-
Machine Learning Pre-Basics
Machine Learning Pre-Basics
1.Classification
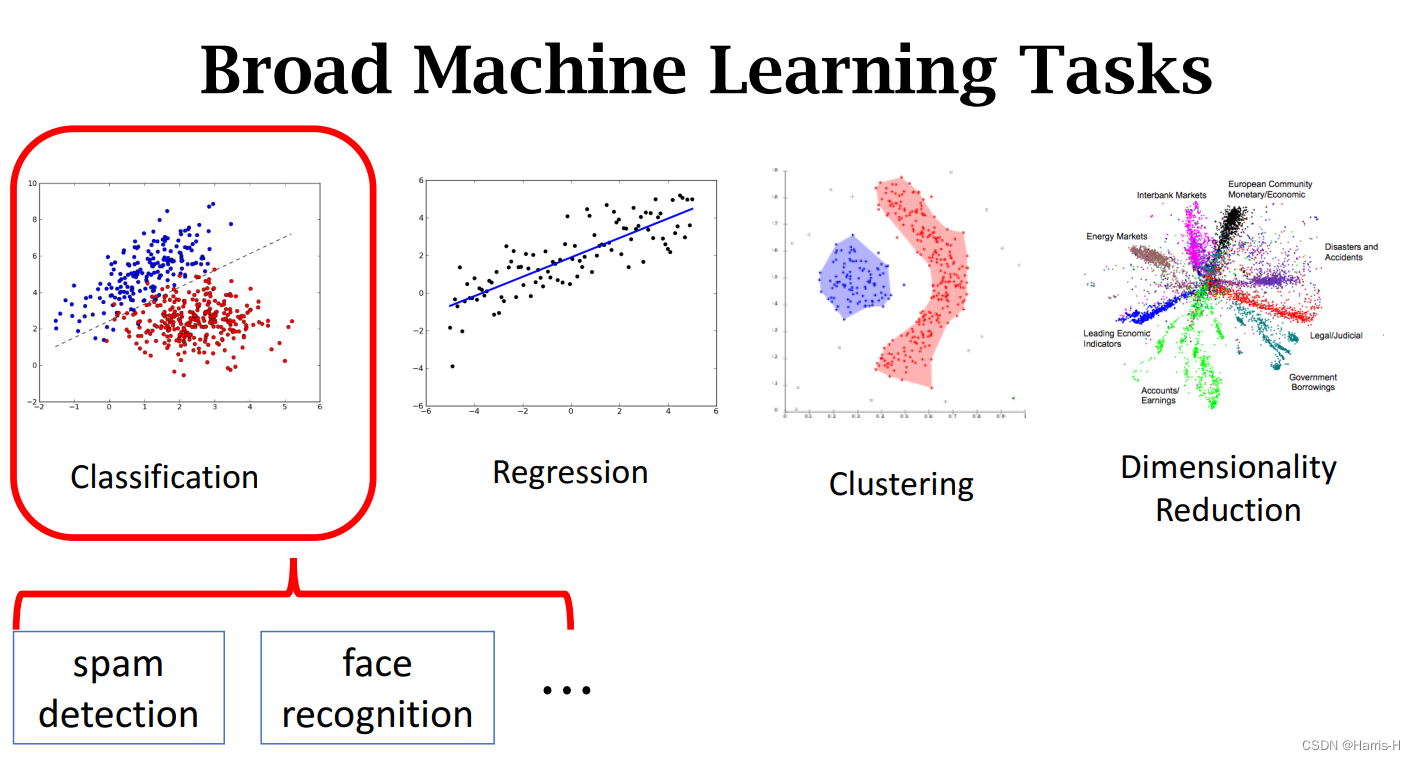
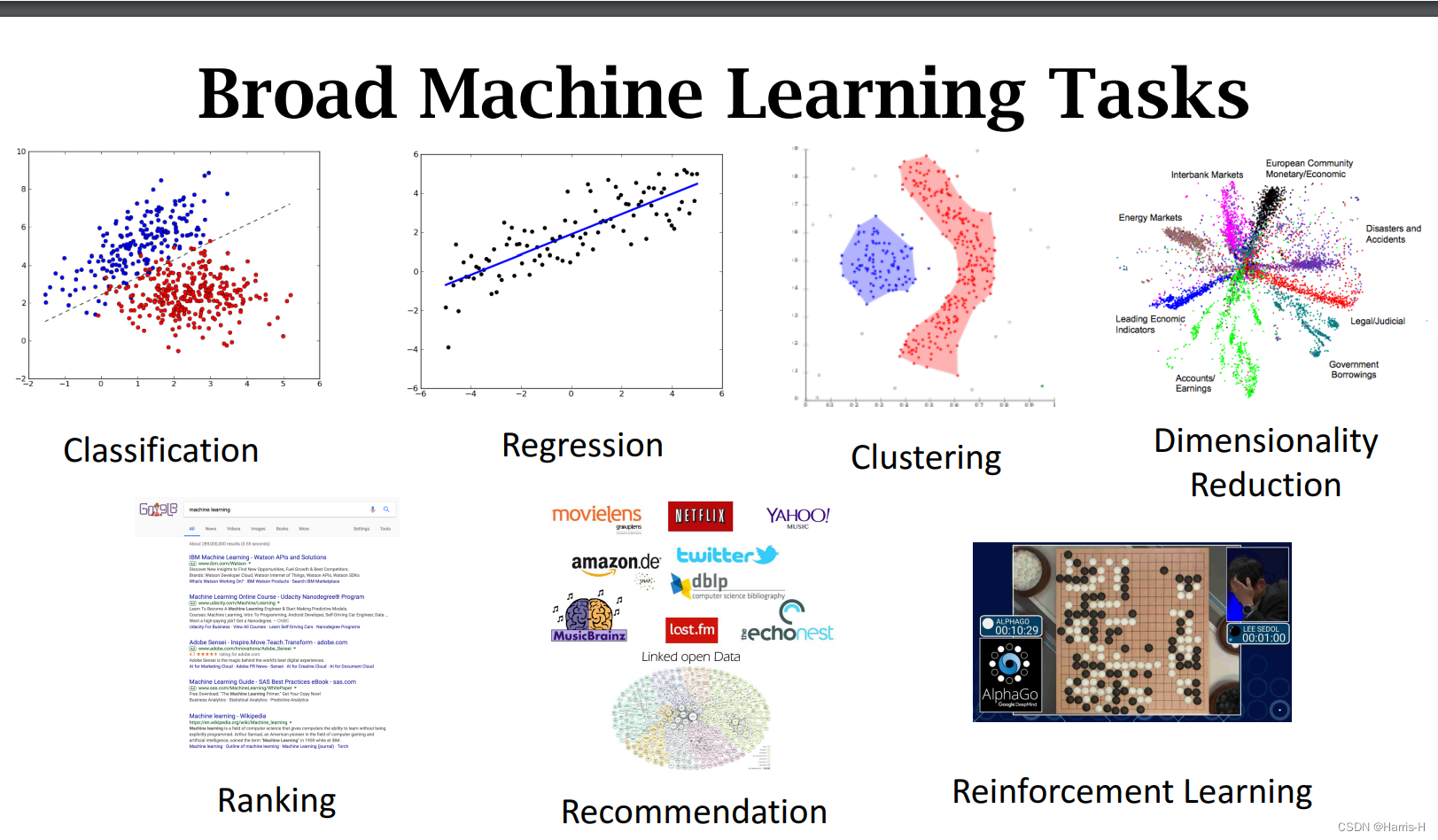
