-
第05章 深度卷积神经网络模型
序言
1. 内容介绍
本章介绍深度学习算法-卷积神经网络用于 图片分类 的应用,主要介绍主流深度卷积神经网络 (CNN) 模型,包括 ResNet DenseNet SeNet 的算法模型、数学推理、模型实现 以及 PyTorch框架 的实现。并能够把它应用于现实世界的 数据集 实现分类效果。
2. 理论目标
- ResNet 的基础模型架构、训练细节与数学推理
- DenseNet 的基础模型架构、训练细节与数学推理
- SeNet 的基础模型架构、训练细节与数学推理
3. 实践目标
- 掌握PyTorch框架下ResNet DenseNet SeNet的实现
- 掌握迁移学习与特征提取
- 熟悉各经典算法在图像分类应用上的优缺点
4. 实践数据集
- Flower 数据集分类
- Oxford-IIIT 数据集分类
- CIFAR-10 数据集分类
5. 内容目录
- 1.卷积神经网络模型详解 ResNet
- 2.卷积神经网络模型详解 DenseNet
- 3.PyTorch 实践
- 4.图像分类实例 Flower 数据集
- 5.图像分类实例 Oxford-IIIT 数据集
- 6.图像分类实例 CIFAR-10 数据集
第1节 卷积神经网络模型 ResNet
1.1 ResNet 简介
ResNet 残差神经网络是由微软研究院的何恺明、张祥雨、任少卿、孙剑等人提出,以一种残差学习框架来解决 网络退化 问题,从而训练更深的网络。这种框架可以结合已有的各种网络结构,充分发挥二者的优势。在 ImageNet 分类数据集中,拥有152层的残差网络,以 3.75% top-5 的错误率获得了ILSVRC 2015 分类比赛的冠军。同时很多证据表明残差学习是通用的,不仅可以应用于视觉问题,也可应用于非视觉问题。
ResNet 的主要贡献是发现了退化现象(Degradation),并针对退化现象发明了快捷连接 (Shortcut connection),极大的消除了深度过大的神经网络训练困难问题。神经网络的深度首次突破了100层、最大的神经网络甚至超过了1000层。ResNet以三种方式挑战了传统的神经网络架构:
-
ResNet 通过引入 快捷连接 来绕过残差层,这允许数据直接流向任何后续层。这与传统的、顺序的 pipeline 形成鲜明对比:传统的架构中,网络依次处理低级feature 到高级feature 。
-
ResNet 的 层数 非常深,最高达1202层。而 ALexNet 这样的架构,网络层数要小两个量级
-
ResNet 中去掉单个层并不会影响其预测性能。而训练好的 AlexNet 等网络中,移除层会导致预测性能损失
1.2 网络退化问题
学习更深的网络的一个障碍是 梯度消失 与 梯度爆炸,该问题可以通过Batch Normalization 在很大程度上解决。但 ResNet 作者 何凯明 发现随着网络的深度的增加,准确率达到饱和之后迅速下降,而这种下降不是由过拟合引起的,这称作网络退化问题。如果更深的网络训练误差更大,则说明是由于优化算法引起的,即越深的网络,求解优化问题越难。如下所示更深的网络导致更高的训练误差和测试误差

这个现象与 “越深的网络准确率越高的信念” 显然是矛盾的、冲突的。理论上讲,较深的模型不应该比和它对应的、较浅的模型更差。因为较深的模型是较浅的模型的超空间。较深的模型可以通过先构建较浅的模型,然后添加很多恒等映射的网络层。但实际上我们的较深的模型后面添加的不是恒等映射,而是一些 非线性层。
ResNet 团队把退化现象归因为深层神经网络难以实现 恒等变换 (y=x), 同时表明通过多个非线性层来近似横等映射可能是困难的。于是,ResNet 团队在残差网络模块中增加了快捷连接分支,在 线性转换和非线性转换 之间寻求一个平衡,以解决网络退化问题。
1.3 ResNet 模型结构
假设需要学习的是映射 \vec{y} = H(\vec{x})y=H(x) ,残差块使用堆叠的非线性层拟合残差:\vec{y} = F(\vec{x}, W_i) + \vec{x}y=F(x,Wi)+x , 其中
-
\vec{x}x 和 \vec{y}y 是块的输入和输出向量
-
F(\vec{x}, W_i)F(x,Wi) 是要学习的残差映射。因为 F(\vec{x}, W_i) = H(\vec{x}) - \vec{x}F(x,Wi)=H(x)−x ,因此称 FF 为残差
-
通过 快捷连接 (shortcut) 逐个元素相加来执行。快捷连接 指的是那些跳过一层或者更多层的连接
- 快捷连接简单的执行恒等映射,并将其输出添加到堆叠层的输出
- 快捷连接既不增加额外的参数,也不增加计算复杂度
- 相加之后通过非线性激活函数,这可以视作对整个残差块添加非线性,即 relu(\vec{y})relu(y)
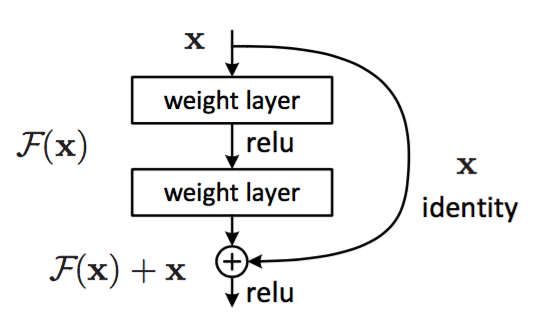
残差块隐含了一个假设:F(\vec{x}, W_i)F(x,Wi) 和 \vec{x}x 的维度相等。如果它们的维度不等,则需要在快捷连接中对 \vec{x}x 执行线性投影来匹配维度:\vec{y} = F(\vec{x}, W_i) + W_s\vec{x}y=F(x,Wi)+Wsx , 事实上当它们维度相等时,也可以执行线性变换。但是实践表明使用 恒等映射足以解决退化问题 ,而使用线性投影会增加参数和计算复杂度。因此 W_sWs 仅在匹配维度时使用
残差函数 FF 的形式是可变的
-
层数可变:论文中的实验包含有两层堆叠、三层堆叠,实际任务中也可以包含更多层的堆叠。如果 FF 只有一层,则残差块退化线性层为 \vec{y} = W\vec{x} + \vec{x}y=Wx+x
-
连接形式可变:不仅可用于全连接层,也可用于卷积层。此时 FF 代表多个卷积层的堆叠,而最终的逐元素加法 ++ 在两个 feature map 上逐通道进行

残差学习成功的原因:学习残差 F(\vec{x}, W_i)F(x,Wi) 比学习原始映射 H(\vec{x})H(x) 要更 容易
-
当原始映射 HH 就是一个恒等映射时,FF 就是一个零映射。此时求解器只需要简单的将堆叠的非线性连接的权重推向零即可。实际任务中原始映射 HH 可能不是一个恒等映射:
- 如果原始映射 HH 更偏向于恒等映射(而不是更偏向于非恒等映射),则 FF 就是关于恒等映射的抖动,会更容易学习
- 如果原始映射 HH 更偏向于零映射,那么学习 HH 本身要更容易。但是在实际应用中,零映射非常少见,因为它会导致输出全为0
-
如果原始映射 HH 是一个非恒等映射,则可以考虑对残差模块使用缩放因子。如 Inception-Resnet 中在残差模块与快捷连接叠加之前,对残差进行缩放
-
可以通过观察残差 FF 的输出来判断:如果 FF 的输出均为 0 附近的、较小的数,则说明原始映射 HH 更偏向于恒等映射;否则,说明原始映射 HH 更偏向于非横等映射
Plain 网络为一些简单网络结构的叠加,如下图中给出了四种 Plain 网络,它们的区别主要是网络深度不同。其中,输入图片尺寸均为 224\times224224×224
ResNet 简单的在 Plain 网络上添加快捷连接来实现

