-
webpack原理-webpack5内部分包原理解析
theme: fancy
开场白
大家好,我是Webpack,AKA打包老炮,我的slogan是:“打天下的包,让Rollup无包可打”。
今天我要带来的才艺是:解析webpack5内部的分包规则,也就是ChunkGraph- 1
如果还没看过这篇文章的话,建议先读完再看这里。
webpack原理解析【长文万字】
webpack原理 - ModuleGraph原理本文从以下几个问题依次解答剖析webpack内部的分包规则:
- 1:webpack分包规则与ChunkGraph的关系
- 2:ChunGraph长什么样子?
- 3:ChunkGraph构建的过程?
webpack分包规则与ChunkGraph的关系
你可以简单的认为ChunkGraph就等于webpack的分包规则!
这句话有点简单,但这么理解完全没问题。我们都知道chunk往往都是一一对应产物【bundle】,那么一个程序往往不是只有一个chunk,一般来说我们配置多个入口文件,就会产生多个chunk;多个异步引入模块,也会产生多个chunk。那么问题就来了,你知道这些逻辑在webpack的内部是如何实现的吗?webpack又是如何设计这些对象的?
如果你看过往期文章,知道了ModuleGraph是以module为中心描绘module之间关系的对象。那么对应的:ChunkGraph就是以chunk为中心描绘chunk与module关系对象。
在讨论ChunkGraph之前,希望能够先想象一下这样一个场景:
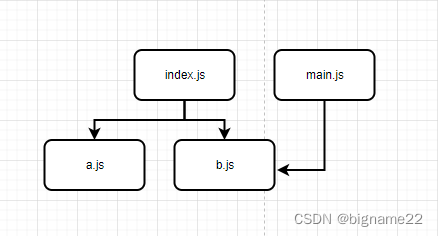
入口文件1index.js,引用了a.js、b.js;入口文件2main.js,引用了b.js。这样的结构打包出来的chunk会是什么样的呢?- 1
根据你的经验,你可能马上想到了,这样打包出来的chunk有两个:
- chunk-index[a.js, b.js]
- chunk-main[b.js]
没有错,事实也是如此。但是你理解webpack构建出来这两个chunk的原理吗?
另外,这个b.js被两个chunk引用你可能马上也想到了通过配置SplitChunkPlugin将b.js打包到新的chunk以减小包体积的问题。 - chunk-b[b.js]
那SplitChunkGraph又是如何去完成上述这个功能的呢?【SplitChunkPlugin的原理我们留到以后再出文章去解析】
这里我们可以简单理解为SplitChunkPlugin也是通过改写ChunkGraph对象内部数据来实现的。
所以学习ChunkGraph的原理除了面试时跟面试官battle外,也有助于你更加好的去优化你的项目构建速度、减小包体积的问题。
ChunkGraph长什么样子?
在想webpack怎么实现之前先思考如果是我们来实现ChunkGraph的话,我们该如何设计呢?
在开始阅读webpack5的源码之前我也问过自己这个问题。我的想法是ChunkGraph核心记录的信息应该是:- 有哪些chunk,chunk里面有哪些module
- 有哪些module,module属于哪些chunk
有了这样的信息就能够清楚的表达chunk与module的关系了。也方便分包优化的操作。
所以必然的,要有一个放chunk列表的变量【chunks】;也要有一个放module列表的变量【modules】。
事实上当我打开webpack内部源码的时候,也发现了这样的变量。但不同的是,chunks不是一个数组而是一个Map
但问题不大
- chunks:Map
- modules:Map
所以,带着这样的思路去有助于阅读webpack的源码
ChunkGraph的核心:
- 有哪些chunk,chunk里面有哪些module
- 有哪些module,module属于哪些chunk
ChunkGraph的庐山真面目
至此,正式揭开ChunkGraph的真实面目:

这里面除了ChunGraph对象,还有
ChunkGraphChunk:记录一个chunk有哪些module
ChunkGraphModule:记录一个module属于哪些chunk。就好像b.js 既属于chunk-index, 又属于chunk-main。接下来我们剖析源码分析,上图的数据是如何收集构建出来的【主要是关注ChunkGraph的_modules、_chunks是如何添加进来数据的】。
ChunkGraph构建的过程?
