2 nn.Conv2d( in_channels=channels_list[10], out_channels=num_classes * num_anchors, kernel_size=1 ), # reg_pred2 nn.Conv2d( in_channels=channels_list[10], out_channels=4 * num_anchors, kernel_size=1 ), # obj_pred2 nn.Conv2d( in_channels=channels_list[10], out_channels=1 * num_anchors, kernel_size=1 ) ) return head_layers- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
yolov5的detect head我之前是写过博客记录的,见:Yolov5-6.0系列 | yolov5的模型网络构建。
补充:注意美团这里yolov6的forward过程:
if self.grid[i].shape[2:4] != y.shape[2:4]: d = self.stride.device yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)]) self.grid[i] = torch.stack((xv, yv), 2).view(1, self.na, ny, nx, 2).float() if self.inplace: y[..., 0:2] = (y[..., 0:2] + self.grid[i]) * self.stride[i] # xy y[..., 2:4] = torch.exp(y[..., 2:4]) * self.stride[i] # wh else: xy = (y[..., 0:2] + self.grid[i]) * self.stride[i] # xy wh = torch.exp(y[..., 2:4]) * self.stride[i] # wh y = torch.cat((xy, wh, y[..., 4:]), -1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
其还是沿用了yolov3的偏移设置

并没有使用yolov5所提出的消除网格的方法,所以还会存在一些极端点网络无法处理。所以有理由详细使用yolov5的网格敏感度消除的方法会使得yolov6的性能进一步的提升。
if self.inplace: y[..., 0:2] = (y[..., 0:2] * 2 + self.grid[i]) * self.stride[i] # xy y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh- 1
- 2
- 3
在head这一部分,除了是完全参数独立之外,其实没有过太多的改进。训练和推理形式都是类似的,返回和推理的shape也是和yolov5类似的。
# Train: [1, 3, 80, 80, 25] [1, 3, 40, 40, 25] [1, 3, 20, 20, 25] # Eval: 0: [1, 19200+4800+1200, 25] # 1: [1, 3, 80, 80, 25] [1, 3, 40, 40, 25] [1, 3, 20, 20, 25] return x if self.training else (torch.cat(z, 1), x)- 1
- 2
- 3
- 4
总结:
综上所述,将参数重结构化(3x3,1x1,残差分支合并为一个3x3卷积)方法使用在yolov5的框架中,改进了backbone与neck部分,方便部署。然后在head上使用了参数全独立的解耦。不过,缺点是甚至没有借鉴yolov5的网格敏感度消除,网络可能会出现极端点无法预测的情况。
2. 训练策略改进
2.1 Anchor-free 无锚范式
这个东西很早的时候就出现了,之前也写过一些列anchor-free算法的介绍:FCOS,CenterNet,ASFF,SAPD等等。具体参考专栏:目标检测论文专栏
由于 Anchor-based检测器需要在训练之前进行聚类分析以确定最佳 Anchor 集合,这会一定程度提高检测器的复杂度,而anchor-free就不需要任何anchor的手工或者是聚类的设置,直接是类似语义分割的想法在每个特征点上直接预测4个回归目标域k个分类目标。
不过不同算法的分配情况不同。
2.2 SimOTA 标签分配策略
YOLOv5 的标签分配策略是基于 Shape 匹配,并通过跨网格匹配策略增加正样本数量,从而使得网络快速收敛,但是该方法属于静态分配方法,并不会随着网络训练的过程而调整。
YOLOv6 引入了
SimOTA算法动态分配正样本,进一步提高检测精度。在之前的文章已经对SimOTA标签分配策略进行了详细介绍,见:YoloX | SimOTA标签匹配策略2.3 SIoU 边界框回归损失
近年来,常用的边界框回归损失包括IoU、GIoU、CIoU、DIoU loss等等,这些损失函数通过考虑预测框与目标框之前的重叠程度、中心点距离、纵横比等因素来衡量两者之间的差距,从而指导网络最小化损失以提升回归精度,但是这些方法都没有考虑到预测框与目标框之间方向的匹配性。
关于IoU、GIoU、CIoU、DIoU loss的具体介绍,之前的博客已有介绍,见:YOLOv4中的tricks概念总结——Bag of freebies
对于SIoU损失,其结果形式搞得相当的复杂,其具体包含了四个部分:角度损失(Angle cost)、距离损失(Distance cost)、形状损失(Shape cost)、IoU损失(IoU cost)
详细见:目标检测–边框回归损失函数SIoU原理详解及代码实现,这里作简要的摘抄。
- 角度损失

- 距离损失

其中:

- 形状损失

-
IoU损失
-
SIoU损失

3. 实验结果与总结
- 消融实验

- 效果对比

yolov6的实验对比更加偏向于轻量级模型的对比。对yolov6的提出,我主要从两个方面去做总结,一个是模型上的改进,另外一个是训练策略上的改进。
但是可以看见,无论是模型上的改进还是训练策略上的改进并没有提出一些比较新颖的见解。对于网络结构上的改进,主要是利用了重结构化的思想改进了yolov5的框架,同时将head进行参数的完全独立不共享(这样做可能会有效,但是感觉增加了很大的参数量)。而参数重结构化可以使得推理过程的速度加快,改变网络的拓扑结构。
对于训练策略上,没有消除网格的敏感度,可能会导致特殊值无法处理的情况。使用了一个比较新颖的Iou损失函数。但是,无论是模型还是训练策略,更感觉是一个大杂烩。特别是完全的参数独立的解耦头,只提升了0.2%,对于我们个人的配置有点怀疑其有效性,根绝投入和收获不成比例。
不过,yolov6的成功,更说明了参数重结构化的可行性与有效性。也侧面反映出yolov5的成功,影响深远。
参考资料:
4. Yolov5-6.0系列 | yolov5的模型网络构建
-
相关阅读:
如何设置和解除PDF文件保护?
毛里智慧小学宿舍楼工程量清单编制
技术实践|大模型内容安全蓝军的道与术
百度实习后端开发一二三面
基于黏菌优化的BP神经网络(分类应用) - 附代码
Leetcode 754. 到达终点数字
信号量优先级反转问题记录(总是遗忘)
【随想】每日两题Day.10(实则一题)
javaEE高阶---Spring核心与设计思想
Vue脚手架的初次了解/使用
- 原文地址:https://blog.csdn.net/weixin_44751294/article/details/126540962
