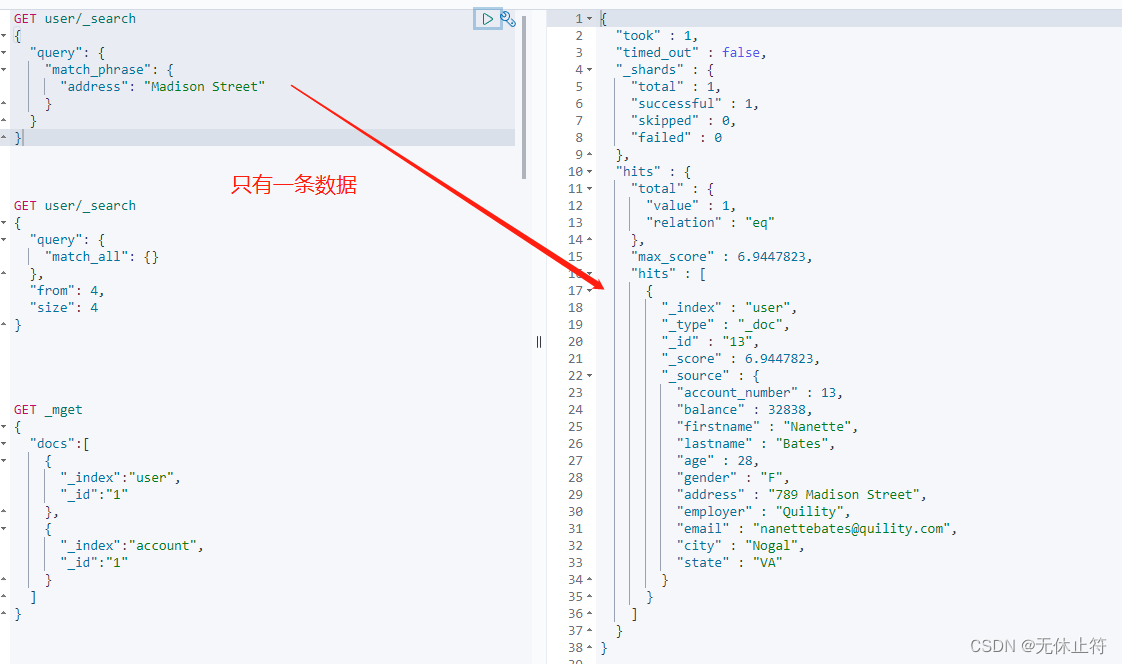
es中的分页查询 :对于es来说,from和size分页在数据量比较小的情况下可行;如果数据量比较大就要使用scrollGET user/ _search
{
"query" : {
"match_all" : { }
} ,
"from" : 4 ,
"size" : 4
}
match查询 :
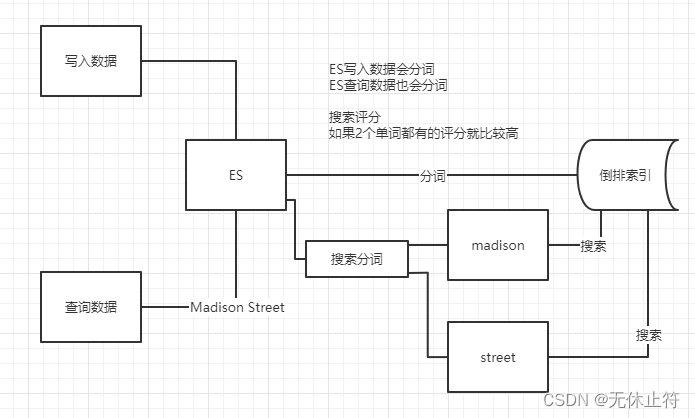
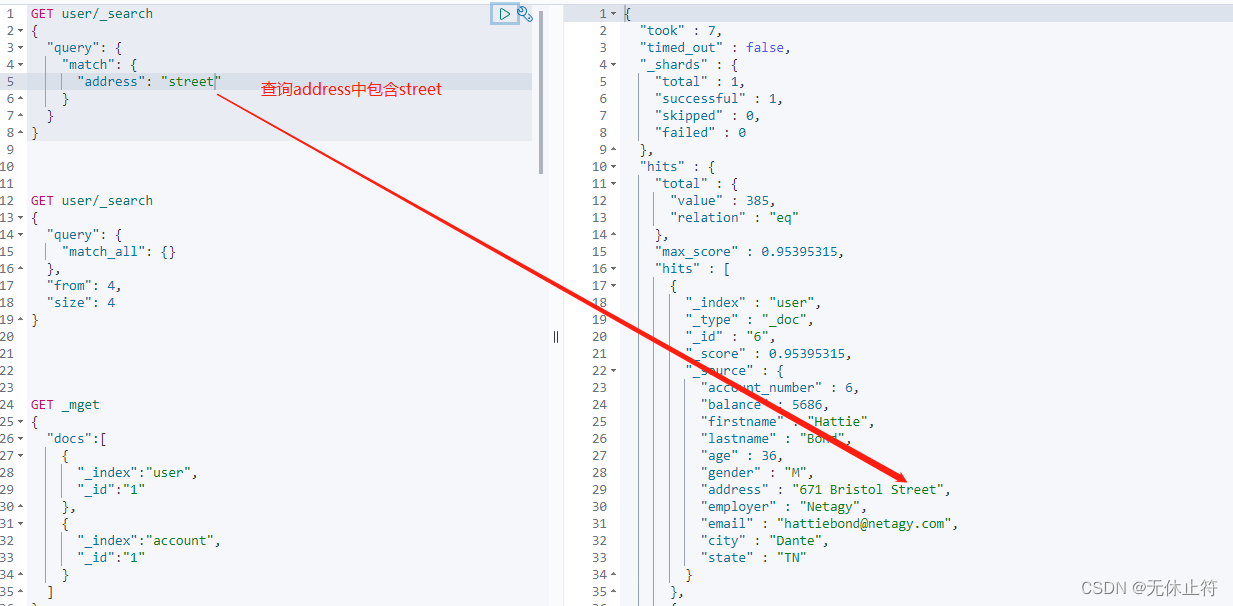
模糊匹配,需要指定字段名,但是输入会进行分词,比如“hello world”会进行拆分为hello和world,然后匹配,如果字段中包含hello或world,或者都包含的结果都会被查询出来; 