ChunkGraph构建发生在webpack的seal函数内;
大致可以分为两个阶段:- 初始化入口ChunkGraph
- 构建完整chunkGraph
初始化入口ChunkGraph
这个阶段的代码比较简单。可以总结为以下步骤
- 遍历入口
- 创建入口chunk,关联chunk和chunkGrorup关系
- 遍历入口的module
- 设置chunkGraph的_modules,_chunks值【收集ChunkGraph的_modules中的entryModules, _chunks中的entryInChunks】
- 设置chunkGraphInit值
tips: 简单一句话总结:创建入口chunk,绑定入口module与chunk的关系,设置chunkGraphInit值。

对应源码也贴一下。

细心地你可能已经找到了一个入口对应一个chunk的原因了。在上述的流程中仅仅是入口chunk,入口module做了处理。
所以说这个阶段叫:初始化入口ChunkGraph。
chunkGraphInit数据是为了构建完整chunkGraph提供一个起点数据,在下一阶段会从这个起点不断摸索其他module与chunk的关系。看看真实数据长什么样子,来帮助下我们更好的理解该阶段
假设当前的module依赖关系:
那么此时chunkGraphInit的数据设置成了这个样子:
chunkGraphInit: Map{ {chunkGroup-index, [module-index]}, {chunkGroup-main, [module-main] }, }- 1
- 2
- 3
- 4
此时chunkGraph内部_modules、_chunks内部数据是这个样子的
_modules: Map{ < module-index, chunkGraphModule:{ chunks: [], entryInChunks: [chunk-index] } >, < module-main, chunkGraphModule:{ chunks: [], entryInChunks: [chunk-main] } >, }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
_chunks: Map{ < chunk-index, chunkGraphChunk:{ modules: [], entreyModules: [module-index] } >, < chunk-main, chunkGraphChunk:{ modules: [], entreyModules: [module-main] } >, }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
再补充一个知识:chunkGroup【给chunk分组的对象。为什么要给chunk分组这是一个值得思考的问题?以后有机会再出个文章分析一下】
此时的Compilation中chunkGroups的数据chunkGroups: [ chunkGroup-index:{ chunks: [chunk-index], _children: [], _parents: [], }, chunkGroup-main: { chunks: [chunk-main], _children: [], _parents: [], } ]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
有了起点数据后,此时将进入下一个阶段…
构建完整chunkGraph
这个阶段也可以叫:通过入口拓展来完善ChunkGraph。
前面我们已经得到了两个非常重要的数据:
chunkGraphInit: Map{ <chunkGroup-index, [module-index]>, <chunkGroup-main, [module-main]>, }- 1
- 2
- 3
- 4
```javascript // ChunkGraph的属性 _modules: Map{ < module-index, chunkGraphModule:{ chunks: [], entryInChunks: [chunk-index] } >, < module-main, chunkGraphModule:{ chunks: [], entryInChunks: [chunk-main] } >, } _chunks: Map{ < chunk-index, chunkGraphChunk:{ modules: [], entreyModules: [module-index] } >, < chunk-main, chunkGraphChunk:{ modules: [], entreyModules: [module-main] } >, }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
聪明伶俐的你,已经想到接下来就是通过入口module顺藤摸瓜找到其他module添加进chunk中,并且module也记录着他属于哪些chunk的信息收集过程。也就是ChunkGraph的信息不断在完善的过程。
接下来从源码的角度来解析这一过程的实现原理,完成该功能的核心函数buildChunGraph(Compilation, chunkGraphInit)。一起来看看buildChunkGraph函数都干了些啥吧。

内部调用visitModules()函数开始对module顺藤摸瓜:visitModules()函数内部定义了queue队列,遍历chunkGraphInit中的入口modules,将moduel转换为queueItem压入到队列中【此时的queueItem的action=1,action控制着queueItem的处理流程】。