FLOPs:floating point operations 的缩写,意思是浮点运算量,用于衡量算法/模型的复杂度
FLOPS:floating point per second的缩写,意思是每秒浮点运算次数,用于衡量计算速度
相对于输入的 feature map,残差块的输出 feature map 尺寸可能会发生变化
- 输出 feature map 的通道数增加, 此时需要 扩充 快捷连接的输出 feature map, 否则快捷连接的输出 feature map 无法和残差块的 feature map 累加
- 直接通过 0 来填充需要扩充的维度,在图中以实线标识
- 通过1x1 卷积来扩充维度,在图中以虚线标识
- 输出 feature map 的尺寸减半, 此时需要对快捷连接执行步长为 2 的 池化/卷积 :如果快捷连接已经采用 1\times11×1 卷积,则该卷积步长为 2 ;否则采用步长为 2 的最大池化
1.4 ResNet PyTorch
# %load res.py import math import torch import torch.nn as nn class Bottleneck(nn.Module): def __init__(self,inplanes,planes,downsample = None,stride = 1): super(Bottleneck, self).__init__() self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, stride=1, bias=False) self.bn1 = nn.BatchNorm2d(planes) self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(planes) self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, stride=1, bias=False) self.bn3 = nn.BatchNorm2d(planes * 4) self.relu = nn.ReLU(inplace=True) self.downsample = downsample def forward(self, x): identity = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out = self.relu(out) out = self.conv3(out) out = self.bn3(out) if self.downsample is not None: identity = self.downsample(x) out += identity out = self.relu(out) return out class ResNet50(nn.Module): def __init__(self, num_classes=1000): super(ResNet50, self).__init__() self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2,padding=3,bias=False) self.bn1 = nn.BatchNorm2d(64) self.relu = nn.ReLU(inplace=True) self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) self.layer1 = self._make_stage(64,64,1,3) self.layer2 = self._make_stage(256,128,2,4) self.layer3 = self._make_stage(512,256,2,6) self.layer4 = self._make_stage(1024,512,2,3) self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) self.fc = nn.Linear(512 * 4, num_classes) def _make_stage(self, inplanes, planes, stride, num_blocks): downsample = nn.Sequential( nn.Conv2d(inplanes, planes * 4, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(planes*4) ) layers = [] layers.append(Bottleneck(inplanes, planes, downsample, stride)) for _ in range(1, num_blocks): layers.append(Bottleneck(4*planes, planes)) return nn.Sequential(*layers) def forward(self, x): x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.maxpool(x) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) x = self.avgpool(x) x = torch.flatten(x, 1) x = self.fc(x) return x def build_res50(phase,num_classes,pretrained): if phase != "test" and phase != "train": print("ERROR: Phase: " + phase + " not recognized") return if not pretrained: model = ResNet50(num_classes=num_classes) else: model = ResNet50() model_weights_path = 'weights/resnet50-19c8e357.pth' model.load_state_dict(torch.load(model_weights_path), strict=False) for parma in model.parameters(): parma.requires_grad = False ratio = int(math.sqrt(2048/num_classes)) floor = math.floor(math.log2(ratio)) hidden_size = int(math.pow(2,11-floor)) model.fc = nn.Sequential( nn.Linear(2048, hidden_size), nn.ReLU(inplace=True), nn.Dropout(0.5), nn.Linear(hidden_size,num_classes)) return modelfrom torchsummary import summary net = build_res50('train',10,False) net.cuda() summary(net,(3,224,224))- ----------------------------------------------------------------
- Layer (type) Output Shape Param #
- ================================================================
- Conv2d-1 [-1, 64, 112, 112] 9,408
- BatchNorm2d-2 [-1, 64, 112, 112] 128
- ReLU-3 [-1, 64, 112, 112] 0
- MaxPool2d-4 [-1, 64, 56, 56] 0
- Conv2d-5 [-1, 64, 56, 56] 4,096
- BatchNorm2d-6 [-1, 64, 56, 56] 128
- ReLU-7 [-1, 64, 56, 56] 0
- Conv2d-8 [-1, 64, 56, 56] 36,864
- BatchNorm2d-9 [-1, 64, 56, 56] 128
- ReLU-10 [-1, 64, 56, 56] 0
- Conv2d-11 [-1, 256, 56, 56] 16,384
- BatchNorm2d-12 [-1, 256, 56, 56] 512
- Conv2d-13 [-1, 256, 56, 56] 16,384
- BatchNorm2d-14 [-1, 256, 56, 56] 512
- ReLU-15 [-1, 256, 56, 56] 0
- Bottleneck-16 [-1, 256, 56, 56] 0
- Conv2d-17 [-1, 64, 56, 56] 16,384
- BatchNorm2d-18 [-1, 64, 56, 56] 128
- ReLU-19 [-1, 64, 56, 56] 0
- Conv2d-20 [-1, 64, 56, 56] 36,864
- BatchNorm2d-21 [-1, 64, 56, 56] 128
- ReLU-22 [-1, 64, 56, 56] 0
- Conv2d-23 [-1, 256, 56, 56] 16,384
- BatchNorm2d-24 [-1, 256, 56, 56] 512
- ReLU-25 [-1, 256, 56, 56] 0
- Bottleneck-26 [-1, 256, 56, 56] 0
- Conv2d-27 [-1, 64, 56, 56] 16,384
- BatchNorm2d-28 [-1, 64, 56, 56] 128
- ReLU-29 [-1, 64, 56, 56] 0
- Conv2d-30 [-1, 64, 56, 56] 36,864
- BatchNorm2d-31 [-1, 64, 56, 56] 128
- ReLU-32 [-1, 64, 56, 56] 0
- Conv2d-33 [-1, 256, 56, 56] 16,384
- BatchNorm2d-34 [-1, 256, 56, 56] 512
- ReLU-35 [-1, 256, 56, 56] 0
- Bottleneck-36 [-1, 256, 56, 56] 0
- Conv2d-37 [-1, 128, 56, 56] 32,768
- BatchNorm2d-38 [-1, 128, 56, 56] 256
- ReLU-39 [-1, 128, 56, 56] 0
- Conv2d-40 [-1, 128, 28, 28] 147,456
- BatchNorm2d-41 [-1, 128, 28, 28] 256
- ReLU-42 [-1, 128, 28, 28] 0
- Conv2d-43 [-1, 512, 28, 28] 65,536
- BatchNorm2d-44 [-1, 512, 28, 28] 1,024
- Conv2d-45 [-1, 512, 28, 28] 131,072
- BatchNorm2d-46 [-1, 512, 28, 28] 1,024
- ReLU-47 [-1, 512, 28, 28] 0
- Bottleneck-48 [-1, 512, 28, 28] 0
- Conv2d-49 [-1, 128, 28, 28] 65,536
- BatchNorm2d-50 [-1, 128, 28, 28] 256
- ReLU-51 [-1, 128, 28, 28] 0
- Conv2d-52 [-1, 128, 28, 28] 147,456
- BatchNorm2d-53 [-1, 128, 28, 28] 256
- ReLU-54 [-1, 128, 28, 28] 0
- Conv2d-55 [-1, 512, 28, 28] 65,536
- BatchNorm2d-56 [-1, 512, 28, 28] 1,024
- ReLU-57 [-1, 512, 28, 28] 0
- Bottleneck-58 [-1, 512, 28, 28] 0
- Conv2d-59 [-1, 128, 28, 28] 65,536
- BatchNorm2d-60 [-1, 128, 28, 28] 256
- ReLU-61 [-1, 128, 28, 28] 0
- Conv2d-62 [-1, 128, 28, 28] 147,456
- BatchNorm2d-63 [-1, 128, 28, 28] 256
- ReLU-64 [-1, 128, 28, 28] 0
- Conv2d-65 [-1, 512, 28, 28] 65,536
- BatchNorm2d-66 [-1, 512, 28, 28] 1,024
- ReLU-67 [-1, 512, 28, 28] 0
- Bottleneck-68 [-1, 512, 28, 28] 0
- Conv2d-69 [-1, 128, 28, 28] 65,536
- BatchNorm2d-70 [-1, 128, 28, 28] 256
- ReLU-71 [-1, 128, 28, 28] 0
- Conv2d-72 [-1, 128, 28, 28] 147,456
- BatchNorm2d-73 [-1, 128, 28, 28] 256
- ReLU-74 [-1, 128, 28, 28] 0
- Conv2d-75 [-1, 512, 28, 28] 65,536
- BatchNorm2d-76 [-1, 512, 28, 28] 1,024
- ReLU-77 [-1, 512, 28, 28] 0
- Bottleneck-78 [-1, 512, 28, 28] 0
- Conv2d-79 [-1, 256, 28, 28] 131,072
- BatchNorm2d-80 [-1, 256, 28, 28] 512
- ReLU-81 [-1, 256, 28, 28] 0
- Conv2d-82 [-1, 256, 14, 14] 589,824
- BatchNorm2d-83 [-1, 256, 14, 14] 512
- ReLU-84 [-1, 256, 14, 14] 0
- Conv2d-85 [-1, 1024, 14, 14] 262,144
- BatchNorm2d-86 [-1, 1024, 14, 14] 2,048
- Conv2d-87 [-1, 1024, 14, 14] 524,288
- BatchNorm2d-88 [-1, 1024, 14, 14] 2,048
- ReLU-89 [-1, 1024, 14, 14] 0
- Bottleneck-90 [-1, 1024, 14, 14] 0
- Conv2d-91 [-1, 256, 14, 14] 262,144
- BatchNorm2d-92 [-1, 256, 14, 14] 512
- ReLU-93 [-1, 256, 14, 14] 0
- Conv2d-94 [-1, 256, 14, 14] 589,824
- BatchNorm2d-95 [-1, 256, 14, 14] 512
- ReLU-96 [-1, 256, 14, 14] 0
- Conv2d-97 [-1, 1024, 14, 14] 262,144
- BatchNorm2d-98 [-1, 1024, 14, 14] 2,048
- ReLU-99 [-1, 1024, 14, 14] 0
- Bottleneck-100 [-1, 1024, 14, 14] 0
- Conv2d-101 [-1, 256, 14, 14] 262,144
- BatchNorm2d-102 [-1, 256, 14, 14] 512
- ReLU-103 [-1, 256, 14, 14] 0
- Conv2d-104 [-1, 256, 14, 14] 589,824
- BatchNorm2d-105 [-1, 256, 14, 14] 512
- ReLU-106 [-1, 256, 14, 14] 0
- Conv2d-107 [-1, 1024, 14, 14] 262,144
- BatchNorm2d-108 [-1, 1024, 14, 14] 2,048
- ReLU-109 [-1, 1024, 14, 14] 0
- Bottleneck-110 [-1, 1024, 14, 14] 0
- Conv2d-111 [-1, 256, 14, 14] 262,144
- BatchNorm2d-112 [-1, 256, 14, 14] 512
- ReLU-113 [-1, 256, 14, 14] 0
- Conv2d-114 [-1, 256, 14, 14] 589,824
- BatchNorm2d-115 [-1, 256, 14, 14] 512
- ReLU-116 [-1, 256, 14, 14] 0
- Conv2d-117 [-1, 1024, 14, 14] 262,144
- BatchNorm2d-118 [-1, 1024, 14, 14] 2,048
- ReLU-119 [-1, 1024, 14, 14] 0
- Bottleneck-120 [-1, 1024, 14, 14] 0
- Conv2d-121 [-1, 256, 14, 14] 262,144
- BatchNorm2d-122 [-1, 256, 14, 14] 512
- ReLU-123 [-1, 256, 14, 14] 0
- Conv2d-124 [-1, 256, 14, 14] 589,824
- BatchNorm2d-125 [-1, 256, 14, 14] 512
- ReLU-126 [-1, 256, 14, 14] 0
- Conv2d-127 [-1, 1024, 14, 14] 262,144
- BatchNorm2d-128 [-1, 1024, 14, 14] 2,048
- ReLU-129 [-1, 1024, 14, 14] 0
- Bottleneck-130 [-1, 1024, 14, 14] 0
- Conv2d-131 [-1, 256, 14, 14] 262,144
- BatchNorm2d-132 [-1, 256, 14, 14] 512
- ReLU-133 [-1, 256, 14, 14] 0
- Conv2d-134 [-1, 256, 14, 14] 589,824
- BatchNorm2d-135 [-1, 256, 14, 14] 512
- ReLU-136 [-1, 256, 14, 14] 0
- Conv2d-137 [-1, 1024, 14, 14] 262,144
- BatchNorm2d-138 [-1, 1024, 14, 14] 2,048
- ReLU-139 [-1, 1024, 14, 14] 0
- Bottleneck-140 [-1, 1024, 14, 14] 0
- Conv2d-141 [-1, 512, 14, 14] 524,288
- BatchNorm2d-142 [-1, 512, 14, 14] 1,024
- ReLU-143 [-1, 512, 14, 14] 0
- Conv2d-144 [-1, 512, 7, 7] 2,359,296
- BatchNorm2d-145 [-1, 512, 7, 7] 1,024
- ReLU-146 [-1, 512, 7, 7] 0
- Conv2d-147 [-1, 2048, 7, 7] 1,048,576
- BatchNorm2d-148 [-1, 2048, 7, 7] 4,096
- Conv2d-149 [-1, 2048, 7, 7] 2,097,152
- BatchNorm2d-150 [-1, 2048, 7, 7] 4,096
- ReLU-151 [-1, 2048, 7, 7] 0
- Bottleneck-152 [-1, 2048, 7, 7] 0
- Conv2d-153 [-1, 512, 7, 7] 1,048,576
- BatchNorm2d-154 [-1, 512, 7, 7] 1,024
- ReLU-155 [-1, 512, 7, 7] 0
- Conv2d-156 [-1, 512, 7, 7] 2,359,296
- BatchNorm2d-157 [-1, 512, 7, 7] 1,024
- ReLU-158 [-1, 512, 7, 7] 0
- Conv2d-159 [-1, 2048, 7, 7] 1,048,576
- BatchNorm2d-160 [-1, 2048, 7, 7] 4,096
- ReLU-161 [-1, 2048, 7, 7] 0
- Bottleneck-162 [-1, 2048, 7, 7] 0
- Conv2d-163 [-1, 512, 7, 7] 1,048,576
- BatchNorm2d-164 [-1, 512, 7, 7] 1,024
- ReLU-165 [-1, 512, 7, 7] 0
- Conv2d-166 [-1, 512, 7, 7] 2,359,296
- BatchNorm2d-167 [-1, 512, 7, 7] 1,024
- ReLU-168 [-1, 512, 7, 7] 0
- Conv2d-169 [-1, 2048, 7, 7] 1,048,576
- BatchNorm2d-170 [-1, 2048, 7, 7] 4,096
- ReLU-171 [-1, 2048, 7, 7] 0
- Bottleneck-172 [-1, 2048, 7, 7] 0
- AdaptiveAvgPool2d-173 [-1, 2048, 1, 1] 0
- Linear-174 [-1, 10] 20,490
- ================================================================
- Total params: 23,528,522
- Trainable params: 23,528,522
- Non-trainable params: 0
- ----------------------------------------------------------------
- Input size (MB): 0.57
- Forward/backward pass size (MB): 286.55
- Params size (MB): 89.75
- Estimated Total Size (MB): 376.88
- ----------------------------------------------------------------
1.5 ResNet 分析
考虑从输出 \vec{y}_0y0 到 \vec{y}_3y3 的三个 ResNet 块构建的网络, 根据
\vec{y}_3 = \vec{y}_2 + f_3(\vec{y}_2) = |{\vec{y}_1 + f_2(\vec{y}_1)}| + f_3({\vec{y}_1 + f_2(\vec{y}_1)})y3=y2+f3(y2)=∣y1+f2(y1)∣+f3(y1+f2(y1))
=[\vec{y}_0 + f_1(\vec{y}_0) + f_2(\vec{y}_0 + f_1(\vec{y}_0))] + f_3(\vec{y}_0 + f_1(\vec{y}_0) + f_2(\vec{y}_0 + f_1(\vec{y}_0)))=[y0+f1(y0)+f2(y0+f1(y0))]+f3(y0+f1(y0)+f2(y0+f1(y0)))
- 下图中左图为原始形式,右图为分解视图。分解视图中展示了数据从输入到输出的多条路径

- 对于严格顺序的网络,这些网络中的输入总是在单个路径中从第一层直接流到最后一层

分解视图中,每条路径可以通过二进制编码向量 \vec{\textbf{b}} = (b_1,b_2,\dots,b_n), b_i \in {0,1}b=(b1,b2,…,bn),bi∈0,1 来索引:如果流过残差块 f_ifi ,则 b_i=1bi=1 ;如果跳过残差块 f_ifi ,则 b_i=0bi=0,因此ResNet 从输入到输出具有 2^n2n 条路径,第 ii 个残差块 f_ifi 的输入汇聚了之前的 i-1i−1 个残差块的 2^{i-1}2i−1 条路径
普通的前馈神经网络 (FNN) 也可以在单个神经元(而不是网络层)这一粒度上运用分解视图,这也可以将网络分解为不同路径的集合。它与 ResNet 分解的区别是
- FNN 的神经元分解视图中,所有路径都具有相同的长度
- ResNet 网络的残差块分解视图中,所有路径具有不同的路径长度
ResNet 中,从输入到输出存在许多条不同长度的路径。这些 路径长度 的分布服从二项分布。对于 nn 层深的ResNet,大多数路径的深度为 \frac{n}{2}2n, 下图为一个 54 个块的 ResNet 网络的路径长度的分布,其中 95% 的路径只包含 19~35 个块

ResNet 中,路径梯度 幅度随着它在反向传播中经过的残差块的数量呈指数减小。因此,训练期间大多数梯度来源于更短的路径。对于一个包含 54 个残差块的 ResNet 网络
- 下图表示单条长度为 kk 的路径在反向传播到 input 处的梯度的幅度的均值,它刻画了长度为 kk 的单条路径的对于更新的影响, 因为长度为 kk 的路径有多条,因此取其平均值

- 下图表示长度为 kk 的所有路径在反向传播到 input 处的梯度的幅度的和。它刻画了长度为 kk 的所有路径对于更新的影响。它不仅取决于长度为 kk 的单条路径的对于更新的影响,还取决于长度为 kk 的单条路径的数量

有效路径 指反向传播到 input 处的梯度幅度相对较大的路径。ResNet 中有效路径相对较浅,而且有效路径数量占比较少,在一个 54 个块的 ResNet 网络中
- 几乎所有的梯度更新都来自于长度为 5~17 的路径
- 长度为 5~17 的路径占网络所有路径的 0.45%
因此 ResNet 不是让梯度流流通整个网络深度来解决梯度消失问题,而是引入能够在非常深的网络中传输梯度的短路径来 避免 梯度消失问题,和 ResNet 原理类似,随机深度网络起作用有两个原因
- 训练期间,网络看到的路径分布会发生变化,主要是变得更短
- 训练期间,每个 mini-batch 选择不同的短路径的子集,这会鼓励各路径独立地产生良好的结果
ResNet 网络训练完成之后,如果随机丢弃单个残差块,则测试误差基本不变。因为移除一个残差块时,ResNet 中路径的数量从 2^n2n 减少到 2^{n-1}2n−1,留下了一半的路径。
VGG 网络训练完成之后,如果随机丢弃单个块,则测试误差急剧上升,预测结果就跟随机猜测差不多。因为移除一个块时,VGG 中唯一可行的路径被破坏。

删除 ResNet 残差块通常会删除长路径。当删除了 kk 个残差块时,长度为 xx 的路径的剩余比例为下式
percent = \frac{C^x_{n-k}}{C^x_n}percent=CnxCn−kx

- 删除 10 个残差模块,一部分有效路径(路径长度为 5~17)仍然被保留,模型测试性能会部分下降
- 删除 20 个残差模块,绝大部分有效路径(路径长度为 5~17)被删除,模型测试性能会大幅度下降
第2节 卷积神经网络模型 DenseNet
2.1 DenseNet 简介
DenseNet 不是通过更深或者更宽的结构,而是通过 特征重用 来提升网络的学习能力
ResNet 的思想是:创建从 “靠近输入的层” 到 “靠近输出的层” 的直连。而 DenseNet 做得更为彻底, 将所有层以前馈的形式相连,这种网络因此称作DenseNet
DenseNet 具有以下的优点
- 缓解 梯度消失 的问题。因为每层都可以直接从损失函数中获取梯度、从原始输入中获取信息,从而易于训练
- 密集连接 还具有正则化的效应,缓解了小训练集任务的过拟合
- 鼓励 特征重用 , 网络将不同层学到的 feature map 进行组合
- 大幅度减少 参数数量,因为每层的卷积核尺寸都比较小,输出通道数较少 (由增长率 kk 决定)
DenseNet 具有比传统卷积网络更少的参数,因为它不需要重新学习多余的 feature map
传统的前馈神经网络可以视作在层与层之间传递状态的算法,每一层接收前一层的状态,然后将新的状态传递给下一层。这会改变状态,但是也传递了需要保留的信息
ResNet 通过恒等映射来直接传递需要保留的信息,因此层之间只需要传递状态的变化
-
DenseNet 会将所有层的状态全部保存到集体知识中,同时每一层增加很少数量的 feture map 到网络的集体知识中
-
DenseNet 的层很窄(即 feature map 的通道数很小),如每一层的输出只有 12 个通道
2.2 DenseNet 模型结构
具有 LL 层的传统卷积网络有 LL 个连接,每层仅仅与 后继层 相连。具有 LL 个残差块的 ResNet 在每个残差块增加了跨层连接,第 ll 个残差块的输出为
\vec{x}_{l+1} = \vec{x}_l + F(\vec{x}_l + W_l)xl+1=xl+F(xl+Wl)
其中 \vec{x}_lxl 是第 ll 个残差块的输入特征;W_l = \{W_{l,k} | 1 \le k \le K\}Wl={Wl,k∣1≤k≤K} 为一组与第 ll 个残差块相关的权重(包括偏置项),KK 是残差块中的层的数量,FF 代表残差函数
具有 LL 个层块的 DenseNet 块有 \frac{L(L+1)}{2}2L(L+1) 个连接,每层以 前馈 的方式将该层与它后面的 所有层 相连。对于第 ll 层:所有先前层的 feature map 都作为本层的输入,第 ll 层具有 ll 个输入feature map ;本层输出的feature map 都将作为后面 L-1L−1 层的输入。假设 DenseNet 块包含 LL 层,每一层都实现了一个非线性变换 H_l()Hl() ,其中 ll 表示层的索引。假设DenseNet块的输入为 x_0x0 ,DenseNet 块的第 ll 层的输出为 x_lxl ,则有
x_l = H_l([x_0,x_1,\dots,x_{l-1}])xl=Hl([x0,x1,…,xl−1])