机器学习能应用到广泛的任务中:分类、回归、聚集、降维。
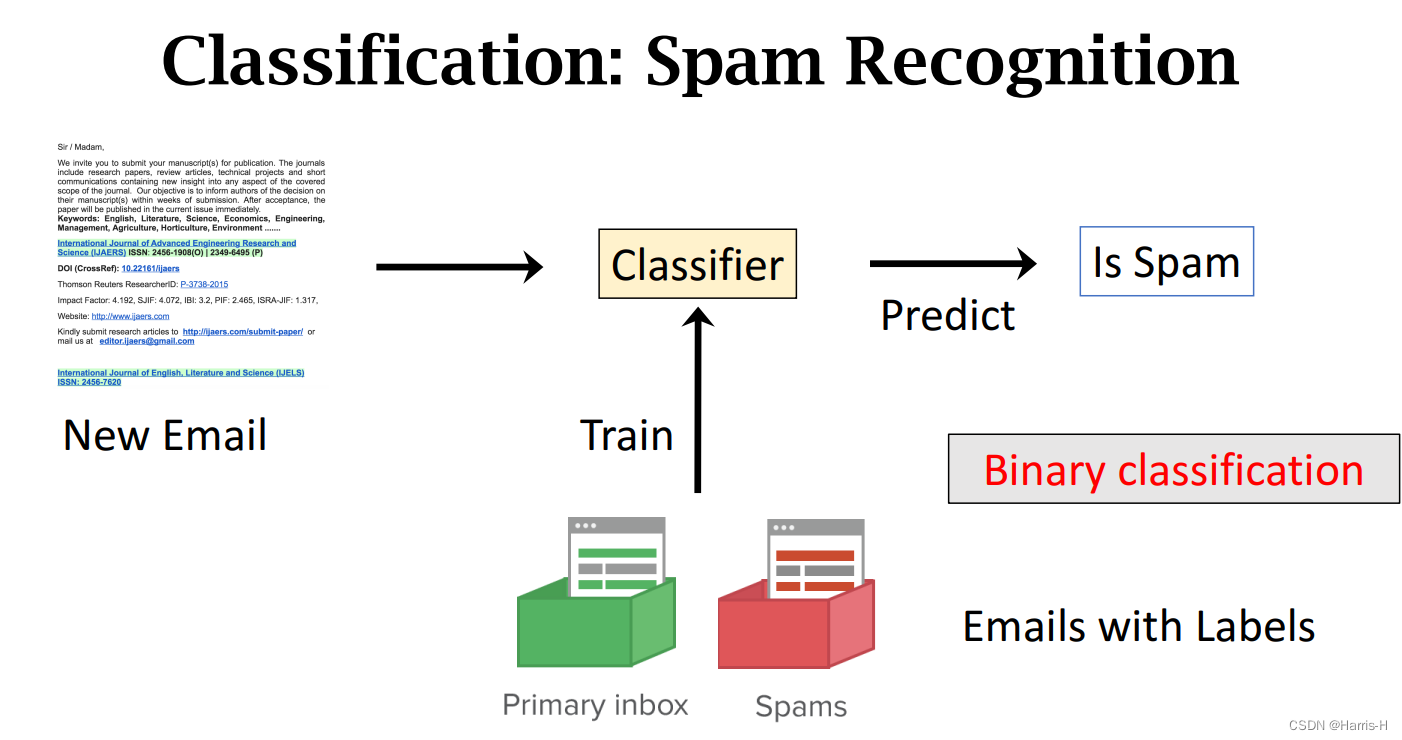
上面是一个常见的垃圾邮件二分类问题。
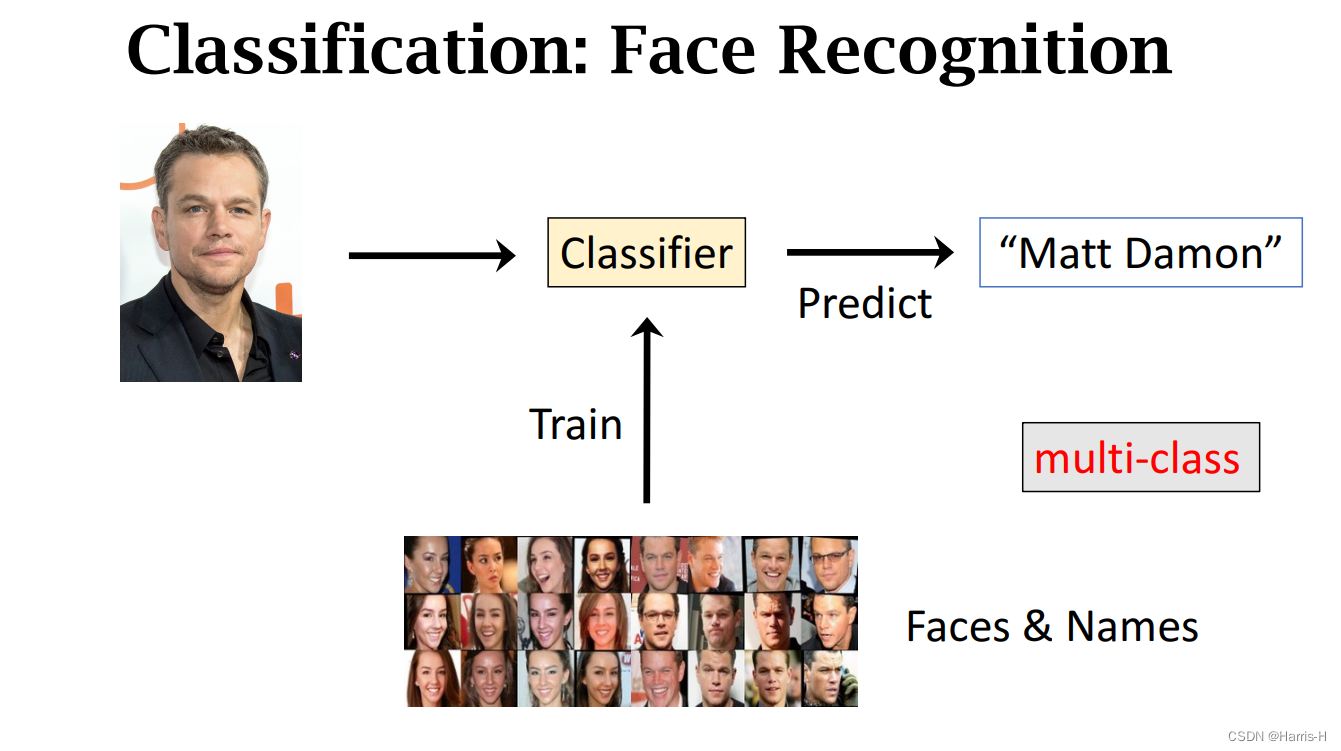