并且大小写不敏感,也就是说match是一个部分匹配的模糊查询 GET user/ _search
{
"query" : {
"match" : {
"address" : "street"
}
}
}
match_phrase :短语查询
会对输入做分词,但是需要结果中也包含所有的分词,而且顺序要求一样 以“hello world”为例,要求结果中必须包含hello和world,而且还要求他们是连着的,顺序也是固定的 “hello that world”则不满足,world hello也不满足条件 GET user/ _search
{
"query" : {
"match_phrase" : {
"address" : "Madison Street"
}
}
}
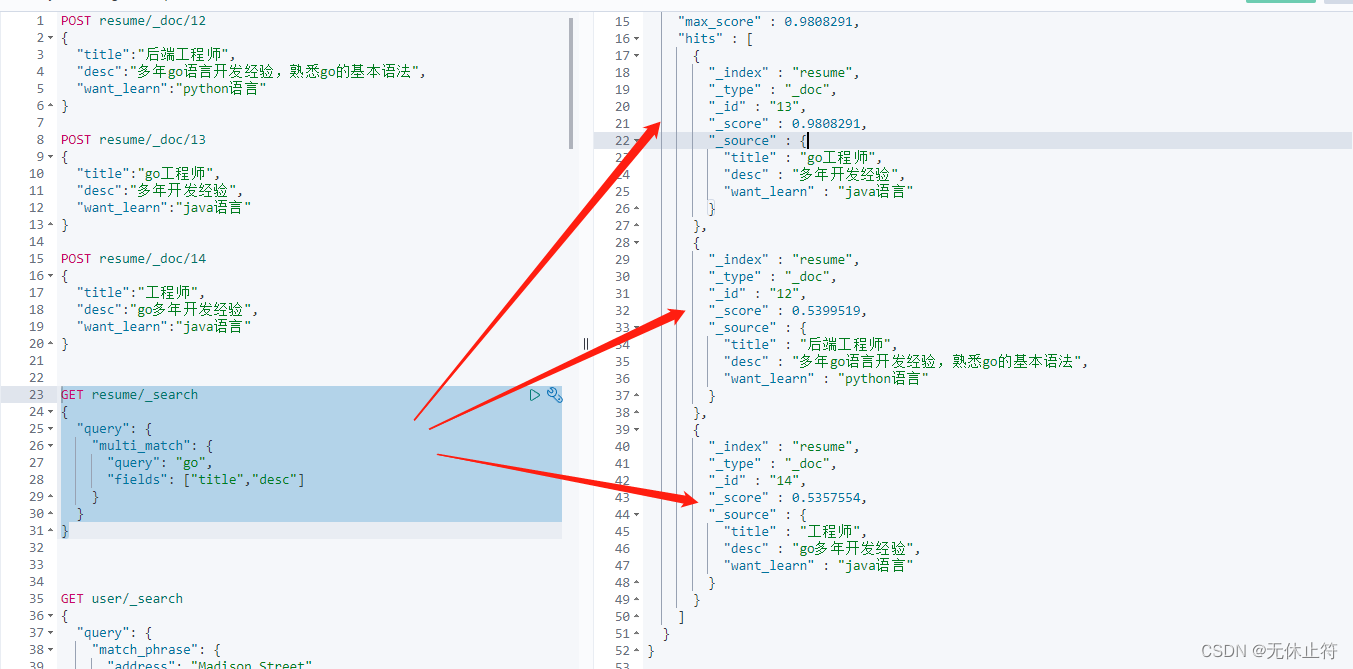
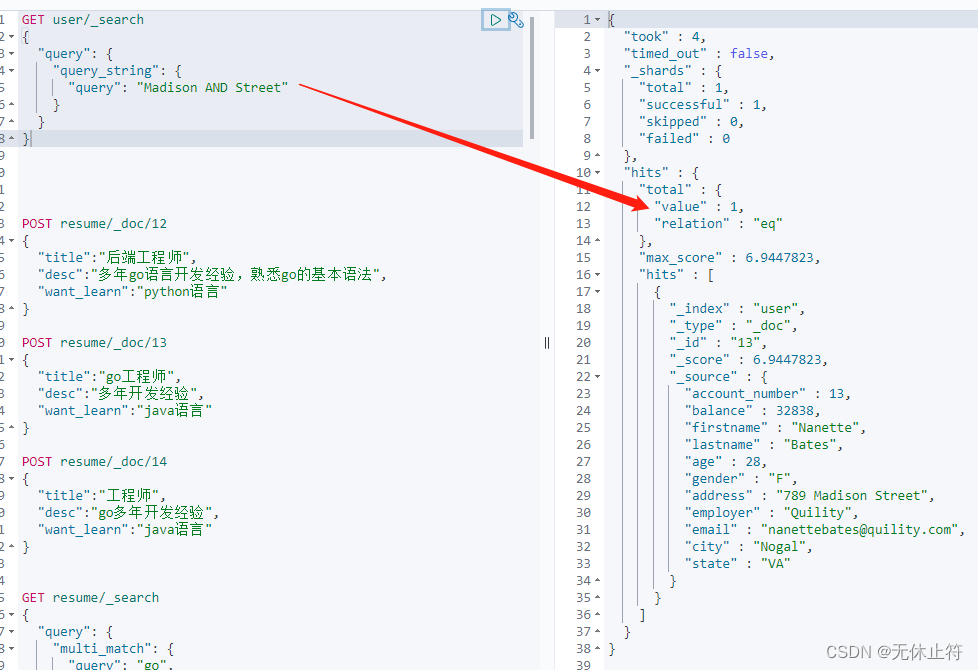
multi_match :提供了一个简便的方法用来对多个字段执行相同的查询,即对指定的多个字段进行match查询我们插入一些测试数据 POST resume/ _doc/ 12
{
"title" : "后端工程师" ,
"desc" : "多年go语言开发经验,熟悉go的基本语法" ,
"want_learn" : "python语言"
}
POST resume/ _doc/ 13
{
"title" : "go工程师" ,
"desc" : "多年开发经验" ,
