-
shell脚本编程基础(中)
目录
(一)shell流程控制-for循环语句
脚本在执行任务的时候,总会遇到需要循环执行的时候,比如说我们需要脚本每隔五分钟执行一次ping的操作,除了计划任务,我们还可以使用脚本来完成,那么我们就用到了循环语句。
1. for 循环介绍
很多人把for循环叫做条件循环,或者for i in 。其实前者说的就是for的特性,for循环的次数和给予的条件是成正比的,也就是你给5个条件,那么他就循环5次;后者说的是for的语法。
循环的优点:
- 节省内存(完成同一个任务)
- 结构更清晰
- 节省时间成本
2. for语法
2.1 for 语法一
- for var in value1 value2 ......
- do
- commands
- done
循环输出1-9数字
- #!/bin/bash
- for i in `seq 1 9` #seq 1 9 是从1数到9
- do
- echo $i
- done
2.2 for语法二
C式的for命令
- for ((变量;条件;自增减运算 ))
- do
- 代码块
- done
输出1-9
- #!/bin/bash
- for (( i=1;i<10;i++ ))
- do
- echo $i
- done
for循环使用多个变量
- #!/bin/bash
- for (( a=0,b=9;a<10;a++,b-- ))
- do
- echo $a,$b
- done
for 无限循环 使用((;;)) 条件可以实现无线循环
- #!/bin/bash
- for ((;;))
- do
- echo "hehe"
- done
3.循环控制语句
3.1 sleep N 脚本执行到该步休眠N秒
- #!/bin/bash
- for i in `seq 9 -1 0`
- do
- echo -n -e "\b$i"
- sleep 1
- done
- echo
3.2 continue 跳过循环中的某次循环
默认循环输出1-9,但是使用continue跳过输出5
- #!/bin/bash
- for (( i=1;i<10;i++ ))
- do
- if [ $i -eq 5 ]
- then
- continue
- else
- echo $i
- fi
- done
3.3 break 跳出循环继续执行后续代码
默认循环输出1-9,当输出到5的时候跳出循环
- #!/bin/bash
- for (( i=1;i<10;i++ ))
- do
- echo $i
- if [ $i -eq 5 ]
- then
- break
- fi
- done
3.4实例
- #监控主机存活的脚本
- for ((;;))
- do
- ping -c1 $1 &>/dev/null #-c1是是发送一个请求包,并将返回数据放进回收站
- if [ $? -eq 0 ]
- then
- echo "`date +"%F %H:%M:%S"`: $1 is UP"
- else
- echo "`date +"%F %H:%M:%S"`: $1 is DOWN"
- fi
- #脚本节奏控制 生产环境下建议1分钟及以上
- sleep 3
- done
(二)shell流程控制-while循环语句
1. while循环介绍
while在shell中也是负责循环的语句,和for一样。因为功能一样,很多人在学习和工作中的脚本遇到循环到底该使用for还是while呢?很多人不知道,就造就了有人一遇到循环就是for或者一位的while。我个人认为可以按照我说的这个思想来使用,既知道循环次数就可以用for,比如说一天需要循环24次;如果不知道代码要循环多少次,那就用while,比如我们作业中要求写的猜数字,每个人猜对一个数字的次数都是不能固定的,也是未知的。所以这样的循环我就建议大家用while了。
2.while循环语法
- while [ condition ] #注意,条件为真while才会循环,条件为假,while停止循环
- do
- commands
- done
丈母娘选金友鑫条件:
- read -p "money:" money
- read -p "car:" car
- read -p "house:" house
- while [ $money -lt 1000000000 ] || [ $car -lt 1 ] || [ $house -lt 1 ]
- do
- echo "不行"
- read -p "money:" money
- read -p "car:" car
- read -p "house:" house
- done
- echo "给你了"
3. while实战
1、使用while 遍历文件内容
- #使用while遍历文件内容
- #!/bin/bash
- while read i
- do
- echo "$i"
- done < $1
2、使用while读出文件中的列,IFS指定默认的列分隔符
- #使用while读出文件中的列,IFS指定默认的列分隔符
- #!/bin/bash
- IFS=$":"
- while read f1 f2 f3 f4 f5 f6 f7
- do
- echo "$f1 $f2 $f3"
- done < /etc/passwd
3、九九乘法表
- #九九乘法表
- #!/bin/bash
- n=1
- while [ $n -lt 10 ];do
- for ((m=1;m<=$n;m++));do
- echo -n -e "$m*$n=$((m*n))\t"
- done
- echo
- n=$((n+1))
- done
(三)shell流程控制-until循环语句
1. until介绍
和while正好相反,until是条件为假开始执行,条件为真停止执行。
2. until语法
- until [ condition ] #注意,条件为假until才会循环,条件为真,until停止循环
- do
- commands代码块
- done
3.案例
- 打印10-20数字
- #!/bin/bash
- init_num=10
- until [ $init_num -gt 20 ]
- do
- echo $init_num
- init_num=$((init_num + 1))
- done
(四)shell流程控制-case条件判断语句
1. case介绍
在生产环境中,我们总会遇到一个问题需要根据不同的状况来执行不同的预案,那么我们要处理这样的问题就要首先根据可能出现的情况写出对应预案,根据出现的情况来加载不同的预案。
2. case语法
- case 变量 in
- 条件1)
- 执行代码块1
- ;;
- 条件2)
- 执行代码块2
- ;;
- ......
