-
概率论知识点总结(上)
参考资料
- 概率论 · 复习概要
- 何书元《概率论与数理统计》
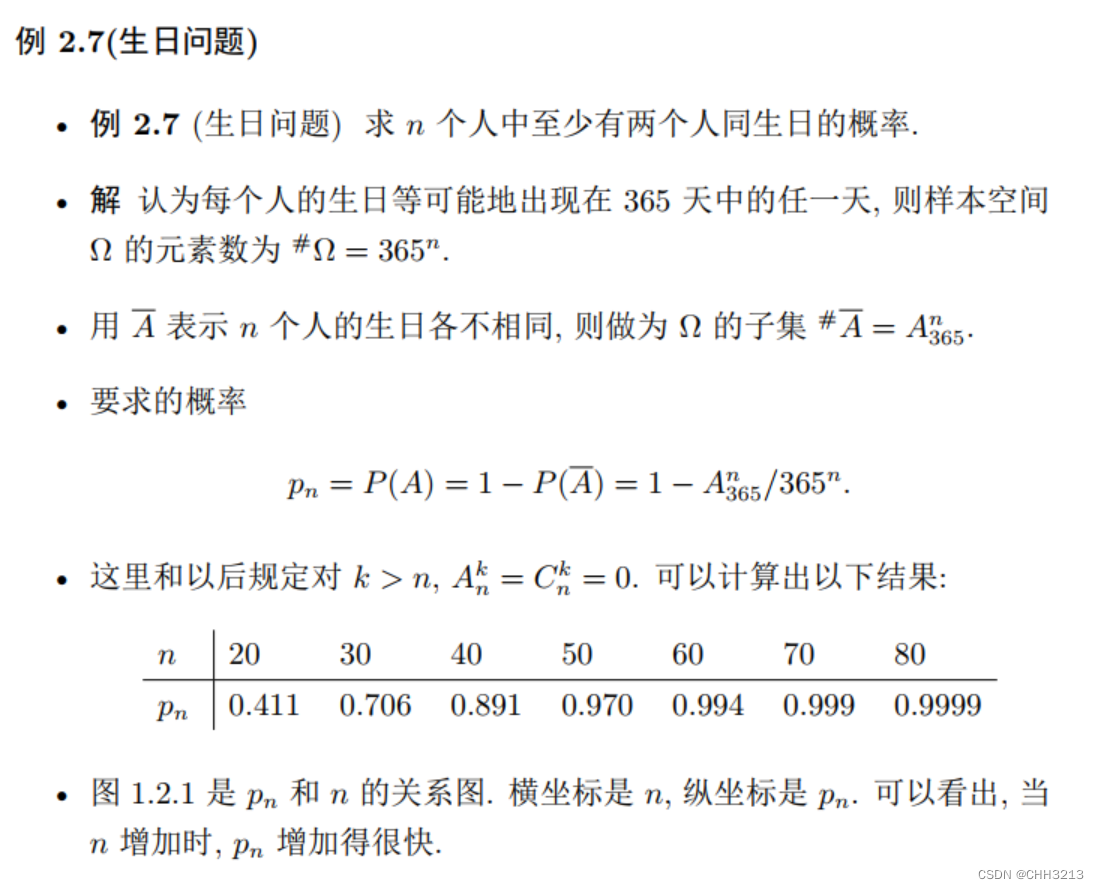
1. 随机事件与概率
1.1 古典概型
古典概型中常用计数一有重复的排列数
- 从 n n n 个不同元素中有放回地每次随机抽取一个, 共抽取 m m m 次, 有序 地记录结果, 共有 n m n^{m} nm 种等可能的不同结果。
- 例: 掷骰子 3 次, 记录每次结果, 结果一共有 6 × 6 × 6 = 6 3 6 \times 6 \times 6=6^{3} 6×6×6=63 种。
- 例: 从 52 张扑克牌中随机有放回地抽取并记录 3 次, 结果共有 5 2 3 52^{3} 523 种。
古典概型中常用计数一排列数
- 从
n
n
n 个不同元素中无放回地每次随机抽取一个, 共抽取
m
m
m 次
(
m
≤
n
)
(m \leq n)
(m≤n), 有序地记录结果, 共有
A n m = n ( n − 1 ) … ( n − m + 1 ) = n ! ( n − m ) ! A_{n}^{m}=n(n-1) \ldots(n-m+1)=\frac{n !}{(n-m) !} Anm=n(n−1)…(n−m+1)=(n−m)!n!
种等可能的不同结果。 - A n m A_{n}^{m} Anm 在有的教材中记为 P n m P_{n}^{m} Pnm 。
- 例: 从 52 张扑克牌中随机无放回地抽取 3 张, 记录每次结果, 结果有 52 × 51 × 50 = A 52 3 52 \times 51 \times 50=A_{52}^{3} 52×51×50=A523 种。
古典概型中常用计数一组合数
- 从
n
n
n 个不同元素中无放回地每次抽取一个, 共抽取
m
m
m 次
(
m
≤
n
)
(m \leq n)
(m≤n), 不计次序地记录结果 (只要元素相同, 不管次序是否相同都算是相同结 果), 共有
C n m = n ( n − 1 ) … ( n − m + 1 ) m ! = n ! m ! ( n − m ) ! C_{n}^{m}=\frac{n(n-1) \ldots(n-m+1)}{m !}=\frac{n !}{m !(n-m) !} Cnm=m!n(n−1)…(n−m+1)=m!(n−m)!n!
种等可能的不同结果。 - 例: 从一副扑克牌的 4 张 A 中随机无放回抽取 2 张组成一手牌, 不计 次序。有 C 4 2 = 4 × 3 / 2 = 6 C_{4}^{2}=4 \times 3 / 2=6 C42=4×3/2=6 种结果。
古典概型中常用计数一分组方式数
- 将
n
n
n 个不同元素分成有序号的
k
k
k 组, 要求第
i
i
i 组恰好有
n
i
n_{i}
ni 个元素
(
i
=
1
,
2
,
…
,
k
)
(i=1,2, \ldots, k)
(i=1,2,…,k), 分组结果中同组的元素不考虑次序。则这样分组的 所有不同分法个数为
( n n 1 , n 2 , … , n k ) = n ! n 1 ! n 2 ! … n k ! . \left(\right)=\frac{n !}{n_{1} ! n_{2} ! \ldots n_{k} !} . (nn1,n2,…,nk)=n1!n2!…nk!n!.n n 1 , n 2 , … , n k - 当随机分组时, 这些分法是等可能的。
- 随机分组的方法是 n n n 个元素随机排列 ( n n n ! 种排法), 然后前 n 1 n_{1} n1 个不计 次序地归入 i = 1 i=1 i=1 组, 后续 n 2 n_{2} n2 个不计次序地归入 i = 2 i=2 i=2 组, 以此类推。
- 例 10 个学生分成
A
,
B
,
C
\mathrm{A}, \mathrm{B}, \mathrm{C}
A,B,C 三个组, 分别有 3、3、4人, 组内不计次 序。
分组方式个数为
10 ! 3 ! 3 ! 4 ! ≜ ( 10 3 , 3 , 4 ) \frac{10 !}{3 ! 3 ! 4 !} \triangleq\left(\right) 3!3!4!10!≜(103,3,4)10 3 , 3 , 4
古典概型中常用计数一可重复分组数
- 从 n n n 个不同的球中有放回地每次抽取一个, 共抽取 m m m 次, 结果不计 次序。共有 C n + m − 1 m C_{n+m-1}^{m} Cn+m−1m 种不同的组合。
- 用 0 和 1 组成的序列表示一个结果。
- 用 n − 1 n-1 n−1 个 1 分隔出 n n n 个组, 1 表示组边界。这 n n n 个组是结果排序后 球号 1 , 2 , … , n 1,2, \ldots, n 1,2,…,n 的组。
- 每组内有若干个 0 表示该组个数, 如果出现 11 则该组没有球, 把 m m m 个 0 分配到各个组中。
- 这样, 用长度为 n + m − 1 n+m-1 n+m−1 的 0-1 向量表示一个结果, 结果个数为 C n + m − 1 n − 1 C_{n+m-1}^{n-1} Cn+m−1n−1 (从 n + m − 1 n+m-1 n+m−1 个二进制位中选择 1 的位置, 即边界的位置)。
- 可重复分组数在随机分组时一般不是等可能的。
- 例如, 从红、白两个球中有放回地抽取 2 次, 计数这 2 次红球、白球 个数。共有 (红 0 , 白 2 ) , ( ),( ),( 红 1 , 白 1 ) , ( ),( ),( 红 2 , 白 0 ) ) ) 三种结果, 即 C 2 + 2 − 1 2 = 3 C_{2+2-1}^{2}=3 C2+2−12=3 种结果。随机抽取时 (红 1 , 白 1) 概率为 1 2 \frac{1}{2} 21, (红 0 , 白 2) 和 (红 2 , 白 0 ) 0) 0) 的概率都是 1 4 \frac{1}{4} 41 。
例题
1.2 加法公式与乘法公式
和事件的概率 P ( A ∪ B ) P(A \cup B) P(A∪B) 在不同场合下的求法:
-
一般形式:
P ( A ∪ B ) = P ( A ) + P ( B ) − P ( A B ) P ( A ∪ B ∪ C ) = P ( A ) + P ( B ) + P ( C ) − P ( A B ) − P ( A C ) − P ( B C ) + P ( A B C ) .P(A∪B)P(A∪B∪C)=P(A)+P(B)−P(AB)=P(A)+P(B)+P(C)−P(AB)−P(AC)−P(BC)+P(ABC).P ( A ∪ B ) = P ( A ) + P ( B ) − P ( A B ) P ( A ∪ B ∪ C ) = P ( A ) + P ( B ) + P ( C ) − P ( A B ) − P ( A C ) − P ( B C ) + P ( A B C ) . -
若 A , B A, B A,B 互不相容: P ( A ∪ B ) = P ( A ) + P ( B ) P(A \cup B)=P(A)+P(B) P(A∪B)=P(A)+P(B).