"want_learn" : "java语言"
}
POST resume/ _doc/ 14
{
"title" : "工程师" ,
"desc" : "go多年开发经验" ,
"want_learn" : "java语言"
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 GET resume/ _search
{
"query" : {
"multi_match" : {
"query" : "go" ,
"fields" : [ "title" , "desc" ]
}
}
}
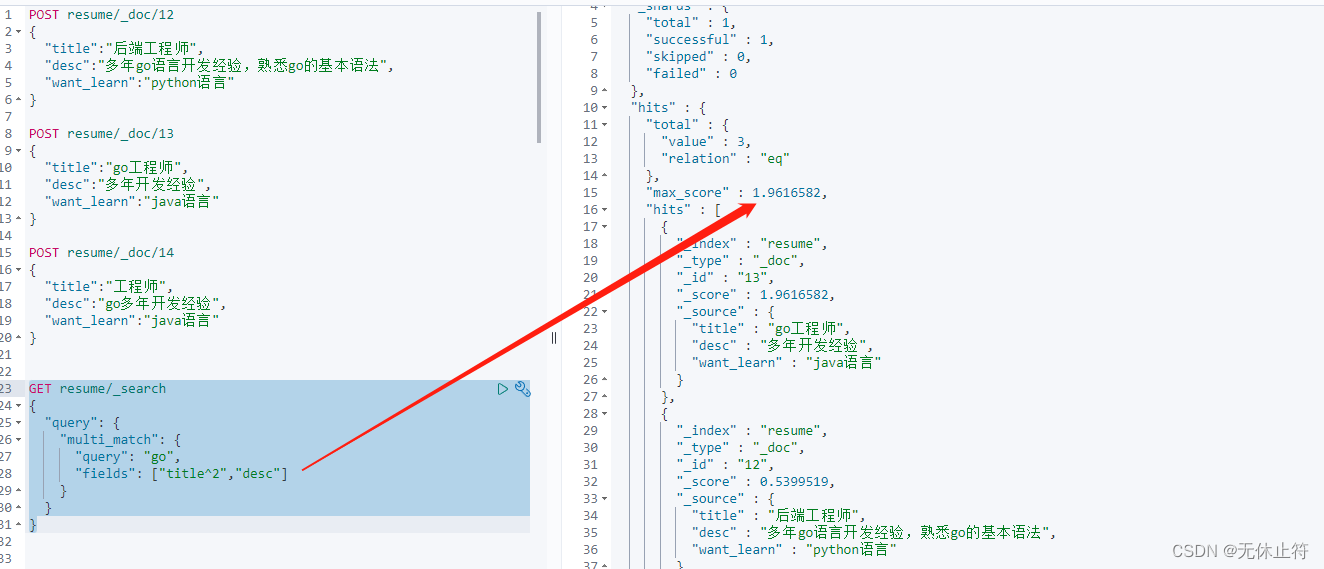
