-
word2vec中的skip-gram--学习笔记
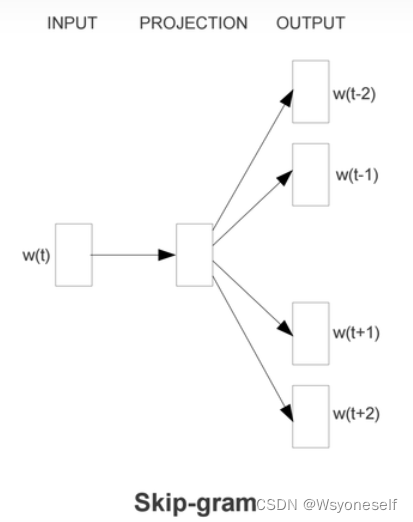
- skip-gram:
- 如果两个不同的单词有着非常相似的“上下文”,则通过模型训练,两个单词的嵌入向量将非常相似。且隐含帮助词干化(去除词缀得到词根的过程)
- 一些优化:
- 将常见的单词组合或词组作为单个“words”来处理: 一些单词组合的含义和拆开不一样,简单处理只要一起出现就当做一个单独的词
- 对高频次单词进行抽样来减少训练样本个数:具体:在训练原始文本中遇到的每一个单词,都有一定概率被从文本中删掉,被删掉的概率与单词的频率有关
- 对优化目标采用“negative sampling”方法,这样每个训练样本的训练只会更新一小部分的模型权重,从而降低计算负担。
- negative sampling:负采样,不同于原本每个训练样本更新所有的权重,负采样每次让一个训练样本仅仅更新一小部分的权重,这样就会降低梯度下降过程中的计算量。
- 更新随机选择的一部分word以及input word对应的权重进行更新,选择:一个单词被选作negative sample的概率跟它出现的频次有关,出现频次越高的单词越容易被选作negative words。负采样概率*1亿=单词在表中出现的次数。
- 训练模型:通过给神经网络输入文本中成对的单词来训练完成相关性概率计算。

- word2vec:通过一个embedding空间使得语义上相似的单词在该空间内距离很近。
- skip-gram是给定input word 来预测上下文。CBOW是给定上下文预测input word
- 训练网络的方法抽象:
- 整个建模过程实际与自动编码器的思想很相似:先基于训练数据构建一个神经网络,真正需要的是这个模型通过训练数据所学的参数,如隐层的权重矩阵。
- 该方法实际会在无监督特征学习中使用,常见的如自编码器,通过在隐层将输入进行编码压缩,输出层将数据解码恢复初始状态,训练完成后,将输出层砍掉,仅保留隐层。基于成对的单词来对神经网络进行训练,训练样本是 ( input word, output word ) 这样的单词对,input word和output word都是one-hot编码的向量。最终模型的输出是一个概率分布。
- skip-gram:
-
相关阅读:
升级打怪拿offer,10w+字总结的Java面试题(附答案)够你刷
Shell系统学习之Shell条件测试,判断语句和运算符
入栏需看——学习记忆
z—libirary最新地址获取,zlibirary地址获取方式,zliabary最新地址,zliabary官网登录方式,zliabary最新登陆
JavaSE学习——网络编程
我的私人笔记(zookeeper分布式安装)
SpringBoot缓存
mysql学习笔记-底层原理详解
Effectively Learning Spatial Indices(VLDB)
【Linux】进程概念 —— 孤儿进程与进程优先级
- 原文地址:https://blog.csdn.net/weixin_45647721/article/details/126586865