-
若 A , B A, B A,B 相互独立:
P ( A ∪ B ) = 1 − P ( A ∪ B ‾ ) = 1 − P ( A ˉ B ˉ ) = 1 − P ( A ˉ ) P ( B ˉ )P(A∪B)=1−P(A∪B)=1−P(AˉBˉ)=1−P(Aˉ)P(Bˉ)P ( A ∪ B ) = 1 − P ( A ∪ B ¯ ) = 1 − P ( A ¯ B ¯ ) = 1 − P ( A ¯ ) P ( B ¯ )
积事件的概率 P ( A B ) P(A B) P(AB) 的求法:
- 一般形式:
P ( A B ) = P ( A ) P ( B ∣ A ) = P ( B ) P ( A ∣ B ) . P(A B)=P(A) P(B \mid A)=P(B) P(A \mid B) . P(AB)=P(A)P(B∣A)=P(B)P(A∣B). - 若
A
,
B
A, B
A,B 相互独立:
P ( A B ) = P ( A ) P ( B ) . P(A B)=P(A) P(B) . P(AB)=P(A)P(B).
乘法公式来自于条件概率公式:
P ( B ∣ A ) = P ( A B ) P ( A ) P(B \mid A)=\frac{P(A B)}{P(A)} P(B∣A)=P(A)P(AB)
1.3 全概率公式和 Bayes 公式
全概率公式
P ( A ) = P ( A B 1 ) + P ( A B 2 ) + ⋯ + P ( A B n ) = P ( B 1 ) P ( A ∣ B 1 ) + P ( B 2 ) P ( A ∣ B 2 ) + ⋯ + P ( B n ) P ( A ∣ B n ) .P(A)=P(AB1)+P(AB2)+⋯+P(ABn)=P(B1)P(A∣B1)+P(B2)P(A∣B2)+⋯+P(Bn)P(A∣Bn).P ( A ) = P ( A B 1 ) + P ( A B 2 ) + ⋯ + P ( A B n ) = P ( B 1 ) P ( A ∣ B 1 ) + P ( B 2 ) P ( A ∣ B 2 ) + ⋯ + P ( B n ) P ( A ∣ B n ) .
Bayes 公式
P ( B i ∣ A ) = P ( B i ) P ( A ∣ B i ) ∑ j = 1 n P ( B j ) P ( A ∣ B j ) , i = 1 , 2 , ⋯ , n . P\left(B_{i} \mid A\right)=\frac{P\left(B_{i}\right) P\left(A \mid B_{i}\right)}{\sum_{j=1}^{n} P\left(B_{j}\right) P\left(A \mid B_{j}\right)}, \quad i=1,2, \cdots, n . P(Bi∣A)=∑j=1nP(Bj)P(A∣Bj)P(Bi)P(A∣Bi),i=1,2,⋯,n.
Bayes 公式本质上是条件概率公式:
P ( B i ∣ A ) = P ( A B i ) P ( A ) , P\left(B_{i} \mid A\right)=\frac{P\left(A B_{i}\right)}{P(A)}, P(Bi∣A)=P(A)P(ABi),
只是其分子、分母进一步分别使用了乘法公式和全概率公式.- 全概率公式表达了 “综合考虑引起结果 A A A 的各种原因 B i B_{i} Bi, 计算导致结果 A A A 出现的可能性的大小”; 如果一个事件的发生有多个 “诱因”, 就要用到全概率公式.
- Bayes 公式则反映了 “当结果 A A A 出现时, 它是由原因 B i B_{i} Bi 引起的可能性的大小”. Bayes 公式常用来 追究责任, 或者 “执果索因”. 也就是计算各个 “诱因” 对事件发生的 “贡献”.
例题:
发报台分别以概率0.6和0.4发出信号“1”和“0”。由于通讯系统受到干扰,当发出信号“1”时,收报台未必收到信号“1”,而是分别以概率0.8和0.2收到信号“1”和“0”;同时,当发出信号“0”时,收报台分别以概率0.9和0.1收到信号“0”和“1”。求(1)收报台收到信号“1”的概率;(2)当收报台收到信号“1”时,发报台确是发出信号“1”的概率。
正确答案:
设A1=“发出信号1”,A0=“发出信号0”,A=“收到信号1”
(1)由全概率公式,有P(A)=P(A|A1)P(A1)+P(A|A0)P(A0)=0.8x0.6+0.1x0.4=0.52
(2)由贝叶斯公式,有P(A1|A)=P(A|A1)P(A1)/P(A)=0.8x0.6/0.52=12/13
2. 随机变量及其概率分布
2.0 密度函数与分布函数
概率密度函数定义
- 设
X
X
X 是随机变量, 如果存在非负函数
f
(
x
)
f(x)
f(x) 使得对任何满 足
−
∞
≤
a
<
b
≤
∞
-\infty \leq a−∞≤a<b≤∞ 的
a
,
b
a, b
a,b, 有
P ( a < X ≤ b ) = ∫ a b f ( x ) d x , P(aP(a<X≤b)=∫abf(x)dx,
就称 X X X 是连续型随机变量, 称 f ( x ) f(x) f(x) 是 X X X 的概率密度函数, 简称为概 率密度 (probability density) 或密度.
分布密度性质
-
设 f ( x ) f(x) f(x) 是 X X X 的概率密度, 则 f ( x ) f(x) f(x) 有如下的基本性质.
(a) ∫ − ∞ ∞ f ( x ) d x = 1 \int_{-\infty}^{\infty} f(x) d x=1 ∫−∞∞f(x)dx=1,
(b) P ( X = a ) = 0 P(X=a)=0 P(X=a)=0. 于是 P ( a < X ≤ b ) = P ( a ≤ X ≤ b ) P(aP(a<X≤b)=P(a≤X≤b) , -
证明: (a) 由
∫ − ∞ ∞ f ( x ) d x = P ( − ∞ < X ≤ ∞ ) = 1 \int_{-\infty}^{\infty} f(x) d x=P(-\infty∫−∞∞f(x)dx=P(−∞<X≤∞)=1
可得。 -
(b)
Pr ( X = a ) ≤ Pr ( X ∈ ( a − ε , a ] ) = ∫ a − ε a f ( x ) d x → 0 , ε → 0. \operatorname{Pr}(X=a) \leq \operatorname{Pr}(X \in(a-\varepsilon, a])=\int_{a-\varepsilon}^{a} f(x) d x \rightarrow 0, \quad \varepsilon \rightarrow 0 . Pr(X=a)≤Pr(X∈(a−ε,a])=∫a−εaf(x)dx→0,ε→0.
概率分布函数定义
- 对随机变量
X
X
X, 称
x
x
x 的函数
F ( x ) = P ( X ≤ x ) , − ∞ ≤ x ≤ ∞ , F(x)=P(X \leq x), \quad-\infty \leq x \leq \infty, F(x)=P(X≤x),−∞≤x≤∞,
为 X X X 的概率分布函数, 简称为分布函数 (distribution function), 也称 为累积 (cumulative) 分布函数。 - 例: Φ ( x ) = ∫ − ∞ x φ ( t ) d t \Phi(x)=\int_{-\infty}^{x} \varphi(t) d t Φ(x)=∫−∞xφ(t)dt 是标准正态分布的分布函数.