上面是人脸识别的多分类问题。
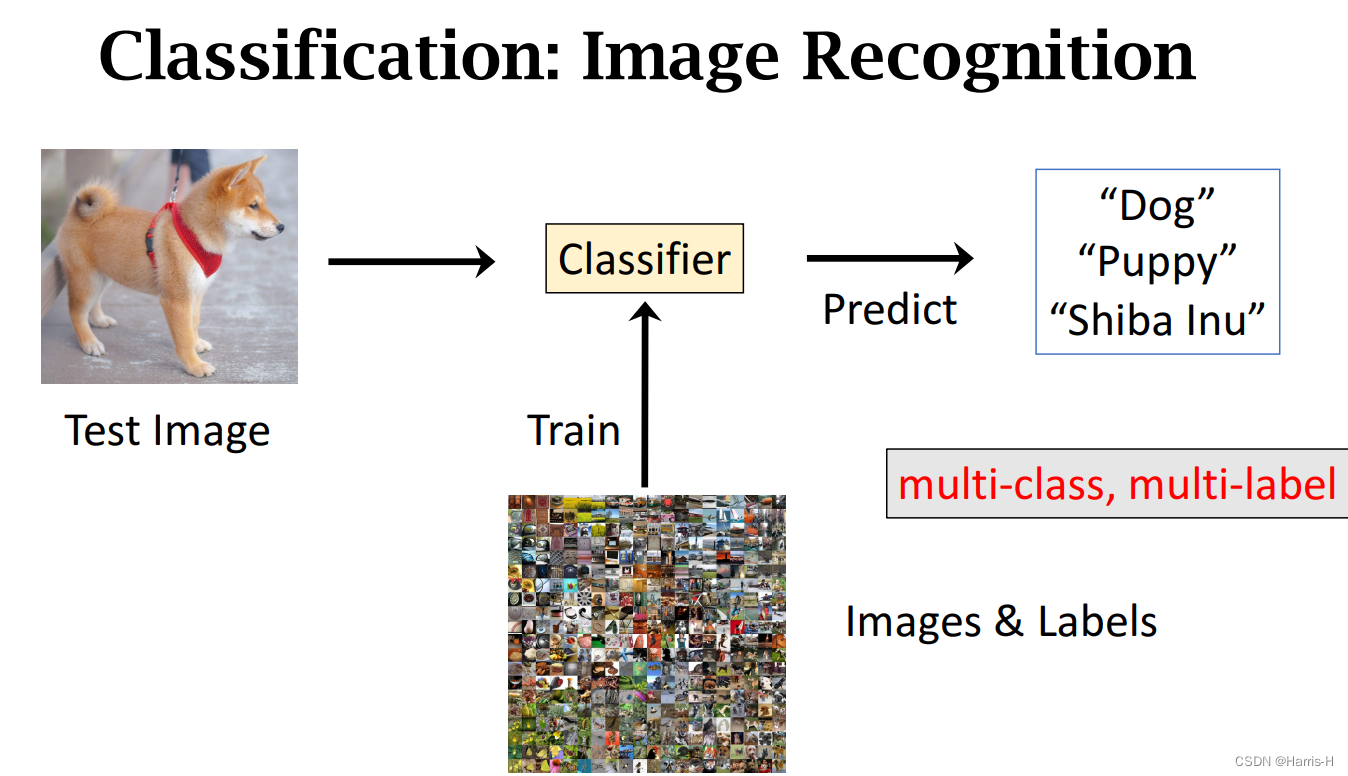
多类别、多标签的分类问题。
2.Regression
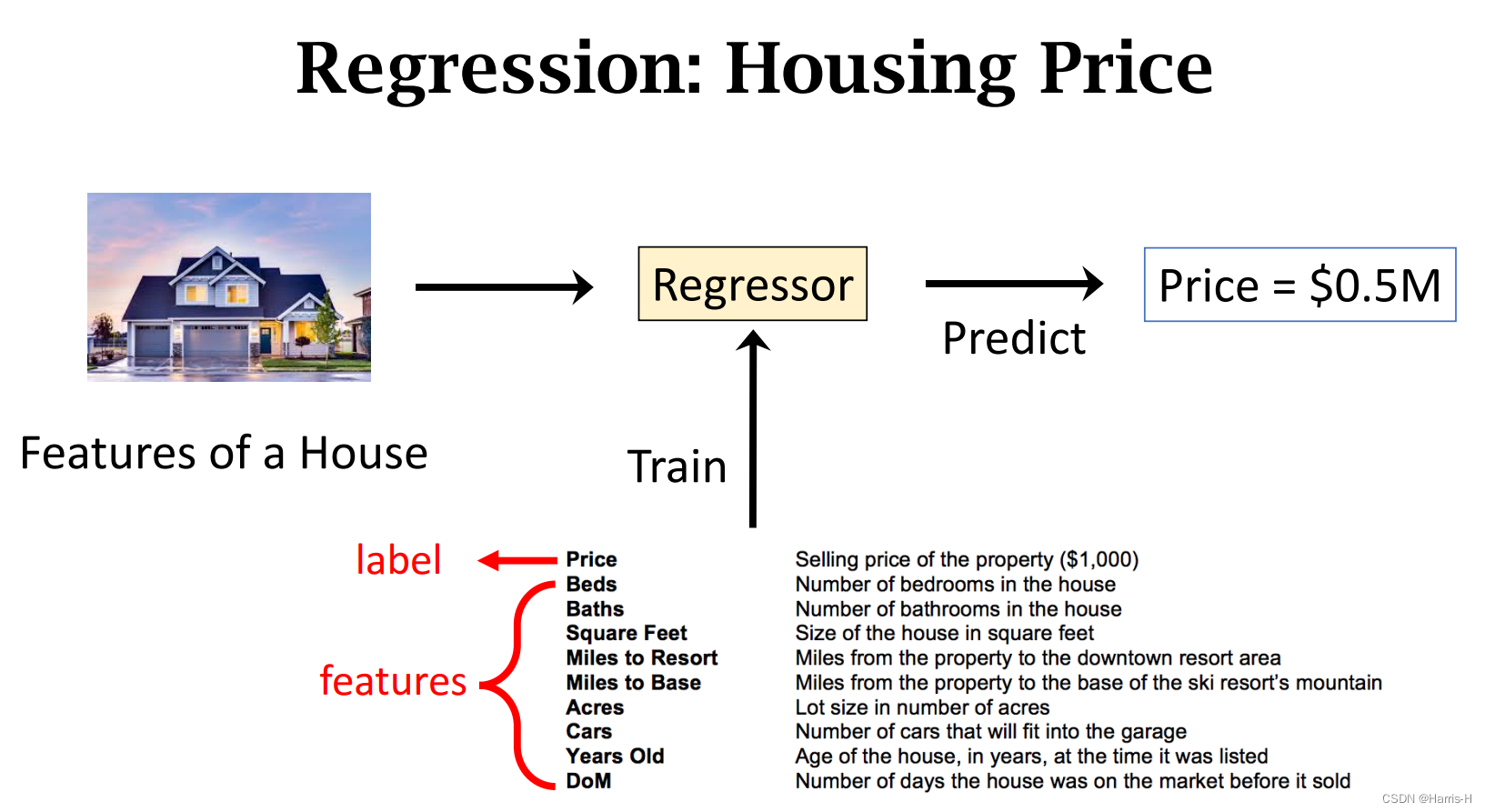
回归模型通过训练 带有features和label 的数据 来预测。