此时的queueItem是有了module与chunk等关键信息的了。

此时遍历queue队列,弹出queueItem处理,处理queueItem的过程相对繁琐。大致可总结为:- 调用chunkGraph.connectChunkAndModule(chunk, module)【构建ChunkGraph的_modules、_chunks信息(即确定了module属于哪些chunk,chunk有哪些module)】
- 将queueItem的action改为5,重新压回到queueItem
- 找到module引入了哪些module,转化为queueItem【action=1】,再压入到queue队列中
简单总结:从入口module开始,找到依赖的modules不断压入到队列中去处理。直到最后没有了新的依赖module压入队列。
用一个流程图来更好的理解这一过程:
tips: 当有异步依赖的时候才会走action=4

处理queueItem的那块代码也贴出来看看,非常值得学习的一种控制逻辑设计:

上面这部分逻辑很难消化,因为确实看的时候感到有点吃力。但是当我们去描绘出queue队列在处理过程中如何变化的时候,感觉又好理解了许多。
下面以这个依赖结构为例子,我们来看看queue的数据变化情况:

来看看queue一开始只以入口module转化为queueItem【此时的queueItem的action=1】的情况吧:

此时的queue只有两个消息:queue: [ queue-app:{action:1 ...}, queue-index:{action:1 ...}, ]- 1
- 2
- 3
- 4
然后弹出queue-index,此时queue只剩下queue-app:
queue: [ queue-app:{action:1 ...}, ]- 1
- 2
- 3
然后开始处理queue-index:
- 将module-index, chunk-index添加进chunkGraph的_modules,_chunks
- 将弹出的queue-index的action设为5,然后重新压入queue
此时queue队列的数据:
queue: [ queue-app:{action:1 ...}, queue-index:{action:5 ...}, ]- 1
- 2
- 3
- 4
继续处理queue-index:
- 找到module-index的依赖 module-a 、 module-b。转化为queueItem【action=1】并压入队列
此时queue队列的数据:
queue: [ queue-app:{action:1 ...}, queue-index:{action:5 ...}, queue-b:{action:1 ...}, queue-a:{action:1 ...}, ]- 1
- 2
- 3
- 4
- 5
- 6
到这里对queue-index的处理已经完成。
接着回到循环,弹出队列queue-a,
然后开始处理queue-a:- 将module-a, chunk-a添加进chunkGraph的_modules,_chunks
- 将弹出的queue-a的action设为5,然后重新压入queue
此时queue队列的数据:
queue: [ queue-app:{action:1 ...}, queue-index:{action:5 ...}, queue-b:{action:1 ...}, queue-a:{action:5 ...}, ]- 1
- 2
- 3
- 4
- 5
- 6
…这里就不凑字数了,queue-a又找到了module-a1,又压入队列…
action等于5的时候就有给队列添加的可能了,所以queue最终会被全部消费掉。
这里直接放一张整理过程中的笔记,略显凌乱。但还是有用的:

时光飞逝,到这一步ChunkGraph已经将所有的module都分配到对应的chunk。但关于分包的逻辑此时还没结束,因为还有个令人又爱又恨的SplitChunkPlugin插件,它会对目前的ChunkGraph再进一步优化,这个分包插件在webpack4开始内置支持!配置好SplitChunkPlugin一定能让你的项目更上一层楼。
下一篇文章准备写关于SplitChunkPlugin插件优化分包的原理。又是难啃的一篇文章。
文章结尾分享一下关于阅读源码的一些心得:- 1
- 抓住重点,别被带偏: 源码中会有很对属性函数会让你看的一头雾水,切记分清主次,把时间集中在核心代码中。可以去参考其他优秀的文章提到的流程、函数。帮助自己找到核心代码!
- 画流程图,整理流程: 边看边画,有效避免看了东忘了西的尴尬场面,浪费时间回头再看
- 看数据源: 有些关键的对象/属性如ChunkGraph、ChunkModule、Compilation、Module等,在调试的时候可以查看这些对象真实记录的数据,有助于理解该对象,并且能够反推一些复杂的函数的逻辑作用。
感谢阅读~ 能坚持看到这里的看官点赞支持一下吧!❤❤❤❤❤
-
相关阅读:
基于 Serverless 架构的 CI/CD 框架:Serverless-cd
阿里云函数计算 GPU 宣布降价,最高幅度达 93%,阶梯计费越用越便宜!
双非渣本,奋斗3年,阿里四面终拿Offer,定级p6
Java2EE基础练习及面试题_chapter05面向对象(中_03)
java的io流详解
探索JDK8新特性,Stream 流:构建流的多种方式
接口回调中的次数判断方法
《web课程设计》用HTML CSS做一个简洁、漂亮的个人博客网站
10个Golang 数据库最佳实践
卸载重装最新版mysql数据库亲测有效
- 原文地址:https://blog.csdn.net/bigname22/article/details/126669842