其中 [x_0,x_1,\dots,x_{l-1}][x0,x1,…,xl−1] 表示 0,\dots,l-10,…,l−1 层输出的 feature map 沿着通道方向的拼接。在 ResNet 中,不同 feature map 是通过直接相加来作为块的输出。当 feature map 的尺寸改变时,无法沿着通道方向进行拼接。此时将网络划分为多个 DenseNet 块,每块内部的 feature map 尺寸相同,块之间的feature map 尺寸不同
DenseNet 块中,每层的 H_l()Hl() 输出的 feature map 通道数都相同,都是 kk 个。kk 是一个重要的超参数,称作网络的 增长率。第 ll 层的输入 feature map 的通道数为 k_0 + k \times (l-1)k0+k×(l−1), 其中 k_0k0 为输入层的通道数
DenseNet 不同于现有网络的一个重要地方是 DenseNet 的网络很窄,即输出的 feature map 通道数较小,一个很小的增长率就能够获得不错的效果。一种解释是 DenseNet 块的每层都可以访问块内的所有早前层输出的 feature map,这些f eature map 可以视作 DenseNet 块的 全局状态。每层输出的 feature map 都将被添加到块的这个全局状态中,该全局状态可以理解为网络块的 集体知识,由块内所有层共享, 而增长率 kk 决定了新增特征占全局状态的比例
因此 feature map 无需逐层复制(因为它是全局共享),这也是 DenseNet 与传统网络结构不同的地方。这有助于整个网络的特征重用,并产生更紧凑的模型。
- H_l()Hl() 可以是包含了 Batch Normalization(BN) 、ReLU 单元、池化或者卷积等操作的复合函数
- H_l()Hl() 的结构为先执行BN,再执行ReLU,最后接一个 3\times33×3 的卷积,即 BN-ReLU-Conv(3x3)
DenseNet 块中每层只产生 kk 个输出 feature map,但是它具有很多输入。当在 H_l()Hl() 之前采用 1\times11×1 卷积实现降维时,可以减小计算量。
H_l()Hl() 的输入是由第 0,1,2,\dots,l-10,1,2,…,l−1 层的输出 feature map 组成,其中第 0 层的输出feature map就是整个DensNet 块的输入feature map
事实上第 1,2,\dots,l-11,2,…,l−1 层从 DensNet 块的输入 feature map 中抽取各种特征。即 H_l()Hl() 包含了 DensNet 块的输入 feature map 的冗余信息,这可以通过 1times11times1 卷积降维来去掉这种冗余性。因此这种 1\times11×1 卷积降维对于 DenseNet 块极其有效
如果在 H_l()Hl() 中引入 1\times11×1 卷积降维,则该版本的 DenseNet 称作 DenseNet-B。其 H_l()Hl() 结构为先执行 BN ,再执行 ReLU,再接一个 1\times11×1 的卷积,再执行 BN,再执行 ReLU,最后接一个 3\times33×3 的卷积, 即 BN-ReLU-Conv(1x1)-BN-ReLU-Conv(3x3)
其中1x1 卷积的输出通道数是个超参数,选取为 4\times k4×k
一个 DenseNet 网络具有多个 DenseNet 块,DenseNet 块之间由过渡层连接。DenseNet 块之间的层称为 过渡层,其主要作用是连接不同的 DenseNet 块。
过渡层可以包含卷积或池化操作,从而改变前一个 DenseNet 块的输出 feature map 的大小(包括尺寸大小、通道数量)。过渡层由一个 BN 层、一个 1\times11×1 卷积层、一个 2\times22×2 平均池化层组成。其中 1\times11×1 卷积层用于减少 DenseNet 块的输出通道数,提高模型的紧凑性
如果不减少 DenseNet 块的输出通道数,则经过了 NN 个DenseNet 块之后,网络的 feature map 的通道数为:K_0 + N \times k \times (L - 1)K0+N×k×(L−1),其中 k_0k0 为输入图片的通道数,LL 为每个DenseNet 块的层数

如果 Dense 块输出 feature map的通道数为 mm,则可以使得过渡层输出 feature map 的通道数为 \theta mθm,其中 \thetaθ 为压缩因子
-
当 \theta = 1θ=1 时,经过过渡层的feature map 通道数不变
-
当 \theta < 1θ<1 时,经过过渡层的feature map 通道数减小。此时的DenseNet 称做 DenseNet-C。结合了DenseNet-C 和 DenseNet-B 的改进的网络称作 DenseNet-BC
ImageNet 训练的 DenseNet 网络结构,其中增长率 k=32k=32
- conv 代表的是 BN-ReLU-Conv 的组合, 1\times11×1 conv 表示先执行 BN,再执行 ReLU,最后执行 1\times11×1 的卷积
- DenseNet-xx 表示 DenseNet 块有 xx 层, DenseNet-169 表示 DenseNet 块有 L=169L=169 层
- 所有 DenseNet 使用的是 DenseNet-BC 结构,输入图片尺寸为 224\times224224×224,初始卷积尺寸为 7\times77×7、输出通道 2k、步长为 2 ,压缩因子 \theta = 0.5θ=0.5
- 所有 DenseNet 块的最后接一个全局平均池化层,该池化层的结果作为 softmax 输出层的输入

