-
Path-Ranking:KBQA中path生成、召回、粗排与精排
路径生成:通过实体链接获取到了问题中的实体,路径生成则是从实体出发,遍历KG,生成所有可能的答案路径,在过程中对路径进行剪枝。
1、路径召回
路径召回策略分为单实体和多实体两种情况。其中,多实体优先,即:如果多实体间存在路径,则不进行单实体召回。
1.1 单实体路径召回策略:
(1) 作为头实体的一度路径 <实体><关系>;
(2) 作为尾实体的一度路径 <关系><实体>;
(3) 对 (1) 扩展至二度出路径 <实体><关系1><关系2>;
(4) 对 (1) 扩展至二度入路径 <实体><关系1><关系2>;
(5) 对 (2) 扩展至二度出路径 <关系1><实体><关系2>;
(6) 对 (2) 扩展至二度入路径 <关系1><实体><关系2>。
1.2 多实体路径召回策略(以双实体为例):
(1) 一度路径 <实体1><关系1><实体2><关系2>;
(2) 一度路径 <关系1><实体1><关系2><实体2>;
(3) 一度路径 <关系1><实体1><实体2><关系2>;
(4) 一度路径 <实体1><关系1><关系2><实体2>;
(5) 对 (1)(同2、3、4) 扩展至二度出路径 <实体><关系1><实体2><关系2><关系3>;
(6) 对 (1)(同2、3、4) 扩展至二度入路径 <实体><关系1><实体2><关系2><关系3>;
(7) 实体间的关系<实体1><实体2>。
2、剪枝
为避免候选答案数目爆炸,我们根据以下策略进行剪枝。
(1) 删除一跳路径中答案实体是话题实体的路径,避免将话题实体本身作为答案;
(2) 如果二跳节点超过10000个,则不进行二跳;
(3) 删掉二跳路径中答案实体是话题实体的路径,避免将话题实体本身作为答案;
(4) 当二跳路径(出或入)数超过100条但小于500时,删掉二跳路径(出或入)中的关系与问句没有任何字符上的交集的候选答案路径;
(5) 当二跳路径(出或入)数超过500时,过滤掉所有二跳路径。
3、路径排序
路径排序分为粗排和精排两个步骤。
3.1 粗排
根据问题query和候选路径path的特征,对候选路径进行粗排,可采用机器学习模型,如:LightGBM、XGBOOST等,保留top20条路径,可参考以下特征进行特征工程时:
- 字符特征
- 字符重合数
- 词重合数
- 字符的Jaccard相似度(类似IOU)
- 词的Jaccard相似度(类似IOU)
- 编辑距离
- path的字符是否全部在query中
- path自身特征
- 答案的个数
- path的跳数
- path中实体的个数
- path中关系的个数
- path的长度
- 语义特征
- 字级别向量的相似度
- 词级别向量的相似度(可用jieba切词)
- bi-gram级别向量相似度(可用ac自动机等)
- 流行度特征
- 答案在KG中出现的频率
- 答案不同的一度关系的个数
- 数字特征
- 数字的重合数
- query与path的Jaccard相似度
- path中的数字是否全部在query中
- 其他特征
- 候选答案是否在query中
- path中的关系是否在query中
- path中的意图是否在query中
- …
3.2 精排
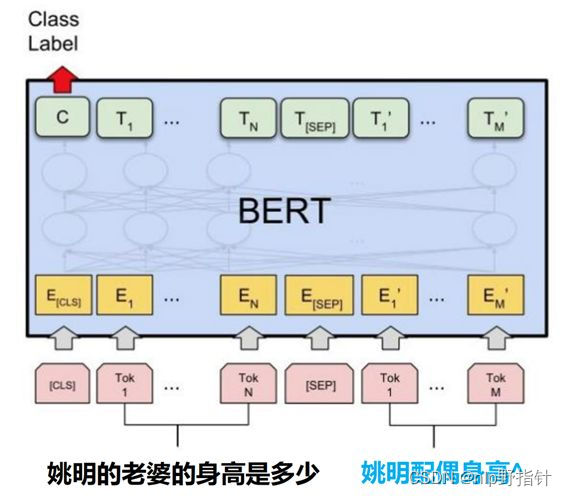
3.1中使用lgb等机器学习模型的主要目的通过粗排,减少精排过程中的数据量,在精排时能够好的利用预训练语言模型计算query和path的语义匹配度,选择得分最高的答案路径作为答案。
公众号:自然语言处理及深度学习
- 字符特征
-
相关阅读:
System.Data.SqlClient.SqlError: 因为数据库正在使用,所以无法获得对数据库的独占访问权。
浅谈 RADIUS 认证协议的起源与未来展望
如何使用 Spring Security手动验证用户
Flume环境搭建
clm大气强迫数据制作
Flutter 中的照片管理器(photo_manager):简介与使用指南
年轻人如何预防胆囊结石?
Elasticsearch核心概念解析:索引、文档与类型
第17章 站点构建
dataloader重构与keras入门体验
- 原文地址:https://blog.csdn.net/yjh_SE007/article/details/127068875