-
CTF-python爬虫学习笔记
学习链接
【Python+爬虫】爆肝两个月!拜托三连了!这绝对是全B站最用心(没有之一)的Python+爬虫公开课程,从入门到(不)入狱 !
。知识
,积累积累积累积累
1.1 timeout
requests.post(url,data=payload,timeout=2.5)- 1
为防止服务器不能及时响应,大部分发至外部服务器的请求都应该带着 timeout 参数。在默认情况下,除非显式指定了 timeout 值,requests 是不会自动进行超时处理的。如果没有 timeout,你的代码可能会挂起若干分钟甚至更长时间
, Python基础
1.1 出现错误

复制红框中的内容去查找1.2 打印
(1)字符串连接
ptint(“6”+“lks”)
(2)单双引号转义
print("6\“lks”)
(3)换行
print(“6\nlks”)
(4)三引号跨行字符串
print(“”“6
lks
lks”“”)

1.3 注释
单行注释
#

单行形式注释快捷键

ctrl + /
(正斜杠)多行注释
“”"
“”"

1.4 数据类型

字符串 str
字符串长度- 1
len(’ 6 ') -> 3 ——》空格算一个长度
len(‘\n’) -> 1 ——》 完整的转义符算一个长度
提取字符串中的内容- 1
“Hello”[3] -> ‘l’
索引从0开始
控制类型 NoneType

表示完全没有值,可以将未确定的变量定义为Nonemy_wife = None- 1
求数据的类型
type(6)
type(“lks”)

1.5 交互模式
[0x00]PyCharm


交互模式下
可以不用print- 1

计算结果可以直接输出- 1

退出交互模式- 1
quit()

[0x01]命令行

1.6 用户输入
input
user_age = input(“请输入您的年龄:”)
但是input输入的数据的类型是字符串
类型转换
int() str() float()

1.7 if条件判断语句
[0x00] 一般条件判断

mood_index = int(input("对象今天的心情指数是:")) if mood_index >= 60: print("恭喜,今晚应该可以打游戏,去吧!皮卡丘") else: # mood_index < 60 print("为了自个儿小命,还是别打了。")- 1
- 2
- 3
- 4
- 5
[0x01] 嵌套条件判断——下图上没有对齐

[0x02] 多个条件判断

# BMI = 体重 / (身高 ** 2) user_weight = float(input("请输入您的体重(单位:kg):")) user_height = float(input("请输入您的身高(单位:m):")) user_BMI = user_weight / (user_height) ** 2 print("您的BMI值为:" + str(user_BMI)) # 偏瘦:user_BMI <= 18.5 # 正常:18.5 < user_BMI <= 25 # 偏胖:25 < user_BMI <= 30 # 肥胖:user_BMI > 30 if user_BMI <= 18.5: print("BMI在偏瘦的范围") elif user_BMI <= 25: print("BMI在正常的范围") elif user_BMI <= 30: print("BMI在偏胖的范围") else: print("BMI在肥胖的范围")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
1.8 逻辑运算符
[0x00]and or not
2 > 1 and 3 > 2 2 > 1 or 2 > 3 not (2 > 3)- 1
- 2
- 3
- 4
- 5
[0x01]优先级
not–>and–>or
1.9 列表
[0x00] 列表的基本使用
添加 append- 1
shopping_list = ["键盘"] shopping_list.append("显示器") print(shopping_list)- 1
- 2
- 3
删除 remove- 1
shopping_list = ["键盘", "显示器"] shopping_list.remove("显示器") print(shopping_list)- 1
- 2
- 3
求长度 len- 1
shopping_list = ["键盘", "显示器"] print(len(shopping_list))- 1
- 2
索引 []- 1
shopping_list = ["键盘", "显示器"] print(shopping_list [1])- 1
- 2
max min sorted- 1

