-
【数学与算法】跟踪、预测、单目标、多目标、匈牙利匹配之间的关系
关于多目标跟踪的文章可以参考 目标跟踪初探——SORT。
多目标跟踪的步骤先后(简单记法):
先运动方程预测,再匈牙利匹配,最后再卡尔曼滤波矫正,得到最优估计。
【卡尔曼滤波+匈牙利匹配】 进行多目标跟踪的详细步骤:(1) 计算每个检测对象与每个状态跟踪器之间的【代价矩阵】;(2) 匈牙利匹配(KM算法)求出【检测对象和融合track的匹配对】、【未匹配上的检测对象】、【未匹配上的融合track】;(3) 给没匹配上的检测对象创建融合track;(4) 对匹配上的融合track求出【卡尔曼增益】、根据检测对象的观测值求出【状态最优状态估计】、 【状态误差协方差后验估计】。(5) 根据预测方程,对状态误差协方差矩阵P进行预测:P=A*P*A^T+Q,并给所有track进行运动方程的状态预测

过程噪声和测量噪声一定存在,否则,上面两个方程就是确定的方程,就不存在卡尔曼预测了。
过程噪声和测量噪声,这两个噪声的协方差矩阵并不是状态方程和测量方程中的那两个 w k w_k wk和 v k v_k vk,注意看, w k w_k wk和 v k v_k vk是向量,向量中各元素对应每个特征的随机扰动,他们每个特征都假设服从高斯分布。注意:均值u=0,标准差 σ \sigma σ=1的高斯分布叫标准正态分布。
卡尔曼滤波器中只假设特征服从均值为0的高斯分布,并不是服从标准正态分布。你既可以把你的特征标准差 σ \sigma σ设为1,也可以设为其他值。所以,简单的卡尔曼滤波器都是把标准差 σ \sigma σ设为1。
单个特征服从高斯分布N(0, σ \sigma σ)。
如果把多个零均值的特征组成特征向量,那么特征向量就服从N(0,C)。C就是协方差矩阵。
如果两个特征之间的协方差为0,就表示这两个特征之间相互独立。那么特征向量的协方差矩阵就是对角阵,即只有对角线上的元素非0,其他元素都为0。对角线元素就表示自己特征的方差。
卡尔曼滤波的三个假设:可以参考卡尔曼滤波的三个假设.
- 1.服从高斯分布(测量噪声、系统噪声以及初始值都要求是,且互不相关)
- 2.系统是线性的(状态变化和测量都要求是)
- 3.贝叶斯滤波的马尔可夫假设。又叫完整状态假设,假设过去以及未来的数据都是独立的。也就是
t时刻的状态可以只由t-1时刻的状态推出,与(t-2)时刻的状态无关。这个其实在上面的线性公式中已经体现出来了。
预测与观测均是高斯分布,两个高斯分布的乘积就是加权后的结果。新的高斯分布方差最小,确定性也最高。障碍物
跟踪主要功能为:防止障碍物的位置、速度信息的帧间跳变,保证障碍物信息的连续性。