2.3 DenseNet PyTorch
# %load dense.py import math import torch import torch.nn as nn import torch.nn.functional as F from collections import OrderedDict class DenseLayer(nn.Module): expansion = 4 def __init__(self, in_channels, growth_rate): super(DenseLayer, self).__init__() zip_channels = self.expansion * growth_rate self.features = nn.Sequential( nn.BatchNorm2d(in_channels), nn.ReLU(inplace=True), nn.Conv2d(in_channels, zip_channels, kernel_size=1, bias=False), nn.BatchNorm2d(zip_channels), nn.ReLU(inplace=True), nn.Conv2d(zip_channels, growth_rate, kernel_size=3, padding=1, bias=False) ) def forward(self, x): out = self.features(x) out = torch.cat([out, x], 1) return out class Transition(nn.Sequential): def __init__(self, num_input_features, num_output_features): super(Transition, self).__init__() self.features = nn.Sequential( nn.BatchNorm2d(num_input_features), nn.ReLU(inplace=True), nn.Conv2d(num_input_features, num_output_features,kernel_size=1, bias=False), nn.AvgPool2d(kernel_size=2, stride=2) ) def forward(self, x): out = self.features(x) return out class DenseNet121(nn.Module): def __init__(self,growth_rate = 32,reduction = 0.5,num_classes=1000): super(DenseNet121, self).__init__() self.growth_rate = growth_rate self.reduction = reduction self.features = nn.Sequential(OrderedDict([ ('conv0', nn.Conv2d(3, 64, kernel_size=7, stride=2,padding=3, bias=False)), ('norm0', nn.BatchNorm2d(64)), ('relu0', nn.ReLU(inplace=True)), ('pool0', nn.MaxPool2d(kernel_size=3, stride=2, padding=1)), ])) num_features = 2 * growth_rate num_blocks = (6, 12, 24, 16) self.layer1, num_features = self._make_dense_layer(num_features, num_blocks[0]) self.layer2, num_features = self._make_dense_layer(num_features, num_blocks[1]) self.layer3, num_features = self._make_dense_layer(num_features, num_blocks[2]) self.layer4, num_features = self._make_dense_layer(num_features, num_blocks[3], transition=False) self.bn = nn.BatchNorm2d(num_features) self.classifier = nn.Linear(num_features,num_classes) def _make_dense_layer(self, in_channels, nblock, transition=True): layers = [] for i in range(nblock): layers += [DenseLayer(in_channels, self.growth_rate)] in_channels += self.growth_rate out_channels = in_channels if transition: out_channels = int(math.floor(in_channels * self.reduction)) layers += [Transition(in_channels, out_channels)] return nn.Sequential(*layers), out_channels def forward(self,x): out = self.features(x) out = self.layer1(out) out = self.layer2(out) out = self.layer3(out) out = self.layer4(out) out = self.bn(out) out = F.relu(out, inplace=True) out = F.adaptive_avg_pool2d(out, (1, 1)) out = out.view(out.size(0), -1) out = self.classifier(out) return out def build_dense121(phase,num_classes,pretrained): if phase != "test" and phase != "train": print("ERROR: Phase: " + phase + " not recognized") return if not pretrained: model = DenseNet121(num_classes=num_classes) else: model = DenseNet121() model_weights_path = 'weights/densenet121-a639ec97.pth' model.load_state_dict(torch.load(model_weights_path), strict=False) for parma in model.parameters(): parma.requires_grad = False ratio = int(math.sqrt(1024/num_classes)) floor = math.floor(math.log2(ratio)) hidden_size = int(math.pow(2,10-floor)) model.classifier = nn.Sequential(nn.Linear(1024, hidden_size), nn.ReLU(inplace=True), nn.Linear(hidden_size, num_classes)) return modelnet = build_dense121('train',10,False) net.cuda() summary(net,(3,224,224))- ----------------------------------------------------------------
- Layer (type) Output Shape Param #
- ================================================================
- Conv2d-1 [-1, 64, 112, 112] 9,408
- BatchNorm2d-2 [-1, 64, 112, 112] 128
- ReLU-3 [-1, 64, 112, 112] 0
- MaxPool2d-4 [-1, 64, 56, 56] 0
- BatchNorm2d-5 [-1, 64, 56, 56] 128
- ReLU-6 [-1, 64, 56, 56] 0
- Conv2d-7 [-1, 128, 56, 56] 8,192
- BatchNorm2d-8 [-1, 128, 56, 56] 256
- ReLU-9 [-1, 128, 56, 56] 0
- Conv2d-10 [-1, 32, 56, 56] 36,864
- DenseLayer-11 [-1, 96, 56, 56] 0
- BatchNorm2d-12 [-1, 96, 56, 56] 192
- ReLU-13 [-1, 96, 56, 56] 0
- Conv2d-14 [-1, 128, 56, 56] 12,288
- BatchNorm2d-15 [-1, 128, 56, 56] 256
- ReLU-16 [-1, 128, 56, 56] 0
- Conv2d-17 [-1, 32, 56, 56] 36,864
- DenseLayer-18 [-1, 128, 56, 56] 0
- BatchNorm2d-19 [-1, 128, 56, 56] 256
- ReLU-20 [-1, 128, 56, 56] 0
- Conv2d-21 [-1, 128, 56, 56] 16,384
- BatchNorm2d-22 [-1, 128, 56, 56] 256
- ReLU-23 [-1, 128, 56, 56] 0
- Conv2d-24 [-1, 32, 56, 56] 36,864
- DenseLayer-25 [-1, 160, 56, 56] 0
- BatchNorm2d-26 [-1, 160, 56, 56] 320
- ReLU-27 [-1, 160, 56, 56] 0
- Conv2d-28 [-1, 128, 56, 56] 20,480
- BatchNorm2d-29 [-1, 128, 56, 56] 256
- ReLU-30 [-1, 128, 56, 56] 0
- Conv2d-31 [-1, 32, 56, 56] 36,864
- DenseLayer-32 [-1, 192, 56, 56] 0
- BatchNorm2d-33 [-1, 192, 56, 56] 384
- ReLU-34 [-1, 192, 56, 56] 0
- Conv2d-35 [-1, 128, 56, 56] 24,576
- BatchNorm2d-36 [-1, 128, 56, 56] 256
- ReLU-37 [-1, 128, 56, 56] 0
- Conv2d-38 [-1, 32, 56, 56] 36,864
- DenseLayer-39 [-1, 224, 56, 56] 0
- BatchNorm2d-40 [-1, 224, 56, 56] 448
- ReLU-41 [-1, 224, 56, 56] 0
- Conv2d-42 [-1, 128, 56, 56] 28,672
- BatchNorm2d-43 [-1, 128, 56, 56] 256
- ReLU-44 [-1, 128, 56, 56] 0
- Conv2d-45 [-1, 32, 56, 56] 36,864
- DenseLayer-46 [-1, 256, 56, 56] 0
- BatchNorm2d-47 [-1, 256, 56, 56] 512
- ReLU-48 [-1, 256, 56, 56] 0
- Conv2d-49 [-1, 128, 56, 56] 32,768
- AvgPool2d-50 [-1, 128, 28, 28] 0
- BatchNorm2d-51 [-1, 128, 28, 28] 256
- ReLU-52 [-1, 128, 28, 28] 0
- Conv2d-53 [-1, 128, 28, 28] 16,384
- BatchNorm2d-54 [-1, 128, 28, 28] 256
- ReLU-55 [-1, 128, 28, 28] 0
- Conv2d-56 [-1, 32, 28, 28] 36,864
- DenseLayer-57 [-1, 160, 28, 28] 0
- BatchNorm2d-58 [-1, 160, 28, 28] 320
- ReLU-59 [-1, 160, 28, 28] 0
- Conv2d-60 [-1, 128, 28, 28] 20,480
- BatchNorm2d-61 [-1, 128, 28, 28] 256
- ReLU-62 [-1, 128, 28, 28] 0
- Conv2d-63 [-1, 32, 28, 28] 36,864
- DenseLayer-64 [-1, 192, 28, 28] 0
- BatchNorm2d-65 [-1, 192, 28, 28] 384
- ReLU-66 [-1, 192, 28, 28] 0
- Conv2d-67 [-1, 128, 28, 28] 24,576
- BatchNorm2d-68 [-1, 128, 28, 28] 256
- ReLU-69 [-1, 128, 28, 28] 0
- Conv2d-70 [-1, 32, 28, 28] 36,864
- DenseLayer-71 [-1, 224, 28, 28] 0
- BatchNorm2d-72 [-1, 224, 28, 28] 448
- ReLU-73 [-1, 224, 28, 28] 0
- Conv2d-74 [-1, 128, 28, 28] 28,672
- BatchNorm2d-75 [-1, 128, 28, 28] 256
- ReLU-76 [-1, 128, 28, 28] 0
- Conv2d-77 [-1, 32, 28, 28] 36,864
- DenseLayer-78 [-1, 256, 28, 28] 0
- BatchNorm2d-79 [-1, 256, 28, 28] 512
- ReLU-80 [-1, 256, 28, 28] 0
- Conv2d-81 [-1, 128, 28, 28] 32,768
- BatchNorm2d-82 [-1, 128, 28, 28] 256
- ReLU-83 [-1, 128, 28, 28] 0
- Conv2d-84 [-1, 32, 28, 28] 36,864
- DenseLayer-85 [-1, 288, 28, 28] 0
- BatchNorm2d-86 [-1, 288, 28, 28] 576
- ReLU-87 [-1, 288, 28, 28] 0
- Conv2d-88 [-1, 128, 28, 28] 36,864
- BatchNorm2d-89 [-1, 128, 28, 28] 256
- ReLU-90 [-1, 128, 28, 28] 0
- Conv2d-91 [-1, 32, 28, 28] 36,864
- DenseLayer-92 [-1, 320, 28, 28] 0
- BatchNorm2d-93 [-1, 320, 28, 28] 640
- ReLU-94 [-1, 320, 28, 28] 0
- Conv2d-95 [-1, 128, 28, 28] 40,960
- BatchNorm2d-96 [-1, 128, 28, 28] 256
- ReLU-97 [-1, 128, 28, 28] 0
- Conv2d-98 [-1, 32, 28, 28] 36,864
- DenseLayer-99 [-1, 352, 28, 28] 0
- BatchNorm2d-100 [-1, 352, 28, 28] 704
- ReLU-101 [-1, 352, 28, 28] 0
- Conv2d-102 [-1, 128, 28, 28] 45,056
- BatchNorm2d-103 [-1, 128, 28, 28] 256
- ReLU-104 [-1, 128, 28, 28] 0
- Conv2d-105 [-1, 32, 28, 28] 36,864
- DenseLayer-106 [-1, 384, 28, 28] 0
- BatchNorm2d-107 [-1, 384, 28, 28] 768
- ReLU-108 [-1, 384, 28, 28] 0
- Conv2d-109 [-1, 128, 28, 28] 49,152
- BatchNorm2d-110 [-1, 128, 28, 28] 256
- ReLU-111 [-1, 128, 28, 28] 0
- Conv2d-112 [-1, 32, 28, 28] 36,864
- DenseLayer-113 [-1, 416, 28, 28] 0
- BatchNorm2d-114 [-1, 416, 28, 28] 832
- ReLU-115 [-1, 416, 28, 28] 0
- Conv2d-116 [-1, 128, 28, 28] 53,248
- BatchNorm2d-117 [-1, 128, 28, 28] 256
- ReLU-118 [-1, 128, 28, 28] 0
- Conv2d-119 [-1, 32, 28, 28] 36,864
- DenseLayer-120 [-1, 448, 28, 28] 0
- BatchNorm2d-121 [-1, 448, 28, 28] 896
- ReLU-122 [-1, 448, 28, 28] 0
- Conv2d-123 [-1, 128, 28, 28] 57,344
- BatchNorm2d-124 [-1, 128, 28, 28] 256
- ReLU-125 [-1, 128, 28, 28] 0
- Conv2d-126 [-1, 32, 28, 28] 36,864
- DenseLayer-127 [-1, 480, 28, 28] 0
- BatchNorm2d-128 [-1, 480, 28, 28] 960
- ReLU-129 [-1, 480, 28, 28] 0
- Conv2d-130 [-1, 128, 28, 28] 61,440
- BatchNorm2d-131 [-1, 128, 28, 28] 256
- ReLU-132 [-1, 128, 28, 28] 0
- Conv2d-133 [-1, 32, 28, 28] 36,864
- DenseLayer-134 [-1, 512, 28, 28] 0
- BatchNorm2d-135 [-1, 512, 28, 28] 1,024
- ReLU-136 [-1, 512, 28, 28] 0
- Conv2d-137 [-1, 256, 28, 28] 131,072
- AvgPool2d-138 [-1, 256, 14, 14] 0
- BatchNorm2d-139 [-1, 256, 14, 14] 512
- ReLU-140 [-1, 256, 14, 14] 0
- Conv2d-141 [-1, 128, 14, 14] 32,768
- BatchNorm2d-142 [-1, 128, 14, 14] 256
- ReLU-143 [-1, 128, 14, 14] 0
- Conv2d-144 [-1, 32, 14, 14] 36,864
- DenseLayer-145 [-1, 288, 14, 14] 0
- BatchNorm2d-146 [-1, 288, 14, 14] 576
- ReLU-147 [-1, 288, 14, 14] 0
- Conv2d-148 [-1, 128, 14, 14] 36,864
- BatchNorm2d-149 [-1, 128, 14, 14] 256
- ReLU-150 [-1, 128, 14, 14] 0
- Conv2d-151 [-1, 32, 14, 14] 36,864
- DenseLayer-152 [-1, 320, 14, 14] 0
- BatchNorm2d-153 [-1, 320, 14, 14] 640
- ReLU-154 [-1, 320, 14, 14] 0
- Conv2d-155 [-1, 128, 14, 14] 40,960
- BatchNorm2d-156 [-1, 128, 14, 14] 256
- ReLU-157 [-1, 128, 14, 14] 0
- Conv2d-158 [-1, 32, 14, 14] 36,864
- DenseLayer-159 [-1, 352, 14, 14] 0
- BatchNorm2d-160 [-1, 352, 14, 14] 704
- ReLU-161 [-1, 352, 14, 14] 0
- Conv2d-162 [-1, 128, 14, 14] 45,056
- BatchNorm2d-163 [-1, 128, 14, 14] 256
- ReLU-164 [-1, 128, 14, 14] 0
- Conv2d-165 [-1, 32, 14, 14] 36,864
- DenseLayer-166 [-1, 384, 14, 14] 0
- BatchNorm2d-167 [-1, 384, 14, 14] 768
- ReLU-168 [-1, 384, 14, 14] 0
- Conv2d-169 [-1, 128, 14, 14] 49,152
- BatchNorm2d-170 [-1, 128, 14, 14] 256
- ReLU-171 [-1, 128, 14, 14] 0
- Conv2d-172 [-1, 32, 14, 14] 36,864
- DenseLayer-173 [-1, 416, 14, 14] 0
- BatchNorm2d-174 [-1, 416, 14, 14] 832
- ReLU-175 [-1, 416, 14, 14] 0
- Conv2d-176 [-1, 128, 14, 14] 53,248
- BatchNorm2d-177 [-1, 128, 14, 14] 256
- ReLU-178 [-1, 128, 14, 14] 0
- Conv2d-179 [-1, 32, 14, 14] 36,864
- DenseLayer-180 [-1, 448, 14, 14] 0
- BatchNorm2d-181 [-1, 448, 14, 14] 896
- ReLU-182 [-1, 448, 14, 14] 0
- Conv2d-183 [-1, 128, 14, 14] 57,344
- BatchNorm2d-184 [-1, 128, 14, 14] 256
- ReLU-185 [-1, 128, 14, 14] 0
- Conv2d-186 [-1, 32, 14, 14] 36,864
- DenseLayer-187 [-1, 480, 14, 14] 0
- BatchNorm2d-188 [-1, 480, 14, 14] 960
- ReLU-189 [-1, 480, 14, 14] 0
- Conv2d-190 [-1, 128, 14, 14] 61,440
- BatchNorm2d-191 [-1, 128, 14, 14] 256
- ReLU-192 [-1, 128, 14, 14] 0
- Conv2d-193 [-1, 32, 14, 14] 36,864
- DenseLayer-194 [-1, 512, 14, 14] 0
- BatchNorm2d-195 [-1, 512, 14, 14] 1,024
- ReLU-196 [-1, 512, 14, 14] 0
- Conv2d-197 [-1, 128, 14, 14] 65,536
- BatchNorm2d-198 [-1, 128, 14, 14] 256
- ReLU-199 [-1, 128, 14, 14] 0
- Conv2d-200 [-1, 32, 14, 14] 36,864
- DenseLayer-201 [-1, 544, 14, 14] 0
- BatchNorm2d-202 [-1, 544, 14, 14] 1,088
- ReLU-203 [-1, 544, 14, 14] 0
- Conv2d-204 [-1, 128, 14, 14] 69,632
- BatchNorm2d-205 [-1, 128, 14, 14] 256
- ReLU-206 [-1, 128, 14, 14] 0
- Conv2d-207 [-1, 32, 14, 14] 36,864
- DenseLayer-208 [-1, 576, 14, 14] 0
- BatchNorm2d-209 [-1, 576, 14, 14] 1,152
- ReLU-210 [-1, 576, 14, 14] 0
- Conv2d-211 [-1, 128, 14, 14] 73,728
- BatchNorm2d-212 [-1, 128, 14, 14] 256
- ReLU-213 [-1, 128, 14, 14] 0
- Conv2d-214 [-1, 32, 14, 14] 36,864
- DenseLayer-215 [-1, 608, 14, 14] 0
- BatchNorm2d-216 [-1, 608, 14, 14] 1,216
- ReLU-217 [-1, 608, 14, 14] 0
- Conv2d-218 [-1, 128, 14, 14] 77,824
- BatchNorm2d-219 [-1, 128, 14, 14] 256
- ReLU-220 [-1, 128, 14, 14] 0
- Conv2d-221 [-1, 32, 14, 14] 36,864
- DenseLayer-222 [-1, 640, 14, 14] 0
- BatchNorm2d-223 [-1, 640, 14, 14] 1,280
- ReLU-224 [-1, 640, 14, 14] 0
- Conv2d-225 [-1, 128, 14, 14] 81,920
- BatchNorm2d-226 [-1, 128, 14, 14] 256
- ReLU-227 [-1, 128, 14, 14] 0
- Conv2d-228 [-1, 32, 14, 14] 36,864
- DenseLayer-229 [-1, 672, 14, 14] 0
- BatchNorm2d-230 [-1, 672, 14, 14] 1,344
- ReLU-231 [-1, 672, 14, 14] 0
- Conv2d-232 [-1, 128, 14, 14] 86,016
- BatchNorm2d-233 [-1, 128, 14, 14] 256
- ReLU-234 [-1, 128, 14, 14] 0
- Conv2d-235 [-1, 32, 14, 14] 36,864
- DenseLayer-236 [-1, 704, 14, 14] 0
- BatchNorm2d-237 [-1, 704, 14, 14] 1,408
- ReLU-238 [-1, 704, 14, 14] 0
- Conv2d-239 [-1, 128, 14, 14] 90,112
- BatchNorm2d-240 [-1, 128, 14, 14] 256
- ReLU-241 [-1, 128, 14, 14] 0
- Conv2d-242 [-1, 32, 14, 14] 36,864
- DenseLayer-243 [-1, 736, 14, 14] 0
- BatchNorm2d-244 [-1, 736, 14, 14] 1,472
- ReLU-245 [-1, 736, 14, 14] 0
- Conv2d-246 [-1, 128, 14, 14] 94,208
- BatchNorm2d-247 [-1, 128, 14, 14] 256
- ReLU-248 [-1, 128, 14, 14] 0
- Conv2d-249 [-1, 32, 14, 14] 36,864
- DenseLayer-250 [-1, 768, 14, 14] 0
- BatchNorm2d-251 [-1, 768, 14, 14] 1,536
- ReLU-252 [-1, 768, 14, 14] 0
- Conv2d-253 [-1, 128, 14, 14] 98,304
- BatchNorm2d-254 [-1, 128, 14, 14] 256
- ReLU-255 [-1, 128, 14, 14] 0
- Conv2d-256 [-1, 32, 14, 14] 36,864
- DenseLayer-257 [-1, 800, 14, 14] 0
- BatchNorm2d-258 [-1, 800, 14, 14] 1,600
- ReLU-259 [-1, 800, 14, 14] 0
- Conv2d-260 [-1, 128, 14, 14] 102,400
- BatchNorm2d-261 [-1, 128, 14, 14] 256
- ReLU-262 [-1, 128, 14, 14] 0
- Conv2d-263 [-1, 32, 14, 14] 36,864
- DenseLayer-264 [-1, 832, 14, 14] 0
- BatchNorm2d-265 [-1, 832, 14, 14] 1,664
- ReLU-266 [-1, 832, 14, 14] 0
- Conv2d-267 [-1, 128, 14, 14] 106,496
- BatchNorm2d-268 [-1, 128, 14, 14] 256
- ReLU-269 [-1, 128, 14, 14] 0
- Conv2d-270 [-1, 32, 14, 14] 36,864
- DenseLayer-271 [-1, 864, 14, 14] 0
- BatchNorm2d-272 [-1, 864, 14, 14] 1,728
- ReLU-273 [-1, 864, 14, 14] 0
- Conv2d-274 [-1, 128, 14, 14] 110,592
- BatchNorm2d-275 [-1, 128, 14, 14] 256
- ReLU-276 [-1, 128, 14, 14] 0
- Conv2d-277 [-1, 32, 14, 14] 36,864
- DenseLayer-278 [-1, 896, 14, 14] 0
- BatchNorm2d-279 [-1, 896, 14, 14] 1,792
- ReLU-280 [-1, 896, 14, 14] 0
- Conv2d-281 [-1, 128, 14, 14] 114,688
- BatchNorm2d-282 [-1, 128, 14, 14] 256
- ReLU-283 [-1, 128, 14, 14] 0
- Conv2d-284 [-1, 32, 14, 14] 36,864
- DenseLayer-285 [-1, 928, 14, 14] 0
- BatchNorm2d-286 [-1, 928, 14, 14] 1,856
- ReLU-287 [-1, 928, 14, 14] 0
- Conv2d-288 [-1, 128, 14, 14] 118,784
- BatchNorm2d-289 [-1, 128, 14, 14] 256
- ReLU-290 [-1, 128, 14, 14] 0
- Conv2d-291 [-1, 32, 14, 14] 36,864
- DenseLayer-292 [-1, 960, 14, 14] 0
- BatchNorm2d-293 [-1, 960, 14, 14] 1,920
- ReLU-294 [-1, 960, 14, 14] 0
- Conv2d-295 [-1, 128, 14, 14] 122,880
- BatchNorm2d-296 [-1, 128, 14, 14] 256
- ReLU-297 [-1, 128, 14, 14] 0
- Conv2d-298 [-1, 32, 14, 14] 36,864
- DenseLayer-299 [-1, 992, 14, 14] 0
- BatchNorm2d-300 [-1, 992, 14, 14] 1,984
- ReLU-301 [-1, 992, 14, 14] 0
- Conv2d-302 [-1, 128, 14, 14] 126,976
- BatchNorm2d-303 [-1, 128, 14, 14] 256
- ReLU-304 [-1, 128, 14, 14] 0
- Conv2d-305 [-1, 32, 14, 14] 36,864
- DenseLayer-306 [-1, 1024, 14, 14] 0
- BatchNorm2d-307 [-1, 1024, 14, 14] 2,048
- ReLU-308 [-1, 1024, 14, 14] 0
- Conv2d-309 [-1, 512, 14, 14] 524,288
- AvgPool2d-310 [-1, 512, 7, 7] 0
- BatchNorm2d-311 [-1, 512, 7, 7] 1,024
- ReLU-312 [-1, 512, 7, 7] 0
- Conv2d-313 [-1, 128, 7, 7] 65,536
- BatchNorm2d-314 [-1, 128, 7, 7] 256
- ReLU-315 [-1, 128, 7, 7] 0
- Conv2d-316 [-1, 32, 7, 7] 36,864
- DenseLayer-317 [-1, 544, 7, 7] 0
- BatchNorm2d-318 [-1, 544, 7, 7] 1,088
- ReLU-319 [-1, 544, 7, 7] 0
- Conv2d-320 [-1, 128, 7, 7] 69,632
- BatchNorm2d-321 [-1, 128, 7, 7] 256
- ReLU-322 [-1, 128, 7, 7] 0
- Conv2d-323 [-1, 32, 7, 7] 36,864
- DenseLayer-324 [-1, 576, 7, 7] 0
- BatchNorm2d-325 [-1, 576, 7, 7] 1,152
- ReLU-326 [-1, 576, 7, 7] 0
- Conv2d-327 [-1, 128, 7, 7] 73,728
- BatchNorm2d-328 [-1, 128, 7, 7] 256
- ReLU-329 [-1, 128, 7, 7] 0
- Conv2d-330 [-1, 32, 7, 7] 36,864
- DenseLayer-331 [-1, 608, 7, 7] 0
- BatchNorm2d-332 [-1, 608, 7, 7] 1,216
- ReLU-333 [-1, 608, 7, 7] 0
- Conv2d-334 [-1, 128, 7, 7] 77,824
- BatchNorm2d-335 [-1, 128, 7, 7] 256
- ReLU-336 [-1, 128, 7, 7] 0
- Conv2d-337 [-1, 32, 7, 7] 36,864
- DenseLayer-338 [-1, 640, 7, 7] 0
- BatchNorm2d-339 [-1, 640, 7, 7] 1,280
- ReLU-340 [-1, 640, 7, 7] 0
- Conv2d-341 [-1, 128, 7, 7] 81,920
- BatchNorm2d-342 [-1, 128, 7, 7] 256
- ReLU-343 [-1, 128, 7, 7] 0
- Conv2d-344 [-1, 32, 7, 7] 36,864
- DenseLayer-345 [-1, 672, 7, 7] 0
- BatchNorm2d-346 [-1, 672, 7, 7] 1,344
- ReLU-347 [-1, 672, 7, 7] 0
- Conv2d-348 [-1, 128, 7, 7] 86,016
- BatchNorm2d-349 [-1, 128, 7, 7] 256
- ReLU-350 [-1, 128, 7, 7] 0
- Conv2d-351 [-1, 32, 7, 7] 36,864
- DenseLayer-352 [-1, 704, 7, 7] 0
- BatchNorm2d-353 [-1, 704, 7, 7] 1,408
- ReLU-354 [-1, 704, 7, 7] 0
- Conv2d-355 [-1, 128, 7, 7] 90,112
- BatchNorm2d-356 [-1, 128, 7, 7] 256
- ReLU-357 [-1, 128, 7, 7] 0
- Conv2d-358 [-1, 32, 7, 7] 36,864
- DenseLayer-359 [-1, 736, 7, 7] 0
- BatchNorm2d-360 [-1, 736, 7, 7] 1,472
- ReLU-361 [-1, 736, 7, 7] 0
- Conv2d-362 [-1, 128, 7, 7] 94,208
- BatchNorm2d-363 [-1, 128, 7, 7] 256
- ReLU-364 [-1, 128, 7, 7] 0
- Conv2d-365 [-1, 32, 7, 7] 36,864
- DenseLayer-366 [-1, 768, 7, 7] 0
- BatchNorm2d-367 [-1, 768, 7, 7] 1,536
- ReLU-368 [-1, 768, 7, 7] 0
- Conv2d-369 [-1, 128, 7, 7] 98,304
- BatchNorm2d-370 [-1, 128, 7, 7] 256
- ReLU-371 [-1, 128, 7, 7] 0
- Conv2d-372 [-1, 32, 7, 7] 36,864
- DenseLayer-373 [-1, 800, 7, 7] 0
- BatchNorm2d-374 [-1, 800, 7, 7] 1,600
- ReLU-375 [-1, 800, 7, 7] 0
- Conv2d-376 [-1, 128, 7, 7] 102,400
- BatchNorm2d-377 [-1, 128, 7, 7] 256
- ReLU-378 [-1, 128, 7, 7] 0
- Conv2d-379 [-1, 32, 7, 7] 36,864
- DenseLayer-380 [-1, 832, 7, 7] 0
- BatchNorm2d-381 [-1, 832, 7, 7] 1,664
- ReLU-382 [-1, 832, 7, 7] 0
- Conv2d-383 [-1, 128, 7, 7] 106,496
- BatchNorm2d-384 [-1, 128, 7, 7] 256
- ReLU-385 [-1, 128, 7, 7] 0
- Conv2d-386 [-1, 32, 7, 7] 36,864
- DenseLayer-387 [-1, 864, 7, 7] 0
- BatchNorm2d-388 [-1, 864, 7, 7] 1,728
- ReLU-389 [-1, 864, 7, 7] 0
- Conv2d-390 [-1, 128, 7, 7] 110,592
- BatchNorm2d-391 [-1, 128, 7, 7] 256
- ReLU-392 [-1, 128, 7, 7] 0
- Conv2d-393 [-1, 32, 7, 7] 36,864
- DenseLayer-394 [-1, 896, 7, 7] 0
- BatchNorm2d-395 [-1, 896, 7, 7] 1,792
- ReLU-396 [-1, 896, 7, 7] 0
- Conv2d-397 [-1, 128, 7, 7] 114,688
- BatchNorm2d-398 [-1, 128, 7, 7] 256
- ReLU-399 [-1, 128, 7, 7] 0
- Conv2d-400 [-1, 32, 7, 7] 36,864
- DenseLayer-401 [-1, 928, 7, 7] 0
- BatchNorm2d-402 [-1, 928, 7, 7] 1,856
- ReLU-403 [-1, 928, 7, 7] 0
- Conv2d-404 [-1, 128, 7, 7] 118,784
- BatchNorm2d-405 [-1, 128, 7, 7] 256
- ReLU-406 [-1, 128, 7, 7] 0
- Conv2d-407 [-1, 32, 7, 7] 36,864
- DenseLayer-408 [-1, 960, 7, 7] 0
- BatchNorm2d-409 [-1, 960, 7, 7] 1,920
- ReLU-410 [-1, 960, 7, 7] 0
- Conv2d-411 [-1, 128, 7, 7] 122,880
- BatchNorm2d-412 [-1, 128, 7, 7] 256
- ReLU-413 [-1, 128, 7, 7] 0
- Conv2d-414 [-1, 32, 7, 7] 36,864
- DenseLayer-415 [-1, 992, 7, 7] 0
- BatchNorm2d-416 [-1, 992, 7, 7] 1,984
- ReLU-417 [-1, 992, 7, 7] 0
- Conv2d-418 [-1, 128, 7, 7] 126,976
- BatchNorm2d-419 [-1, 128, 7, 7] 256
- ReLU-420 [-1, 128, 7, 7] 0
- Conv2d-421 [-1, 32, 7, 7] 36,864
- DenseLayer-422 [-1, 1024, 7, 7] 0
- BatchNorm2d-423 [-1, 1024, 7, 7] 2,048
- Linear-424 [-1, 10] 10,250
- ================================================================
- Total params: 6,964,106
- Trainable params: 6,964,106
- Non-trainable params: 0
- ----------------------------------------------------------------
- Input size (MB): 0.57
- Forward/backward pass size (MB): 371.81
- Params size (MB): 26.57
- Estimated Total Size (MB): 398.95
- ----------------------------------------------------------------
2.4 DenseNet 设计技巧
虽然 DenseNet 的计算效率较高、参数相对较少,但是 DenseNet 对内存 不友好 。考虑到 GPU 显存大小的限制,因此无法训练较深的 DenseNet。假设DenseNet块包含 LL 层,对于第 ll 层有 x_l = H_l([x_0,x_1,\dots,x_{l-1}])xl=Hl([x0,x1,…,xl−1])
假设每层的输出 feature map 尺寸均为 W \times HW×H、通道数为 kk,H_lHl 由 BN-ReLU-Conv(3x3) 组成,则
- 拼接 Concat 操作 [\dots][…] :需要生成临时 feature map 作为第 ll 层的输入,内存消耗为 WHK \times lWHK×l
- BN 操作需要生成临时 feature map 作为 ReLU 的输入,内存消耗为 WHK \times lWHK×l
- ReLU 操作可以执行原地修改,因此不需要额外的 feature map 存放 ReLU 的输出
- Conv 操作需要生成输出 feature map 作为第 ll 层的输出,它是必须的开销
因此除了第 1,2,\dots,L1,2,…,L 层的输出 feature map 需要内存开销之外,第 ll 层还需要 2WHKl2WHKl 的内存开销来存放中间生成的临时 feature map。 整个 DenseNet Block 需要 WHk(1 + L)LWHk(1+L)L 的内存开销来存放中间生成的临时 feature map, 即 DenseNet Block 的内存消耗为 O(L^2)O(L2),是网络深度的平方关系
拼接 Concat 操作是必须的,因为当卷积的输入存放在连续的内存区域时,卷积操作的计算效率较高。而 DenseNet Block 中,第 ll 层的输入 feature map 由前面各层的输出 feature map 沿通道方向拼接而成。而这些输出 feature map 并不在连续的内存区域
另外,拼接 feature map 并不是简单的将它们拷贝在一起。由于 feature map 在 Tensorflow/PyTorch 实现中的表示为 \Re^{n \times d \times w \times h}ℜn×d×w×h (channel first),或者 \Re^{n \times w \times h \times d}ℜn×w×h×d (channel last),如果简单的将它们拷贝在一起则是沿着 mini batch 维度的拼接,而不是沿着通道方向的拼接, DenseNet Block 的这种内存消耗并不是 DenseNet Block 的结构引起的,而是由 深度学习库 引起的。因为 Tensorflow/PyTorch 等库在实现神经网络时,会存放中间生成的临时节点 (如BN 的输出节点),这是为了在反向传播阶段可以直接获取临时节点的值
这是在时间代价和空间代价之间的 折中 :通过开辟更多的空间来存储临时值,从而在反向传播阶段节省计算。
除了临时 feature map 的内存消耗之外,网络的参数也会消耗内存。设 H_lHl 由BN-ReLU-Conv(3x3) 组成,则第 ll 层的网络参数数量为 9Lk^29Lk2 (不考虑 BN ), 整个 DenseNet Block 的参数数量为 \frac{9k^2(L+1)L}{2}29k2(L+1)L ,即 O(L)O(L), 因此网络参数的数量也是网络深度的 平方关系
- 由于DenseNet 参数数量与网络的深度呈平方关系,因此 DenseNet 网络的参数更多、网络容量更大。这也是 DenseNet 优于其它网络的一个重要因素
- 通常情况下都有 WH > \frac{9k}{2}WH>29k ,其中 W,HW,H 为网络 feature map 的宽、高,kk 为网络的增长率。所以网络参数消耗的内存要远小于临时 feature map 消耗的内存
传统的 DenseNet Block 实现与内存优化的 DenseNet Block 对比如下(第 ll 层,该层的输入 feature map 来自于同一个块中早前的层的输出)

