-
【K 均值聚类】02/5:简介

一、说明
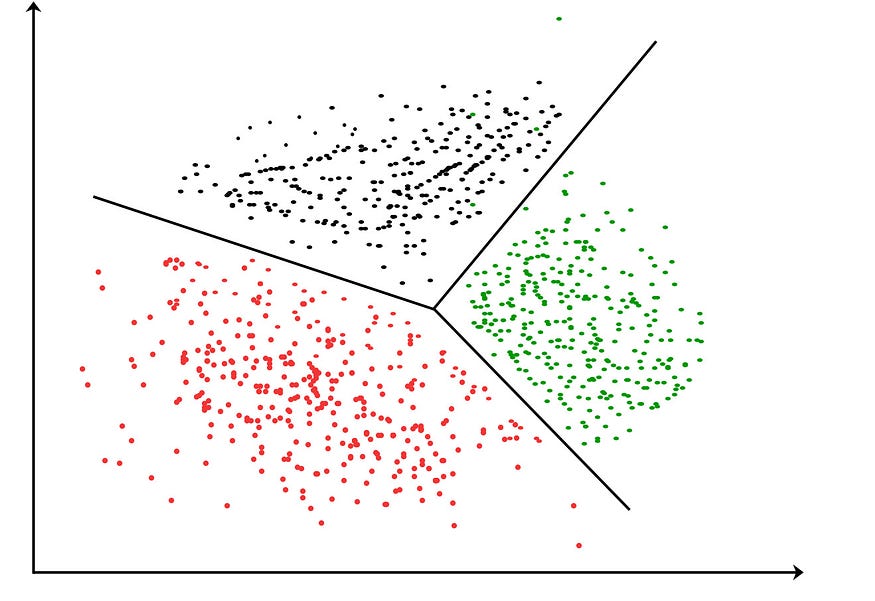
k-mean算法是一种聚类算法,它的主要思想是基于数据点之间的距离进行聚类。K-means聚类是一种无监督的机器学习算法。让我们再解释一下这句话。聚类分析的目标是将数据划分为同类聚类。每个聚类中的点彼此之间比其他聚类中的点更相似。
无监督机器学习是在没有任何标签的数据集上进行训练的。目标是发现数据中的模式或关系,而不是根据一组标记的示例进行预测。
-
相关阅读:
[Python] 元组操作及方法总结
pytorch -- torch.nn网络结构
带你学会指针进阶
选择排序算法(C++版)
“泰迪杯”技能赛丨第二期赛前培训预告
用户的生命周期
【仿真动画】ABB IRB 8700 机器人搬运(ruckig在线轨迹生成)动画欣赏
光导布局设计工具
geecg-uniapp 源码下载运行 修改端口号 修改tabBar 修改展示数据
25.flink上下游算子之间数据是如何流动的(重要)
- 原文地址:https://blog.csdn.net/gongdiwudu/article/details/132700648