离散型随机变量的分布函数
- 从定义看出, 如果
X
X
X 是离散型随机变量, 有概率分布
p k = P ( X = x k ) , k = 1 , 2 , ⋯ , p_{k}=P\left(X=x_{k}\right), k=1,2, \cdots, pk=P(X=xk),k=1,2,⋯,
则 X X X 的分布函数
F ( x ) = P ( X ≤ x ) = P ( ⋃ j : x j ≤ x { X = x j } ) = ∑ j : x j ≤ x p j F(x)=P(X \leq x)=P\left(\bigcup_{j: x_{j} \leq x}\left\{X=x_{j}\right\}\right)=\sum_{j: x_{j} \leq x} p_{j} F(x)=P(X≤x)=P⎝ ⎛j:xj≤x⋃{X=xj}⎠ ⎞=j:xj≤x∑pj - 是单调不减的阶梯函数.
连续型随机变量的分布函数
- 如果
X
X
X 是连续型随机变量, 有概率密度
f
(
x
)
f(x)
f(x), 则
F ( x ) = ∫ − ∞ x f ( t ) d t F(x)=\int_{-\infty}^{x} f(t) d t F(x)=∫−∞xf(t)dt
是连续函数, 并且在 f ( x ) f(x) f(x) 的连续点 x x x 有 f ( x ) = F ′ ( x ) f(x)=F^{\prime}(x) f(x)=F′(x). 我们称 F ( x ) F(x) F(x) 是 f ( x ) f(x) f(x) 的分布函数.
分布函数性质
- 分布函数
F
(
x
)
F(x)
F(x) 的常用性质:
(1) F F F 单调不减右连续,
(2) F ( ∞ ) = 1 , F ( − ∞ ) = 0 F(\infty)=1, F(-\infty)=0 F(∞)=1,F(−∞)=0.
证明
- (1) 对
x
<
y
x
x<y , 单调不减性由
{ x < X ≤ y } = { X ≤ y } − { X ≤ x } \{x{x<X≤y}={X≤y}−{X≤x}
和 P ( x < X ≤ y ) = P ( X ≤ y ) − P ( X ≤ x ) = F ( y ) − F ( x ) ≥ 0 P(xP(x<X≤y)=P(X≤y)−P(X≤x)=F(y)−F(x)≥0 得到. - 由于
n
n
n 越大, 集合
{
X
≤
x
+
1
/
n
}
\{X \leq x+1 / n\}
{X≤x+1/n} 越小, 所以用
F
F
F 的单调性和概率
P
P
P 的连续性得到
lim δ ↓ 0 F ( x + δ ) = lim n → ∞ F ( x + 1 / n ) = lim n → ∞ P ( X ≤ x + 1 / n ) = P ( ∩ n = 1 ∞ { X ≤ x + 1 / n } ) = P ( X ≤ x ) = F ( x ) .δ↓0limF(x+δ)=n→∞limF(x+1/n)=n→∞limP(X≤x+1/n)=P(∩n=1∞{X≤x+1/n})=P(X≤x)=F(x).lim δ ↓ 0 F ( x + δ ) = lim n → ∞ F ( x + 1 / n ) = lim n → ∞ P ( X ≤ x + 1 / n ) = P ( ∩ n = 1 ∞ { X ≤ x + 1 / n } ) = P ( X ≤ x ) = F ( x ) . - (2) 由 F ( ∞ ) = P ( X ≤ ∞ ) = P ( Ω ) = 1 F(\infty)=P(X \leq \infty)=P(\Omega)=1 F(∞)=P(X≤∞)=P(Ω)=1 和 F ( − ∞ ) = P ( X ≤ − ∞ ) = F(-\infty)=P(X \leq-\infty)= F(−∞)=P(X≤−∞)= P ( ∅ ) = 0 P(\emptyset)=0 P(∅)=0 得到 (2).
2.1 已知密度函数 f ( x ) f(x) f(x), 求分布函数 F ( x ) F(x) F(x)
密度函数 f ( x ) f(x) f(x) 一般是分段函数. 由 f ( x ) f(x) f(x) 求 F ( x ) F(x) F(x), 本质上是分段函数求积分的问题!
典型例题:
设随机变量 X X X 具有概率密度
f ( x ) = { k x , 0 ⩽ x < 3 , 2 − x 2 , 3 ⩽ x ⩽ 4 , 0 , 其它. f(x)=f(x)=⎩ ⎨ ⎧kx,2−2x,0,0⩽x<3,3⩽x⩽4, 其它. { k x , 0 ⩽ x < 3 , 2 − x 2 , 3 ⩽ x ⩽ 4 , 0 , 其它.
(1) 确定常数 k k k; (2) 求 X X X 的分布函数 F ( x ) F(x) F(x); (3) 求 P { 1 < X ⩽ 3.5 } P\{1P{1<X⩽3.5} .解
(1) 由 ∫ − ∞ + ∞ f ( x ) d x = 1 \int_{-\infty}^{+\infty} f(x) \mathrm{d} x=1 ∫−∞+∞f(x)dx=1, 得
∫ 0 3 k x d x + ∫ 3 4 ( 2 − x 2 ) d x = 1 , \int_{0}^{3} k x \mathrm{~d} x+\int_{3}^{4}\left(2-\frac{x}{2}\right) \mathrm{d} x=1, ∫03kx dx+∫34(2−2x)dx=1,
解得 k = 1 6 k=\frac{1}{6} k=61.(2) 对 F ( x ) = ∫ − ∞ x f ( t ) d t F(x)=\int_{-\infty}^{x} f(t) \mathrm{d} t F(x)=∫−∞xf(t)dt,
- x < 0 x<0 x<0 时, F ( x ) = ∫ − ∞ x f ( t ) d t = ∫ − ∞ x 0 d t = 0 F(x)=\int_{-\infty}^{x} f(t) \mathrm{d} t=\int_{-\infty}^{x} 0 \mathrm{~d} t=0 F(x)=∫−∞xf(t)dt=∫−∞x0 dt=0.
- 0 ⩽ x < 3 0 \leqslant x<3 0⩽x<3 时, F ( x ) = ∫ − ∞ 0 0 d t + ∫ 0 x t 6 d t = x 2 12 F(x)=\int_{-\infty}^{0} 0 \mathrm{~d} t+\int_{0}^{x} \frac{t}{6} \mathrm{~d} t=\frac{x^{2}}{12} F(x)=∫−∞00 dt+∫0x6t dt=12x2.
-
3
⩽
x
<
4
3 \leqslant x<4
3⩽x<4 时,
F ( x ) = ∫ − ∞ 0 0 d t + ∫ 0 3 t 6 d t + ∫ 3 x ( 2 − t 2 ) d t = − 3 + 2 x − x 2 4F(x)=∫−∞00 dt+∫036t dt+∫3x(2−2t)dt=−3+2x−4x2F ( x ) = ∫ − ∞ 0 0 d t + ∫ 0 3 t 6 d t + ∫ 3 x ( 2 − t 2 ) d t = − 3 + 2 x − x 2 4 -
x
⩾
4
x \geqslant 4
x⩾4 时,
F
(
x
)
=
1
F(x)=1
F(x)=1.
即
F ( x ) = { 0 , x < 0 x 2 12 , 0 ⩽ x < 3 − 3 + 2 x − x 2 4 , 3 ⩽ x < 4 , 1 , x ⩾ 4 F(x)=F(x)=⎩ ⎨ ⎧0,12x2,−3+2x−4x2,1,x<00⩽x<33⩽x<4,x⩾4{ 0 , x < 0 x 2 12 , 0 ⩽ x < 3 − 3 + 2 x − x 2 4 , 3 ⩽ x < 4 , 1 , x ⩾ 4
做完一定要验算: F ′ ( x ) = f ( x ) F^{\prime}(x)=f(x) F′(x)=f(x).
(3) P { 1 < x ⩽ 3.5 } = F ( 3.5 ) − F ( 1 ) = 41 / 48 P\{1
P{1<x⩽3.5}=F(3.5)−F(1)=41/48 .2.2 随机变量的函数
已知连续型随机变量 X X X 的概率密度 f X ( x ) f_{X}(x) fX(x), 求随机变量 Y = g ( X ) Y=g(X) Y=g(X) 的概率密度 f Y ( y ) f_{Y}(y) fY(y), 两种方法:
- 分布函数微分法
已知随机变量 X X X 具有概率密度
f X ( x ) = { f ( x ) , a < x < b , 0 , 其他. f_{X}(x)=fX(x)={f(x),0,a<x<b, 其他. { f ( x ) , a < x < b , 0 , 其他.
对随机变量 Y = g ( X ) Y=g(X) Y=g(X), 要求 f Y ( y ) f_{Y}(y) fY(y). 则对函数关系 y = g ( x ) y=g(x) y=g(x), 给出反函数 x = h ( y ) x=h(y) x=h(y), 有
f Y ( y ) = { f ( h ( y ) ) ⋅ ∣ h ′ ( y ) ∣ , a < h ( y ) < b , 0 , 其他. f_{Y}(y)=fY(y)={f(h(y))⋅∣h′(y)∣,0,a<h(y)<b, 其他. { f ( h ( y ) ) ⋅ | h ′ ( y ) | , a < h ( y ) < b , 0 , 其他.