- 左图为传统的 DenseNet Block 的第 ll 层, 首先将 feature map 拷贝到连续的内存块,拷贝时完成拼接的操作。然后依次执行 BN、ReLU、Conv 操作。该层的临时 feature map 需要消耗内存 2WHkl2WHkl,该层的输出 feature map 需要消耗内存 WHkWHk
另外某些实现(如LuaTorch)还需要为反向传播过程的梯度分配内存, 计算 BN 层输出的梯度时,需要用到第 ll 层输出层的梯度和 BN 层的输出。存储这些梯度需要额外的 O(lk)O(lk) 的内存
另外一些实现(如PyTorch,MxNet)会对梯度使用共享的内存区域来存放这些梯度,因此只需要 O(k)O(k) 的内存- 右图为内存优化的 DenseNet Block 的第 ll 层, 采用两组预分配的共享内存区 Shared memory Storage location 来存 Concate 操作和 BN 操作输出的临时feature map
第3节 PyTorch 实践
3.1 模型训练代码
加载同级目录下 train.py 程序代码
# %load train.py import os os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE" import time import argparse import sys import torch import torch.nn as nn import torch.optim as optim import torch.backends.cudnn as cudnn from torchvision import datasets, transforms from torch.autograd import Variable import matplotlib as mpl import matplotlib.pyplot as plt mpl.rc('axes', labelsize = 14) mpl.rc('xtick', labelsize = 12) mpl.rc('ytick', labelsize = 12) sys.path.append(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))) from res import build_res50 from dense import build_dense121 from datasets.config import * from datasets.cifar import CIFAR10 from datasets.flower import shuffle_flower from datasets.oxford_iiit import shuffle_oxford def str2bool(v): return v.lower() in ("yes", "true", "t", "1") parser = argparse.ArgumentParser( description='Image Classification Training With Pytorch') train_set = parser.add_mutually_exclusive_group() parser.add_argument('--dataset', default='Flower', choices=['Flower', 'Oxford-IIIT', 'CIFAR-10'], type=str, help='Flower, Oxford-IIIT, CIFAR-10') parser.add_argument('--dataset_root', default=FLOWER_ROOT, help='Dataset root directory path') parser.add_argument('--model', default='ResNet', choices=['ResNet', 'DenseNet'], type=str, help='ResNet or DenseNet') parser.add_argument('--pretrained', default=True, type=str2bool, help='Using pretrained model weights') parser.add_argument('--crop_size', default=224, type=int, help='Resized crop value') parser.add_argument('--batch_size', default=32, type=int, help='Batch size for training') parser.add_argument('--num_workers', default=0, type=int, help='Number of workers used in dataloading') parser.add_argument('--epoch_size', default=20, type=int, help='Number of Epoches for training') parser.add_argument('--cuda', default=True, type=str2bool, help='Use CUDA to train model') parser.add_argument('--shuffle', default=False, type=str2bool, help='Shuffle new train and test folders') parser.add_argument('--lr', '--learning-rate', default=2e-4, type=float, help='initial learning rate') parser.add_argument('--save_folder', default='weights/', help='Directory for saving checkpoint models') parser.add_argument('--photo_folder', default='results/', help='Directory for saving photos') args = parser.parse_args() if not os.path.exists(args.save_folder): os.mkdir(args.save_folder) if not os.path.exists(args.photo_folder): os.mkdir(args.photo_folder) data_transform = transforms.Compose([transforms.RandomResizedCrop(args.crop_size), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) def train(): if args.dataset == 'Flower': if not os.path.exists(FLOWER_ROOT): parser.error('Must specify dataset_root if specifying dataset') args.dataset_root = FLOWER_ROOT train_path = os.path.join(FLOWER_ROOT, 'train') if not os.path.exists(train_path) or args.shuffle: shuffle_flower() dataset = datasets.ImageFolder(root=train_path,transform=data_transform) if args.dataset == 'Oxford-IIIT': if not os.path.exists(OXFORD_IIIT_ROOT): parser.error('Must specify dataset_root if specifying dataset') args.dataset_root = OXFORD_IIIT_ROOT train_path = os.path.join(OXFORD_IIIT_ROOT, 'train') if not os.path.exists(train_path) or args.shuffle: shuffle_oxford() dataset = datasets.ImageFolder(root=train_path,transform=data_transform) if args.dataset == 'CIFAR-10': if not os.path.exists(CIFAR_ROOT): parser.error('Must specify dataset_root if specifying dataset') args.dataset_root = CIFAR_ROOT dataset = CIFAR10(train=True,transform=data_transform,target_transform=None) classes = dataset.classes if args.model == 'ResNet': net = build_res50(phase='train', num_classes=len(classes), pretrained=args.pretrained) if args.model == 'DenseNet': net = build_dense121(phase='train', num_classes=len(classes), pretrained=args.pretrained) if args.cuda and torch.cuda.is_available(): net = torch.nn.DataParallel(net) cudnn.benchmark = True net.cuda() optimizer = optim.Adam(net.parameters(), lr=args.lr) criterion = nn.CrossEntropyLoss() epoch_size = args.epoch_size print('Loading the dataset...') data_loader = torch.utils.data.DataLoader(dataset, args.batch_size, num_workers=args.num_workers, shuffle=True, pin_memory=True) print('Training on:', args.dataset) print('Using model:', args.model) print('Using the specified args:') print(args) loss_list = [] acc_list = [] for epoch in range(epoch_size): net.train() train_loss = 0.0 correct = 0 total = len(dataset) t0 = time.perf_counter() for step, data in enumerate(data_loader, start=0): images, labels = data if args.cuda: images = Variable(images.cuda()) labels = Variable(labels.cuda()) else: images = Variable(images) labels = Variable(labels) # forward outputs = net(images) # backprop optimizer.zero_grad() loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics train_loss += loss.item() _, predicted = outputs.max(1) correct += predicted.eq(labels).sum().item() # print train process rate = (step + 1) / len(data_loader) a = "*" * int(rate * 50) b = "." * int((1 - rate) * 50) print("\rEpoch {}: {:^3.0f}%[{}->{}]{:.3f}".format(epoch+1, int(rate * 100), a, b, loss), end="") print(' Running time: %.3f' % (time.perf_counter() - t0)) acc = 100.*correct/ total loss = train_loss / step print('train loss: %.6f, acc: %.3f%% (%d/%d)' % (loss, acc, correct, total)) loss_list.append(loss) acc_list.append(acc/100) torch.save(net.state_dict(),args.save_folder + args.dataset + "_" + args.model + '.pth') plt.plot(range(epoch_size), loss_list, range(epoch_size), acc_list) plt.xlabel('Epoches') plt.ylabel('Sparse CrossEntropy Loss | Accuracy') plt.savefig(os.path.join( os.path.dirname( os.path.abspath(__file__)), args.photo_folder, args.dataset + "_" + args.model + "_train_details.png")) if __name__ == '__main__': train()- dataset:
训练采用的数据集,目前提供 Flower, Oxford-IIIT, CIFAR-10 供选择。 点击查看数据集加载Demo
- dataset_root:
数据集读取地址, default已设置为数据集相对路径,部署在云端可能需要修改
- model:
训练使用的算法模型,目前提供 ResNet, DenseNet 等卷积神经网络
- pretrained:
是否使用 PyTorch 预训练权重
- crop_size:
数据图像预处理剪裁大小,default为224,只有 LeNet 默认使用 32\times3232×32 尺寸大小
- shuffle:
是否重新生成新的train-test数据集样本
- batch_size:
单次训练所抓取的数据样本数量,default为32
- num_workers:
加载数据所使用线程个数,default为0,n\in (2,4,8,12\dots)n∈(2,4,8,12…)
- epoch_size:
训练次数, default为20
- cuda:
是否调用GPU训练
- lr:
超参数学习率,采用Adam优化函数,default为 0.0020.002
- save_folder:
模型权重保存地址
- 训练细节
print 于 python console, 包括单个epoch训练时间、训练集损失值、准确率
- 模型权重
模型保存路径为 ./weight/{dataset}_{model}.pth
- 损失函数与正确率
图片保存路径为 ./result/{dataset}_{model}_train_details.png
3.2 模型测试代码
加载同级目录下 test.py 程序代码
# %load test.py import sys import os os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE" import argparse import torch import torch.nn as nn import torch.backends.cudnn as cudnn from torchvision import transforms, datasets from torch.autograd import Variable import itertools import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt mpl.rc('axes', labelsize = 14) mpl.rc('xtick', labelsize = 12) mpl.rc('ytick', labelsize = 12) sys.path.append(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))) from res import build_res50 from dense import build_dense121 from datasets.config import * from datasets.cifar import CIFAR10 parser = argparse.ArgumentParser( description='Convolutional Neural Network Testing With Pytorch') parser.add_argument('--dataset', default='Flower', choices=['Flower', 'Oxford-IIIT', 'CIFAR-10'], type=str, help='Flower, Oxford-IIIT, or CIFAR-10') parser.add_argument('--dataset_root', default=FLOWER_ROOT, help='Dataset root directory path') parser.add_argument('--model', default='ResNet', choices=['ResNet', 'DenseNet'], type=str, help='ResNet or DenseNet') parser.add_argument('--crop_size', default=224, type=int, help='Resized crop value') parser.add_argument('--batch_size', default=32, type=int, help='Batch size for training') parser.add_argument('--num_workers', default=0, type=int, help='Number of workers used in dataloading') parser.add_argument('--weight', default='weights/{}_{}.pth', type=str, help='Trained state_dict file path to open') parser.add_argument('--cuda', default=True, type=bool, help='Use cuda to train model') parser.add_argument('--pretrained', default=True, type=bool, help='Using pretrained model weights') parser.add_argument('-f', default=None, type=str, help="Dummy arg so we can load in Jupyter Notebooks") args = parser.parse_args() args.weight = args.weight.format(args.dataset,args.model) data_transform = transforms.Compose([transforms.RandomResizedCrop(args.crop_size), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) def confusion_matrix(preds, labels, conf_matrix): for p, t in zip(preds, labels): conf_matrix[p, t] += 1 return conf_matrix def save_confusion_matrix(cm, classes, normalize=False, title='Confusion matrix', cmap=plt.cm.Blues): plt.imshow(cm, interpolation='nearest', cmap=cmap) plt.title(title) plt.colorbar() tick_marks = np.arange(len(classes)) plt.xticks(tick_marks, classes, rotation=90) plt.yticks(tick_marks, classes) plt.axis("equal") ax = plt.gca() left, right = plt.xlim() ax.spines['left'].set_position(('data', left)) ax.spines['right'].set_position(('data', right)) for edge_i in ['top', 'bottom', 'right', 'left']: ax.spines[edge_i].set_edgecolor("white") thresh = cm.max() / 2. for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])): num = '{:.2f}'.format(cm[i, j]) if normalize else int(cm[i, j]) plt.text(j, i, num, verticalalignment='center', horizontalalignment="center", color="white" if num > thresh else "black") plt.ylabel('True label') plt.xlabel('Predicted label') plt.savefig(os.path.join( os.path.dirname( os.path.abspath(__file__)), "results", args.dataset + '_confusion_matrix.png')) def test(): # load data if args.dataset == 'Flower': if not os.path.exists(FLOWER_ROOT): parser.error('Must specify dataset_root if specifying dataset') args.dataset_root = FLOWER_ROOT test_path = os.path.join(FLOWER_ROOT, 'val') if not os.path.exists(test_path): parser.error('Must train models before evaluating') dataset = datasets.ImageFolder(root=test_path,transform=data_transform) if args.dataset == 'Oxford-IIIT': if not os.path.exists(OXFORD_IIIT_ROOT): parser.error('Must specify dataset_root if specifying dataset') args.dataset_root = OXFORD_IIIT_ROOT test_path = os.path.join(OXFORD_IIIT_ROOT, 'val') if not os.path.exists(test_path): parser.error('Must train models before evaluating') dataset = datasets.ImageFolder(root=test_path,transform=data_transform) if args.dataset == 'CIFAR-10': if not os.path.exists(CIFAR_ROOT): parser.error('Must specify dataset_root if specifying dataset') args.dataset_root = CIFAR_ROOT dataset = CIFAR10(train=False,transform=data_transform,target_transform=None) classes = dataset.classes num_classes = len(classes) data_loader = torch.utils.data.DataLoader(dataset, args.batch_size, num_workers=args.num_workers, shuffle=True, pin_memory=True) # load net if args.model == 'ResNet': net = build_res50(phase='train', num_classes=len(classes), pretrained=args.pretrained) if args.model == 'DenseNet': net = build_dense121(phase='train', num_classes=len(classes), pretrained=args.pretrained) if args.cuda and torch.cuda.is_available(): net = torch.nn.DataParallel(net) cudnn.benchmark = True net.cuda() net.load_state_dict(torch.load(args.weight)) print('Finish loading model: ', args.weight) net.eval() print('Training on:', args.dataset) print('Using model:', args.model) print('Using the specified args:') print(args) # evaluation criterion = nn.CrossEntropyLoss() test_loss = 0 correct = 0 total = 0 conf_matrix = torch.zeros(num_classes, num_classes) class_correct = list(0 for i in range(num_classes)) class_total = list(0 for i in range(num_classes)) with torch.no_grad(): for step, data in enumerate(data_loader): images, labels = data if args.cuda: images = Variable(images.cuda()) labels = Variable(labels.cuda()) else: images = Variable(images) labels = Variable(labels) # forward outputs = net(images) loss = criterion(outputs, labels) test_loss += loss.item() _, predicted = outputs.max(1) conf_matrix = confusion_matrix(predicted, labels=labels, conf_matrix=conf_matrix) total += labels.size(0) correct += predicted.eq(labels).sum().item() c = (predicted.eq(labels)).squeeze() for i in range(c.size(0)): label = labels[i] class_correct[label] += c[i].item() class_total[label] += 1 acc = 100.* correct / total loss = test_loss / step print('test loss: %.6f, acc: %.3f%% (%d/%d)' % (loss, acc, correct, total)) for i in range(num_classes): print('accuracy of %s : %.3f%% (%d/%d)' % ( str(classes[i]), 100 * class_correct[i] / class_total[i], class_correct[i], class_total[i])) save_confusion_matrix(conf_matrix.numpy(), classes=classes, normalize=False, title = 'Normalized confusion matrix') if __name__ == '__main__': test()训练采用的数据集,目前提供 Flower, Oxford-IIIT, CIFAR-10 供选择。 点击查看数据集加载Demo
- dataset_root:
数据集读取地址, default已设置为数据集相对路径,部署在云端可能需要修改
- model:
训练使用的算法模型,目前提供 ResNet, DenseNet 等卷积神经网络
- pretrained:
是否使用 PyTorch 预训练权重
- crop_size:
数据图像预处理剪裁大小,default为224,只有 LeNet 默认使用 32\times3232×32 尺寸大小
- shuffle:
单次训练所抓取的数据样本数量,default为32
- num_workers:
加载数据所使用线程个数,default为0,n\in (2,4,8,12\dots)n∈(2,4,8,12…)
- trained_model:
模型权重保存路径,default为 train.py 生成的ptb文件路径
- cuda:
是否调用GPU训练
- 测试集损失值与准确率
print 于 python console 第一行
- 各类别准确率
print 于 python console 后续列表
- 混淆矩阵
图片保存路径为 ./photos/%_confusion_matrix.png
第4节 Flower 数据集

