-
FUTR3D: A Unified Sensor Fusion Framework for 3D Detection 论文笔记
原文链接:https://arxiv.org/pdf/2203.10642.pdf
1.引言
不同的车辆有不同的传感器种类、型号和安装方式,分别定制融合算法需要大量工作。
本文设计了一个统一的传感器融合模型FUTR3D。首先分别提取各模态特征,然后使用基于查询的模态无关特征采样器(MAFS)从统一域中采样不同模态的特征。然后使用transformer解码器处理3D查询,进行3D目标的集合预测。
3.方法
如下图所式,FUTR3D可分为4部分,即模态编码器(各模态分别处理)、基于查询的模态无关特征采样器(根据查询的初始位置采样和聚合多模态特征)、共享的transformer解码器(基于融合特征,用迭代细化模块细化边界框)、损失函数计算(基于预测和真实边界框之间的集合到集合的匹配)。

注意单一模态方法如DETR3D或Object DGCNN可以视作属于FUTR3D的特例(即FUTR3D也可进行单一模态3D检测)。
3.1 特定模态的特征编码
可以使用任何编码器。
对于激光雷达点云,本文使用VoxelNet或PointPillars编码,经过3D主干和FPN后得到BEV下的多尺度激光雷达特征图
 。
。对于雷达点云,本文使用共享的MLP
 处理每个点
处理每个点 ,得到逐点特征
,得到逐点特征 。
。对于
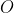 个环视图像,本文使用ResNet和FPN得到多尺度特征
个环视图像,本文使用ResNet和FPN得到多尺度特征 。
。3.2 模态无关特征采样器
输入是一组物体查询
 ,以及多模态特征。MAFS通过采样和融合特征来更新查询。
,以及多模态特征。MAFS通过采样和融合特征来更新查询。初始3D参考点:首先通过对查询进行线性变换和sigmoid归一化来解码3D参考点:

其中
![c_i\in[0,1]^3](https://1000bd.com/contentImg/2022/08/17/182607739.gif) 是3D空间中的坐标。然后此参考点作为锚,聚合多模态多尺度特征。注意初始的3D参考点不依赖于任何模态的特征。
是3D空间中的坐标。然后此参考点作为锚,聚合多模态多尺度特征。注意初始的3D参考点不依赖于任何模态的特征。激光雷达特征采样:设
 是参考点在BEV下的投影,则第
是参考点在BEV下的投影,则第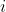 个参考点的采样特征为相应位置多尺度特征的加权求和:
个参考点的采样特征为相应位置多尺度特征的加权求和:
其中
 用到了双线性插值,
用到了双线性插值, 是查询通过线性变换和sigmoid归一化得到的权重系数。
是查询通过线性变换和sigmoid归一化得到的权重系数。雷达特征采样:选择每个物体查询参考点的
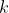 近邻雷达点,进行特征的加权求和:
近邻雷达点,进行特征的加权求和: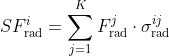
其中权重系数
 的生成和前面类似。
的生成和前面类似。图像特征采样:设
 是参考点在第个相机图像上投影(使用相机内外参),则采样特征为各图像各尺度相应位置特征的加权和:
是参考点在第个相机图像上投影(使用相机内外参),则采样特征为各图像各尺度相应位置特征的加权和:
其中
 用到了双线性插值,权重系数
用到了双线性插值,权重系数 类似前面的方法生成。若参考点的投影在某图像外,则相应的采样值为0。
类似前面的方法生成。若参考点的投影在某图像外,则相应的采样值为0。模态无关特征融合:首先将各采样特征拼接,并使用MLP
 编码:
编码:
查询的更新量为该融合特征加上位置编码,即

然后按
 更新查询。
更新查询。最后,使用自注意力模块在各查询间进行交互,再加上残差连接,即

3.3 迭代细化3D边界框
设第
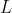 层transformer解码块输出的查询为
层transformer解码块输出的查询为 。对每个查询,使用共享的MLP预测边界框参数(中心坐标偏移
。对每个查询,使用共享的MLP预测边界框参数(中心坐标偏移 、长宽高、朝向的正余弦以及速度和类别)。使用该层预测边界框中心作为下一层的3D参考点,即
、长宽高、朝向的正余弦以及速度和类别)。使用该层预测边界框中心作为下一层的3D参考点,即 。
。3.4 损失
使用集合到集合的损失,即先进行预测和真实边界框的双向匹配,并对每组匹配计算分类和回归损失,然后使用匈牙利算法求解最优匹配。
4.实验
4.1 实施细节
使用nuScenes数据集。低分辨率激光雷达数据是由原始的高分辨率激光雷达数据生成的,即先将点云转换为球坐标,仅取相应俯仰角区间内的点。
训练时先预训练编码器,再进行联合训练微调。
4.2 多模态检测
激光雷达与相机融合:FUTR3D可以使用更低成本的传感器配置,实现高成本传感器的性能。例如,相机和4线激光雷达融合的FUTR3D方法 就能达到与 32线激光雷达检测的CenterPoint 相当的性能;相机和1线激光雷达融合时,FUTR3D比PointPainting的性能高很多。
雷达与相机融合:FUTR3D能达到比CenterFusion略高的性能;相比于仅用相机的方法,雷达与相机融合能有更高的速度估计精度。
4.3 相机与激光雷达的特点
物体类别:仅基于相机的方法总体性能低于仅基于4线激光雷达的方法,但在自行车、交通锥和障碍物的检测上有较高的精度,说明激光雷达不适于检测小物体。此外结合相机与4线激光雷达后,这些小物体的检测性能有极大提升。
物体距离:激光雷达对远距离物体的检测性能要好于相机,但两者结合能将性能提升到新的层次,特别是对于远距离物体的检测。
物体大小:相机和激光雷达融合方法相比激光雷达检测方法,对小型物体的检测比对大型物体更有利,因为相机能提供更高的分辨率。但相比相机检测方法,不同大小物体的性能提升相近,这说明深度信息对不同大小物体的重要程度相同。
4.4 消融研究
物体查询:物体查询数量对检测结果的影响很小。
主干选择:更深的图像主干和更高分辨率的体素网格对检测有利。
4.6 复杂度分析
FUTR3D的MAFS和解码器是轻量而高效的,模型复杂度主要取决于主干。
-
相关阅读:
嵌入式Linux应用开发-基础知识-第十九章驱动程序基石③
基于Supabase开发公众号接口
第5集丨Caché 对象介绍
Cocos Creator 3.x 优量汇/广点通 android
【算法】牛顿迭代法求平方根及多次方根
Python学习基础笔记二十七——内置函数
416. 分割等和子集
当当API接口开发系列(商品详情页面和按关键词搜索商品列表)
TCP 滑动窗口详解(非常实用)
jsp-一篇就够
- 原文地址:https://blog.csdn.net/weixin_45657478/article/details/126331791