回归相比分类,是连续且可排序的。


分类的标签是确定的且无法比较的。
3.Clustering
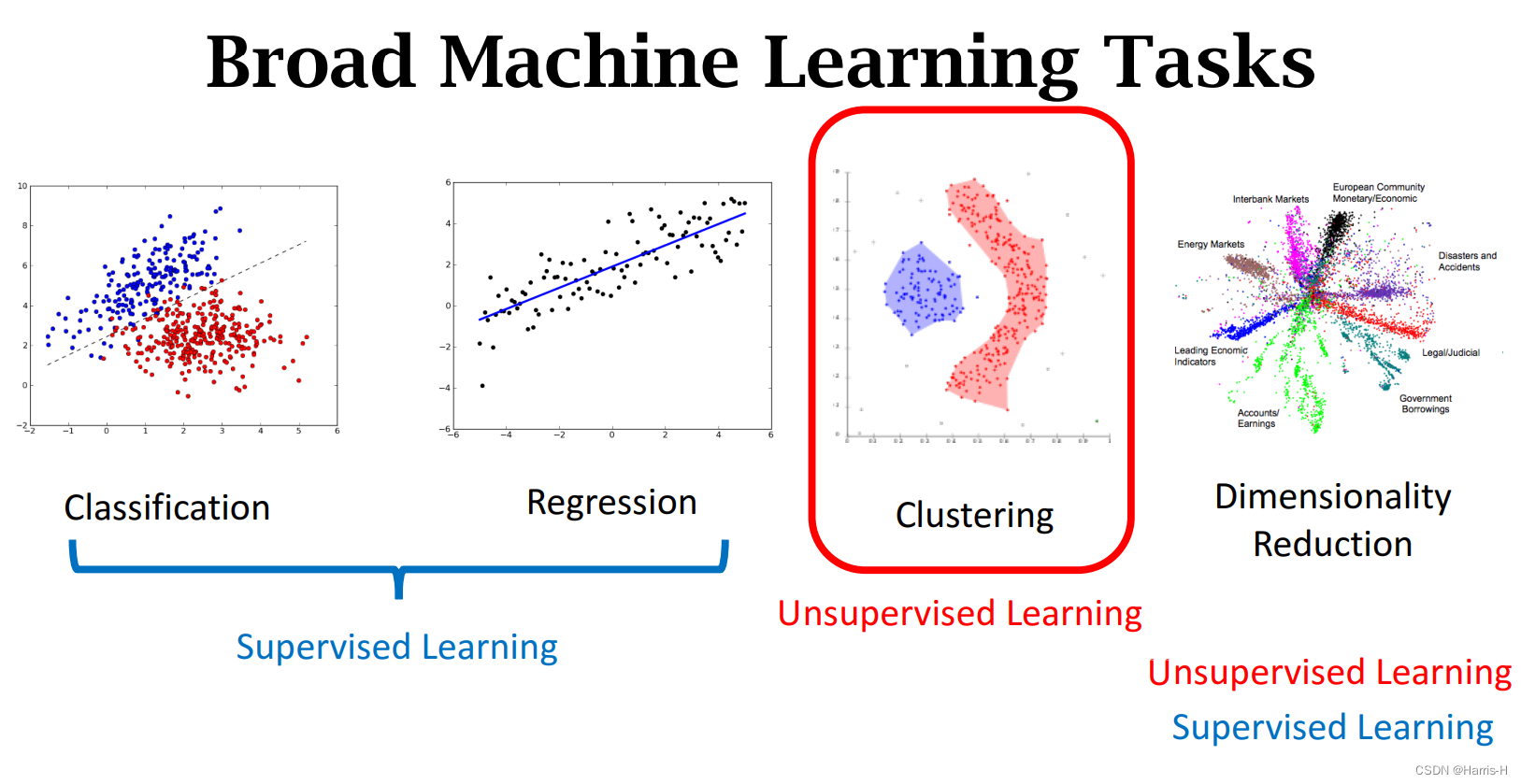

Clustering 的任务就是聚类。

监督学习是从带标签的训练数据学习。
