-
SparkML机器学习实战:应用回归算法,预测二手房价格
未经许可,禁止以任何形式转载,若要引用,请标注链接地址
全文共计100828字,阅读大概需要3分钟一、业务场景
受某房产中介委托,需开发一套机器学习系统,当用户将要售卖的二手房挂到二手房网站上时,该机器学习系统能自动根据该二手房的相关信息给出合理的销售价格预测,以指导客户报价。
二、数据集说明
本案例所使用的数据集为纯文本文件,说明如下:
数据集路径:/data/dataset/ml/house/train.csv三、操作步骤
阶段一、启动HDFS、Spark集群服务和zeppelin服务器
1、启动HDFS集群
在Linux终端窗口下,输入以下命令,启动HDFS集群:1. $ start-dfs.sh- 1
2、启动Spark集群
在Linux终端窗口下,输入以下命令,启动Spark集群:1. $ cd /opt/spark 2. $ ./sbin/start-all.sh- 1
- 2
3、启动zeppelin服务器
在Linux终端窗口下,输入以下命令,启动zeppelin服务器:1. $ zeppelin-daemon.sh start- 1
4、验证以上进程是否已启动
在Linux终端窗口下,输入以下命令,查看启动的服务进程:1. $ jps- 1
如果显示以下6个进程,则说明各项服务启动正常,可以继续下一阶段。
2288 NameNode 2402 DataNode 2603 SecondaryNameNode 2769 Master 2891 Worker 2984 ZeppelinServer- 1
- 2
- 3
- 4
- 5
- 6
阶段二、准备案例中用到的数据集
1、将本案例要用到的数据集上传到HDFS文件系统的/data/dataset/ml/目录下。在Linux终端窗口下,输入以下命令:
1. $ hdfs dfs -mkdir -p /data/dataset/ml 2. $ hdfs dfs -put /data/dataset/ml/house /data/dataset/ml/- 1
- 2
2、在Linux终端窗口下,输入以下命令,查看HDFS上是否已经上传了该数据集:
1. $ hdfs dfs -ls /data/dataset/ml/house- 1
这时应该看到house目录及其中的训练数据集已经上传到了HDFS的/data/dataset/ml/目录下。
阶段三、对数据集进行探索和分析
1、新建一个zeppelin notebook文件,并命名为house_project。
2、先导入案例中要用到的机器学习库。在notebook单元格中,输入以下代码:1. // 导入相关的包 2. import org.apache.spark.sql.functions._ 3. import org.apache.spark.ml.Pipeline 4. import org.apache.spark.ml.feature.{StringIndexer,VectorAssembler,RFormula} 5. import org.apache.spark.ml.regression.LinearRegression 6. import org.apache.spark.ml.evaluation.RegressionEvaluator 7. import org.apache.spark.mllib.evaluation.RegressionMetrics- 1
- 2
- 3
- 4
- 5
- 6
- 7
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:
import org.apache.spark.sql.functions._ import org.apache.spark.ml.Pipeline import org.apache.spark.ml.feature.{StringIndexer, VectorAssembler, RFormula} import org.apache.spark.ml.regression.LinearRegression import org.apache.spark.ml.evaluation.RegressionEvaluator import org.apache.spark.mllib.evaluation.RegressionMetrics- 1
- 2
- 3
- 4
- 5
- 6
3、加载训练数据集。在notebook单元格中,输入以下代码:
1. // 加载数据文件 2. val file = "hdfs://localhost:9000/data/dataset/ml/house/train.csv" 3. val house_data = spark.read.option("header", "true").option("inferSchema","true").csv(file)- 1
- 2
- 3
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:
file: String = /data/dataset/ml/house/train.csv house_data: org.apache.spark.sql.DataFrame = [Id: int, MSSubClass: int … 79 more fields]- 1
- 2
由以上输出内容可以看出,该数据集共有81个字段。
4、简单数据探索,查看数据模式。在notebook单元格中,输入以下代码:
1. // 简单的数据探索 2. house_data.printSchema- 1
- 2
同时按下【Shift+Enter】,执行以上代码,输出内容如下:
root |— Id: integer (nullable = true) |— MSSubClass: integer (nullable = true) |— MSZoning: string (nullable = true) |— LotFrontage: string (nullable = true) |— LotArea: integer (nullable = true) |— Street: string (nullable = true) |— Alley: string (nullable = true) |— LotShape: string (nullable = true) |— LandContour: string (nullable = true) |— Utilities: string (nullable = true) |— LotConfig: string (nullable = true) |— LandSlope: string (nullable = true) |— Neighborhood: string (nullable = true) |— Condition1: string (nullable = true) |— Condition2: string (nullable = true) |— BldgType: string (nullable = true) |— HouseStyle: string (nullable = true) |— OverallQual: integer (nullable = true) |— OverallCond: integer (nullable = true) |— YearBuilt: integer (nullable = true) |— YearRemodAdd: integer (nullable = true) |— RoofStyle: string (nullable = true) |— RoofMatl: string (nullable = true) |— Exterior1st: string (nullable = true) |— Exterior2nd: string (nullable = true) |— MasVnrType: string (nullable = true) |— MasVnrArea: string (nullable = true) |— ExterQual: string (nullable = true) |— ExterCond: string (nullable = true) |— Foundation: string (nullable = true) |— BsmtQual: string (nullable = true) |— BsmtCond: string (nullable = true) |— BsmtExposure: string (nullable = true) |— BsmtFinType1: string (nullable = true) |— BsmtFinSF1: integer (nullable = true) |— BsmtFinType2: string (nullable = true) |— BsmtFinSF2: integer (nullable = true) |— BsmtUnfSF: integer (nullable = true) |— TotalBsmtSF: integer (nullable = true) |— Heating: string (nullable = true) |— HeatingQC: string (nullable = true) |— CentralAir: string (nullable = true) |— Electrical: string (nullable = true) |— 1stFlrSF: integer (nullable = true) |— 2ndFlrSF: integer (nullable = true) |— LowQualFinSF: integer (nullable = true) |— GrLivArea: integer (nullable = true) |— BsmtFullBath: integer (nullable = true) |— BsmtHalfBath: integer (nullable = true) |— FullBath: integer (nullable = true) |— HalfBath: integer (nullable = true) |— BedroomAbvGr: integer (nullable = true) |— KitchenAbvGr: integer (nullable = true) |— KitchenQual: string (nullable = true) |— TotRmsAbvGrd: integer (nullable = true) |— Functional: string (nullable = true) |— Fireplaces: integer (nullable = true) |— FireplaceQu: string (nullable = true) |— GarageType: string (nullable = true) |— GarageYrBlt: string (nullable = true) |— GarageFinish: string (nullable = true) |— GarageCars: integer (nullable = true) |— GarageArea: integer (nullable = true) |— GarageQual: string (nullable = true) |— GarageCond: string (nullable = true) |— PavedDrive: string (nullable = true) |— WoodDeckSF: integer (nullable = true) |— OpenPorchSF: integer (nullable = true) |— EnclosedPorch: integer (nullable = true) |— 3SsnPorch: integer (nullable = true) |— ScreenPorch: integer (nullable = true) |— PoolArea: integer (nullable = true) |— PoolQC: string (nullable = true) |— Fence: string (nullable = true) |— MiscFeature: string (nullable = true) |— MiscVal: integer (nullable = true) |— MoSold: integer (nullable = true) |— YrSold: integer (nullable = true) |— SaleType: string (nullable = true) |— SaleCondition: string (nullable = true) |— SalePrice: integer (nullable = true)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
5、选择数据列子集,只保留作为特征使用的11个列。在notebook单元格中,输入以下代码:
1. // 选择作为特征使用的列(11个字段) 2. val cols = Seq[String]("SalePrice", "LotArea", "RoofStyle", "Heating", "1stFlrSF", "2ndFlrSF", "BedroomAbvGr","KitchenAbvGr", "GarageCars", "TotRmsAbvGrd", "YearBuilt") 3. val colNames = cols.map(n => col(n)) // Column 4. 5. // 只选择所需的列 6. val skinny_house_data = house_data.select(colNames:_*) // 可变参数- 1
- 2
- 3
- 4
- 5
- 6
同时按下【Shift+Enter】,执行以上代码,输出内容如下:
cols: Seq[String] = List(SalePrice, LotArea, RoofStyle, Heating, 1stFlrSF, 2ndFlrSF, BedroomAbvGr, KitchenAbvGr, GarageCars, TotRmsAbvGrd, YearBuilt) colNames: Seq[org.apache.spark.sql.Column] = List(SalePrice, LotArea, RoofStyle, Heating, 1stFlrSF, 2ndFlrSF, BedroomAbvGr, KitchenAbvGr, GarageCars, TotRmsAbvGrd, YearBuilt) skinny_house_data: org.apache.spark.sql.DataFrame = [SalePrice: int, LotArea: int … 9 more fields]- 1
- 2
- 3
由以上输出内容可以看出,经过转换以后,最终的DataFrame只保留了11列。
6、查看转换以后的数据。在notebook单元格中,输入以下代码:
1. skinny_house_data.take(1)- 1
同时按下【Shift+Enter】,执行以上代码,输出内容如下:
Array[org.apache.spark.sql.Row] = Array([208500,8450,Gable,GasA,856,854,3,1,2,8,2003])- 1
7、查看Schema。在notebook单元格中,输入以下代码:
1. skinny_house_data.printSchema- 1
同时按下【Shift+Enter】,执行以上代码,输出内容如下:
root |— SalePrice: integer (nullable = true) |— LotArea: integer (nullable = true) |— RoofStyle: string (nullable = true) |— Heating: string (nullable = true) |— 1stFlrSF: integer (nullable = true) |— 2ndFlrSF: integer (nullable = true) |— BedroomAbvGr: integer (nullable = true) |— KitchenAbvGr: integer (nullable = true) |— GarageCars: integer (nullable = true) |— TotRmsAbvGrd: integer (nullable = true) |— YearBuilt: integer (nullable = true)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
8、对数据集进行整理,通过相加”1stFlrSF”和”2ndFlrSF”列的值,创建一个名为”TotalSF”的新列(即将1楼面积和2楼面积相加),并将”SalePrice”列转换为double类型。在notebook单元格中,输入以下代码:
1. // 通过相加"1stFlrSF"和"2ndFlrSF"列的值,创建一个名为"TotalSF"的新列(即将1楼面积和2楼面积相加) 2. // 将"SalePrice"列转换为double 3. val skinny_house_data1 = skinny_house_data.withColumn("TotalSF", $"1stFlrSF" + $"2ndFlrSF"). 4. drop("1stFlrSF","2ndFlrSF"). 5. withColumn("SalePrice", $"SalePrice".cast("double")) 6. skinny_house_data1.show(3)- 1
- 2
- 3
- 4
- 5
- 6
同时按下【Shift+Enter】,执行以上代码,输出内容如下:

由以上输出内容可以看出,在将”1stFlrSF”和”2ndFlrSF”列合并之后,将这两个列删除,现在DataFrame仅有10列了。
9、检查名为”SalePrice”的标签列的统计信息。在notebook单元格中,输入以下代码:
1. skinny_house_data1.describe("SalePrice").show- 1
同时按下【Shift+Enter】,执行以上代码,输出内容如下:
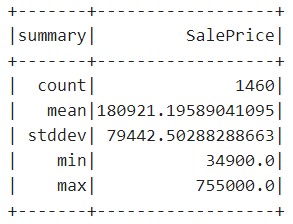
由以上输出内容可以看出所有二手房的均价、最高价和最低价。
10、将数据拆分为训练数据集和测试数据集。在notebook单元格中,输入以下代码:
1. val Array(training, test) = skinny_house_data1.randomSplit(Array(0.8, 0.2))- 1
同时按下【Shift+Enter】,执行以上代码,输出内容如下:
training: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [SalePrice: double, LotArea: int … 8 more fields] test: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [SalePrice: double, LotArea: int … 8 more fields]- 1
- 2
11、创建estimators和transformers以设置一个管道(pipeline)。
在notebook单元格中,输入以下代码:1. // 设置无效的分类值处理策略为skip,以避免在评估(evaluation)时发生错误 2. val roofStyleIndxr = new StringIndexer().setInputCol("RoofStyle"). 3. setOutputCol("RoofStyleIdx"). 4. setHandleInvalid("skip") 5. 6. // 同理 7. val heatingIndxr = new StringIndexer().setInputCol("Heating"). 8. setOutputCol("HeatingIdx"). 9. setHandleInvalid("skip") 10. 11. // 将多个特征组装为一个特性向量 12. val assembler = new VectorAssembler().setInputCols(Array("LotArea", "RoofStyleIdx","HeatingIdx","LotArea", "BedroomAbvGr","KitchenAbvGr", "GarageCars","TotRmsAbvGrd", "YearBuilt","TotalSF")).setOutputCol("features") 13. 14. // 创建线性回归算法(一个Estimator),指定SalePrice为标签列 15. val linearRegression = new LinearRegression().setLabelCol("SalePrice")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