- esac
注意:每个代码块执行完毕要以;;结尾代表结束,case结尾要以倒过来写的esac来结束。
案例说明
- #!/bin/bash
- read -p "NUM: " N
- case $N in
- 1)
- echo haha
- ;;
- 2)
- echo hehe
- ;;
- 3)
- echo heihei
- ;;
- *)
- echo bye
- ;;
- esac
3. shell特殊变量
特殊参数:

(五)shell函数
1.函数介绍
建议大家把代码模块化,一个模块实现一个功能,哪怕是一个很小的功能都可以,这样的话我们写代码就会逻辑上比较简单,代码量比较少,排错简单,这也就是函数的好处。
函数的优点:
- 代码模块化,调用方便,节省内存
- 代码模块化,代码量少,排错简单
- 代码模块化,可以改变代码的执行顺序
2.函数的语法
语法一:
- 函数名 () {
- 代码块
- return N
- }
语法二:
- function 函数名 {
- 代码块
- return N
- }
3.函数的应用
3.1定义一个函数
- print () {
- echo "welcome to ayitula"
或者
- function hello {
- echo "hello world"
- }
print 和 hello就是函数的名字,函数名字命名参考变量一节中的变量命名规则
3.2函数应用
定义好函数后,如果想调用该函数,只需通过函数名调用即可。
- #!/bin/bash
- N1 () {
- echo "`date +%F`"
- }
- N2 () {
- echo -e "\t\t\t\twelcome to ayitula"
- echo -e "\n"
- }
- N3 () {
- echo "1) 剪子"
- echo "2) 石头"
- echo "3) 布"
- }
- N4 () {
- echo -e "\n\n\n"
- read -p "请输入代码: " DL
- }
- #调用代码
- N2
- N1
- N3
- N4
4.实战
nginx启动管理脚本
- #!/bin/bash
- #nginx service manage script
- #variables
- nginx_install_doc=/usr/local/nginx
- proc=nginx
- nginxd=$nginx_install_doc/sbin/nginx
- pid_file=$nginx_install_doc/logs/nginx.pid
- nginx_process_id=`cat $pid_fileps`
- ngnix_process_num=`ps aux |grep nginx_process_id|grep -v "grep"|wc -l`
- #Source function library
- if [ -f /etc/init.d/functions ];then
- . /etc/init.d/functions
- else
- echo "not found /etc/init.d/functions"
- exit
- fi
- #function
- start () {
- #如果nginx没有启动直接启动,否则报错已经启动
- if [ -f $pid_file ];tnen
- if [ -f $pid_file ]&&[ $ngnix_process_num -ge 1 ];then
- echo "nginx running ......"
- else
- if [ -f $pid_file ]&&[ $ngnix_process_num -lt 1 ];then
- rm -f $pid_file
- echo "ngin start `daemon $nginxd`"
- fi
- echo "ngin start `daemon $nginxd`"
- fi
- }
- stop () {
- if [ -f $pid_file ]&&[ $ngnix_process_num -ge 1 ];then
- action "ngnix stop" killall -s QUIT $proc
- rm -f $pid_file
- else
- action "nginx stop" killall -s QUIT $proc 2>/dev/null
- fi
- }
- restart () {
- stop
- sleep 1
- start
- }
- reload () {
- if [ -f $pid_file ]&&[ $ngnix_process_num -ge 1 ];then
- action "nginx reload" killall -s HUP $proc
- else
- action "nginx reload" killall -s HUP $proc 2>/dev/null
- fi
- }
- status () {
- if [ -f $pid_file ]&&[ $ngnix_process_num -ge 1 ];then
- echo "nginx running ..."