[0x01] 列表是对象

[0x02] 列表是可变的,

不可变
s = "Hello" print(s.upper()) s=s.upper() print(s)- 1
- 2
- 3
- 4

可变的列表
shopping_list = ["键盘"] shopping_list.append("显示器") print(shopping_list)- 1
- 2
- 3

1.10 字典
[0x00] 基本结构
结构

键值得为不可变的数据类型
元组

不可变- 1

字典中存元组

[0x01] 基本使用
添加
contacts = {"小明":"13700000000", "小花":"13700000001"} contacts["美女A"] = "18600000000" print(contacts)- 1
- 2
- 3
- 4

索引变为
键contacts = {"小明":"13700000000", "小花":"13700000001"} print(contacts["小明"])- 1
- 2
- 3
是否存在

删除 del
contacts = {"小明":"13700000000", "小花":"13700000001", "美女":"15730877213"} del contacts["小明"] print(contacts)- 1
- 2
- 3
- 4
- 5

求键值对对数 len
contacts = {"小明":"13700000000", "小花":"13700000001", "美女":"15730877213"} print(len(contacts))- 1
- 2
- 3
- 4

返回所有的键、值、键值对

1.11 for循环
[0x00] 基本结构
in——不在即not in

可迭代对象:列表,字典,字符串

[0x01] 基本使用
键值对的循环
两个变量- 1

一个元组- 1

range

range的循环

1.12 while
[0x00] for for range while

1.13 格式化字符串–春节发短信
[0x00] for


[0x01] format

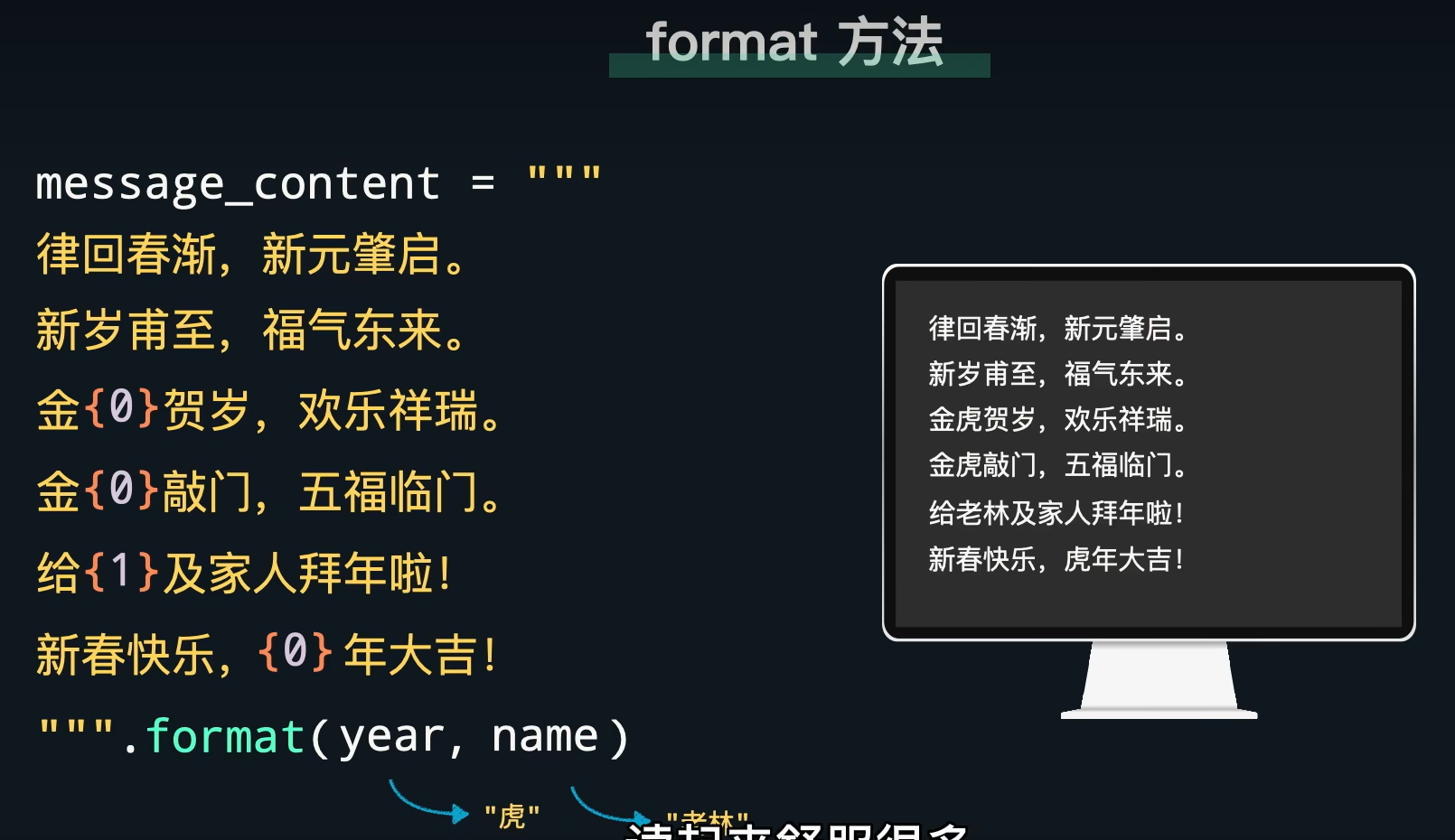


[0x02] f-字符串

[0x03] 字典循环
(1)format

(2)f-

(3)有数字
不用特殊处理
1.14 函数
[0x00] 一个完整的函数

[0x01] 内置函数集合
[0x02] Python 标准库
[0x03] 第三方库–暂无,太难学了
[0x04] 引入标准库或第三方库


1.15 面向对象编程
