-
Proximal Policy Optimization Algorithms
本文提出一种新的强化学习策略梯度方法族,通过与环境的交互在采样数据之间交替进行,并使用随机梯度上升优化"替代"目标函数。标准策略梯度方法对每个数据样本执行一次梯度更新,本文提出一种新的目标函数,使多个小批量更新阶段成为可能。这些新方法称为近端策略优化(proximal policy optimization, PPO),具有信赖域策略优化(trust region policy optimization, TRPO)的一些优点,但它们实现起来更简单,更通用,并且具有更好的样本复杂度(经验上)。实验在一组基准任务上测试了PPO,包括模拟机器人运动和Atari游戏,PPO优于其他在线策略梯度方法,总体上在样本复杂性、简单性和wtime之间取得了良好的平衡。
背景:1)信赖域策略优化(trust region policy optimization, TRPO)相对复杂,与包含噪声(如dropout)或参数共享(策略和值函数之间,或与辅助任务)的架构不兼容。
2)为了优化策略,我们轮流从策略中采样数据,并对采样数据执行多个时段的优化。
2.1 Policy Gradient Methods


2.2 Trust Region Methods


3 Clipped Surrogate Objective
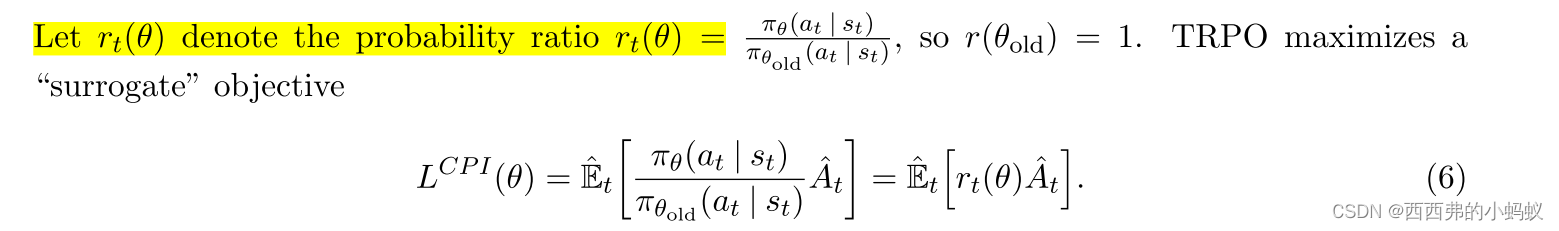
上标CPI为保守策略迭代[KL02],提出了该目标


4 Adaptive KL Penalty Coefficient
另一种方法是对KL散度进行惩罚,并对惩罚系数进行调整,以便每次策略更新时都达到KL散度dtarg的某个目标值。这种方法可以作为截断代理目标的替代或补充。我们发现KL惩罚比裁剪替代目标表现更差,但是,我们在这里包括它,因为它是一个重要的基线。

5 Algorithm




7结论
我们介绍了近端策略优化,这是一种策略优化方法族,使用随机梯度上升的多个时期来执行每次策略更新。这些方法具有信任域方法的稳定性和可靠性,但实现起来要简单得多,只需要对普通策略梯度实现进行几行代码更改,适用于更一般的情况(例如,当为策略和值函数使用联合架构时),并且具有更好的整体性能。
-
相关阅读:
算法入门01二维数组中的查找
python接口自动化测试 之mock模块基本使用介绍
【精华系列】跟着Token学习数据挖掘-1
神经网络参数研究方法,神经网络参数研究方向
【OpenCV 例程 300篇】242. 加速稳健特征检测算法(SURF)
【图像分割】基于萤火虫算法实现图像分割附matlab代码
OFDM信号的时移特性(非整数采样点时移)
css高级 使用
「科技与安全」RK3568J核心板让隔离网闸更强大
如何安装Docker桌面版到Windows系统上
- 原文地址:https://blog.csdn.net/zj_18706809267/article/details/126679673