权重设置 :我们希望title中出现go的时候得分更高,注意前面的查询13的得分是0.98,修改title的权重后,得分为1.96GET resume/ _search
{
"query" : {
"multi_match" : {
"query" : "go" ,
"fields" : [ "title^2" , "desc" ]
}
}
}
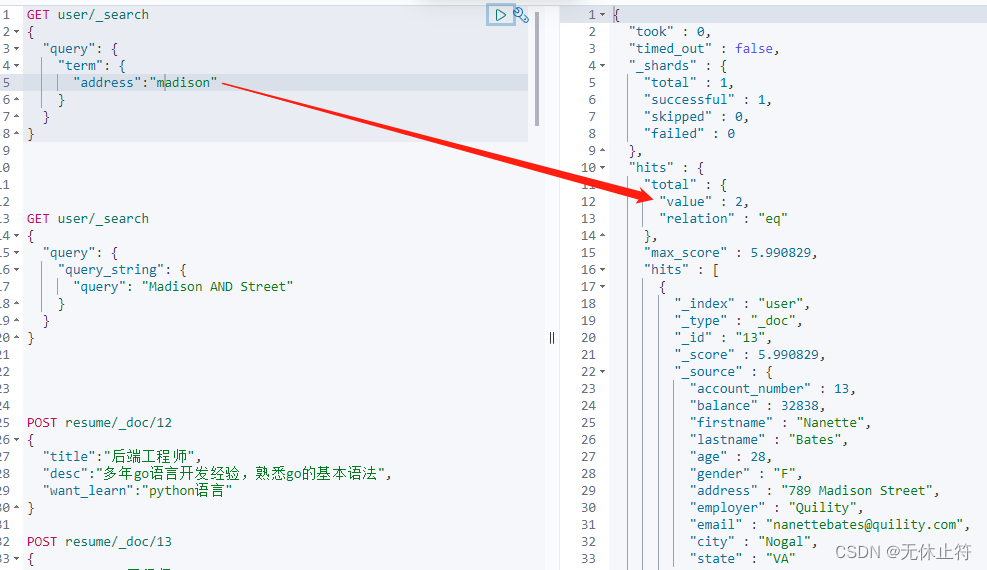
query_string :和match类似,但是match需要指定字段名,query_string是在所有字段中搜索,范围更广泛query_string简单查询 GET user/ _search
{
"query" : {
"query_string" : {
"query" : "Madison Street"
