-
Semantically Contrastive Learning for Low-light Image Enhancement 论文阅读笔记

这是AAAI2022的一篇无监督暗图增强论文
- introduction中提到一个重要观点:前景和背景的增强策略需要区别对待,而语义信息可以辅助进行区域的辨别,从而有利于统一物体区域内部的亮度一致性(我的理解是,其实也和空间、景深有关,在简单的光源分布下相同景深相邻区域的物体通常具有相同的照度,而同一物体区域内的像素通常具有相同的景深,并且一般还有相近的颜色,从而具有相近的亮度)。
- 文章的贡献之一是提出了一个semantic brightness consitency loss,可以利用高层任务的监督提高底层任务的效果,并且增强结果在高层任务上也有准确率上的提升。
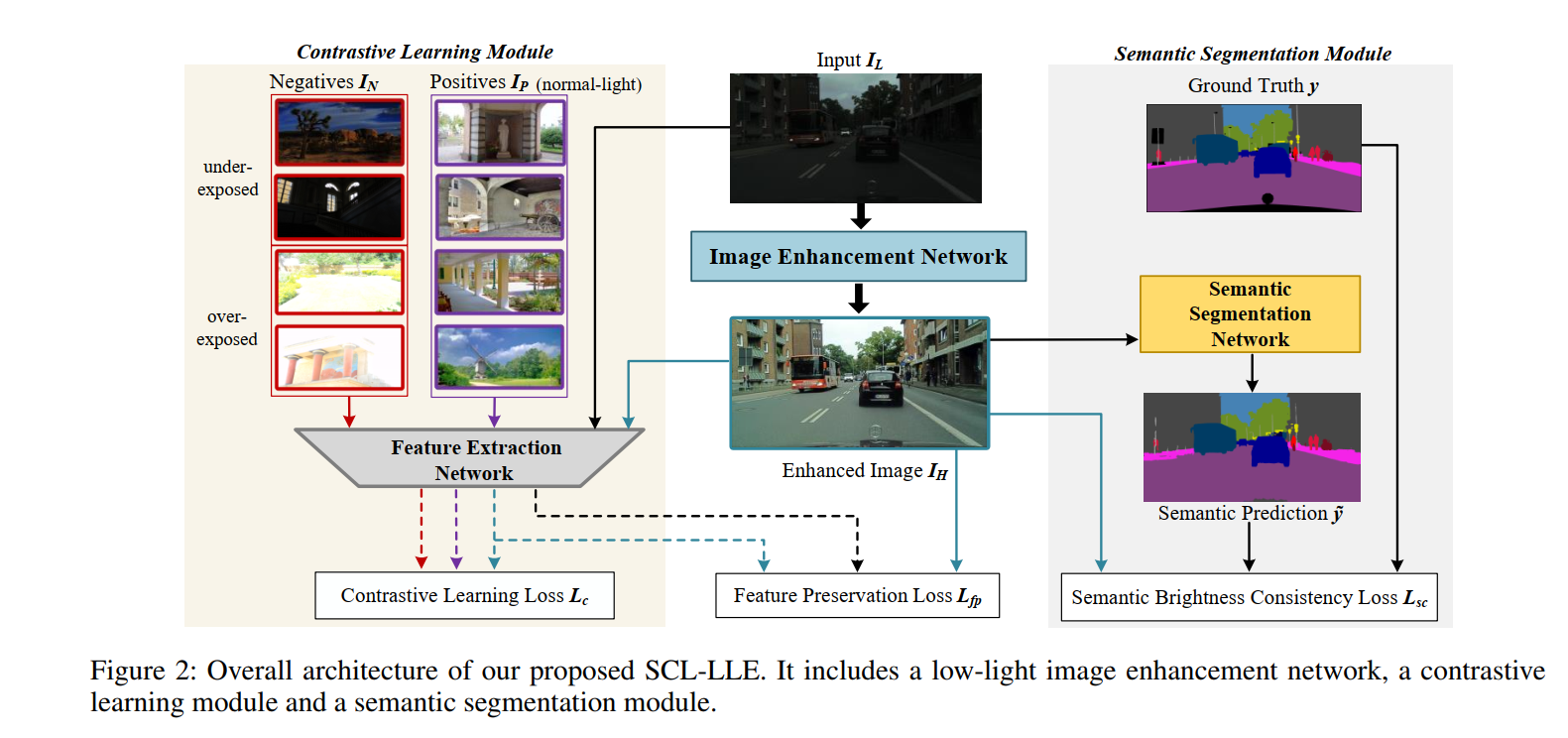
- 网络分为三个模块和三个损失,三个模块分别是增强模块(Unet结构,Zero-DCE曲线预测)、语义分割模块(DeepLabv3+)和特征提取模块(VGG16);三个损失分别是对比学习损失、semantic brightness consitency loss和特征保留损失。
对比学习部分
- 对比学习所用的正例是正常光照图片,负例是过曝和欠曝光图片,并且全部是不成对的。通过pull增强结果与正例之间的距离和push增强结构与负例之间的距离来训练增强网络。计算距离所用的特征是图片经过VGG16提取的各层特征(也就是说每层卷积产生的特征图都要用到)进行进一步计算自相关的结果,比如A图的第
l
l
l层特征各有
C
C
C个通道,那么每两个通道之间算内积可以得到一个自相关矩阵,大小为
C
×
C
C\times C
C×C,这个矩阵就是
G
l
G_l
Gl,VGG一共有
L
L
L层,所以就有
L
L
L个自相关矩阵。将增强结果的自相关矩阵集合与正例的自相关矩阵集合、负例的自相关矩阵集合之间算一个triple loss,d是距离函数