其中函数 y = g ( x ) y=g(x) y=g(x) 处处可导且单调. - 积分转化法.
典型例题:
设随机变量 X X X 具有概率密度
f X ( x ) = { x 8 , 0 < x < 4 , 0 , 其他. f_{X}(x)=fX(x)={8x,0,0<x<4, 其他. { x 8 , 0 < x < 4 , 0 , 其他.
求 Y = 2 X + 8 Y=2 X+8 Y=2X+8 的概率密度 f Y ( y ) f_{Y}(y) fY(y).解 先求 Y Y Y 的分布函数. (请自已注明下述各个步骤的理由.)
F Y ( y ) = P { Y ⩽ y } = P { 2 X + 8 ⩽ y } = P { X ⩽ y − 8 2 } = ∫ − ∞ y − 8 2 f X ( x ) d xFY(y)=P{Y⩽y}=P{2X+8⩽y}=P{X⩽2y−8}=∫−∞2y−8fX(x)dxF Y ( y ) = P { Y ⩽ y } = P { 2 X + 8 ⩽ y } = P { X ⩽ y − 8 2 } = ∫ − ∞ y − 8 2 f X ( x ) d x
注意到积分上限函数求导法则 ( ∫ − ∞ φ ( x ) f ( x ) d x ) ′ = f ( φ ( x ) ) φ ′ ( x ) \left(\int_{-\infty}^{\varphi(x)} f(x) \mathrm{d} x\right)^{\prime}=f(\varphi(x)) \varphi^{\prime}(x) (∫−∞φ(x)f(x)dx)′=f(φ(x))φ′(x), 上式两端关于 y y y 求导, 得
f Y ( y ) = f X ( y − 8 2 ) ⋅ ( y − 8 2 ) y ′ = 1 2 f X ( y − 8 2 ) = { 1 2 ⋅ y − 8 2 , 0 < y − 8 2 < 4 , 0 , 其他. = { y − 8 32 , 8 < y < 16 , 0 , 其他.fY(y)=fX(2y−8)⋅(2y−8)y′=21fX(2y−8)={21⋅2y−8,0,0<2y−8<4, 其他. ={32y−8,0,8<y<16, 其他. f Y ( y ) = f X ( y − 8 2 ) ⋅ ( y − 8 2 ) y ′ = 1 2 f X ( y − 8 2 ) = { 1 2 ⋅ y − 8 2 , 0 < y − 8 2 < 4 , 0 , 其他. = { y − 8 32 , 8 < y < 16 , 0 , 其他.
上述方法体现为下面的一般结论. 称为单调函数公式法:2.3 正态分布
- 正态分布的标准化: 若
X
∼
N
(
μ
,
σ
2
)
X \sim N\left(\mu, \sigma^{2}\right)
X∼N(μ,σ2), 则
X
−
μ
σ
∼
N
(
0
,
1
)
\frac{X-\mu}{\sigma} \sim N(0,1)
σX−μ∼N(0,1).
对一般的随机变量也可以 “标准化”, 即使它不一定服从正态分布. 事实上, X X X 标准化变量为
X ∗ = X − E ( X ) D ( X ) , X^{*}=\frac{X-E(X)}{\sqrt{D(X)}}, X∗=D(X)X−E(X),
则
E ( X ∗ ) = 0 , D ( X ∗ ) = 1. E\left(X^{*}\right)=0, \quad D\left(X^{*}\right)=1 . E(X∗)=0,D(X∗)=1. - 正态分布的再生性: 设
X
,
Y
X, Y
X,Y 相互独立,
X
∼
N
(
μ
1
,
σ
1
2
)
,
Y
∼
N
(
μ
2
,
σ
2
2
)
X \sim N\left(\mu_{1}, \sigma_{1}^{2}\right), Y \sim N\left(\mu_{2}, \sigma_{2}^{2}\right)
X∼N(μ1,σ12),Y∼N(μ2,σ22), 则
X + Y ∼ N ( μ 1 + μ 2 , σ 1 2 + σ 2 2 ) a X ± b Y ∼ N ( a μ 1 ± b μ 2 , a 2 σ 1 2 + b 2 σ 2 2 ) .X+Y∼N(μ1+μ2,σ12+σ22)aX±bY∼N(aμ1±bμ2,a2σ12+b2σ22).X + Y ∼ N ( μ 1 + μ 2 , σ 1 2 + σ 2 2 ) a X ± b Y ∼ N ( a μ 1 ± b μ 2 , a 2 σ 1 2 + b 2 σ 2 2 ) . - Φ ( − x ) = 1 − Φ ( x ) \Phi(-x)=1-\Phi(x) Φ(−x)=1−Φ(x).
- z 1 − α = − z α z_{1-\alpha}=-z_{\alpha} z1−α=−zα.
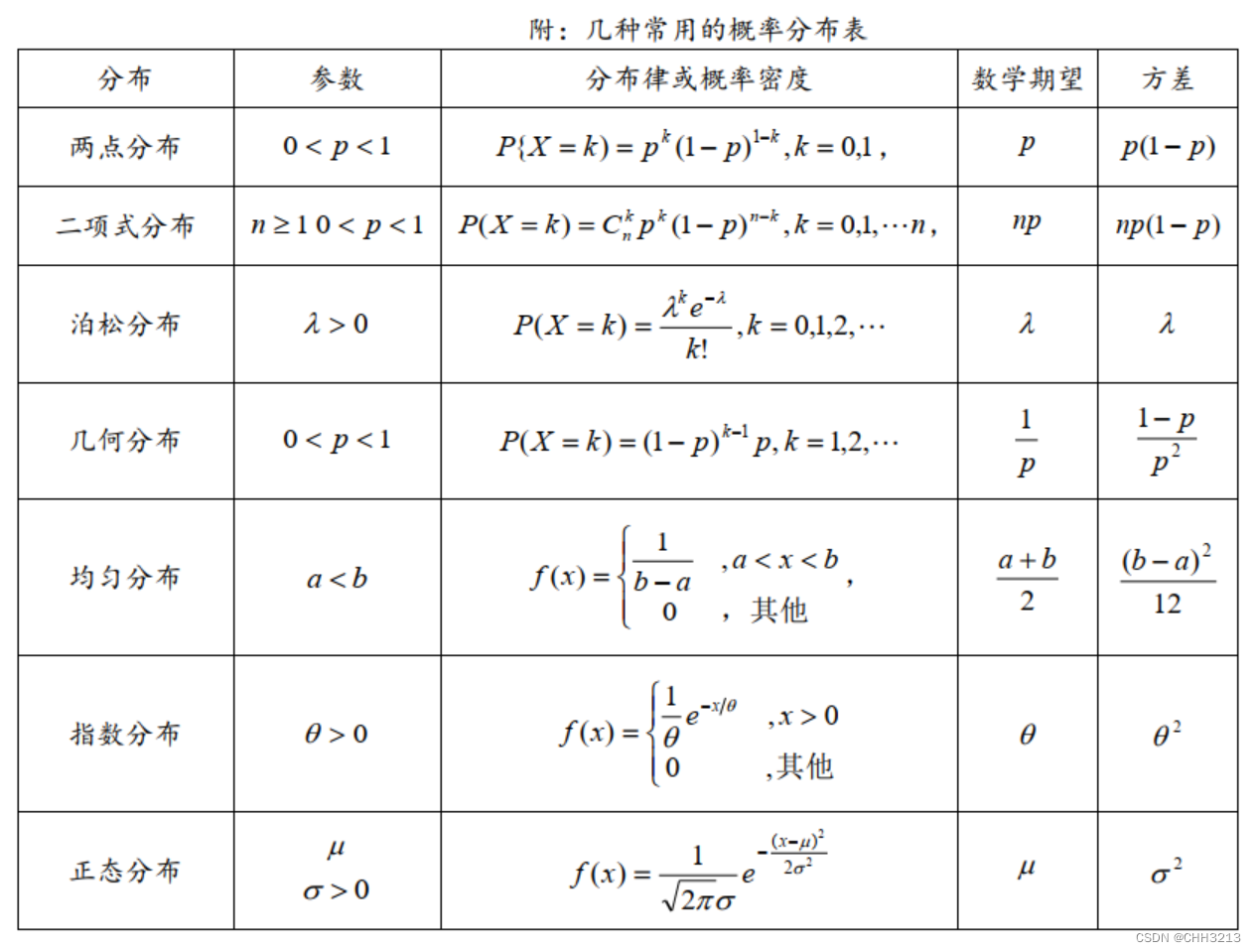
2.4 常用的概率分布表
3. 多维随机变量及其概率分布
3.1 边缘分布与边缘密度
边缘分布
- 设
F
(
x
,
y
)
F(x, y)
F(x,y) 是
(
X
,
Y
)
(X, Y)
(X,Y) 的联合分布, 则
X
,
Y
X, Y
X,Y 分别有概率分布
F X ( x ) = P ( X ≤ x , Y ≤ ∞ ) = F ( x , ∞ ) , F Y ( y ) = P ( X ≤ ∞ , Y ≤ y ) = F ( ∞ , y ) .FX(x)=P(X≤x,Y≤∞)=F(x,∞),FY(y)=P(X≤∞,Y≤y)=F(∞,y).F X ( x ) = P ( X ≤ x , Y ≤ ∞ ) = F ( x , ∞ ) , F Y ( y ) = P ( X ≤ ∞ , Y ≤ y ) = F ( ∞ , y ) .