-
Flower 数据集 来自 Tensorflow 团队,创建于 2019 年 1 月,作为 入门级轻量数据集 包含5个花卉类别 [‘daisy’, ‘dandelion’, ‘roses’, ‘sunflowers’, ‘tulips’]
-
Flower 数据集 是深度学习图像分类中经典的一个数据集,各个类别有 [633, 898, 641, 699, 799] 个样本,每个样本都是一张 320\times232320×232 像素的RGB图片
-
Dataset 库中的 flower.py 按照 0.1 的比例实现训练集与测试集的 样本分离
4.1 ResNet
%run train.py --dataset Flower --model ResNet --pretrained True- Loading the dataset...
- Training on: Flower
- Using model: ResNet
- Using the specified args:
- Namespace(batch_size=32, crop_size=224, cuda=True, dataset='Flower', dataset_root='C:\\Users\\sbzy\\Documents/GitHub/dl_algorithm/datasets\\FLOWER', epoch_size=20, lr=0.0002, model='ResNet', num_workers=0, photo_folder='results/', pretrained=True, save_folder='weights/', shuffle=False)
- Epoch 1: 100%[**************************************************->]0.875 Running time: 26.564
- train loss: 1.081059, acc: 63.733% (2107/3306)
- Epoch 2: 100%[**************************************************->]0.601 Running time: 25.509
- train loss: 0.677766, acc: 78.736% (2603/3306)
- Epoch 3: 100%[**************************************************->]0.456 Running time: 26.531
- train loss: 0.559504, acc: 81.942% (2709/3306)
- Epoch 4: 100%[**************************************************->]1.432 Running time: 26.556
- train loss: 0.520002, acc: 82.638% (2732/3306)
- Epoch 5: 100%[**************************************************->]0.427 Running time: 26.434
- train loss: 0.470244, acc: 83.666% (2766/3306)
- Epoch 6: 100%[**************************************************->]0.331 Running time: 25.863
- train loss: 0.466301, acc: 84.392% (2790/3306)
- Epoch 7: 100%[**************************************************->]0.640 Running time: 26.079
- train loss: 0.425827, acc: 85.390% (2823/3306)
- Epoch 8: 100%[**************************************************->]0.568 Running time: 26.056
- train loss: 0.415019, acc: 85.935% (2841/3306)
- Epoch 9: 100%[**************************************************->]0.174 Running time: 26.167
- train loss: 0.389266, acc: 86.388% (2856/3306)
- Epoch 10: 100%[**************************************************->]0.865 Running time: 26.185
- train loss: 0.396210, acc: 86.842% (2871/3306)
- Epoch 11: 100%[**************************************************->]0.326 Running time: 25.983
- train loss: 0.401938, acc: 86.449% (2858/3306)
- Epoch 12: 100%[**************************************************->]0.729 Running time: 26.115
- train loss: 0.397555, acc: 86.570% (2862/3306)
- Epoch 13: 100%[**************************************************->]0.832 Running time: 25.905
- train loss: 0.377356, acc: 86.903% (2873/3306)
- Epoch 14: 100%[**************************************************->]0.333 Running time: 26.271
- train loss: 0.369491, acc: 87.447% (2891/3306)
- Epoch 15: 100%[**************************************************->]0.061 Running time: 25.992
- train loss: 0.378465, acc: 87.266% (2885/3306)
- Epoch 16: 100%[**************************************************->]0.879 Running time: 26.118
- train loss: 0.355365, acc: 88.052% (2911/3306)
- Epoch 17: 100%[**************************************************->]0.665 Running time: 26.128
- train loss: 0.364475, acc: 87.175% (2882/3306)
- Epoch 18: 100%[**************************************************->]0.498 Running time: 25.985
- train loss: 0.349165, acc: 88.294% (2919/3306)
- Epoch 19: 100%[**************************************************->]0.761 Running time: 26.108
- train loss: 0.358627, acc: 87.598% (2896/3306)
- Epoch 20: 100%[**************************************************->]0.241 Running time: 26.108
- train loss: 0.331572, acc: 89.080% (2945/3306)

