-
论文阅读【Discriminative Latent Semantic Graph for Video Captioning】
Discriminative Latent Semantic Graph for Video Captioning
概要
- 发表:ACM MultiMedia 2021
- 代码:D-LSG
- idea:为了加强object-level interactions和frame-level information(其实是为了常用的处理后的特征:2D-CNN、3D-CNN、R-CNN),作者主要分为三部分主要工作:Enhanced Object Proposal:使用Graph将时空上的特征融合到 latent object中;Visual Knowledge:聚合上述特征于 latent nodes 中并用来预测 semantic words;Sentence Validation:使用GAN模型对重构的视觉特征进行判别。
详细设计
- 核心设计:特征融合/聚合方式(在图中)

ps:感觉有点attention的味道
1. Multiple Feature Extraction
- 常规处理,一般都会用2D-CNN提取appearance(frame-level)特征 V a V^a Va,3D-CNN提取motion特征 V m V^m Vm,R-CNN提取region(object)特征 R R R
2. Enhanced Object Proposal
- 将 region feature 分别聚合到 motion feature 和 appearance feature 中。使用GNN将每个region feature都视为一个node。

根据公式强行解释: v a v^a va与所有region feature都有边相连,所以聚合了所有region feature的特征

这里 Ψ Ψ Ψ和 Φ Φ Φ都是Linear function之后跟了一个Tanh激活。 v ^ t m \hat v_t^m v^tm的计算类似
3. Visual Knowledge
- 主要是在Graph引入了一些新的节点(latent nodes),聚合上述信息分别生成K个候选object visual words和K个motion visual words(计算类似)

4. Discriminative Language Validation
- 为了让生成的caption具有更好的语义方面的信息(semantic concepts)。作者通过从生成的captions重构 P o P^o Po和 P m P^m Pm,然后通过一个判别器进行判别重构的视觉特征 P ^ o , P ^ m \hat P^o,\hat P^m P^o,P^m和真实的征 P o , P m P^o, P^m Po,Pm。
- 具体实现是将生成的caption通过一些1D CNN+残差 的层得到sentence feature
S
S
S,然后让
P
o
P^o
Po“聚合”
S
S
S的特征
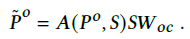
- 给生成的视觉特征
P
^
o
\hat P^o
P^o和真实的视觉特征
P
o
P^o
Po打分,将其视为一个pair,类似于计算他们的相似性


- 判别式模型的输出分数(学习给生成特征低分,真实特征高分)

- 判别式模型Loss(后者是正则化项)

- 生成式模型的损失

代码
-
相关阅读:
Cocos Creator3.8 项目实战(六)Combobox控件的实现和使用
多线程07:async、future、packaged_task、promise
哈希表题目:快乐数
【Spring Web教程】SpringBoot 实现一应用多Tomcat容器
Camtasia 2022全新版超清录制电脑视频
MongoDB聚合运算符:$sinh
MySQL | 事务隔离级别详解和实现原理
Notify
老年生活照护实训室:让养老护理变得更简单
《进程地址空间》
- 原文地址:https://blog.csdn.net/hei_hei_hei_/article/details/125546830