我们称 X X X 的分布函数 F X ( x ) , Y F_{X}(x), Y FX(x),Y 的分布函数 F Y ( x ) F_{Y}(x) FY(x) 为 ( X , Y ) (X, Y) (X,Y) 的边缘 分布函数 (marginal distribution function).
边缘密度
- 设 f ( x , y ) f(x, y) f(x,y) 是随机向量 ( X , Y ) (X, Y) (X,Y) 的概率密度, 则 X X X 和 Y Y Y 也都是连续型 随机变量, 我们称 X , Y X, Y X,Y 各自的概率密度为 f ( x , y ) f(x, y) f(x,y) 或 ( X , Y ) (X, Y) (X,Y) 的边缘 密度 (marginal density).
- 对任何
a
<
b
aa<b, 有
P ( a < X ≤ b ) = P ( a < X ≤ b , Y < ∞ ) = ∫ a b ( ∫ − ∞ ∞ f ( x , y ) d y ) d xP(a<X≤b)=P(a<X≤b,Y<∞)=∫ab(∫−∞∞f(x,y)dy)dxP ( a < X ≤ b ) = P ( a < X ≤ b , Y < ∞ ) = ∫ a b ( ∫ − ∞ ∞ f ( x , y ) d y ) d x
由概率密度的定义知道 X X X 有边缘密度
f X ( x ) = ∫ − ∞ ∞ f ( x , y ) d y . f_{X}(x)=\int_{-\infty}^{\infty} f(x, y) d y . fX(x)=∫−∞∞f(x,y)dy. - 完全对称地得到
Y
Y
Y 的边缘函数
f Y ( y ) = ∫ − ∞ ∞ f ( x , y ) d x f_{Y}(y)=\int_{-\infty}^{\infty} f(x, y) d x fY(y)=∫−∞∞f(x,y)dx
联合分布与联合密度
- 设
(
X
,
Y
)
(X, Y)
(X,Y) 有连续的分布函数
F
(
x
,
y
)
F(x, y)
F(x,y), 定义
f ( x , y ) = { ∂ 2 F ( x , y ) ∂ x ∂ y , 当该混合偏导数存在, 0 , 其他. f(x, y)=f(x,y)={∂x∂y∂2F(x,y),0, 当该混合偏导数存在, 其他. { ∂ 2 F ( x , y ) ∂ x ∂ y , 当该混合偏导数存在, 0 , 其他.
如果
∬ R 2 f ( x , y ) d x d y = 1 , \iint_{R^{2}} f(x, y) d x d y=1, ∬R2f(x,y)dxdy=1,
则 f ( x , y ) f(x, y) f(x,y) 是 ( X , Y ) (X, Y) (X,Y) 的联合密度.
独立性的判断, 即看下列式子是否成立:
联合 = 边缘 × 边缘 . 联合 = 边缘 \times 边缘. 联合=边缘×边缘.联合概率计算的例子
- 两人某天在 1 点至 2 点间独立地随机到达某地会面, 先到者等 候 20 分钟后离去. 求这两人能相遇的概率.
- 解 认为每个人在 0 至 60 分钟内等可能到达, 用
X
,
Y
X, Y
X,Y 分别表示他们 的到达时间. 则
X
∼
U
(
0
,
60
)
,
Y
∼
U
(
0
,
60
)
,
X
,
Y
X \sim \mathrm{U}(0,60), Y \sim \mathrm{U}(0,60), X, Y
X∼U(0,60),Y∼U(0,60),X,Y 独立. 利用
f X ( x ) = f Y ( x ) = { 1 60 , x ∈ ( 0 , 60 ) , 0 , x ∉ ( 0 , 60 ) , f_{X}(x)=f_{Y}(x)=fX(x)=fY(x)={601,0,x∈(0,60),x∈/(0,60),{ 1 60 , x ∈ ( 0 , 60 ) , 0 , x ∉ ( 0 , 60 ) ,
得到 ( X , Y ) (X, Y) (X,Y) 的联合密度
f ( x , y ) = f X ( x ) f Y ( y ) = { 1 / 6 0 2 , ( x , y ) ∈ D , 0 , ( x , y ) ∉ D . f(x, y)=f_{X}(x) f_{Y}(y)=f(x,y)=fX(x)fY(y)={1/602,0,(x,y)∈D,(x,y)∈/D.{ 1 / 60 2 , ( x , y ) ∈ D , 0 , ( x , y ) ∉ D .
其中 D = { ( x , y ) ∣ 0 ≤ x , y ≤ 60 } D=\{(x, y) \mid 0 \leq x, y \leq 60\} D={(x,y)∣0≤x,y≤60}.
A = { ( x , y ) ∣ ∣ x − y ∣ ≤ 20 , ( x , y ) ∈ D } . A=\{(x, y)|| x-y \mid \leq 20,(x, y) \in D\} . A={(x,y)∣∣x−y∣≤20,(x,y)∈D}.
要计算的概率是
P ( ∣ X − Y ∣ ≤ 20 ) = ∬ A f ( x , y ) d x d y = 6 0 2 − 4 0 2 6 0 2 = 5 9 .P(∣X−Y∣≤20)=∬Af(x,y)dxdy=602602−402=95.P ( | X − Y | ≤ 20 ) = ∬ A f ( x , y ) d x d y = 60 2 − 40 2 60 2 = 5 9 .

3.2 随机变量函数的分布
例题
设二维随机变量 ( X , Y ) (X, Y) (X,Y) 的概率密度为
f ( x , y ) = { 1 , 0 < x < 1 , 0 < y < 2 x , 0 , 其他. f(x, y)=f(x,y)={1,0,0<x<1,0<y<2x, 其他. { 1 , 0 < x < 1 , 0 < y < 2 x , 0 , 其他.
求:
(I) ( X , Y ) (X, Y) (X,Y) 的边缘概率密度 f X ( x ) , f Y ( y ) f_{X}(x), f_{Y}(y) fX(x),fY(y);
(II) Z = 2 X − Y Z=2 X-Y Z=2X−Y 的概率密度 f Z ( z ) f_{Z}(z) fZ(z).解
(I) 注意到 f ( x , y ) f(x, y) f(x,y) 在 X X X-型区域 { 0 < y < 2 x , 0 < x < 1 \left\{\right. {0<y<2x,0<x<1 上有非零表达式, 该区域可以转化为 Y Y Y-型区 域 { y 2 < x < 1 , 0 < y < 2 . \left\{0 < y < 2 x , 0 < x < 1 \right. {2y<x<1,0<y<2. 则y 2 < x < 1 , 0 < y < 2 .
f X ( x ) = ∫ − ∞ + ∞ f ( x , y ) d y = { ∫ 0 2 x d y , 0 < x < 1 , 0 , 其他. = { 2 x , 0 < x < 1 , 0 , 其他. f Y ( y ) = ∫ − ∞ + ∞ f ( x , y ) d x = { ∫ y 2 1 d x , 0 < y < 2 , 0 , 其他. = { 1 − y 2 , 0 < y < 2 , 0 , 其他.fX(x)=∫−∞+∞f(x,y)dy={∫02x dy,0,0<x<1, 其他. ={2x,0,0<x<1, 其他. fY(y)=∫−∞+∞f(x,y)dx={∫2y1 dx,0,0<y<2, 其他. ={1−2y,0,0<y<2, 其他. f X ( x ) = ∫ − ∞ + ∞ f ( x , y ) d y = { ∫ 0 2 x d y , 0 < x < 1 , 0 , 其他. = { 2 x , 0 < x < 1 , 0 , 其他. f Y ( y ) = ∫ − ∞ + ∞ f ( x , y ) d x = { ∫ y 2 1 d x , 0 < y < 2 , 0 , 其他. = { 1 − y 2 , 0 < y < 2 , 0 , 其他.