[0x00] 三大属性
封装
继承
多态封装
表示写类的人将内部实现细节隐藏起来,使用类的人只通过外部接口访问和使用,接口可以被大致理解为提供使用的方法

继承

多态

1.16 实例化一个对象
[0x00] 简单加上属性

__init__ self- 1
- 2
- 3
[0x01] 难点加上方法

1.17 继承
super() Mammal- 1
- 2
- 3
1.18 文件结构
[0x00] linux 和 windows的大致区别


[0x01] 绝对路径

[0x02] 相对路径

同文件夹下,相对路径可以不加 /

[0x03] /(正斜杠) 和 \(反斜杠)
linux / windows \- 1
- 2
1.19 读文件
[0x00] open函数
默认是"r" 只读模式

open函数encoding是默认跟随系统的。最好写明

读取的文件不存在,报错

[0x01] read方法


[0x02] readline方法
会读到换行符\n,打印本来就会换行,中间就会空一行


[0x03] readlines方法
会读到换行符\n


结合for

[0x04] 三类读文件方法的总结

[0x05] 关闭文件

1.20 写文件
[0x00] write方法
write方法不会帮你换行\n

[0x01] 写入模式“r” 附加模式“a”
“a”和“w”模式下,如果传入的文件不存在,会帮你创建一个

[0x02] 查看+写文件 “r+”
以追加的形式在文件后面添加新的内容

1.21 异常情况处理

,爬虫基础
1.1 爬虫过程-三步



1.2 HTTP请求
[0x00] HTTP的含义


[0x01] 请求方法

[0x02] HTTP请求的结构
整体结构

请求行
方法类型- 1
POST资源路径- 1
/user/info资源路径指明了你要访问服务器的哪个资源

/第一个斜杠表示资源路径的根根后面的
/movie/top250就是要访问的资源的路径查询参数- 1

HTTP协议版本- 1

请求头

Host 指主机域名- 1
主机域名结合请求行里的资源路径,可以得到一个完整的路径

User-Agent- 1
告知客户端的相关信息

Accept- 1
客户端想接收的响应数据是什么类型的

请求体 Get方法的请求体一般是空的

1.3 HTTP响应
[0x00] 整体结构

[0x01] 状态行
(01)协议版本
(02)状态码和状态消息 对应出现
2开头:表示成功,请求已经完成处理
3开头:表示重定向,需要进一步操作
4开头:表示客户端错误,比如请求里面有错误,或请求的资源无效等等

