-
快速排序超详细讲解C语言
快速排序是由东尼·霍尔所发展的一种排序算法。在平均状况下,排序 n 个项目要 Ο(nlogn) 次比较。在最坏状况下则需要 Ο(n2) 次比较,但这种状况并不常见。事实上,快速排序通常明显比其他 Ο(nlogn) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地被实现出来。快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。
快速排序又是一种分而治之思想在排序算法上的典型应用。
基本思想
对于待排序序列,使用某种划分方法排好一个值key,使得key前面的所有值都比key小,key后面的所有值都比key大(升序),从而以key为界限分成了左右两个待排序的子序列,然后分别对子序列进行上述步骤。
框架分为两种:递归和非递归
某种划分方法分为三种:Hoare、挖坑法、前后指针法
递归版本
void QuickSort(int* a, int left, int right){ if(left >= right){ return; } //对待排序序列使用划分方法,得到基准值的下标keyi int keyi = QuickSortPart(a, left, right);//划分有三种方法 // 划分成功后以keyi为边界形成了左右两部分 [left, keyi - 1] 和 [keyi + 1, right] // 递归排[left, keyi - 1] QuickSort(a, left, keyi - 1); // 递归排[keyi + 1, right] QuickSort(a, keyi + 1, right); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
非递归版本
递归的本质实际就是在控制待排序序列的区间,而非递归版本就是用栈模拟递归去保存和使用待排序序列的区间
//使用栈的前序遍历模拟递归 void QuickSortNoR(int* a, int left, int right){ Stack obj; StackInit(&obj); StackPush(&obj, right);//将待排序序列的左右区间入栈 StackPush(&obj, left); while(!StackEmpty(&obj)){ int left = StackTop(&obj);//取出待排序序列的左右区间 StackPop(&obj); int right = StackTop(&obj); StackPop(&obj); int keyi = QuickSortPart(a, left, right);//排序区间内的数据,得到基准值的下标keyi StackPush(&obj, right);//将基准值右边的区间入栈 StackPush(&obj, keyi + 1); StackPush(&obj, keyi - 1);//将基准值左边的区间入栈 StackPush(&obj, left); } StackDestroy(&obj); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
Hoare法
算法步骤