(II) 用积分转化法. 此时 g ( x , y ) = 2 x − y g(x, y)=2 x-y g(x,y)=2x−y. 对任何有界连续函数 h ( z ) h(z) h(z),
∫ − ∞ + ∞ ∫ − ∞ + ∞ h [ g ( x , y ) ] f ( x , y ) d x d y = ∫ 0 1 ( ∫ 0 2 x h ( 2 x − y ) ⋅ 1 d y ) d x = ∫ 0 1 ( ∫ 2 x 0 h ( z ) ( − 1 ) d z ) d x ( 换元 z = 2 x − y ) = ∫ 0 1 ( ∫ 0 2 x h ( z ) d z ) d x = ∫ 0 2 ( h ( z ) ∫ z 2 1 d x ) d z (交换积分次序) = ∫ 0 2 h ( z ) ( 1 − z 2 ) d z ,∫−∞+∞∫−∞+∞h[g(x,y)]f(x,y)dx dy=∫01(∫02xh(2x−y)⋅1 dy)dx=∫01(∫2x0h(z)(−1)dz)dx( 换元 z=2x−y)=∫01(∫02xh(z)dz)dx=∫02(h(z)∫2z1 dx)dz (交换积分次序) =∫02h(z)(1−2z)dz,∫ − ∞ + ∞ ∫ − ∞ + ∞ h [ g ( x , y ) ] f ( x , y ) d x d y = ∫ 0 1 ( ∫ 0 2 x h ( 2 x − y ) ⋅ 1 d y ) d x = ∫ 0 1 ( ∫ 2 x 0 h ( z ) ( − 1 ) d z ) d x ( 换元 z = 2 x − y ) = ∫ 0 1 ( ∫ 0 2 x h ( z ) d z ) d x = ∫ 0 2 ( h ( z ) ∫ z 2 1 d x ) d z (交换积分次序) = ∫ 0 2 h ( z ) ( 1 − z 2 ) d z ,
得 Z Z Z 的概率密度为
f Z ( z ) = { 1 − z 2 , 0 < z < 2 , 0 , 其他. f_{Z}(z)=fZ(z)={1−2z,0,0<z<2, 其他. { 1 − z 2 , 0 < z < 2 , 0 , 其他. 3.3 条件分布和条件密度
条件分布
- 设 X = ( X 1 , X 2 , ⋯ , X n ) , Y = ( Y 1 , Y 2 , ⋯ , Y m ) \boldsymbol{X}=\left(X_{1}, X_{2}, \cdots, X_{n}\right), \boldsymbol{Y}=\left(Y_{1}, Y_{2}, \cdots, Y_{m}\right) X=(X1,X2,⋯,Xn),Y=(Y1,Y2,⋯,Ym) 是随机向量, 本节讨 论已知 X = ( x 1 , x 2 , ⋯ , x m ) \boldsymbol{X}=\left(x_{1}, x_{2}, \cdots, x_{m}\right) X=(x1,x2,⋯,xm) 的条件下, Y \boldsymbol{Y} Y 的概率分布.
- 为了叙述的简单, 我们只对
n
=
m
=
1
n=m=1
n=m=1 的情况详细讨论.
离散型随机变量的条件分布 - 设
(
X
,
Y
)
(X, Y)
(X,Y) 是离散型随机向量, 有概率分布
p i j = P ( X = x i , Y = y j ) > 0 , i , j = 1 , 2 , ⋯ , p_{i j}=P\left(X=x_{i}, Y=y_{j}\right)>0, \quad i, j=1,2, \cdots, pij=P(X=xi,Y=yj)>0,i,j=1,2,⋯, -
X
,
Y
X, Y
X,Y 分别有边缘分布
p i = P ( X = x i ) , q j = P ( Y = y j ) , i , j = 1 , 2 , ⋯ . p_{i}=P\left(X=x_{i}\right), q_{j}=P\left(Y=y_{j}\right), i, j=1,2, \cdots . pi=P(X=xi),qj=P(Y=yj),i,j=1,2,⋯. - 对每个固定的
i
i
i, 由条件概率公式得到条件概率
P ( Y = y j ∣ X = x i ) = P ( X = x i , Y = y j ) P ( X = x i ) = p i j p i , j = 1 , 2 , … P\left(Y=y_{j} \mid X=x_{i}\right)=\frac{P\left(X=x_{i}, Y=y_{j}\right)}{P\left(X=x_{i}\right)}=\frac{p_{i j}}{p_{i}}, j=1,2, \ldots P(Y=yj∣X=xi)=P(X=xi)P(X=xi,Y=yj)=pipij,j=1,2,…
为条件 X = x i X=x_{i} X=xi 下, Y Y Y 的条件概率分布, 简称为条件 分布 (conditional distribution).
条件密度
- 设随机向量
(
X
,
Y
)
(X, Y)
(X,Y) 有联合密度
f
(
x
,
y
)
,
X
f(x, y), X
f(x,y),X 有边缘密度
f
X
(
x
)
f_{X}(x)
fX(x), 若在
x
x
x (确定的
x
)
\left.x\right)
x) 处
f
X
(
x
)
>
0
f_{X}(x)>0
fX(x)>0, 就称
P ( Y ≤ y ∣ X = x ) = ∫ − ∞ y f ( x , t ) f X ( x ) d t , y ∈ R P(Y \leq y \mid X=x)=\int_{-\infty}^{y} \frac{f(x, t)}{f_{X}(x)} d t, y \in \mathbb{R} P(Y≤y∣X=x)=∫−∞yfX(x)f(x,t)dt,y∈R
为条件 X = x X=x X=x 下, Y Y Y 的条件分布函数 (conditional distribution function), 简称为条件分布, 记做 F Y ∣ X ( y ∣ x ) F_{Y \mid X}(y \mid x) FY∣X(y∣x). - 称
f Y ∣ X ( y ∣ x ) = f ( x , y ) f X ( x ) , y ∈ R , f_{Y \mid X}(y \mid x)=\frac{f(x, y)}{f_{X}(x)}, y \in \mathbb{R}, fY∣X(y∣x)=fX(x)f(x,y),y∈R,
为条件 X = x X=x X=x 下, Y Y Y 的条件概率密度, 简称为条件密度 (conditional density).
4. 随机变量的数字特征
4.1 数学期望
数学期望定义一离散型
- 定义
1.1
1.1
1.1 设
X
X
X 有概率分布
p j = P ( X = x j ) , j = 0 , 1 , ⋯ , p_{j}=P\left(X=x_{j}\right), j=0,1, \cdots, pj=P(X=xj),j=0,1,⋯,
只要级数 ∑ j = 0 ∞ ∣ x j ∣ p j \sum_{j=0}^{\infty}\left|x_{j}\right| p_{j} ∑j=0∞∣xj∣pj 收敛, 就称
E ( X ) = ∑ j = 0 ∞ x j p j \mathrm{E}(X)=\sum_{j=0}^{\infty} x_{j} p_{j} E(X)=j=0∑∞xjpj
为 X X X 或分布 { p j } \left\{p_{j}\right\} {pj} 的数学期望 (expected value) 或均值 (mean). - 要求 ∑ j = 0 ∞ ∣ x j ∣ p j \sum_{j=0}^{\infty}\left|x_{j}\right| p_{j} ∑j=0∞∣xj∣pj 收敛的原因是要使上式中的级数有确 切的意义.
- 当所有的 x j x_{j} xj 非负时, 如果 上式中的级数是无穷, 由上式定义的 E ( X ) \mathrm{E}(X) E(X) 也有明确的意义, 它表明 X X X 的平均取值是无穷. 这时也称 X X X 的 数学期望是无穷.
- 不难看出, 只取有限个值的随机变量的数学期望总是存在的.
数学期望定义一连续型
-
设 X X X 是有概率密度 f ( x ) f(x) f(x) 的随机变量, 如果下式成立,
∫ − ∞ ∞ ∣ x ∣ f ( x ) d x < ∞ , \int_{-\infty}^{\infty}|x| f(x) d x<\infty, ∫−∞∞∣x∣f(x)dx<∞,
就称
∫ − ∞ ∞ x f ( x ) d x \int_{-\infty}^{\infty} x f(x) d x ∫−∞∞xf(x)dx
为 X X X 或 f ( x ) f(x) f(x) 的数学期望或均值. -
由于随机变量的数学期望由随机变量的概率分布唯一决定, 所以也可 以对概率分布定义数学期望.
-
概率分布的数学期望就是以它为概率分布的随机变量的数学期望. 有 相同分布的随机变量必有相同的数学期望.
