-
【AI设计模式】03-数据处理-流水线(Pipeline)模式

作者:王磊
更多精彩分享,欢迎访问和关注:https://www.zhihu.com/people/wldandan在AI设计模式系列文章中,我们介绍了数据表示的两种模式-特征哈希模式和嵌入模式,数据表示完成后,就进入数据处理阶段。数据处理阶段中,开发者需要基于框架提供的数据处理算子(如shuffle/map/batch等)、数据处理引擎完成数据处理,用于后续的训练过程。训练数据往往规模比较大,比如COCO数据集在10GB以上,ImageNet数据集在100G以上,想要快速高效的完成数据的处理会非常有挑战。在CPU处理器中,为了可以加速指令的处理速度,通过指令流水线技术,在每个时钟周期并行去完成不同指令的取指、译码、执行、访存和写回操作,实现更高效的处理速度。

引至《计算机体系结构基础》 第三版第九章
所以,参考CPU的指令流水线,在数据处理时引入类似的并行处理机制,可以加速海量数据的数据处理速度,本次给大家介绍流水线(Pipeline)模式。

AI设计模式总览
模式定义
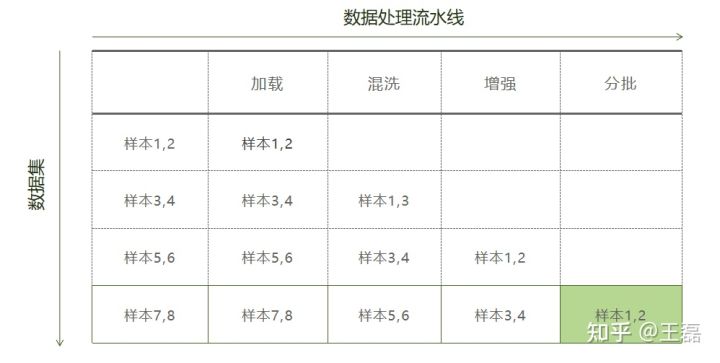
流水线(Pipeline)模式是一种数据处理模式,它将整个数据处理的过程分为多步,以流水线方式处理数据,同时在每个阶段都进行并行处理,实现高效的数据处理。以下图为例,我们将数据处理的过程分为加载、混洗、增强和批量操作,形成一个数据处理的管道,每个管道中都以并行的方式处理样本数据,从而实现流畅高效的数据处理。
解决方案
AI框架的数据处理模块通常会支持流水线模式,以MindSpore框架为例,MindSpore的数据处理引擎实现了如下的流水线:

不同于TensorFlow和PyTorch,MindSpore采用多段并行流水线(Multi-stage Parallel Pipeline)的方式来构建数据处理Pipeline,可以更加细粒度地规划计算资源的使用。如上图所示,每个数据集算子都包含一个输出Connector,即由一组阻塞队列和计数器组成的保序缓冲队列。每个数据集算子都会从上游算子的Connector中取缓存数据进行处理,然后将这块缓存再推送到自身的输出Connector中,由此往后。

这种机制的好处在于:
- 数据集加载、map、batch等操作以任务调度机制来驱动,每个操作的任务互相独立,上下文之间通过Connector来实现联通;
- 每个操作均可以实现细粒度的多线程或多进程并行加速。数据框架为用户提供调整算子线程数和控制多进程处理的接口,可以灵活控制各个节点的处理速度,进而实现整个数据处理Pipeline性能最优;
- 支持用户对Connector大小进行设置,在一定程度上可以有效的控制内存的使用率,能够适应不同网络对数据处理性能的要求。
在这种数据处理机制下,对输出数据进行保序(流水线运行时,输出数据的顺序和数据处理前的顺序一致)处理是保证训练精度的关键。MindSpore采用轮询算法来保证多线程处理时数据的有序性。下图是一个数据处理Pipeline,保序操作发生在下游map算子(4并发)的取出操作中,通过单线程轮询的方式取出上游队列中的数据。Connector内部有两个计数器,expect_consumer_记录了已经有多少个consumer从queues_中取出了数据,pop_from_记录了哪个内部阻塞队列将要进行下一次取出操作。expect_consumer_对consumer取余,而pop_from_对producer取余。expect_consumer_再次为0时,说明所有的local_queues_已经处理完上一批任务,可以继续进行下一批任务的分配和处理,进而实现了上游至下游map操作的多并发保序处理。

案例
基于流水线模式执行的最大特点是需要定义map算子,如下面的数据流水线中,map算子负责调度Resize、Crop、HWC2CHW的启动和执行,对数据管道的数据进行映射变换。