%run test.py --dataset Flower --model ResNet --pretrained True- Finish loading model: weights/Flower_ResNet.pth
- Training on: Flower
- Using model: ResNet
- Using the specified args:
- Namespace(batch_size=32, crop_size=224, cuda=True, dataset='Flower', dataset_root='C:\\Users\\sbzy\\Documents/GitHub/dl_algorithm/datasets\\FLOWER', f=None, model='ResNet', num_workers=0, pretrained=True, weight='weights/Flower_ResNet.pth')
- test loss: 0.305797, acc: 90.110% (328/364)
- accuracy of daisy : 87.302% (55/63)
- accuracy of dandelion : 92.135% (82/89)
- accuracy of roses : 90.625% (58/64)
- accuracy of sunflowers : 89.855% (62/69)
- accuracy of tulips : 89.873% (71/79)

4.2 DenseNet
%run train.py --dataset Flower --model DenseNet --pretrained True- Loading the dataset...
- Training on: Flower
- Using model: DenseNet
- Using the specified args:
- Namespace(batch_size=32, crop_size=224, cuda=True, dataset='Flower', dataset_root='C:\\Users\\sbzy\\Documents/GitHub/dl_algorithm/datasets\\FLOWER', epoch_size=20, lr=0.0002, model='DenseNet', num_workers=0, photo_folder='results/', pretrained=True, save_folder='weights/', shuffle=False)
- Epoch 1: 100%[**************************************************->]1.358 Running time: 28.533
- train loss: 1.479844, acc: 38.869% (1285/3306)
- Epoch 2: 100%[**************************************************->]1.313 Running time: 26.414
- train loss: 1.317668, acc: 46.854% (1549/3306)
- Epoch 3: 100%[**************************************************->]1.420 Running time: 26.416
- train loss: 1.242020, acc: 49.819% (1647/3306)
- Epoch 4: 100%[**************************************************->]1.200 Running time: 26.329
- train loss: 1.199207, acc: 51.754% (1711/3306)
- Epoch 5: 100%[**************************************************->]1.288 Running time: 26.556
- train loss: 1.163759, acc: 54.809% (1812/3306)
- Epoch 6: 100%[**************************************************->]0.689 Running time: 26.803
- train loss: 1.138236, acc: 55.203% (1825/3306)
- Epoch 7: 100%[**************************************************->]0.803 Running time: 27.322
- train loss: 1.122978, acc: 55.596% (1838/3306)
- Epoch 8: 100%[**************************************************->]1.180 Running time: 26.789
- train loss: 1.102592, acc: 57.350% (1896/3306)
- Epoch 9: 100%[**************************************************->]1.098 Running time: 26.681
- train loss: 1.107488, acc: 56.594% (1871/3306)
- Epoch 10: 100%[**************************************************->]1.315 Running time: 26.620
- train loss: 1.065998, acc: 58.288% (1927/3306)
- Epoch 11: 100%[**************************************************->]1.490 Running time: 27.548
- train loss: 1.078985, acc: 57.864% (1913/3306)
- Epoch 12: 100%[**************************************************->]1.067 Running time: 26.945
- train loss: 1.056432, acc: 59.679% (1973/3306)
- Epoch 13: 100%[**************************************************->]1.428 Running time: 26.677
- train loss: 1.055029, acc: 59.952% (1982/3306)
- Epoch 14: 100%[**************************************************->]0.811 Running time: 26.552
- train loss: 1.063877, acc: 60.284% (1993/3306)
- Epoch 15: 100%[**************************************************->]1.409 Running time: 26.576
- train loss: 1.037472, acc: 60.315% (1994/3306)
- Epoch 16: 100%[**************************************************->]1.187 Running time: 26.102
- train loss: 1.026487, acc: 60.950% (2015/3306)
- Epoch 17: 100%[**************************************************->]1.233 Running time: 26.227
- train loss: 1.031807, acc: 60.738% (2008/3306)
- Epoch 18: 100%[**************************************************->]1.221 Running time: 26.052
- train loss: 1.002148, acc: 61.464% (2032/3306)
- Epoch 19: 100%[**************************************************->]0.771 Running time: 26.276
- train loss: 0.998473, acc: 62.129% (2054/3306)
- Epoch 20: 100%[**************************************************->]1.198 Running time: 26.112
- train loss: 0.992600, acc: 62.855% (2078/3306)

%run test.py --dataset Flower --model DenseNet --pretrained True- Finish loading model: weights/Flower_DenseNet.pth
- Training on: Flower
- Using model: DenseNet
- Using the specified args:
- Namespace(batch_size=32, crop_size=224, cuda=True, dataset='Flower', dataset_root='C:\\Users\\sbzy\\Documents/GitHub/dl_algorithm/datasets\\FLOWER', f=None, model='DenseNet', num_workers=0, pretrained=True, weight='weights/Flower_DenseNet.pth')
- test loss: 1.103226, acc: 64.286% (234/364)
- accuracy of daisy : 55.556% (35/63)
- accuracy of dandelion : 82.022% (73/89)
- accuracy of roses : 35.938% (23/64)
- accuracy of sunflowers : 76.812% (53/69)
- accuracy of tulips : 63.291% (50/79)

第5节 Oxford-IIIT 数据集

- Oxford-IIIT 数据集覆盖 30 个种类的猫狗品种,每个类别收集了约 200 张图像样本
- Oxford-IIIT 中每张图像在尺寸、姿势、光暗程度上有很大的浮动,但所有的图像都匹配了相关联的品种、头部框架定位、三维像素点语义分割的标注信息
- Dataset 库中的 oxford_iiit.py 按照 0.1 的比例实现训练集与测试集的 样本分离
5.1 ResNet
%run train.py --dataset Oxford-IIIT --model ResNet --pretrained True- Loading the dataset...
- Training on: Oxford-IIIT
- Using model: ResNet
- Using the specified args:
- Namespace(batch_size=32, crop_size=224, cuda=True, dataset='Oxford-IIIT', dataset_root='C:\\Users\\sbzy\\Documents/GitHub/dl_algorithm/datasets\\OXFORD-IIIT', epoch_size=20, lr=0.0002, model='ResNet', num_workers=0, photo_folder='results/', pretrained=True, save_folder='weights/', shuffle=False)
- Epoch 1: 100%[**************************************************->]1.672 Running time: 52.758
- train loss: 2.521808, acc: 38.588% (2083/5398)
- Epoch 2: 100%[**************************************************->]1.263 Running time: 50.631
- train loss: 1.373019, acc: 66.154% (3571/5398)
- Epoch 3: 100%[**************************************************->]1.509 Running time: 50.305
- train loss: 1.020504, acc: 72.305% (3903/5398)
- Epoch 4: 100%[**************************************************->]0.838 Running time: 49.587
- train loss: 0.868986, acc: 75.213% (4060/5398)
- Epoch 5: 100%[**************************************************->]0.843 Running time: 50.557
- train loss: 0.793433, acc: 77.418% (4179/5398)
- Epoch 6: 100%[**************************************************->]0.902 Running time: 51.422
- train loss: 0.749010, acc: 77.306% (4173/5398)
- Epoch 7: 100%[**************************************************->]1.209 Running time: 50.523
- train loss: 0.707766, acc: 78.770% (4252/5398)
- Epoch 8: 100%[**************************************************->]0.759 Running time: 50.358
- train loss: 0.655945, acc: 80.196% (4329/5398)
- Epoch 9: 100%[**************************************************->]0.902 Running time: 50.031
- train loss: 0.645212, acc: 80.511% (4346/5398)
- Epoch 10: 100%[**************************************************->]0.490 Running time: 49.170
- train loss: 0.634509, acc: 80.548% (4348/5398)
- Epoch 11: 100%[**************************************************->]0.556 Running time: 49.356
- train loss: 0.615873, acc: 80.474% (4344/5398)
- Epoch 12: 100%[**************************************************->]0.503 Running time: 50.010
- train loss: 0.614606, acc: 80.622% (4352/5398)
- Epoch 13: 100%[**************************************************->]0.356 Running time: 49.389
- train loss: 0.591290, acc: 82.049% (4429/5398)
- Epoch 14: 100%[**************************************************->]0.484 Running time: 49.485
- train loss: 0.576546, acc: 82.179% (4436/5398)
- Epoch 15: 100%[**************************************************->]0.473 Running time: 49.611
- train loss: 0.573398, acc: 81.975% (4425/5398)
- Epoch 16: 100%[**************************************************->]0.656 Running time: 50.217
- train loss: 0.584155, acc: 81.938% (4423/5398)
- Epoch 17: 100%[**************************************************->]0.820 Running time: 50.045
- train loss: 0.576462, acc: 82.104% (4432/5398)
- Epoch 18: 100%[**************************************************->]0.566 Running time: 49.894
- train loss: 0.589368, acc: 81.308% (4389/5398)
- Epoch 19: 100%[**************************************************->]0.439 Running time: 49.606
- train loss: 0.539627, acc: 83.938% (4531/5398)
- Epoch 20: 100%[**************************************************->]0.558 Running time: 50.065
- train loss: 0.556025, acc: 83.012% (4481/5398)

%run test.py --dataset Oxford-IIIT --model ResNet --pretrained True- Finish loading model: weights/Oxford-IIIT_ResNet.pth
- Training on: Oxford-IIIT
- Using model: ResNet
- Using the specified args:
- Namespace(batch_size=32, crop_size=224, cuda=True, dataset='Oxford-IIIT', dataset_root='C:\\Users\\sbzy\\Documents/GitHub/dl_algorithm/datasets\\OXFORD-IIIT', f=None, model='ResNet', num_workers=0, pretrained=True, weight='weights/Oxford-IIIT_ResNet.pth')
- test loss: 0.455718, acc: 86.978% (521/599)
- accuracy of Abyssinian : 95.000% (19/20)
- accuracy of American_Bulldog : 80.000% (16/20)
- accuracy of American_Pit_Bull_Terrier : 70.000% (14/20)
- accuracy of Basset_Hound : 80.000% (16/20)
- accuracy of Beagle : 90.000% (18/20)
- accuracy of Bengal : 85.000% (17/20)
- accuracy of Birman : 95.000% (19/20)
- accuracy of Bombay : 100.000% (20/20)
- accuracy of Boxer : 85.000% (17/20)
- accuracy of British_Shorthair : 75.000% (15/20)
- accuracy of Chihuahua : 80.000% (16/20)
- accuracy of Egyptian_Mau : 85.000% (17/20)
- accuracy of English_Cocker_Spaniel : 100.000% (20/20)
- accuracy of English_Setter : 85.000% (17/20)
- accuracy of German_Shorthaired : 95.000% (19/20)
- accuracy of Great_Pyrenees : 95.000% (19/20)
- accuracy of Havanese : 90.000% (18/20)
- accuracy of Japanese_Chin : 90.000% (18/20)
- accuracy of Keeshond : 85.000% (17/20)
- accuracy of Leonberger : 95.000% (19/20)
- accuracy of Maine_Coon : 75.000% (15/20)
- accuracy of Miniature_Pinscher : 85.000% (17/20)
- accuracy of Newfoundland : 95.000% (19/20)
- accuracy of Persian : 95.000% (19/20)
- accuracy of Pomeranian : 85.000% (17/20)
- accuracy of Pug : 70.000% (14/20)
- accuracy of Ragdoll : 80.000% (16/20)
- accuracy of Russian_Blue : 85.000% (17/20)
- accuracy of Saint_Bernard : 95.000% (19/20)
- accuracy of Samoyed : 89.474% (17/19)

