-
Redis缓存满了咋办?什么叫近似LRU算法?为啥不使用真实LRU?
Redis缓存满了怎么办?
那还用说吗,满了就删除一些旧数据不就有空间了嘛。只是不能瞎删,要遵循策略删。由此,就产生了下图所示的Redis内存淘汰策略:
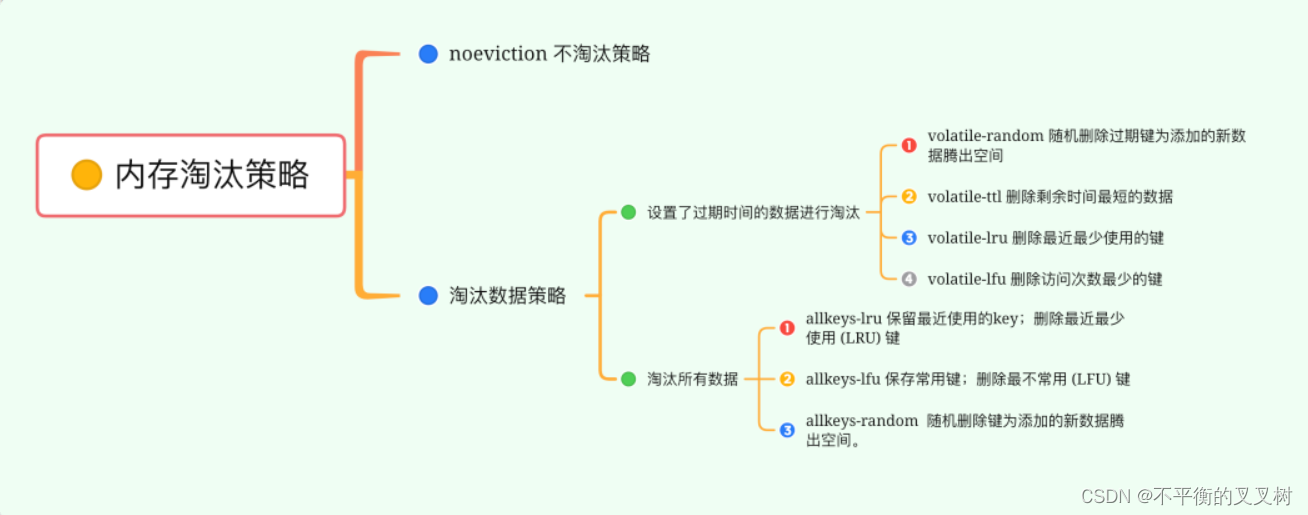
下面详细介绍一下Redis使用的LRU算法(近似)。
近似LRU算法
什么叫LRU算法呢?
LRU的全称是Least Recently Used,也就是 最近最少使用 策略,判断数据最近被使用的时间,距离目前时间最远的数据优先被淘汰,是根据访问时间来更改链表顺序从而实现缓存淘汰的算法。它的核心思想是:如果该数据最近被访问,那么将来被访问的几率也很高。
顺带一提LFU算法:全称是 Least Frequently Used,即 最近最不经常使用策略,在一段时间内,数据被使用频率最少的,优先被淘汰。
LRU强调的是访问时间,LFU强调的是访问频率。
为什么Redis使用的是近似LRU?
究其原因,最为关键的一点是:LRU算法需要用链表管理所有的数据,会造成大量额外的空间消耗。
除此之外,大量的节点被访问就会带来频繁的链表节点移动操作,从而降低了Redis性能。
经常使用的数据在链表的头部,冷数据在尾部,一旦链表容量不够(缓存空间满了),执行删除尾部策略。
所以Redis对该算法做了简化,Redis是通过对少量的key采样,然后淘汰样本数据中最久没有被访问过的key。这就意味着 Redis 很有可能无法淘汰数据库最久访问的数据。
Redis为了实现近似LRU算法,给每个key额外增加了一个24bit的字段,用来存储该key最后一次被访问的时间。
当然Redis 的LRU 算法可以更改样本数量来调整算法的精度,使其更加接近真实的LRU算法,同时又避免了内存的消耗,因为每次只需要采样少量样本,而不是缓存中所有的数据。
Redis 3.0对近似LRU的优化
Redis 3.0对近似LRU算法进行了一些优化。新算法会维护一个候选池(大小为16),池中的数据根据访问时间进行排序,第一次随机选取的key都会放入池中,随后每次随机选取的key只有在访问时间小于池中最小的时间才会放入池中,直到候选池被放满。当池放满后,如果有新的key需要放入,则将池中最后访问时间 最大(最近被访问)的移除。当需要淘汰的时候,则直接从池中选取最近访问时间最小(最久没被访问 )的key淘汰掉就行。也就是池中维护的是要被淘汰的数据。
-
相关阅读:
一分钟告诉你识别植物的软件哪个好?
一文概览NLP句法分析:从理论到PyTorch实战解读
32岁事业无成,我终于选择放过自己了
【Hack The Box】linux练习-- Delivery
Linux 文件、目录和用户权限管理指南
部署软件的 7 种最佳 CI/CD 管道模式
java easyexcel 导出多级表头
Gin框架源码解析
Laravel 6 - 第十五章 验证器
Java 复习笔记 - 常用API 上
- 原文地址:https://blog.csdn.net/NoviceZ/article/details/126865404