非监督学习是从不带标签的数据得出结论。
4.Dimensionality Reduction
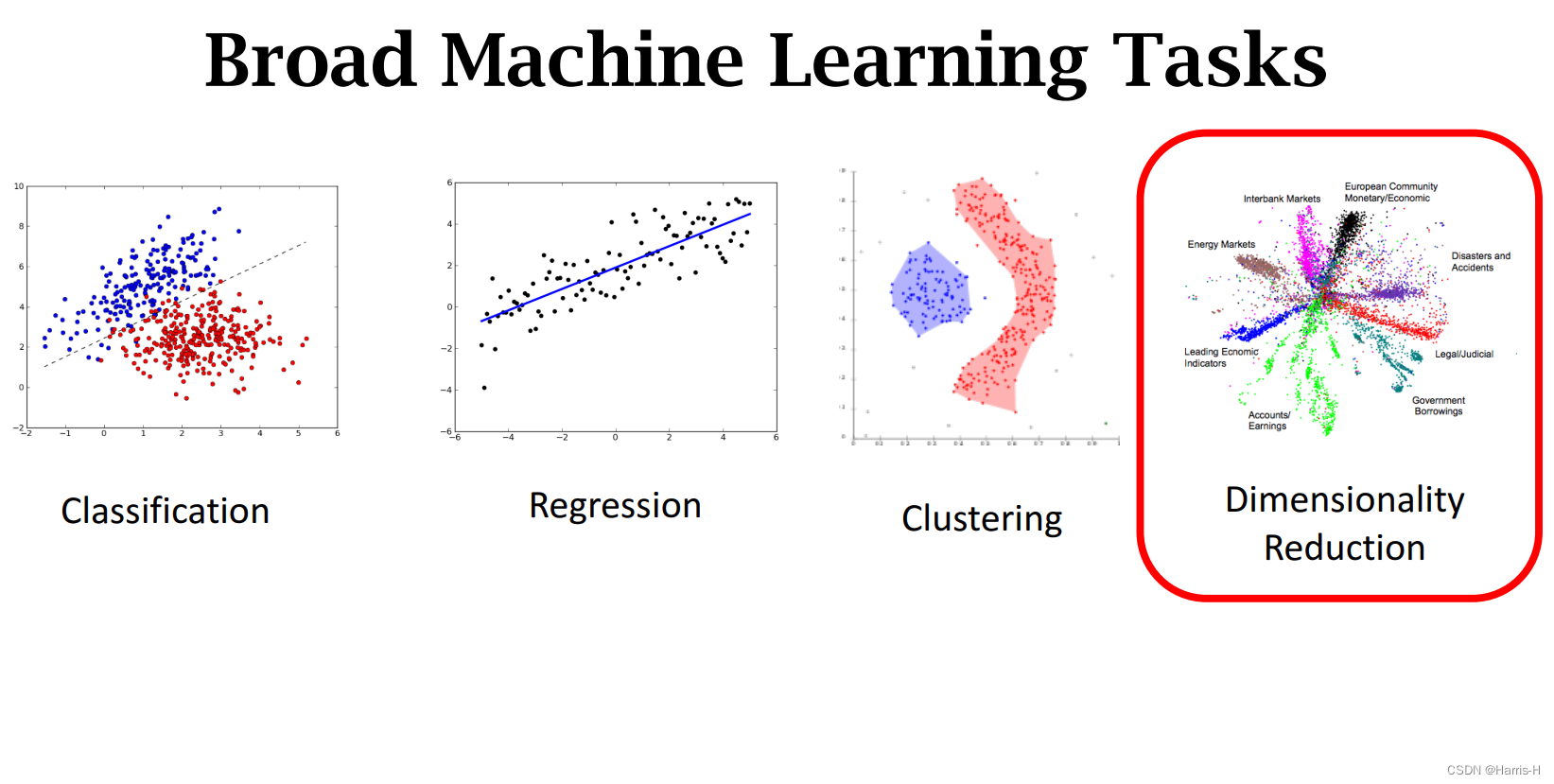
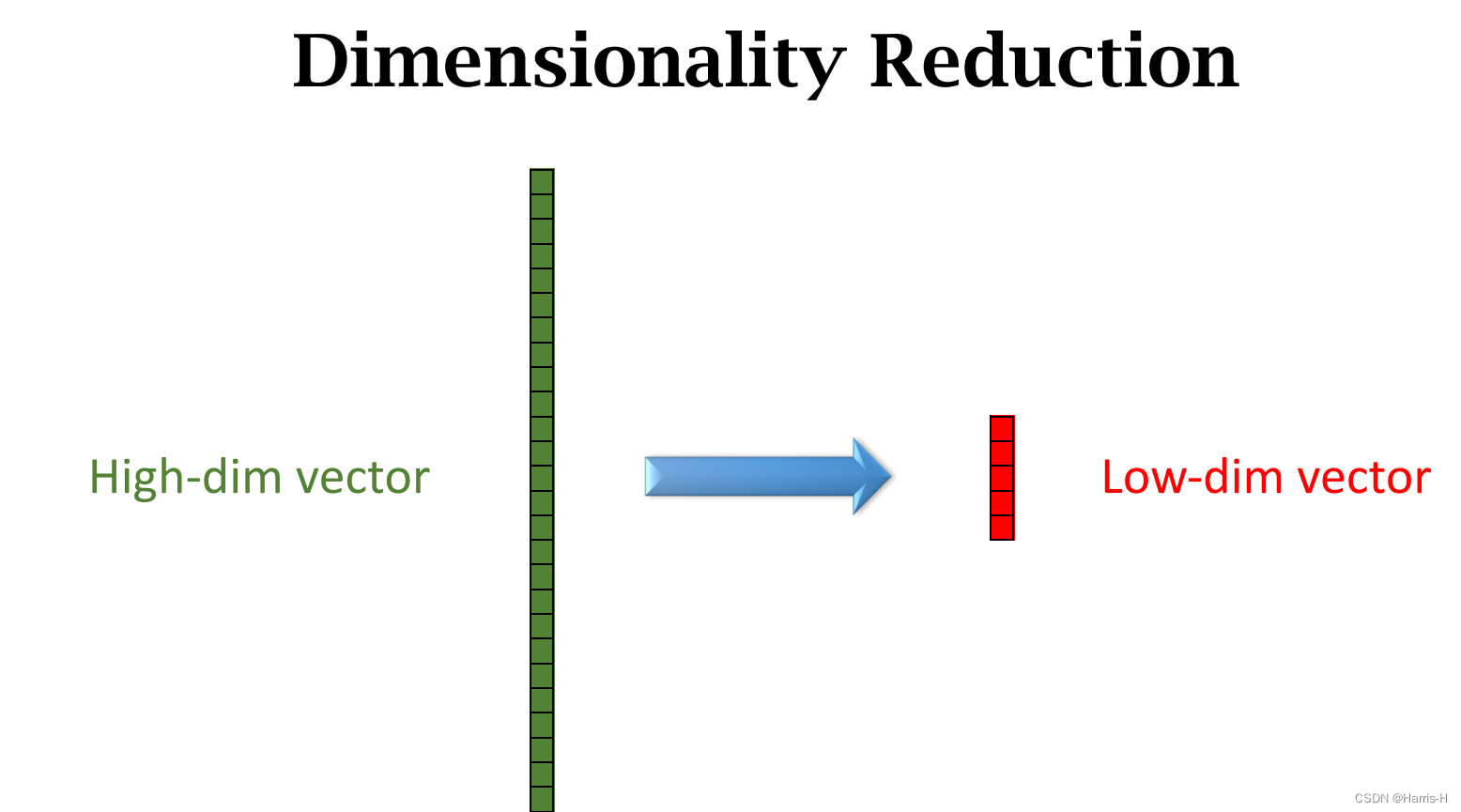

作用是:
1.可视化和分析。
