-
JVM调优工具使用
jps
查看启动的 java 进程

jmap
实例个数与内存占用
看内存信息,实例个数以及占用内存大小
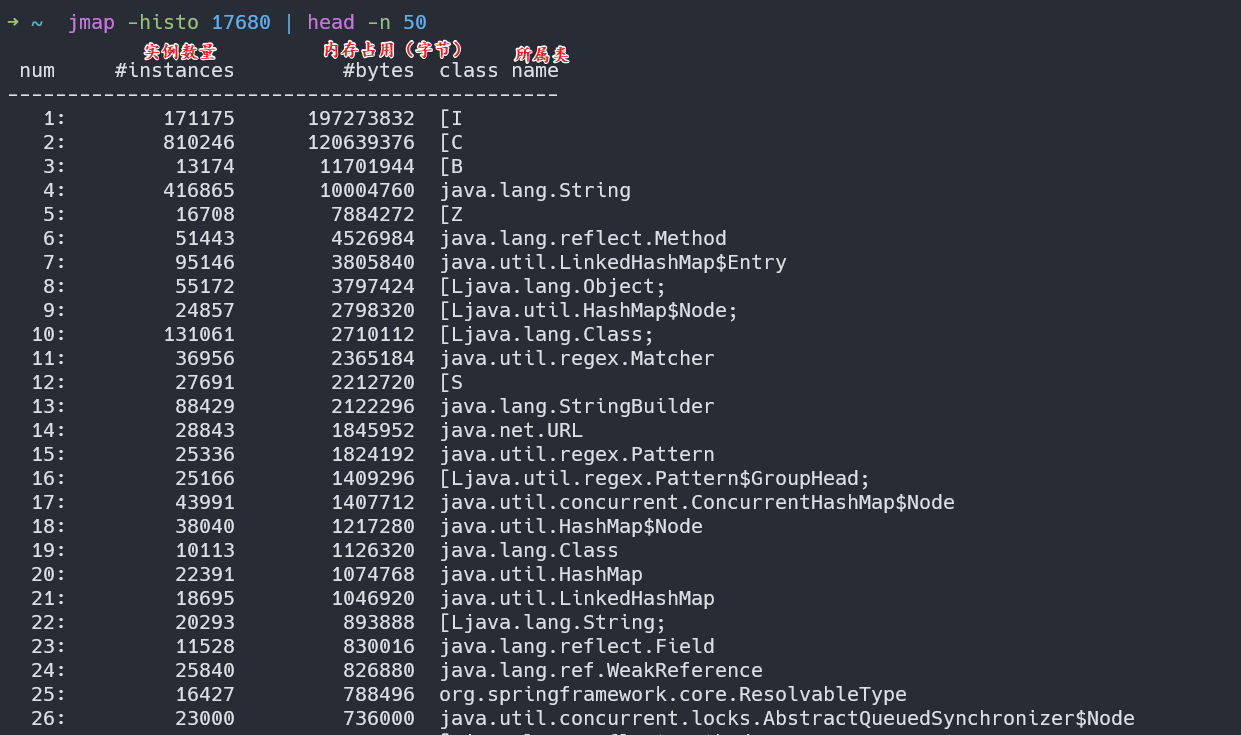
[C is a char[],[S is a short[],[I is a int[],[B is a byte[],[[I is a int[][]堆信息
jump -heap 17680

导出堆内存占用信息
jmap -dump:format=b,file=./j.hprof 17680导出是二进制,可以使用 jdk 自带的 jvisualvm.exe 导入查看


内存溢出时导出
通常设置内存溢出自动导出 dump 文件(内存很大的时候,可能会导不出来)
- -XX:+HeapDumpOnOutOfMemoryError
- -XX:HeapDumpPath=导出路径
Jstack
查找死锁
有如下示例会产生一个死锁:
package io.dc; public class DeadLockTest { private static Object lock1 = new Object(); private static Object lock2 = new Object(); public static void main(String[] args) { new Thread(() -> { synchronized (lock1) { try { System.out.println("thread1 begin"); Thread.sleep(5000); } catch (InterruptedException e) { } synchronized (lock2) { System.out.println("thread1 end"); } } }).start(); new Thread(() -> { synchronized (lock2) { try { System.out.println("thread2 begin"); Thread.sleep(5000); } catch (InterruptedException e) { } synchronized (lock1) { System.out.println("thread2 end"); } } }).start(); System.out.println("main thread end"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
可以使用
jstack PID查看:

直接可以定位到代码的大致位置
找出占用 CPU 最高的 java 线程信息
有如下程序会导致 cpu 飙升:
public class Math { public static final int initData = 666; public int compute() { int a = 1; int b = 2; int c = (a + b) * 10; return c; } public static void main(String[] args) { Math math = new Math(); while (true) { // 导致CPU飙升 math.compute(); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
在 Linux 使用
top命令,发现 java 进程 CPU 占用高:
使用
top -p 105654,然后按H, 查看这个进程的详细信息:

可以看到线程 105655 占用资源比较高,将 105655 转换成 16 进制: 19cb7
执行
jstack 105654 | grep -A 10 "19cb7"查看此线程的相关信息:
可以找到问题代码的大致位置
jinfo
查看正在运行的 java 程序的扩展参数
查看 jvm 使用的参数
jinfo -flags 105654- 1

查看 java 系统参数
jinfo -sysprops 105654- 1

jstat
可以查看堆内存各部分使用量,以及加载类的数量
使用方法:
jstat [-命令选项] [vmid] [间隔时间(毫秒)] [查询次数]
垃圾回收统计
jstat -gc PID- 1

- S0C:第一个幸存区的大小,单位 KB
- S1C:第二个幸存区的大小
- S0U:第一个幸存区的使用大小
- S1U:第二个幸存区的使用大小
- EC:伊甸园区的大小
- EU:伊甸园区的使用大小
- OC:老年代大小
- OU:老年代使用大小
- MC:方法区大小(元空间)
- MU:方法区使用大小
- CCSC: 压缩类空间大小
- CCSU: 压缩类空间使用大小
- YGC:年轻代垃圾回收次数
- YGCT:年轻代垃圾回收消耗时间,单位 s
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间,单位 s
- GCT:垃圾回收消耗总时间,单位 s
堆内存统计
jstat -gccapacity PID- 1

- NGCMN:新生代最小容量
- NGCMX:新生代最大容量
- NGC:当前新生代容量
- S0C:第一个幸存区大小
- S1C:第二个幸存区的大小
- EC:伊甸园区的大小
- OGCMN:老年代最小容量
- OGCMX:老年代最大容量
- OGC:当前老年代大小
- OC: 当前老年代大小
- MCMN: 最小元数据容量
- MCMX:最大元数据容量
- MC:当前元数据空间大小
- CCSMN:最小压缩类空间大小
- CCSMX:最大压缩类空间大小
- CCSC:当前压缩类空间大小
- YGC:年轻代 gc 次数
- FGC:老年代 GC 次数
新生代垃圾回收器情况
jstat -gcnew PID- 1

- S0C:第一个幸存区的大小
- S1C:第二个幸存区的大小
- S0U:第一个幸存区的使用大小
- S1U:第二个幸存区的使用大小
- TT: 对象在新生代存活的次数
- MTT: 对象在新生代存活的最大次数
- DSS: 期望的幸存区大小
- EC:伊甸园区的大小
- EU:伊甸园区的使用大小
- YGC:年轻代垃圾回收次数
- YGCT:年轻代垃圾回收消耗时间
新生代内存统计
jstat -gcnewcapacity PID- 1

- NGCMN:新生代最小容量
- NGCMX:新生代最大容量
- NGC:当前新生代容量
- S0CMX:最大幸存 1 区大小
- S0C:当前幸存 1 区大小
- S1CMX:最大幸存 2 区大小
- S1C:当前幸存 2 区大小
- ECMX:最大伊甸园区大小
- EC:当前伊甸园区大小
- YGC:年轻代垃圾回收次数
- FGC:老年代回收次数
老年代垃圾统计
jstat -gcold PID- 1

- MC:方法区大小
- MU:方法区使用大小
- CCSC: 压缩类空间大小
- CCSU: 压缩类空间使用大小
- OC:老年代大小
- OU:老年代使用大小
- YGC:年轻代垃圾回收次数
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间
老年代堆内存统计
jstat -gcoldcapacity PID- 1