- 从数列中选出一个基准值(key),一般为数列的第一个元素
- 从后往前遍历挑出比key小的值,停下;从前往后遍历挑出比key大的值,停下;然后交换这两个值
- 继续从后往前遍历……从前往后遍历……交换,直到左边和右边相遇记录为meeti,此时交换key和meeti的值
- 返回相遇位置meeti,从而完成分区。
动图演示

代码实现
int QuickSortPart(int* a, int left, int right){ int keyi = left; while(left < right){ while(left < right && a[right] >= a[keyi]){ right--; } while(left < right && a[left] <= a[keyi]){ left++; } if(left < right){ Swap(&a[left], &a[right]); } } int meeti = left; Swap(&a[keyi], &a[meeti]); return meeti; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
Hoare法必须先从右边开始走
因为只有先从右边开始走,才能够保证相遇位置meeti比keyi的值小,原因如下:
- 左边去相遇右边时,由于右边先停,而右边停的条件是值小于key,所以此时相遇点的值小于key
- 右边去相遇左边时,左边此时是上一次交换之后的位置,此时的左边位置的值是小于key的,所以相遇点的值小于key
挖坑法
算法步骤
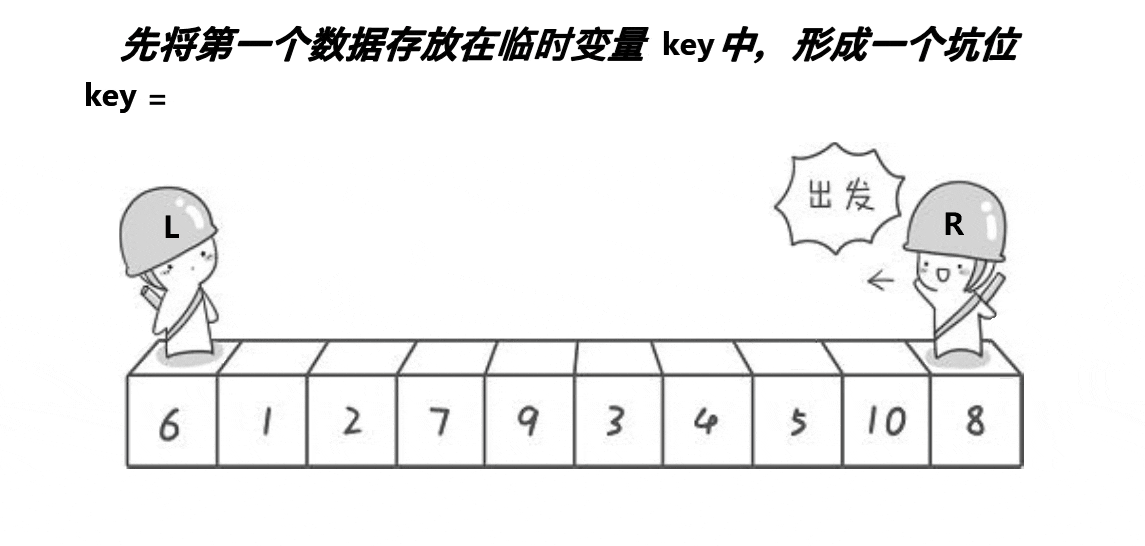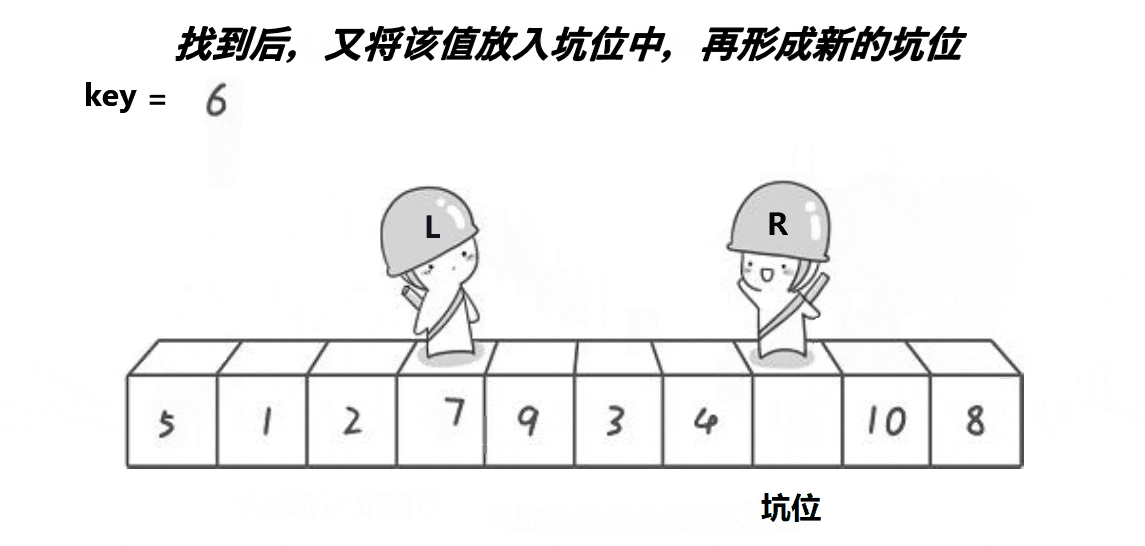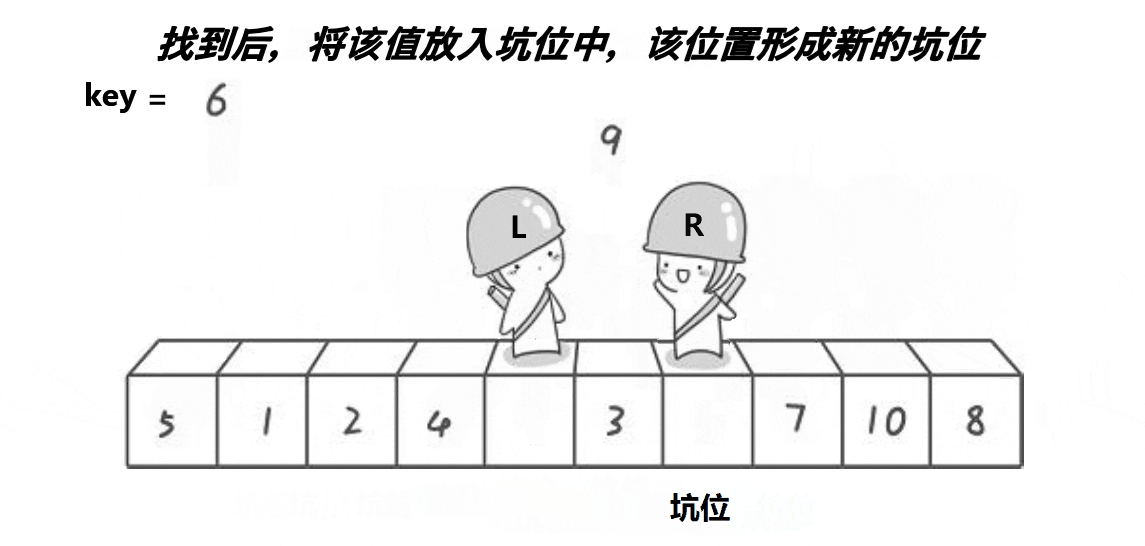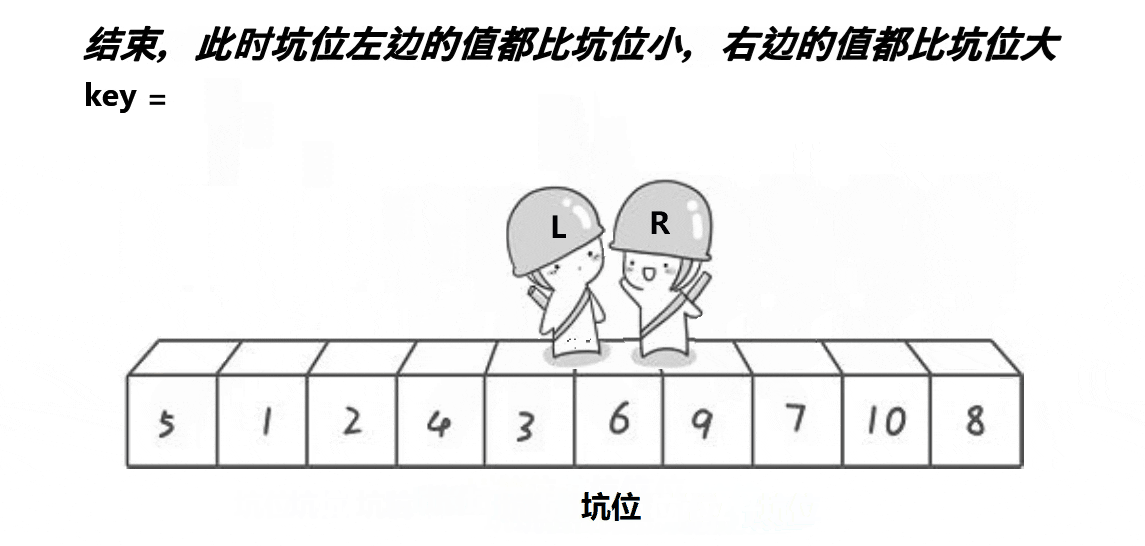
- 从数列中选出一个基准值(key),一般为数列的第一个元素,将基准值key取出,把该位置记录成一个坑hole
- 从后往前寻找比key小的值,然后将该值填入hole中,该值的原位置记录为新的hole
- 从前往后寻找比key大的值,然后将该值填入hole中,该值的原位置记录为新的hole
- 直到前后位置相遇,将key填入hole中,返回hole即可完成分区
动图演示
代码实现
int QuickSortPart(int* a, int left, int right){ int key = a[left]; int hole = left; while(left < right){ while(left < right && a[right] >= key){ right--; } a[hole] = a[right]; hole = right; while(left < right && a[left] <= key){ left++; } a[hole] = a[left]; hole = left; } a[hole] = key; return hole; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
前后指针法
算法步骤