2.数据处理,让下游的ML更加高效和准确。
常用的方法如上。
5.其他
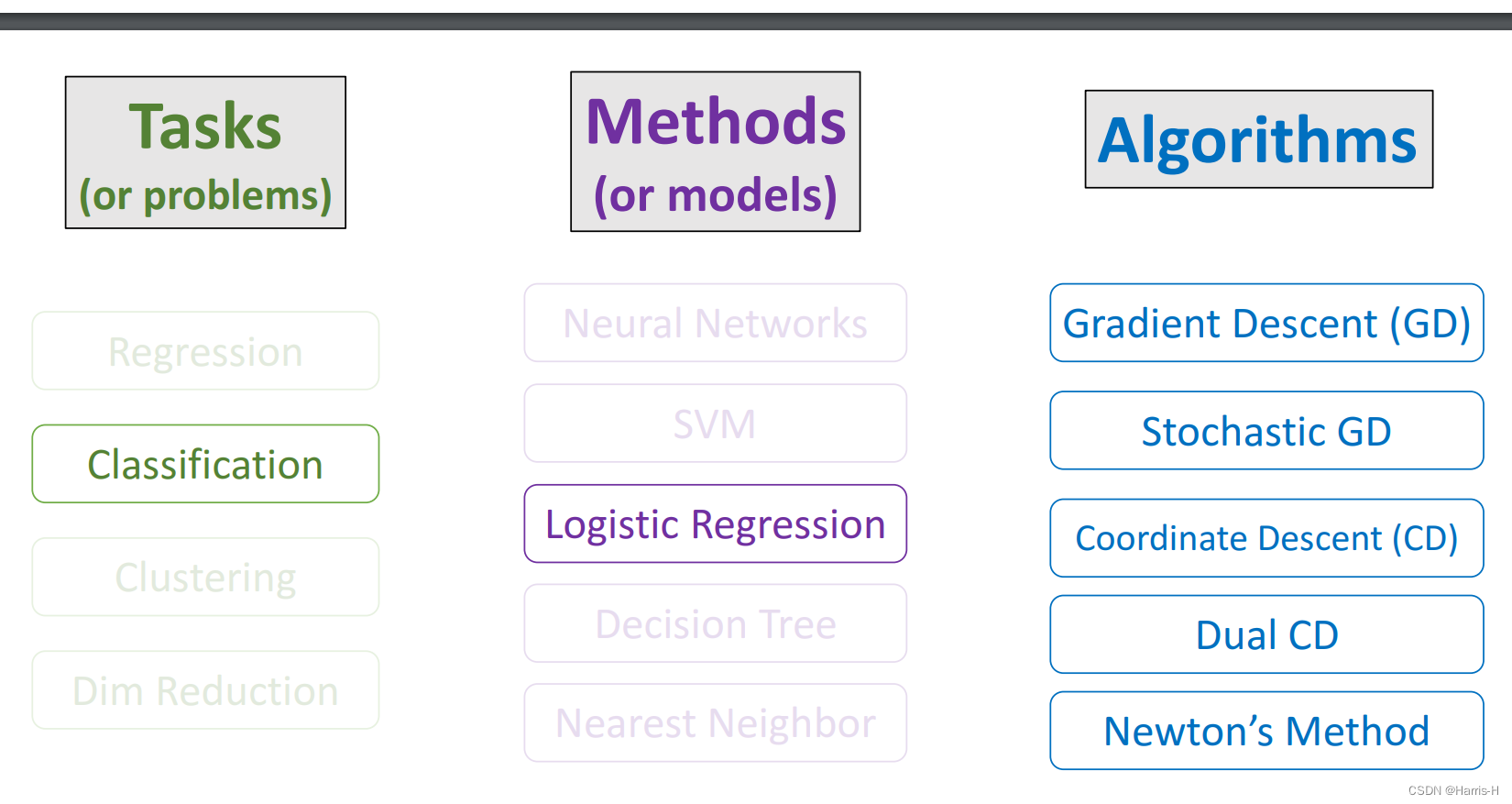
6.Tasks, Methods, & Algorithms
每个Tasks 都Methods和Algorithms
这里以分类为例。
-
相关阅读:
mac上的python2安装
c++ 容器适配器
无涯教程-JavaScript - CONVERT函数
相机以及其它传感器传感器
如何让虚拟角色自然融入现实?
Matlab中如何设置Scope
MongoDB常用命令总结及安装介绍
fegin调用关于session,请求头传递参数问题
ue4使用Niagara粒子实现下雨效果,使用蓝图调节雨量
【linux命令讲解大全】002. 使用locate更快速地查找文件
- 原文地址:https://blog.csdn.net/weixin_45750972/article/details/126924339