5.2 DenseNet
%run train.py --dataset Oxford-IIIT --model DenseNet --pretrained True- Loading the dataset...
- Training on: Oxford-IIIT
- Using model: DenseNet
- Using the specified args:
- Namespace(batch_size=32, crop_size=224, cuda=True, dataset='Oxford-IIIT', dataset_root='C:\\Users\\sbzy\\Documents/GitHub/dl_algorithm/datasets\\OXFORD-IIIT', epoch_size=20, lr=0.0002, model='DenseNet', num_workers=0, photo_folder='results/', pretrained=True, save_folder='weights/', shuffle=False)
- Epoch 1: 100%[**************************************************->]3.417 Running time: 52.623
- train loss: 3.389321, acc: 5.947% (321/5398)
- Epoch 2: 100%[**************************************************->]3.239 Running time: 51.639
- train loss: 3.324268, acc: 7.873% (425/5398)
- Epoch 3: 100%[**************************************************->]3.194 Running time: 51.499
- train loss: 3.275900, acc: 9.392% (507/5398)
- Epoch 4: 100%[**************************************************->]3.118 Running time: 51.520
- train loss: 3.237189, acc: 10.634% (574/5398)
- Epoch 5: 100%[**************************************************->]3.091 Running time: 51.456
- train loss: 3.192028, acc: 11.801% (637/5398)
- Epoch 6: 100%[**************************************************->]3.105 Running time: 52.150
- train loss: 3.159566, acc: 12.523% (676/5398)
- Epoch 7: 100%[**************************************************->]3.357 Running time: 51.849
- train loss: 3.129416, acc: 13.431% (725/5398)
- Epoch 8: 100%[**************************************************->]3.291 Running time: 51.711
- train loss: 3.114922, acc: 13.357% (721/5398)
- Epoch 9: 100%[**************************************************->]3.088 Running time: 50.402
- train loss: 3.082170, acc: 14.357% (775/5398)
- Epoch 10: 100%[**************************************************->]2.907 Running time: 52.089
- train loss: 3.059112, acc: 14.783% (798/5398)
- Epoch 11: 100%[**************************************************->]3.184 Running time: 51.797
- train loss: 3.043412, acc: 14.598% (788/5398)
- Epoch 12: 100%[**************************************************->]2.944 Running time: 51.530
- train loss: 3.036861, acc: 15.969% (862/5398)
- Epoch 13: 100%[**************************************************->]2.953 Running time: 51.445
- train loss: 3.015575, acc: 15.932% (860/5398)
- Epoch 14: 100%[**************************************************->]2.936 Running time: 51.216
- train loss: 3.003686, acc: 15.895% (858/5398)
- Epoch 15: 100%[**************************************************->]3.334 Running time: 50.708
- train loss: 2.990475, acc: 16.803% (907/5398)
- Epoch 16: 100%[**************************************************->]3.245 Running time: 51.944
- train loss: 2.975292, acc: 16.673% (900/5398)
- Epoch 17: 100%[**************************************************->]2.933 Running time: 51.413
- train loss: 2.960971, acc: 17.877% (965/5398)
- Epoch 18: 100%[**************************************************->]2.980 Running time: 51.584
- train loss: 2.959703, acc: 16.932% (914/5398)
- Epoch 19: 100%[**************************************************->]2.703 Running time: 50.915
- train loss: 2.943565, acc: 17.451% (942/5398)
- Epoch 20: 100%[**************************************************->]2.789 Running time: 50.066
- train loss: 2.923782, acc: 17.673% (954/5398)
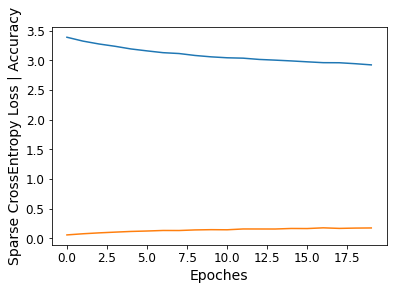
%run test.py --dataset Oxford-IIIT --model DenseNet --pretrained True- Finish loading model: weights/Oxford-IIIT_DenseNet.pth
- Training on: Oxford-IIIT
- Using model: DenseNet
- Using the specified args:
- Namespace(batch_size=32, crop_size=224, cuda=True, dataset='Oxford-IIIT', dataset_root='C:\\Users\\sbzy\\Documents/GitHub/dl_algorithm/datasets\\OXFORD-IIIT', f=None, model='DenseNet', num_workers=0, pretrained=True, weight='weights/Oxford-IIIT_DenseNet.pth')
- test loss: 3.210763, acc: 14.524% (87/599)
- accuracy of Abyssinian : 15.000% (3/20)
- accuracy of American_Bulldog : 0.000% (0/20)
- accuracy of American_Pit_Bull_Terrier : 0.000% (0/20)
- accuracy of Basset_Hound : 15.000% (3/20)
- accuracy of Beagle : 5.000% (1/20)
- accuracy of Bengal : 15.000% (3/20)
- accuracy of Birman : 5.000% (1/20)
- accuracy of Bombay : 55.000% (11/20)
- accuracy of Boxer : 5.000% (1/20)
- accuracy of British_Shorthair : 20.000% (4/20)
- accuracy of Chihuahua : 10.000% (2/20)
- accuracy of Egyptian_Mau : 40.000% (8/20)
- accuracy of English_Cocker_Spaniel : 0.000% (0/20)
- accuracy of English_Setter : 0.000% (0/20)
- accuracy of German_Shorthaired : 40.000% (8/20)
- accuracy of Great_Pyrenees : 10.000% (2/20)
- accuracy of Havanese : 25.000% (5/20)
- accuracy of Japanese_Chin : 15.000% (3/20)
- accuracy of Keeshond : 20.000% (4/20)
- accuracy of Leonberger : 5.000% (1/20)
- accuracy of Maine_Coon : 5.000% (1/20)
- accuracy of Miniature_Pinscher : 0.000% (0/20)
- accuracy of Newfoundland : 15.000% (3/20)
- accuracy of Persian : 0.000% (0/20)
- accuracy of Pomeranian : 20.000% (4/20)
- accuracy of Pug : 5.000% (1/20)
- accuracy of Ragdoll : 35.000% (7/20)
- accuracy of Russian_Blue : 20.000% (4/20)
- accuracy of Saint_Bernard : 15.000% (3/20)
- accuracy of Samoyed : 21.053% (4/19)

第6节 CIFAR-10 数据集

- CIFAR-10 数据集是 Visual Dictionary (Teaching computers to recognize objects) 的子集,由三个多伦多大学教授收集,主要来自Google和各类搜索引擎的图片
- CIFAR-10 数据集包含 60000 张 32\times3232×32 的RBG彩色图像,共计 10 个 包含 6000 张样本图像的不同类别,训练集包含 50000 张图像样本,测试集包含 10000 张图像样本
- CIFAR-10 数据集在深度学习初期 (ImageNet 问世前) 一直是衡量各种算法模型的 benchmark,但其 32\times3232×32 的图像尺寸逐渐无法满足日渐飞速迭代的神经网络结构
6.1 ResNet
%run train.py --dataset CIFAR-10 --model ResNet --pretrained True- Loading the dataset...
- Training on: CIFAR-10
- Using model: ResNet
- Using the specified args:
- Namespace(batch_size=32, crop_size=224, cuda=True, dataset='CIFAR-10', dataset_root='C:\\Users\\sbzy\\Documents/GitHub/dl_algorithm/datasets\\CIFAR-10', epoch_size=20, lr=0.0002, model='ResNet', num_workers=0, photo_folder='results/', pretrained=True, save_folder='weights/', shuffle=False)
- Epoch 1: 100%[**************************************************->]1.182 Running time: 268.943
- train loss: 1.536603, acc: 46.160% (23080/50000)
- Epoch 2: 100%[**************************************************->]1.599 Running time: 272.843
- train loss: 1.306745, acc: 54.256% (27128/50000)
- Epoch 3: 100%[**************************************************->]0.755 Running time: 271.827
- train loss: 1.264989, acc: 55.674% (27837/50000)
- Epoch 4: 100%[**************************************************->]1.132 Running time: 271.198
- train loss: 1.244303, acc: 56.414% (28207/50000)
- Epoch 5: 100%[**************************************************->]0.973 Running time: 270.233
- train loss: 1.222554, acc: 56.928% (28464/50000)
- Epoch 6: 100%[**************************************************->]1.087 Running time: 275.036
- train loss: 1.217354, acc: 57.220% (28610/50000)
- Epoch 7: 100%[**************************************************->]0.884 Running time: 274.613
- train loss: 1.210398, acc: 57.528% (28764/50000)
- Epoch 8: 100%[**************************************************->]1.285 Running time: 273.153
- train loss: 1.196946, acc: 57.820% (28910/50000)
- Epoch 9: 100%[**************************************************->]1.259 Running time: 273.424
- train loss: 1.185041, acc: 58.506% (29253/50000)
- Epoch 10: 100%[**************************************************->]1.548 Running time: 273.988
- train loss: 1.181838, acc: 58.526% (29263/50000)
- Epoch 11: 100%[**************************************************->]1.346 Running time: 273.759
- train loss: 1.178121, acc: 58.676% (29338/50000)
- Epoch 12: 100%[**************************************************->]0.835 Running time: 275.765
- train loss: 1.170078, acc: 59.114% (29557/50000)
- Epoch 13: 100%[**************************************************->]1.329 Running time: 272.255
- train loss: 1.169670, acc: 58.960% (29480/50000)
- Epoch 14: 100%[**************************************************->]1.506 Running time: 272.848
- train loss: 1.168470, acc: 59.054% (29527/50000)
- Epoch 15: 100%[**************************************************->]1.494 Running time: 270.235
- train loss: 1.162010, acc: 59.134% (29567/50000)
- Epoch 16: 100%[**************************************************->]1.065 Running time: 270.341
- train loss: 1.157648, acc: 59.338% (29669/50000)
- Epoch 17: 100%[**************************************************->]1.498 Running time: 271.751
- train loss: 1.155461, acc: 59.522% (29761/50000)
- Epoch 18: 100%[**************************************************->]0.791 Running time: 274.548
- train loss: 1.151811, acc: 59.386% (29693/50000)
- Epoch 19: 100%[**************************************************->]1.116 Running time: 274.017
- train loss: 1.153108, acc: 59.550% (29775/50000)
- Epoch 20: 100%[**************************************************->]1.234 Running time: 275.824
- train loss: 1.150793, acc: 59.674% (29837/50000)

%run test.py --dataset CIFAR-10 --model ResNet --pretrained True- Finish loading model: weights/CIFAR-10_ResNet.pth
- Training on: CIFAR-10
- Using model: ResNet
- Using the specified args:
- Namespace(batch_size=32, crop_size=224, cuda=True, dataset='CIFAR-10', dataset_root='C:\\Users\\sbzy\\Documents/GitHub/dl_algorithm/datasets\\CIFAR-10', f=None, model='ResNet', num_workers=0, pretrained=True, weight='weights/CIFAR-10_ResNet.pth')
- test loss: 1.023940, acc: 63.890% (6389/10000)
- accuracy of airplane : 65.500% (655/1000)
- accuracy of automobile : 66.100% (661/1000)
- accuracy of bird : 49.400% (494/1000)
- accuracy of cat : 54.700% (547/1000)
- accuracy of deer : 58.200% (582/1000)
- accuracy of dog : 55.600% (556/1000)
- accuracy of frog : 77.300% (773/1000)
- accuracy of horse : 65.000% (650/1000)
- accuracy of ship : 74.000% (740/1000)
- accuracy of truck : 73.100% (731/1000)

6.2 DenseNet
%run train.py --dataset CIFAR-10 --model DenseNet --pretrained True- Loading the dataset...
- Training on: CIFAR-10
- Using model: DenseNet
- Using the specified args:
- Namespace(batch_size=32, crop_size=224, cuda=True, dataset='CIFAR-10', dataset_root='C:\\Users\\sbzy\\Documents/GitHub/dl_algorithm/datasets\\CIFAR-10', epoch_size=20, lr=0.0002, model='DenseNet', num_workers=0, photo_folder='results/', pretrained=True, save_folder='weights/', shuffle=False)
- Epoch 1: 100%[**************************************************->]2.152 Running time: 281.216
- train loss: 2.011725, acc: 25.864% (12932/50000)
- Epoch 2: 100%[**************************************************->]1.745 Running time: 279.927
- train loss: 1.880436, acc: 31.006% (15503/50000)
- Epoch 3: 100%[**************************************************->]1.949 Running time: 328.740
- train loss: 1.832803, acc: 33.142% (16571/50000)
- Epoch 4: 100%[**************************************************->]1.841 Running time: 307.168
- train loss: 1.796165, acc: 34.670% (17335/50000)
- Epoch 5: 100%[**************************************************->]2.095 Running time: 279.075
- train loss: 1.776985, acc: 35.518% (17759/50000)
- Epoch 6: 100%[**************************************************->]1.631 Running time: 278.310
- train loss: 1.759114, acc: 36.102% (18051/50000)
- Epoch 7: 100%[**************************************************->]2.244 Running time: 279.672
- train loss: 1.742437, acc: 36.962% (18481/50000)
- Epoch 8: 100%[**************************************************->]1.967 Running time: 278.730
- train loss: 1.728809, acc: 37.422% (18711/50000)
- Epoch 9: 100%[**************************************************->]1.609 Running time: 282.537
- train loss: 1.716504, acc: 38.170% (19085/50000)
- Epoch 10: 100%[**************************************************->]1.459 Running time: 280.416
- train loss: 1.711381, acc: 38.320% (19160/50000)
- Epoch 11: 100%[**************************************************->]1.418 Running time: 279.299
- train loss: 1.705938, acc: 38.524% (19262/50000)
- Epoch 12: 100%[**************************************************->]1.376 Running time: 279.639
- train loss: 1.689652, acc: 38.984% (19492/50000)
- Epoch 13: 100%[**************************************************->]1.685 Running time: 278.627
- train loss: 1.692426, acc: 39.058% (19529/50000)
- Epoch 14: 100%[**************************************************->]1.587 Running time: 279.243
- train loss: 1.680914, acc: 39.208% (19604/50000)
- Epoch 15: 100%[**************************************************->]1.306 Running time: 277.855
- train loss: 1.683740, acc: 39.166% (19583/50000)
- Epoch 16: 100%[**************************************************->]1.839 Running time: 279.118
- train loss: 1.668011, acc: 39.766% (19883/50000)
- Epoch 17: 100%[**************************************************->]2.164 Running time: 278.432
- train loss: 1.662733, acc: 40.276% (20138/50000)
- Epoch 18: 100%[**************************************************->]2.060 Running time: 280.945
- train loss: 1.659158, acc: 40.250% (20125/50000)
- Epoch 19: 100%[**************************************************->]1.370 Running time: 280.071
- train loss: 1.656844, acc: 40.446% (20223/50000)
- Epoch 20: 100%[**************************************************->]1.381 Running time: 278.043
- train loss: 1.648796, acc: 41.018% (20509/50000)
%run test.py --dataset CIFAR-10 --model DenseNet --pretrained True- Finish loading model: weights/CIFAR-10_DenseNet.pth
- Training on: CIFAR-10
- Using model: DenseNet
- Using the specified args:
- Namespace(batch_size=32, crop_size=224, cuda=True, dataset='CIFAR-10', dataset_root='C:\\Users\\sbzy\\Documents/GitHub/dl_algorithm/datasets\\CIFAR-10', f=None, model='DenseNet', num_workers=0, pretrained=True, weight='weights/CIFAR-10_DenseNet.pth')
- test loss: 1.615522, acc: 42.230% (4223/10000)
- accuracy of airplane : 47.600% (476/1000)
- accuracy of automobile : 60.400% (604/1000)
- accuracy of bird : 22.100% (221/1000)
- accuracy of cat : 38.400% (384/1000)
- accuracy of deer : 39.800% (398/1000)
- accuracy of dog : 38.500% (385/1000)
- accuracy of frog : 54.000% (540/1000)
- accuracy of horse : 34.100% (341/1000)
- accuracy of ship : 45.400% (454/1000)
- accuracy of truck : 42.000% (420/1000)

开始实验
-
相关阅读:
centos 下 Makefile 独立模块编译ko
Promrtheus+Grafana+onealert--实现报警
Servlet规范之安全
澳元兑美元预测:美元可能因美国经济衰退担忧而进一步下跌(MogaFX)
帝国cms后台访问链接提示“非法来源”解决方法
RocketMQ消息生产者是如何选择Broker的
golang的map
有谁会易位构词c++代码啊,可以直接运行的或者需要添加完词典库就可以直接运行的
docker版jxTMS使用指南:4.6版升级内容
详探XSS PayIoad
- 原文地址:https://blog.csdn.net/a1234556667/article/details/126447030