期望的计算
计算公式
E ( X ) = ∫ − ∞ + ∞ x f ( x ) d x , E ( g ( X ) ) = ∫ − ∞ + ∞ g ( x ) f ( x ) d x . E ( g ( X ) ) = ∑ k = 1 ∞ g ( x k ) p kE(X)E(g(X))E(g(X))=∫−∞+∞xf(x)dx,=∫−∞+∞g(x)f(x)dx.=k=1∑∞g(xk)pkE ( X ) = ∫ − ∞ + ∞ x f ( x ) d x , E ( g ( X ) ) = ∫ − ∞ + ∞ g ( x ) f ( x ) d x . E ( g ( X ) ) = ∑ k = 1 ∞ g ( x k ) p k 数学期望的几个重要性质
- 设 C C C 是常数, 则有 E ( C ) = C E(C)=C E(C)=C
- 设 X \mathrm{X} X 是随机变量, C \mathrm{C} C 是常数, 则有 E ( C X ) = C E ( X ) E(C X)=C E(X) E(CX)=CE(X)
- 设 X , Y \mathrm{X}, \mathrm{Y} X,Y 是两个随机变量, 则有 E ( X + Y ) = E ( X ) + E ( Y ) E(X+Y)=E(X)+E(Y) E(X+Y)=E(X)+E(Y);
- 设 X , Y X,Y X,Y 是相互独立的随机变量,则有 E ( X Y ) = E ( X ) E ( Y ) E(XY ) = E(X )E(Y) E(XY)=E(X)E(Y)
4.2 方差的性质与计算
方差的计算:
D ( X ) = E [ ( X − E ( X ) ) 2 ] = E ( X 2 ) − ( E ( X ) ) 2 .
D(X)=E[(X−E(X))2]=E(X2)−(E(X))2.D ( X ) = E [ ( X − E ( X ) ) 2 ] = E ( X 2 ) − ( E ( X ) ) 2 . 记 E ( X ) = μ E(X)=\mu E(X)=μ, 由方差定义式 D ( X ) = E [ ( X − μ ) 2 ] D(X)=E\left[(X-\mu)^{2}\right] D(X)=E[(X−μ)2], 可见方差其实是一个期望, 是随机变量函 数 ( X − μ ) 2 (X-\mu)^{2} (X−μ)2 的期望. 由随机变量函数期望的求法, 故有
D ( X ) = ∫ − ∞ + ∞ ( x − μ ) 2 f ( x ) d x . D(X)=\int_{-\infty}^{+\infty}(x-\mu)^{2} f(x) \mathrm{d} x . D(X)=∫−∞+∞(x−μ)2f(x)dx.
方差的性质:- D ( C ) = 0 D(C)=0 D(C)=0,
- D ( X + C ) = D ( X ) D(X+C)=D(X) D(X+C)=D(X).
- D ( a X ) = a 2 D ( X ) , D ( − X ) = D ( X ) D(a X)=a^{2} D(X), D(-X)=D(X) D(aX)=a2D(X),D(−X)=D(X).
-
D
(
X
+
Y
)
=
D
(
X
)
+
D
(
Y
)
+
2
Cov
(
X
,
Y
)
D(X+Y)=D(X)+D(Y)+2 \operatorname{Cov}(X, Y)
D(X+Y)=D(X)+D(Y)+2Cov(X,Y).
X X X 与 Y Y Y 不相关 ⇔ D ( X + Y ) = D ( X ) + D ( Y ) \Leftrightarrow D(X+Y)=D(X)+D(Y) ⇔D(X+Y)=D(X)+D(Y).
X X X 与 Y Y Y 相互独立 ⟹ D ( X + Y ) = D ( X ) + D ( Y ) \Longrightarrow D(X+Y)=D(X)+D(Y) ⟹D(X+Y)=D(X)+D(Y). - D ( a X ± b Y ) = a 2 D ( X ) + b 2 D ( Y ) D(a X \pm b Y)=a^{2} D(X)+b^{2} D(Y) D(aX±bY)=a2D(X)+b2D(Y), 其中 X X X 与 Y Y Y 相互独立.
例题
设随机变量 X , Y X, Y X,Y 相互独立, 且都服从均值为 0 , 方差为 1 2 \frac{1}{2} 21 的正态分布. 求随机变量 ∣ X − Y ∣ |X-Y| ∣X−Y∣ 的方 差,
解 令 Z = X − Y Z=X-Y Z=X−Y. 由题设知, Z ∼ N ( 0 , 1 ) Z \sim N(0,1) Z∼N(0,1). 对
D ( ∣ X − Y ∣ ) = D ( ∣ Z ∣ ) = E ( ∣ Z ∣ 2 ) − [ E ( ∣ Z ∣ ) ] 2 = E ( Z 2 ) − [ E ( ∣ Z ∣ ) ] 2D(∣X−Y∣)=D(∣Z∣)=E(∣Z∣2)−[E(∣Z∣)]2=E(Z2)−[E(∣Z∣)]2D ( | X − Y | ) = D ( | Z | ) = E ( | Z | 2 ) − [ E ( | Z | ) ] 2 = E ( Z 2 ) − [ E ( | Z | ) ] 2
由 E ( Z 2 ) = D ( Z ) + [ E ( Z ) ] 2 = 1 + 0 = 1 E\left(Z^{2}\right)=D(Z)+[E(Z)]^{2}=1+0=1 E(Z2)=D(Z)+[E(Z)]2=1+0=1, 且
E ( ∣ Z ∣ ) = 1 2 π ∫ − ∞ + ∞ ∣ z ∣ e − z 2 / 2 d z = 2 2 π ∫ 0 + ∞ ∣ z ∣ e − z 2 / 2 d z = 2 2 π ∫ 0 + ∞ z e − z 2 / 2 d z = − 2 2 π ∫ 0 + ∞ d ( e − z 2 / 2 ) = 2 2 π e − z 2 / 2 ∣ 0 + ∞ = 2 πE(∣Z∣)=2π1∫−∞+∞∣z∣e−z2/2 dz=2π2∫0+∞∣z∣e−z2/2 dz=2π2∫0+∞ze−z2/2 dz=−2π2∫0+∞d(e−z2/2)=2π2e−z2/2∣ ∣0+∞=π2E ( | Z | ) = 1 2 π ∫ − ∞ + ∞ | z | e − z 2 / 2 d z = 2 2 π ∫ 0 + ∞ | z | e − z 2 / 2 d z = 2 2 π ∫ 0 + ∞ z e − z 2 / 2 d z = − 2 2 π ∫ 0 + ∞ d ( e − z 2 / 2 ) = 2 2 π e − z 2 / 2 | 0 + ∞ = 2 π
故 D ( ∣ X − Y ∣ ) = E ( Z 2 ) − [ E ( ∣ Z ∣ ) ] 2 = 1 − 2 π D(|X-Y|)=E\left(Z^{2}\right)-[E(|Z|)]^{2}=1-\frac{2}{\pi} D(∣X−Y∣)=E(Z2)−[E(∣Z∣)]2=1−π2.4.3 协方差与相关系数
协方差的计算:
Cov ( X , Y ) = E [ ( X − E ( X ) ) ( Y − E ( Y ) ) ] = E ( X Y ) − E ( X ) E ( Y ) .Cov(X,Y)=E[(X−E(X))(Y−E(Y))]=E(XY)−E(X)E(Y).Cov ( X , Y ) = E [ ( X − E ( X ) ) ( Y − E ( Y ) ) ] = E ( X Y ) − E ( X ) E ( Y ) . 相关系数的计算:
ρ X Y = Cov ( X , Y ) D ( X ) D ( Y ) = E [ ( X − E ( X ) ) ( Y − E ( Y ) ) ] D ( X ) D ( Y ) .ρXY=D(X)D(Y)Cov(X,Y)=D(X)D(Y)E[(X−E(X))(Y−E(Y))].ρ X Y = Cov ( X , Y ) D ( X ) D ( Y ) = E [ ( X − E ( X ) ) ( Y − E ( Y ) ) ] D ( X ) D ( Y ) .
随机变量的相关系数 = = = 随机变量 “标准化” 后的协方差. 事实上, X , Y X, Y X,Y 标准化为
X ∗ = X − E ( X ) D ( X ) , Y ∗ = Y − E ( Y ) D ( Y ) , X^{*}=\frac{X-E(X)}{\sqrt{D(X)}}, \quad Y^{*}=\frac{Y-E(Y)}{\sqrt{D(Y)}}, X∗=D(X)X−E(X),Y∗=D(Y)Y−E(Y),
则
ρ X Y = Cov ( X , Y ) D ( X ) D ( Y ) = Cov ( X ∗ , Y ∗ ) . \rho_{X Y}=\frac{\operatorname{Cov}(X, Y)}{\sqrt{D(X)} \sqrt{D(Y)}}=\operatorname{Cov}\left(X^{*}, Y^{*}\right) . ρXY=D(X)D(Y)Cov(X,Y)=Cov(X∗,Y∗).
相关系数的性质-
∣
ρ
∣
⩽
1
|\rho| \leqslant 1
∣ρ∣⩽1. 其中
- ∣ ρ ∣ = 1 ⟺ X |\rho|=1 \Longleftrightarrow X ∣ρ∣=1⟺X 与 Y Y Y 之间存在线性关系,即存在常数 a, b 使 P { Y = a + b X } = 1 P\{Y = a + bX\}=1 P{Y=a+bX}=1;
-
ρ
=
0
⟺
X
\rho=0 \Longleftrightarrow X
ρ=0⟺X 与
Y
Y
Y 之间不存在线性关系, 或称
X
X
X 与
Y
Y
Y 不相关.