- else
- echo "nginx stop"
- fi
- }
- #callable
- case $1 in
- start) start;;
- stop) stop;;
- restart) restart;;
- reload) reload;;
- status) status;;
- *) echo "USAGE:$0 start|stop|restart|reload|status"
- esac
(六)正则表达式
1.正则表达式介绍
正则表达式是一种文本模式匹配,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为”元字符”)。正则表达式就像数学公式一样,我们可以通过正则表达式提供的一些特殊字符来生成一个匹配对应字符串的公式,用此来从数据中匹配出自己想要的数据。
正则表达式是一个三方产品,被常用计算机语言广泛使用,比如:shell、PHP、python、java、js等!
2.特殊字符
定位符使用技巧:同时锚定开头和结尾,做精确匹配;单一锚定开头和结尾,做模糊匹配。

- #精确匹配 以a开头c结尾的字符串
- egrep "^ac$" file
- #模糊匹配 以a开头的字符串
- egrep "^a" file
- #模糊匹配 以c结尾的字符串
- egrep "c$" file
匹配符:匹配字符串
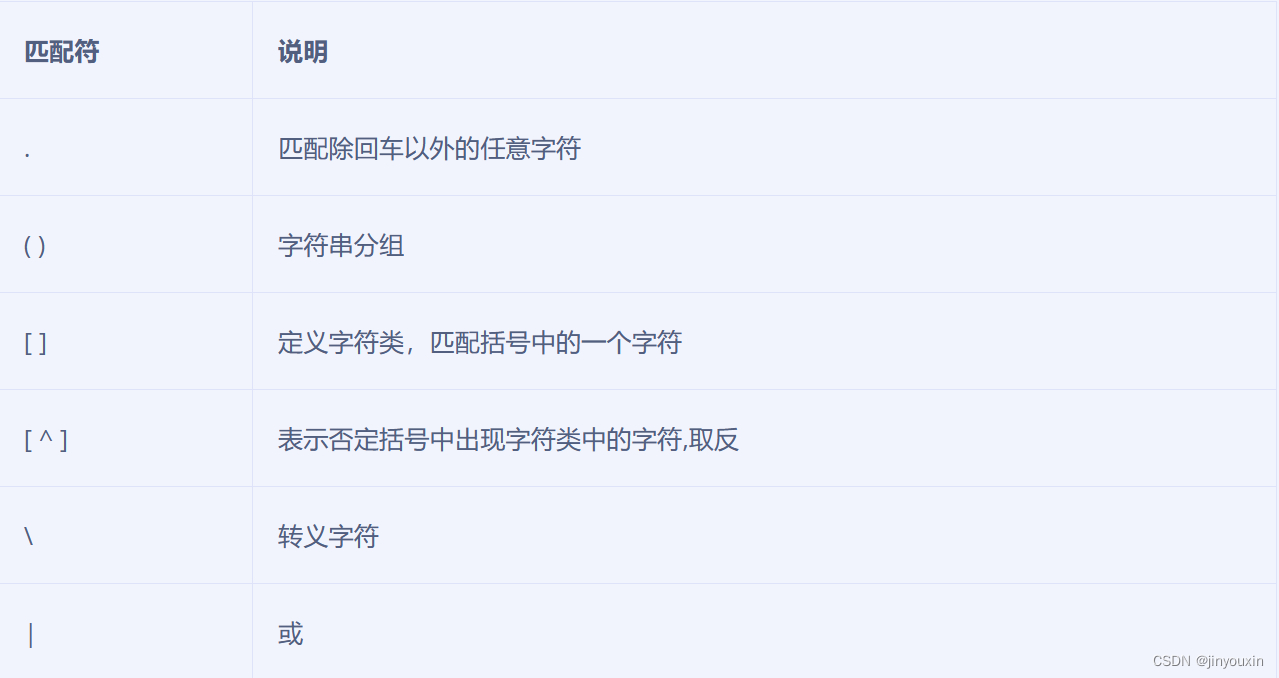
- #精确匹配 以a开头c结尾 中间任意 长度为三个字节的字符串
- egrep "^a.c$" file
- #精确匹配 以a开头c结尾 中间不包含a-z,0-9 长度为三个字节的字符串
- egrep "^a[^a-z0-9]c$" file
- #精确匹配 以e开头f结尾 中间是*号 长度为三个字节的字符串 e*f
- egrep "^e\*f$" file
- #精确匹配 以a开头b或c结尾 中间是任意 长度为三个字节的字符串
- egrep "^a.(b|c)$" file
- #模糊匹配 以cc结尾的字符串 因为$只能锚定单个字符,如果是一个字符串就需要用()来做定义
- egrep "(cc)$" file
限定符:
对前面的字符或者字符串做限定说明

- #精确匹配 以a开头 c结尾 中间是有b或者没有b 长度不限的字符串
- egrep "^ab*c$" file
- #精确匹配 以a开头 c结尾 中间只出现一次b或者没有b的字符串
- egrep "^ab?c$" file
- #精确匹配 以a开头 c结尾 中间是有b且至少出现一次 长度不限的字符串
- egrep "^ab+c$" file
- #精确匹配 以a开头 c结尾 中间是有b且至少出现两次最多出现四次 长度不限的字符串
- egrep "^ab{2,4}c$" file
- #精确匹配 以a开头 c结尾 中间是有b且正好出现三次的字符串
- egrep "^ab{3}c$" file
- #精确匹配 以a开头 c结尾 中间是有b且至少出现一次的字符串