- OGCMN:老年代最小容量
- OGCMX:老年代最大容量
- OGC:当前老年代大小
- OC:老年代大小
- YGC:年轻代垃圾回收次数
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间
元空间统计
jstat -gcmetacapacity PID- 1

- MCMN: 最小元数据容量
- MCMX:最大元数据容量
- MC:当前元数据空间大小
- CCSMN:最小压缩类空间大小
- CCSMX:最大压缩类空间大小
- CCSC:当前压缩类空间大小
- YGC:年轻代垃圾回收次数
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间
jstat -gcutil PID- 1

JVM 运行情况预估
知道了如何统计 jvm 运行的信息,就可以根据现有的信息预估以后程序占用资源的走向,从而调整合理的 jvm 参数,比如: 堆内存大小,年轻代,老年代大小, Eden 和 Survivor 的比例,大对象的阀值,进入老年代年龄的阀值等
年轻代对象增长速率
可以执行
jstat -gc PID 1000 20观察 EU 区估算每秒新增多少对象,一般系统又高峰期和非高峰期,需要在不同时间段分别统计Young GC 触发频率和每次耗时
知道年轻代对象的增长速率,可以预估 Young GC 多久触发一次,Young GC 的平均耗时可以 YGCT / YGC 算出,这两个结果可以知道系统大概多久系统会因为 Young GC 卡顿多久
Young GC 后,存活的对象和进入老年代对象的数量
每次 GC 后,Eden 区会大幅度减少,survivor 和老年代都会有增长,这些增长的对象就是 Young GC 后存活的对象,同时还可以看出每次进入老年代的对象,这就是老年代对象的增长速率
Full GC 的触发频率和平均耗时
知道了老年代的增长速率,就可以估算出 Full GC 的触发频率了,每次耗时可以通过 FGCT / FGC 算出
优化思路
尽量让每次 Young GC 之后的存活对象小于 Survivor 区域的 50%,尽量别让对象进入老年代,尽量减少 Full GC 的频率,避免频繁 Full GC 堆 jvm 性能的影响
一种解决频繁 Full GC 的思路
一般是频繁创建大对象,导致老年代的占用极速增加,这部分代码可能占用 CPU 比较高。
- 可以通过 jmap 找到实例数量靠前的对象,在代码中搜索新建这个对象的位置
- 通过上面说的 top + jstack 的方式找到占用 CPU 资源比较多的线程,再定位具体位置
内存泄漏的案例
一般电商架构可能会使用多级缓存架构,就是redis加上JVM级缓存,大多数同学可能为了图方便对于JVM级缓存就 简单使用一个hashmap,于是不断往里面放缓存数据,但是很少考虑这个map的容量问题,结果这个缓存map越来越大,一直占用着老 年代的很多空间,时间长了就会导致full gc非常频繁,这就是一种内存泄漏,对于一些老旧数据没有及时清理导致一直占用着宝贵的内存 资源,时间长了除了导致full gc,还有可能导致OOM。 这种情况完全可以考虑采用一些成熟的JVM级缓存框架来解决,比如ehcache等自带一些LRU数据淘汰算法的框架来作为JVM级的缓存
高级工具 Arthas
Arthas 是 Alibaba 在 2018 年 9 月开源的 Java 诊断工具。支持 JDK6+, 采用命令行交互模式,可以方便的定位和诊断 线上程序运行问题。Arthas 官方文档十分详细 https://arthas.aliyun.com/doc/manual-install.html?userCode=okjhlpr5
-
相关阅读:
Kafka安装与使用
android 点9记录
计算机毕业设计ssm宠物寄养管理系统41n70系统+程序+源码+lw+远程部署
小程序生成分享海报图片并保存相册
工业物联网解决方案:PLC数据上云
unity学习(59)——选择角色界面--MapHandler1
遨博机械臂URDF功能包ROS仿真
HCNP Routing&Switching之MAC地址防漂移
串口通信-USART和UART的区别
基于Levenberg-Marquardt算法的声源定位matlab仿真
- 原文地址:https://blog.csdn.net/a141210104/article/details/126820552