-
Chapter 3 New Optimizers for Deep Learning
相关知识
参数说明
 :时间步长
:时间步长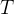 的模型参数
的模型参数 /
/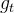 :在处的梯度,用于计算
:在处的梯度,用于计算
 :时间步长0到时间步长累积的动量
:时间步长0到时间步长累积的动量
相关理论
(1)on-line(在线):在一个时间步长中,模型中每来一组数据,就进行修正模型。

(2)off-line(离线):在每个时间步长中,将所有数据注入到模型之中。

SGD
见https://blog.csdn.net/qwertyuiop0208/article/details/126348658
SGD with momentum(SGDM)
从
 开始,其动量为
开始,其动量为 。由“当前的动量
。由“当前的动量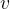 由上一次迭代动量和当前梯度决定,即
由上一次迭代动量和当前梯度决定,即 ”可得:
”可得: 、
、
可知:
迭代的动量是前 迭代的梯度的加权和。
迭代的梯度的加权和。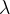 为衰减权重。SGDM相比于SGD的差别在于,参数更新时,不仅仅减去了当前迭代的梯度,还减去了前迭代的梯度的加权和。由此可见,SGDM中,当前迭代的梯度和之前迭代的累积梯度,都会影响参数更新。
为衰减权重。SGDM相比于SGD的差别在于,参数更新时,不仅仅减去了当前迭代的梯度,还减去了前迭代的梯度的加权和。由此可见,SGDM中,当前迭代的梯度和之前迭代的累积梯度,都会影响参数更新。如图中,加入动量后,我们可以看到,参数更新就不会停在当前梯度较小的点了。

Adagrad
 ,与SGD的区别是,学习率除以前迭代的梯度的平方和,故称为自适应梯度下降。与SGDM相比,考虑了随着时间的推移调整学习速度。
,与SGD的区别是,学习率除以前迭代的梯度的平方和,故称为自适应梯度下降。与SGDM相比,考虑了随着时间的推移调整学习速度。其刚开始迭代时,学习率较大,可以快速收敛,而后来学习率逐渐减小,可以使得模型更容易找到最优点。
RMSProp
 ,其中
,其中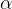 为衰减因子。
为衰减因子。与Adagrad相比,加入了迭代衰减,不会因为后面梯度小而改变不了学习率,与当前迭代越近的梯度,对当前影响越大。
Adam
Adam是SGDM和RMSProp的结合,它基本解决了之前提到的梯度下降的一系列问题,比如随机小样本、自适应学习率、容易卡在梯度较小点等问题。

优化
Adam和SGDM的结合
Adam vs SGDM:
Adam——训练快,泛化差异大,不稳定,可能不收敛
SGDM——训练慢,泛化差异小,稳定,更好的收敛
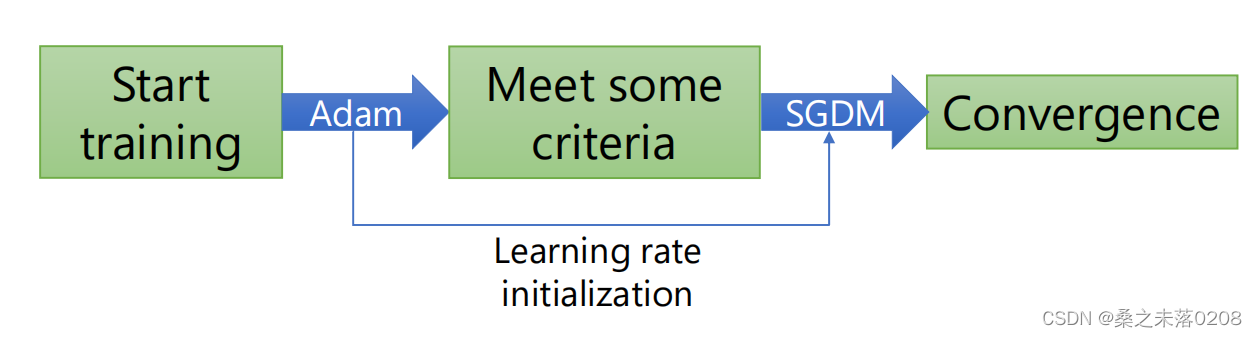
因此,针对如何更好的结合两者的优点,提出“SWATS”:
开始使用Adam进行更快的训练,直到符合一些标准后,选择SGDM使模型收敛。
Adam的改进
在训练的最后阶段,大多数梯度是小的和无信息的,而一些小批量很少提供大的信息梯度。

改进:
 ,记作AMSGrad。
,记作AMSGrad。优点:减小了较小梯度的影响;移除因最大操作而导致的去偏置;单调递减学习速率
SGDM的改进
SGDM收敛过慢,且没有使用自适应学习率的问题。
改进:让学习率在一定范围内变大和变小的方法,记作Cyclical LR。

优点:学习率由LR范围测试决定;通过改变学习速率来避免局部最小值。
总结
RAdam SWATS 灵感 训练开始时的梯度失真导致不准确的自适应学习率 不收敛、泛化能力差、SGDM训练慢 做法 使用预热学习率来减少不准确的自适应学习率的影响 结合Adam和SGDM的优点,先使用Adam,再使用SDM 转换 从SGDM到Adam的转换 从Adam到SGDM的转换 转换的原因 v ^ t 为了更好的收敛 转换的点 当近似值变得有效 人为定义 其他优化器
Lookahead
Lookahead是所有优化器的通用包装器。
参数迭代k步后,再退回来一步。以新的起点重新开始迭代,这样可以增加收敛稳定性,防止跑飞。

上图中的Optim可以是任何优化器。

Nesterov accelerated gradient(NAG)
m t = λ m t − 1 + η ▽ L ( θ t − 1 − λ m t − 1 ) " role="presentation">令
θ t ′ = θ t − λ m t = θ t − 1 − m t − λ m t = θ t − 1 − λ m t − λ m t − 1 − η ▽ L ( θ t − 1 − λ m t − 1 ) = θ t − 1 ′ − λ m t − η ▽ L ( θ t − 1 ′ ) " role="presentation">因此
m t = λ m t − 1 + η ▽ L ( θ t − 1 ′ ) " role="presentation">NAG同Momentum一样,都是利用历史梯度来更新参数。
加入L2正则

加入weight decay

优化器的应用

-
相关阅读:
网络通信:http协议
为什么要有包装类,顺便说一说基本数据类型、包装类、String类该如何转换?
基于Python-django餐厅点餐及推荐系统
聊聊计算机中的寄存器
【Python21天学习挑战赛】- 函数进阶
STL容器——priority_queue的模拟实现
浅谈电弧光保护装置在6KV厂用电系统中的应用与选型
【k8s】五、Pod生命周期(一)
短视频矩阵系统源代码开发,独立saas系统搭建oem源码部署
Python工程化管理:package包层次结构组织以及module模块详解
- 原文地址:https://blog.csdn.net/qwertyuiop0208/article/details/126445002