5开头:表示服务器错误,比如出现问题或正在维护
[0x02] 响应头
(01)包含一些告知客户端的信息

Date:生成响应的日期和时间
Content-Type: 返回内容的类型及编码格式

[0x03] 响应体
(01)服务器想给客户端的数据内容

1.4 Requests发送请求
[0x00] 状态码response.status_code判断是否成功

[0x01] response.ok判断是否成功

[0x02] response.text

爬虫练习
[0x03] 请求头修改
(01)head headers
import requests head = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36" } response = requests.get("https://movie.douban.com/top250",headers=head) if response.ok: print(response.text) else: print(response.status_code)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
修改User-Agent——豆瓣排行榜
状态码
1.5 HTML代码
[0x00] 基本结构

每一个被
<>包围的都是html标签用来告知这个文件类型是HTML是HTML文档的根,所有其他元素都要放在里面存放文章的主体内容最大字号的标题文本段落


检查小箭头,查看图对应的HTML元素

[0x01] 常见标签
(01)标题
<\h1>

(02)文本段落
<\p>
代码中换行相当于一个空格
(03)换行

(04)加粗

(05)下划线

(06)图片
width=“500px”>
height=“…px”

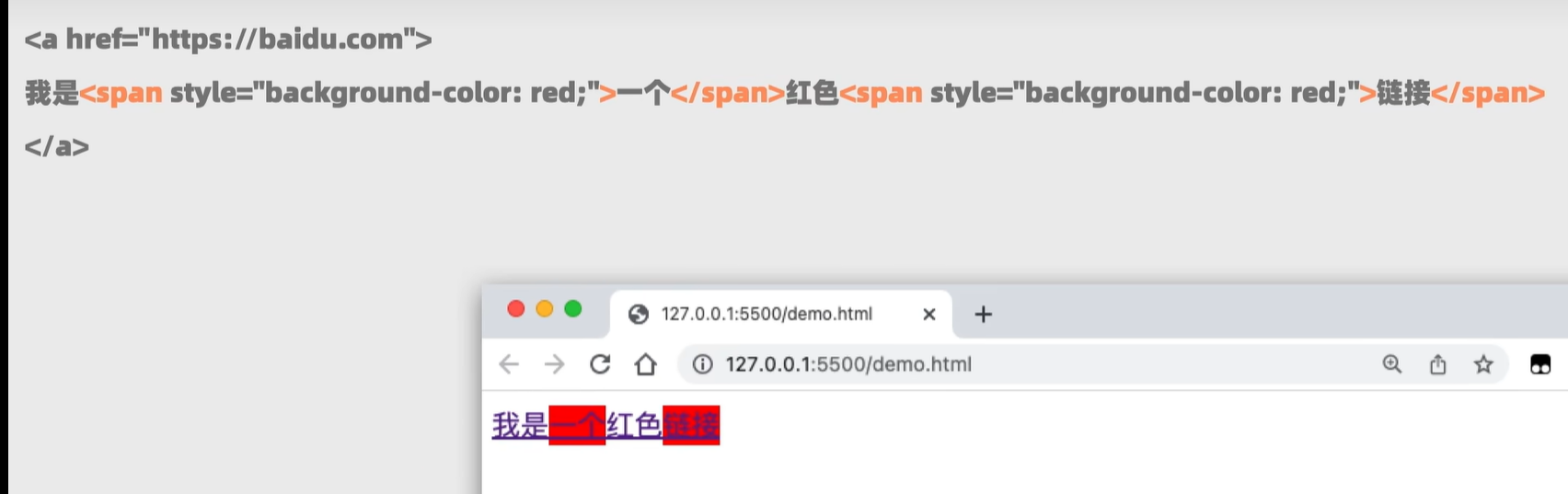
(07)链接
我的主页target="_self"表示在当前页面跳转
target=_blank表示创建新的页面跳转