}
}
}
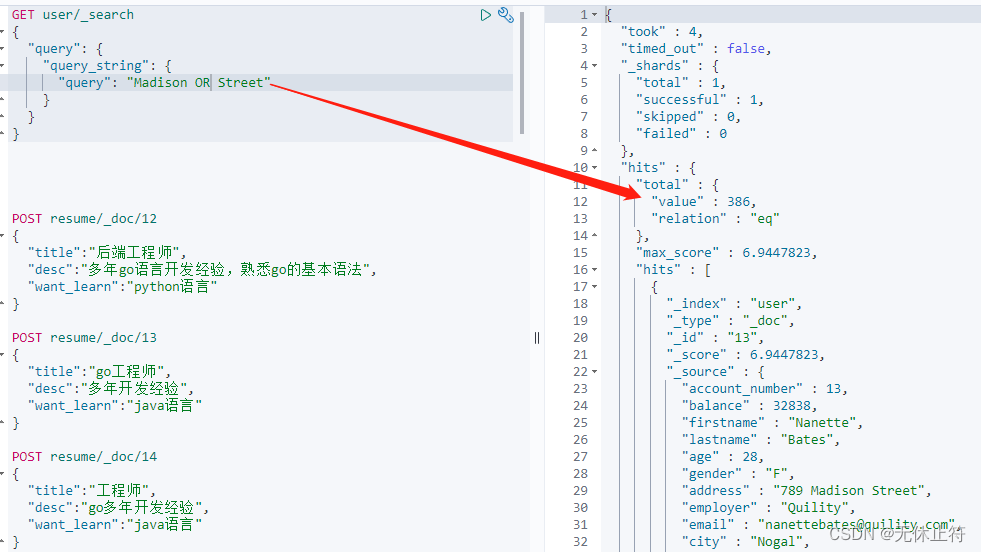
query_string带连接符查询 :OR、AND;注意连接符OR和AND不属于查询内容的一部分
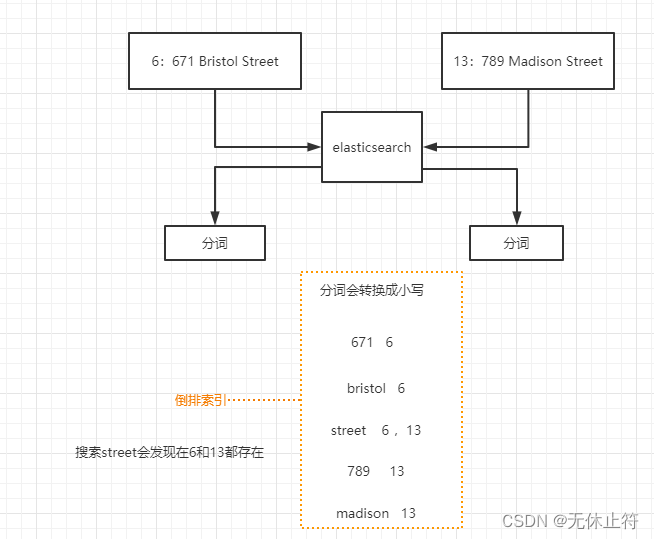
term查询概念 :
term查询不会进行分词;所有的搜索条件都不会进行分词 如果查询单个单词hello,那么term查询和match查询结果是一样的; 如果查询的是“hello world”,结果就差别很大了 term分词的影响 :
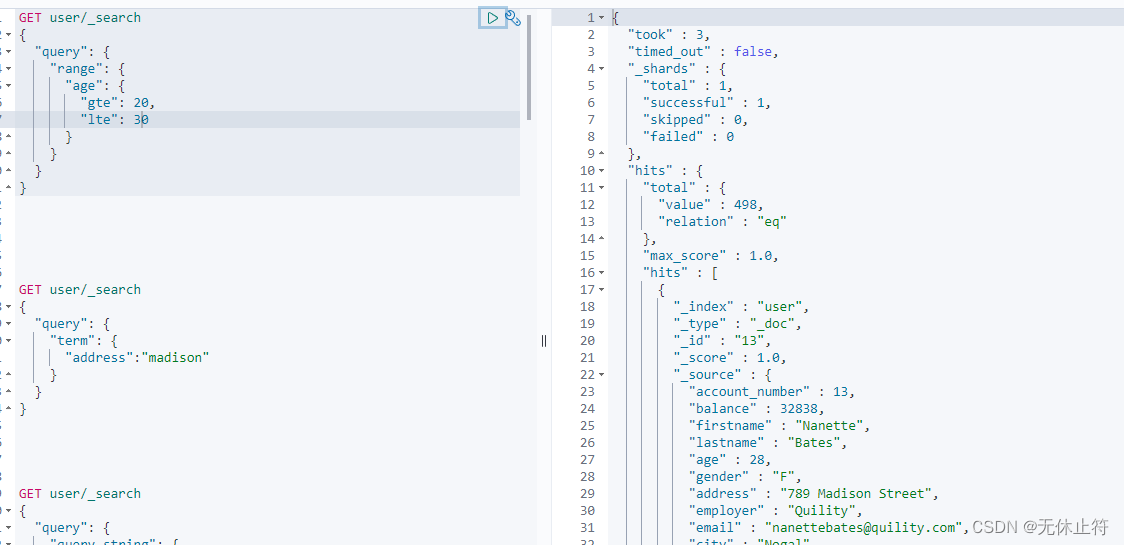