- 从数列中选出一个基准值(key),一般为数列的第一个元素
- 前指针cur和后指针prev从前往后遍历,cur一直移动,当遇到小于key的值时,prev才往前移动,如果cur和prev不相等则交换两值(cur和prev之间有两种状态,要么prev和cur紧贴之间无数据,要么prev和cur之间有数据并且该数据是大于key的)
- 当cur遍历完之后,prev之前的数据全部小于prev,之后的数据全部大于prev,于是就从prev为界限分区了,此时返回prev
动图演示

代码实现
int QuickSortPart(int* a, int left, int right){ int keyi = left; int prev = left; int cur = left + 1; while(cur <= right){ if(a[cur] < a[keyi] && ++prev != cur){ Swap(&a[prev], &a[cur]); } cur++; } Swap(&a[keyi], &a[prev]); return prev; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
快速排序的两种优化方法(可合并使用)
优化一:
快速排序最理想的状态也就是最优的时间复杂度为 O ( N ∗ l o g N ) O(N*log^{N}) O(N∗logN),而达到这一目的的最好的情况是每次分区时,都几乎是从中间分区的,这样才能够达到把 N N N个数据分为 l o g N log^{N} logN层,而如果当待排序序列是有序时,则快速排序会把 N N N个数据分为 N N N层,就会使得时间复杂度变为 O ( N 2 ) O(N^{2}) O(N2),这是非常糟糕的,所以为了减少这种情况,出现了一个优化函数。
该函数的功能是取到序列的第一个数、中间的数、最后一个数,然后比较大小,返回大小为中间的那个数的下标。
下一步就是将该下标的值与序列的第一个值交换,这样就会造成,假设之前的序列是有序的,而现在的序列的第一个值会是序列中间的那个值,从而以该值为key分区时能够减少只分出一个区的情况,即减少把N个数据分为N层的情况。
int GetMidIndex(int* a, int begin, int end){ int mid = begin + ((end - begin) >> 1); if(a[begin] <= a[mid]){ if(a[mid] <= a[end]){ return mid; } else if(a[begin] <= a[end]){ return end; } else{ return begin; } } else{ if(a[begin] <= a[end]){ return begin; } else if(a[mid] <= a[end]){ return end; } else{ return mid; } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
该函数这样使用(以Hoare法举例)