强调: 不相关是 “不线性相关”的简称!
- 以下命题是等价的:
- X X X 与 Y Y Y 不相关.
- ρ X Y = 0 \rho_{X Y}=0 ρXY=0.
- Cov ( X , Y ) = 0 \operatorname{Cov}(X, Y)=0 Cov(X,Y)=0.
- E ( X Y ) = E ( X ) E ( Y ) E(X Y)=E(X) E(Y) E(XY)=E(X)E(Y).
- D ( X + Y ) = D ( X ) + D ( Y ) D(X+Y)=D(X)+D(Y) D(X+Y)=D(X)+D(Y).
- X X X 与 Y Y Y 独立 ⟹ X \Longrightarrow X ⟹X 与 Y Y Y 不相关. 反之不一定成立.
4.4 切比雪夫不等式
P { ∣ X − E ( X ) ∣ ⩾ ε } ⩽ D ( X ) ε 2 , P\{|X-E(X)| \geqslant \varepsilon\} \leqslant \frac{D(X)}{\varepsilon^{2}}, P{∣X−E(X)∣⩾ε}⩽ε2D(X),
或等价地
P { ∣ X − E ( X ) ∣ < ε } ⩾ 1 − D ( X ) ε 2 . P\{|X-E(X)|<\varepsilon\} \geqslant 1-\frac{D(X)}{\varepsilon^{2}} . P{∣X−E(X)∣<ε}⩾1−ε2D(X).5. 概率极限定理
中心极限定理即言: 大量独立同分布的随机变量之和, 近似服从正态分布
中心极限定理:
(1) 设随机变量 X 1 , X 2 , ⋯ , X n X_{1}, X_{2}, \cdots, X_{n} X1,X2,⋯,Xn 独立同分布, E ( X k ) = μ , D ( X k ) = σ 2 , k = 1 , 2 ⋯ , n E\left(X_{k}\right)=\mu, D\left(X_{k}\right)=\sigma^{2}, k=1,2 \cdots, n E(Xk)=μ,D(Xk)=σ2,k=1,2⋯,n. 从而,
E ( ∑ k = 1 n X k ) = n μ , D ( ∑ k = 1 n X k ) = n σ 2 . E\left(\sum_{k=1}^{n} X_{k}\right)=n \mu, \quad D\left(\sum_{k=1}^{n} X_{k}\right)=n \sigma^{2} . E(k=1∑nXk)=nμ,D(k=1∑nXk)=nσ2.
则近似地有
∑ k = 1 n X k ∼ N ( n μ , n σ 2 ) , \sum_{k=1}^{n} X_{k} \sim N\left(n \mu, n \sigma^{2}\right), k=1∑nXk∼N(nμ,nσ2),
上式一般用于求解和的概率问题.进一步 “标准化” 得
∑ k = 1 n X k − n μ n σ ∼ N ( 0 , 1 ) . \frac{\sum_{k=1}^{n} X_{k}-n \mu}{\sqrt{n} \sigma} \sim N(0,1) . nσ∑k=1nXk−nμ∼N(0,1).
等价地,
1 n ∑ k = 1 n X k − μ σ / n ∼ N ( 0 , 1 ) . \frac{\frac{1}{n} \sum_{k=1}^{n} X_{k}-\mu}{\sigma / \sqrt{n}} \sim N(0,1) . σ/nn1∑k=1nXk−μ∼N(0,1).
记 X ˉ = 1 n ∑ k = 1 n X k \bar{X}=\frac{1}{n} \sum_{k=1}^{n} X_{k} Xˉ=n1∑k=1nXk, 则
X ˉ − μ σ / n ∼ N ( 0 , 1 ) . \frac{\bar{X}-\mu}{\sigma / \sqrt{n}} \sim N(0,1) . σ/nXˉ−μ∼N(0,1).
等价地,
X ˉ ∼ N ( μ , σ 2 n ) . \bar{X} \sim N\left(\mu, \frac{\sigma^{2}}{n}\right) . Xˉ∼N(μ,nσ2).
也可以直接由 E ( X k ) = μ , D ( X k ) = σ 2 E\left(X_{k}\right)=\mu, D\left(X_{k}\right)=\sigma^{2} E(Xk)=μ,D(Xk)=σ2, 得 E ( X ˉ ) = μ , D ( X ˉ ) = σ 2 n E(\bar{X})=\mu, D(\bar{X})=\frac{\sigma^{2}}{n} E(Xˉ)=μ,D(Xˉ)=nσ2.
上式一般用于求解平均值的概率问题.(2) 设 n A n_{A} nA 为 n n n 重伯努利试验中事件 A A A 出现的次数, 且 A A A 在每次实验中发生的概率为 p p p. 则 n A n_{A} nA 服从 二项分布 B ( n , p ) B(n, p) B(n,p), 从而
E ( n A ) = n p , D ( n A ) = n p ( 1 − p ) . E\left(n_{A}\right)=n p, \quad D\left(n_{A}\right)=n p(1-p) . E(nA)=np,D(nA)=np(1−p).
当 n n n 很大时, n A n_{A} nA 的 “标准化” 变量 n A − E ( n A ) D ( n A ) \frac{n_{A}-E\left(n_{A}\right)}{\left.\sqrt{D\left(n_{A}\right.}\right)} D(nA)nA−E(nA) 近似服从正态分布, 即
n A − n p n p ( 1 − p ) ∼ N ( 0 , 1 ) . \frac{n_{A}-n p}{\sqrt{n p(1-p)}} \sim N(0,1) . np(1−p)nA−np∼N(0,1).例题
一生产线生产的产品成箱包装, 每箱的重量是随机的. 假设每箱平均重 50 千克, 标准差为 5 千克. 若用最大载重量为 5 吨的汽车承运, 试利用中心极限定理说明每辆车最多可以装多少箱, 才能保障不超 载的概率大于 0.977 0.977 0.977.
解 :
设所求箱数为 n n n, 每箱的重量记为 X 1 , X 2 , ⋯ , X n X_{1}, X_{2}, \cdots, X_{n} X1,X2,⋯,Xn. 由题设可把 X 1 , X 2 , ⋯ , X n X_{1}, X_{2}, \cdots, X_{n} X1,X2,⋯,Xn 视为独立同分布 随机变量. 又
E ( X i ) = 50 , D ( X i ) = 5 2 , ( i = 1 , 2 , ⋯ , n ) E\left(X_{i}\right)=50, \quad D\left(X_{i}\right)=5^{2}, \quad(i=1,2, \cdots, n) E(Xi)=50,D(Xi)=52,(i=1,2,⋯,n)
根据中心极限定理, 有 ∑ i = 1 n X i \sum_{i=1}^{n} X_{i} ∑i=1nXi 近似服从正态分布 ( n ⋅ 50 , n ⋅ 5 2 ) \left(n \cdot 50, n \cdot 5^{2}\right) (n⋅50,n⋅52).
问题即求 n n n 使
P { ∑ i = 1 n X i ⩽ 5000 } > 0.977. P\left\{\sum_{i=1}^{n} X_{i} \leqslant 5000\right\}>0.977 . P{i=1∑nXi⩽5000}>0.977.
其中
P { ∑ i = 1 n X i ⩽ 5000 } = P { ∑ i = 1 n X i − 50 n 5 n ⩽ 5000 − 50 n 5 n } ≈ Φ ( 1000 − 10 n n )P{i=1∑nXi⩽5000}=P{5n∑i=1nXi−50n⩽5n5000−50n}≈Φ(n1000−10n)P { ∑ i = 1 n X i ⩽ 5000 } = P { ∑ i = 1 n X i − 50 n 5 n ⩽ 5000 − 50 n 5 n } ≈ Φ ( 1000 − 10 n n )
故
Φ ( 1000 − 10 n n ) > 0.977 = Φ ( 2 ) , \Phi\left(\frac{1000-10 n}{\sqrt{n}}\right)>0.977=\Phi(2), Φ(n1000−10n)>0.977=Φ(2),
即
1000 − 10 n n > 2 , \frac{1000-10 n}{\sqrt{n}}>2, n1000−10n>2,
从而 n < 98.0199 n<98.0199 n<98.0199, 即最多可以装 98 箱. -
相关阅读:
[如何编译openGauss对应版本的wal2json.so]
代码随想录刷题 Day 22
生成元 rust解法
POSIX线程与Win32线程
OpenCV快速入门:窗口交互
机器学习常见的sampling策略 附PyTorch实现
JS超集对TypeScript的Map对象以及联合类型的深入实战
RocketMQ部署
【附源码】计算机毕业设计JAVA人口老龄化常态下的社区老年人管理与服务平台
新版本Spring Security 2.7 + 用法,直接旧正版粘贴
- 原文地址:https://blog.csdn.net/weixin_42301220/article/details/126478226