图像数据处理
在一小时上手MindSpore,我们基于Mnist数据集用MindSpore框架实现了手写数字识别的任务。其中在图像数据处理过程中,使用了数据流水线模式。在下面的数据处理代码中,我们定义了5个图片处理的操作:TypeCast(数据类型转换)、Resize(图片大小调整)、Rescale(数据标准化)、Rescale(正态分布)、HWC2CHW(转置),然后交给map算子调度,处理完后接着交给shuffule(混洗)和batch(分批)完成流水线的最后处理操作。
- def create_dataset(data_path, batch_size=32, repeat_size=1): # 需要传入数据集的文件路径,批量大小
- # ① 定义数据集
- mnist_ds = ds.MnistDataset(data_path)
- # ②定义所需要操作的map映射
- type_cast_op = C.TypeCast(mstype.int32)
- resize_op = CV.Resize((32, 32), interpolation=Inter.LINEAR) # 目标将图片大小调整为32*32,这样特征图能保证28*28,和原图一致
- rescale_nml_op = CV.Rescale(1 / 0.3081 , -1 * 0.1307 / 0.3081) # 数据集的标准化系数
- rescale_op = CV.Rescale(1.0 / 255.0, 0.0) # 数据做标准化处理,所得到的数值分布满足正态分布
- hwc2chw_op = CV.HWC2CHW() # 转置操作
- # ③使用map映射函数,将数据操作应用到数据集
- mnist_ds = mnist_ds.map(operations=type_cast_op, input_columns="label")
- mnist_ds = mnist_ds.map(operations=[resize_op, rescale_op, rescale_nml_op, hwc2chw_op], input_columns="image")
- # ④进行shuffle和取数据批量的操作
- buffer_size = 10000
- mnist_ds = mnist_ds.shuffle(buffer_size=buffer_size)
- mnist_ds = mnist_ds.batch(batch_size)
- return mnist_ds
完整的代码和执行结果可参考 一小时上手MindSpore文章。
文本数据处理
下面我们用数据流水线的方式完成对句子实施jieba分词的数据处理。
首先下载jieba字典,并将字典文件
hmm_model.utf8和jieba.dict.utf8放在dictionary目录下。- from mindvision.dataset import DownLoad
- # 字典文件存放路径
- dl_path = "./dictionary"
- # 获取字典文件源
- dl_url_hmm = "https://obs.dualstack.cn-north-4.myhuaweicloud.com/mindspore-website/notebook/datasets/hmm_model.utf8"
- dl_url_jieba = "https://obs.dualstack.cn-north-4.myhuaweicloud.com/mindspore-website/notebook/datasets/jieba.dict.utf8"
- # 下载字典文件
- dl = DownLoad()
- dl.download_url(url=dl_url_hmm, path=dl_path)
- dl.download_url(url=dl_url_jieba, path=dl_path)
下面的样例首先构建了一个文本数据集
"明天天气太好了我们一起去外面玩吧",然后使用HMM与MP字典文件创建JiebaTokenizer对象,并对数据集进行分词,最后展示了分词前后的文本结果。- import mindspore.dataset as ds
- import mindspore.dataset.text as text
- # 构造待分词数据
- input_list = ["明天天气太好了我们一起去外面玩吧"]
- HMM_FILE = "./dictionary/hmm_model.utf8"
- MP_FILE = "./dictionary/jieba.dict.utf8"
- # 加载数据集
- dataset = ds.NumpySlicesDataset(input_list, column_names=["text"], shuffle=False)
- print("------------------------分词前----------------------------")
- for data in dataset.create_dict_iterator(output_numpy=True):
- print(text.to_str(data['text']))
- # 使用JiebaTokenizer分词器对数据集进行分词,将jieba分词交给map算子调度
- jieba_op = text.JiebaTokenizer(HMM_FILE, MP_FILE)
- dataset = dataset.map(operations=jieba_op, input_columns=["text"])
- print("------------------------分词后-----------------------------")
- for data in dataset.create_dict_iterator(num_epochs=1, output_numpy=True):
- print(text.to_str(data['text']))
输出结果如下:
- ------------------------分词前----------------------------
- 明天天气太好了我们一起去外面玩吧
- ------------------------分词后-----------------------------
- ['明天' '天气' '太好了' '我们' '一起' '去' '外面' '玩吧']
从以上两个图像和文本数据处理的代码实现来看,虽然数据流水线会提供更好的性能,但它数据流水线在代码组装和数据读取(迭代方式)会稍显复杂。
总结
流水线模式可以实现针对海量数据的高效数据处理,但在运行的过程中会占用比较多的系统资源,包括CPU、内存,以ImageNet的训练为例,内存占用可以达到30-50GB,因此,对于训练数据量较小、训练资源不足或者推理场景(零散样本)的场景,并不适合流水线模式,此时可以考虑使用Eager模式用串行的方式直接调用数据处理的算子完成数据处理。同时在开发调试过程中,因为使用多线程并行模式,相比单线程的Eager模式也会更困难些。开发者在数据处理模式的选择时可以综合权衡以挑选最合适的模式。
说明:严禁转载本文内容,否则视为侵权。
-
相关阅读:
ElasticSearch学习篇10_Lucene数据存储之BKD动态磁盘树
AIRIOT答疑第3期|如何使用物联网平台的可视化组态引擎?
【解决】刷了Magisk修改后的boot,magisk仍然没有ROOT
C 嵌入式系统设计模式 09:硬件适配器模式
Java中SFTP的使用
基于Faster R-CNN的安全帽目标检测
Vue基于python的留学生服务报名系统django
基础面试题
vue实现瀑布流
Dapr 官方文档中文翻译 v1.5 版本正式发布
- 原文地址:https://blog.csdn.net/Kenji_Shinji/article/details/126477915