- egrep "^ab{1,}c$" file
3. POSIX特殊字符

注意
[[ ]]双中括号的意思: 第一个中括号是匹配符[]匹配中括号中的任意一个字符,第二个[]是格式 如[:digit:]- #精确匹配 以a开头c结尾 中间a-zA-Z0-9任意字符 长度为三个字节的字符串
- egrep "^a[[:alnum:]]c$" file
- #精确匹配 以a开头c结尾 中间是a-zA-Z任意字符 长度为三个字节的字符串
- egrep "^a[[:alpha:]]c$" file
- #精确匹配 以a开头c结尾 中间是0-9任意字符 长度为三个字节的字符串
- egrep "^a[[:digit:]]c$" file
- #精确匹配 以a开头c结尾 中间是a-z任意字符 长度为三个字节的字符串
- egrep "^a[[:lower:]]c$" file
- #精确匹配 以a开头c结尾 中间是A-Z任意字符 长度为三个字节的字符串
- egrep "^a[[:upper:]]c$" file
- #精确匹配 以a开头c结尾 中间是非空任意字符 长度为三个字节的字符串
- egrep "^a[[:print:]]c$" file
- #精确匹配 以a开头c结尾 中间是符号字符 长度为三个字节的字符串
- egrep "^a[[:punct:]]c$" file
- #精确匹配 以a开头c结尾 中间是空格或者TAB符字符 长度为三个字节的字符串
- egrep "^a[[:blank:]]c$" file
- egrep "^a[[:space:]]c$" file
- #精确匹配 以a开头c结尾 中间是十六进制字符 长度为三个字节的字符串
- egrep "^a[[:xdigit:]]c$" file
案例
- 匹配合法的IP地址
egrep '^((25[0-5]|2[0-4][[:digit:]]|[01]?[[:digit:]][[:digit:]]?).){3}(25[0-5]|2[0-4][[:digit:]]|[01]?[[:digit:]][[:digit:]]?)$' —color ip.txt- 匹配座机电话号码
egrep '^[[:graph:]]{12}$” number |egrep “^(0[1-9][0-9][0-9]?)-[1-9][0-9]{6,7}$' -
相关阅读:
一张图读懂TuGraph Analytics开源技术架构
C#解析JSON详解
数字IC设计中基本运算的粗略的延时估计
kubeadm初始化搭建cri-dockerd记录 containerd.io
Java NIO 学习
1794 - 最长不下降子序列(LIS)
pytest 命令的使用
Hive_Hive统计指令analyze table和 describe table
http客户端Feign
【Linux】第二篇——权限管理
- 原文地址:https://blog.csdn.net/m0_61506558/article/details/127908185