- 训练的时候,从SICE数据集的Part部分选取360张正常曝光的图片、360张欠曝光的图片、360张过曝光的图片,并在训练过程中随机匹配。
语义分割部分
- 损失函数如下:

- 其中
B
s
B_s
Bs表示第
s
s
s类的区域内像素的亮度均值:
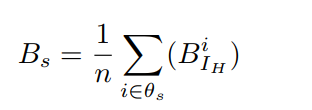
- p s p_s ps表示GT的类别, q s q_s qs表示增强结果在语义分割网络中预测的类别。这部分训练使用的是Cityscapes数据集中的暗图部分。
特征保持损失
- 其实就是增强前后图片的特征图(应该是指在VGG中的)之间的距离:

其它
- 此外还有Zero-DCE中的颜色保持损失和平滑损失

完整网络结构
训练细节
- 语义分割网络首先在Cityscapes数据集上训练,VGG首先在ImageNet上训练,然后fix这两个网络的参数,只训练enhancement网络。输入的大小resize为384x384,epoch为50,batch size为2(看起来还挺好训练的)。
实验结果
- 对比了在多个数据集上的user study、NIQE和UN指标:

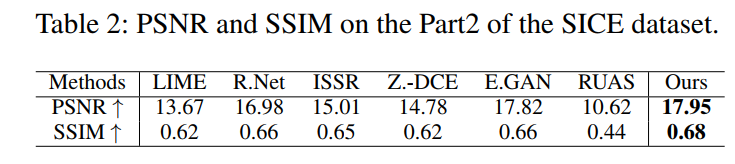
- 对比了在SICE上的PSNR和SSIM
- 对比了在Cityscapes上提高的mIOU:

-
相关阅读:
uni-app发布后iOS端页面背景图片上下滑动问题
机器如何快速学习数据采集
供热管网安全运行监测,提升供热管网安全性能
ChatGPT发展报告:原理、技术架构详解和产业未来(附下载)
佳作导读 | 《C++ Core Guidelines》
【并联有源电力滤波器】基于pq理论的并联有源电力滤波器(Simulink)
【D3.js】2.2-给 Circle 元素添加属性
ARM/DSP+FPGA运动控制机器视觉控制器方案定制
数据库基础
.NET周刊【12月第1期 2023-12-06】
- 原文地址:https://blog.csdn.net/weixin_44326452/article/details/126560750