(08)容器
独占一块,一行只能有一个
一行能有多个

(09)列表
其中的元素

(10)表格
表格
表格头部
表格主题
表格行
单元格
边框

(11)class属性
定义元素的类名称,帮我们分组

[0x02] 一次较难的练习
DOCTYPE html> <html> <head> <title>这是一个标题title> head> <body> <div style="background-color: red;"> <h1>我是一个一级标题h1> <h2>我是一个二级标题h2> <h6>我是一个六级标题h6> <p>这是一个<b>文本段落b>这是一个<i>文本段落i>这是一个文本段落 p> div> <p>这是一个<span style="background-color: blue;"><b>文本段落b>span>这是一个<span style="background-color: pink;"><i>文本段落i>span>这是一个文本段落 p> <img src="https://img0.baidu.com/it/u=2994715313,656209907&fm=253&app=138&size=w931&n=0&f=PNG&fmt=auto?sec=1696438800&t=1a4d44a163b0f5b02d666812bb3d2392" width="300px"> <p>p> <a href="https://www.baidu.com" target="_blank">百度链接a> <ol> <li>我是第一项li> <li>我是第二项li> ol> <ul> <li>我是第一项li> <li>我是第二项li> ul> <table border="2" class="data-table"> <thead> <tr> <td>111td> <td>222td> <td>333td> tr> thead> <tbody> <tr> <td>444td> <td>555td> <td>666td> tr> <tr> <td>777td> <td>888td> tr> tbody> table> body> html>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
1.6 解析HTML代码
[0x00] 安装bs4
python -m pip install bs4- 1
[0x01] bs4解析后的树状结构

[0x02] 爬取代码
(01)基本代码

requests.get(url,headers=headers).text:将上述内容以文本的方式进行返回。soup = BeautifulSoup(content, "html.parser"):soup是一个对象,html.parser是HTML代码解析器soup.p:得到HTML中的第一个元素,即文本段落元素。打印soup.img:得到第一个
元素

soup.p会把第一个p标签连带里面的所有内容都一并返回findAll
(02)爬取价格实战
通过all_prices = soup.findAll(“p”, attrs={“class”: “price_color”}):
all_prices是一个可迭代对象,意思是可以通过for循环依次操作返回的各个对象
attrs是一个字典,找class属性的值为price_color的元素print(price.string):把标签包围的文字返回给我们
print(price.string[2: ]):切片操作能得到索引值大于等于2的所有剩下的字符串

find
(03)爬取书名实战
通过find返回的是第一个对象


1.7 大实战——获取豆瓣电影TOP250

import requests from bs4 import BeautifulSoup headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36" } for start_num in range(0, 250, 25): response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers) html = response.text soup = BeautifulSoup(html, "html.parser") all_titles = soup.findAll("span", attrs={"class": "title"}) for title in all_titles: title_string = title.string if "/" not in title_string: print(title_string)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 相关阅读:
MathType公式转换LaTeX代码
使用 Amazon Bedrock 和 Amazon SageMaker,开启全新的生成式 AI “工作年”!
免费享受企业级安全:雷池社区版WAF,高效专业的Web安全的方案
电子器件系列52:达林顿晶体管阵列
山西电力市场日前价格预测【2023-10-18】
DFS专题训练1
使用BWGS进行基因型数据预测
【名词从句的练习题】名词从句的虚拟
c++ 利比亚行动 (libyan)
C++入门篇11 模板进阶
- 原文地址:https://blog.csdn.net/m0_74317362/article/details/133466664