int QuickSortPart(int* a, int left, int right){ int mid = GetMidIndex(a, left, right); Swap(&a[left], &a[mid]); //上面是优化,其它两种分区方法也是这样使用优化 int keyi = left; while(left < right){ while(left < right && a[right] >= a[keyi]){ right--; } while(left < right && a[left] <= a[keyi]){ left++; } if(left < right){ Swap(&a[left], &a[right]); } } int meeti = left; Swap(&a[keyi], &a[meeti]); return meeti; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
优化二:
快速排序的理想状态就是将 N N N个数据分成 l o g N log^{N} logN层,达到近似完全二叉树的形状,而完全二叉树的最后三层递归将会达到整个递归过程中的87.5%,而最后的三层递归也就最多只有8个数据,与其让这8个数据递归这么多次还不如直接进行插入排序,这样将会减少巨额的递归次数,从而优化排序的速度。
void QuickSort(int* a, int left, int right){ if(left >= right){ return; } if(right - left + 1 <= 8){//当数据小于等于8时,不再进行递归了,改为插入排序 Insert(a + left, right - left + 1); } else{//当数据量大于8时,才去递归 int keyi = QuickSortPart(a, left, right); QuickSort(a, left, keyi - 1); QuickSort(a, keyi + 1, right); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
复杂度、稳定性分析
-
时间复杂度
最优时间复杂度 O ( N ∗ l o g N ) O(N*log^{N}) O(N∗logN)
最差时间复杂度 O ( N 2 ) O(N^{2}) O(N2)
-
空间复杂度
最优空间复杂度 O ( l o g N ) O(log^{N}) O(logN)
最差时间复杂度 O ( N ) O(N) O(N)
递归主要消耗在栈空间,非递归主要消耗在堆上
-
稳定性
快速排序是不稳定的
-
相关阅读:
vxe-table 打包部署上线,校验样式失效
网站使用谷歌登录 oauth java nuxt auth
RestoreDet
Pytorch 入门
Flink 源码解读系列 DataStream 数据流元素 StreamElement
网络安全的主要威胁及应对方法
【LeetCode】655. 输出二叉树
Policy Gradient with Baseline
Sidecar-详解 JuiceFS CSI Driver 新模式
第2章 持久化初始数据到指定表
- 原文地址:https://blog.csdn.net/qq_67569905/article/details/126574477