同时按下【Shift+Enter】,执行以上代码,输出内容如下:
roofStyleIndxr: org.apache.spark.ml.feature.StringIndexer = strIdx_b6f3651520c7 heatingIndxr: org.apache.spark.ml.feature.StringIndexer = strIdx_05d504adda48 assembler: org.apache.spark.ml.feature.VectorAssembler = vecAssembler_51b012c1b303 linearRegression: org.apache.spark.ml.regression.LinearRegression = linReg_be6dd30866fd- 1
- 2
- 3
- 4
12、查看线性加归算法的各参数含义和默认值。在notebook单元格中,输入以下代码:
1. linearRegression.explainParams- 1
同时按下【Shift+Enter】,执行以上代码,输出内容如下:
String = aggregationDepth: suggested depth for treeAggregate (>= 2) (default: 2) elasticNetParam: the ElasticNet mixing parameter, in range [0, 1]. For alpha = 0, the penalty is an L2 penalty. For alpha = 1, it is an L1 penalty (default: 0.0) epsilon: The shape parameter to control the amount of robustness. Must be > 1.0. (default: 1.35) featuresCol: features column name (default: features) fitIntercept: whether to fit an intercept term (default: true) labelCol: label column name (default: label, current: SalePrice) loss: The loss function to be optimized. Supported options: squaredError, huber. (Default squaredError) (default: squaredError) maxIter: maximum number of iterations (>= 0) (default: 100) predictionCol: prediction column name (default: prediction) regParam: regulariza…- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
由以上输出内容可以看出,LinearRegression算法具有哪些参数,以及这些参数的默认值和当前值分别是多少。
13、设置管道并使用该管道训练模型。在notebook单元格中,输入以下代码:
1. // 设置pipeline 2. val pipeline = new Pipeline().setStages(Array(roofStyleIndxr, heatingIndxr, assembler, linearRegression)) 3. 4. // 训练该pipeline 5. val model = pipeline.fit(training)- 1
- 2
- 3
- 4
- 5
同时按下【Shift+Enter】,执行以上代码,输出内容如下:
pipeline: org.apache.spark.ml.Pipeline = pipeline_df9c90368f8d model: org.apache.spark.ml.PipelineModel = pipeline_df9c90368f8d- 1
- 2
这样,我们就得到了一个经过回归算法训练的预测模型。
14、执行预测。在notebook单元格中,输入以下代码:
1. // 执行预测 2. val predictions = model.transform(test)- 1
- 2
同时按下【Shift+Enter】,执行以上代码,输出内容如下:
predictions: org.apache.spark.sql.DataFrame = [SalePrice: double, LotArea: int … 12 more fields]- 1
由以上输出内容可以看出,在拟合数据后,得到一个Word2VecModel的模型对象。
15、查看预测结果。在notebook单元格中,输入以下代码:
1. predictions.select($"SalePrice",$"prediction").show(10,false)- 1
同时按下【Shift+Enter】,执行以上代码,输出内容如下:

16、执行模型性能的评估。在notebook单元格中,输入以下代码:
1. // 执行模型性能的评估,默认的度量标准是ROC下面的面积(这里改用rmse) 2. val evaluator = new RegressionEvaluator().setLabelCol("SalePrice"). 3. setPredictionCol("prediction"). 4. setMetricName("rmse") 5. val rmse = evaluator.evaluate(predictions)- 1
- 2
- 3
- 4
- 5
同时按下【Shift+Enter】,执行以上代码,输出内容如下:
evaluator: org.apache.spark.ml.evaluation.RegressionEvaluator = regEval_9371eb8014a0 rmse: Double = 42370.856215530395- 1
- 2
由以上输出内容可以看出,该次预测的结果并不理想。可以尝试从数据拆分开始多运行几次,每次的结果可能都不相同。
-
相关阅读:
HMM+维特比算法
Mac m1芯片 启动报错 MacOSDnsServerAddressStreamProvider
java实现边查边导出功能
使用Python实现几种底层技术的数据结构
算法|每日一题|倍数求和|容斥原理
Java并发编程学习二:线程安全
通过kubernetes可视化界面(rancher)安装kibana
buuctf----firmware
PTE-精听学习(一)
【操作系统】基础知识概述
- 原文地址:https://blog.csdn.net/qq_44807756/article/details/125592391