所有的状态估计问题都会有这两个方程:
运动方程:上一帧到当前帧的一个变化关系。通过前一帧的状态量和方差,得到当前帧的状态量和方差。
观测方程:将当前的状态,观测矩阵乘上这个状态,再把观测的噪声加进去,就得到你当前的观测结果。
注意,状态量和观测量的维度不一定相等,比如位置和速度是状态量,观测量只有速度,那么可以通过设定观测矩阵,来去掉观测量的位置。如果
观测量的维度和状态量的维度一致,可以写为:
Z = [ P t _ m e a s u r e V t _ m e a s u r e ] = [ 1 0 0 1 ] [ P t V t ] + 测量噪声向量 ( 二维 ) Z==[ P t _ m e a s u r e V t _ m e a s u r e ] [ 1 0 0 1 ] +测量噪声向量(二维) Z=[Pt_measureVt_measure]=[1001][PtVt]+测量噪声向量(二维)[ P t V t ]
观测矩阵就是 [ 1 0 0 1 ][1001]。[ 1 0 0 1 ] 如果
观测量的维度和状态量的维度不一致,只有速度可以观测到,那么可以写为:
Z = V t _ m e a s u r e = [ 0 1 ] [ P t V t ] + 测量噪声向量 ( 一维 ) Z=V_{t\_measure}=[ 0 1 ] +测量噪声向量(一维) Z=Vt_measure=[01][PtVt]+测量噪声向量(一维)[ P t V t ]
观测矩阵就是 [ 0 1 ][01]。[ 0 1 ] 预测值是根据系统的状态用运动方程来预测的;
观测值是通过某种传感器来获取的。
zhz:卡尔曼滤波的核心就是加权平均法,只不过我们平时设置权重可能是人为经验指定的权重,而卡尔曼滤波则是根据测量噪声、过程噪声、状态向量到测量向量的转移矩阵等进行建模得到的权重。注意2个预测公式和5个更新公式,我们想要得到的是状态量的最优值,他是在更新公式中,不是在预测公式中,因为最优估计是通过加权平均估计出来的,不是预测出来的,因为预测出来的值也是有过程噪声的,根据上一时刻状态量预测出下一时刻的状态量,有偏差,需要加权法来矫正。
预测的两个公式是根据上一时刻的状态量 得到当前时刻的状态量(先验值) , 或者根据上一时刻 k − 1 k-1 k−1的 x ^ k − 1 \hat{x}_{k-1} x^k−1的后验估计协方差,得到当前 k k k时刻的 x ^ k − \hat{x}_{k}^- x^k−的先验估计协方差。一个是状态量的预测,一个是状态估计的协方差的预测。更新的三个公式是分别是求卡尔曼增益、状态量的最优值、当前时刻的后验估计协方差。
预测和更新是交替进行。预测后的值需要在更新中用到;而更新后的值,作为下一时刻的预测的输入(时刻下标k变为了k-1代入预测公式)。更新公式中的状态最优估计公式需要用到卡尔曼增益公式,而卡尔曼增益公式需要用到预测公式中的协方差预测,协方差公式的更新也需要用到预测公式中的协方差预测,以及卡尔曼增益。

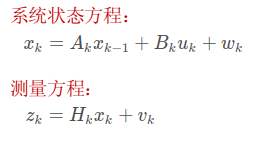

预测:预测就是针对每一个
单一目标来特定分析。如果有多个目标,那么就是分别对每个目标进行预测。- (1) 根据该目标
k-1时刻的状态来预测k时刻的状态(得到k时刻的先验估计值); - (2) 然后用
k时刻的观测值再来校正k的估计值,(进行加权)得到k时刻的后验估计(最优估计)。
跟踪:对于
单目标跟踪来说,不需要匈牙利匹配,只需要卡尔曼滤波。
对于多目标跟踪来说,需要卡尔曼滤波器和匈牙利匹配一起才能做到。- (1) 卡尔曼滤波器先根据所有目标
k-1时刻的状态分别预测对应目标k时刻的状态(是先验估计值,并非最优估计,因为还不知道k时刻的观测值,要匹配上之后才知道观测值); - (2) 然后
匈牙利匹配把所有目标的k时刻状态预测值(先验估计)和所有目标的k时刻观测值的状态进行匹配,匹配上就是跟踪上了。 - 注意,是
k时刻预测值(先验估计值)和k时刻观测值匹配,进行下一次跟踪时,再利用k时刻观测值矫正k时刻先验估计值,得到k时刻最优估计值,作为新的状态值来预测k+1时刻的先验估计值。
平滑:平滑是对历史数据做修正。 -
相关阅读:
【tio-websocket】13、消息编码、解码、处理—TioHandler
Flask 实现增改及分页查询的完整 Demo
核壳量子点/聚苯乙烯荧光微球core-shell QDs/polystyrene fluorescent microspheres
std::cout、printf 和 RCLCPP_INFO的对比
elasticsearch配置密码、docker数据迁移、IP白名单
chatGPT底层原理是什么,为什么chatGPT效果这么好?三万字长文深度剖析-下
【含视频教程】python实现图书管理系统
哪个牌子的儿童护眼灯好?分享315护眼灯合格名单的护眼台灯
【从 0 开始学微服务】【11】微服务为什么要容器化?
【JVM】优化参数+优化工具+优化实例
- 原文地址:https://blog.csdn.net/u011754972/article/details/123245772