因为term不会分词不会转换成小写,这就导致了如果使用大写的Madison是无法搜索到结果的; 因为数据插入es的时候有分词并全部转换成了小写 GET user/ _search
{
"query" : {
"range" : {
"age" : {
"gte" : 20 ,
"lte" : 30
}
}
}
}
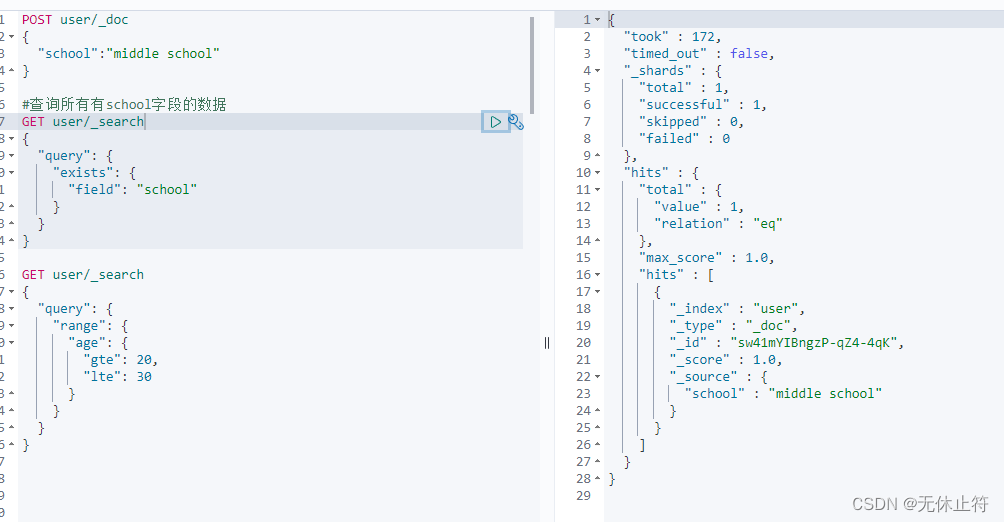
#插入一条测试数据
POST user/ _doc
{
"school" : "middle school"
}
#查询所有有school字段的数据
GET user/ _search
{
"query" : {
"exists" : {
"field" : "school"
}
}
}
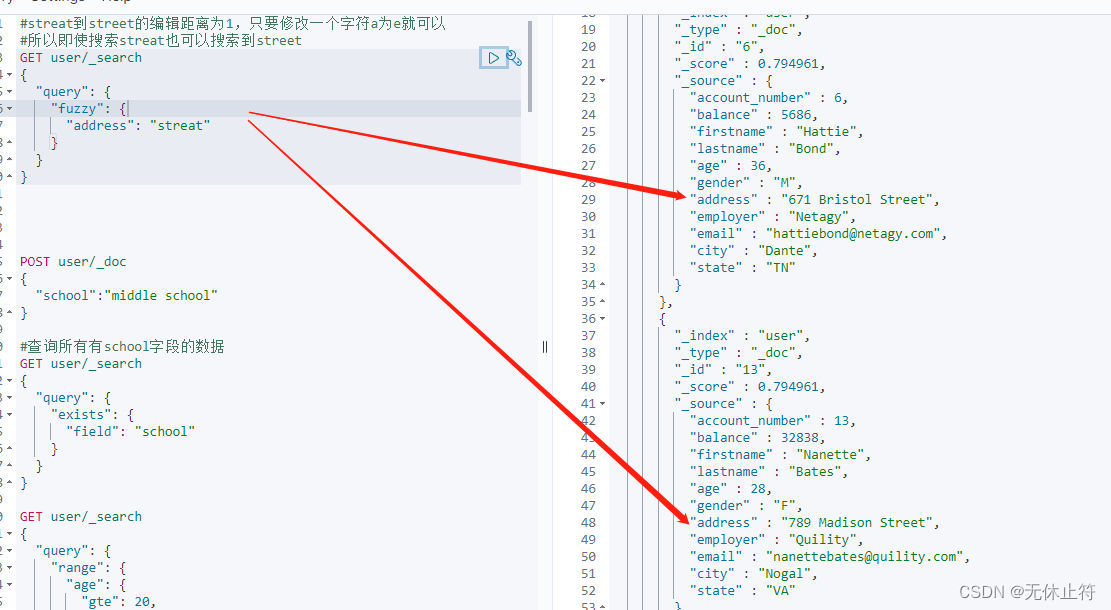
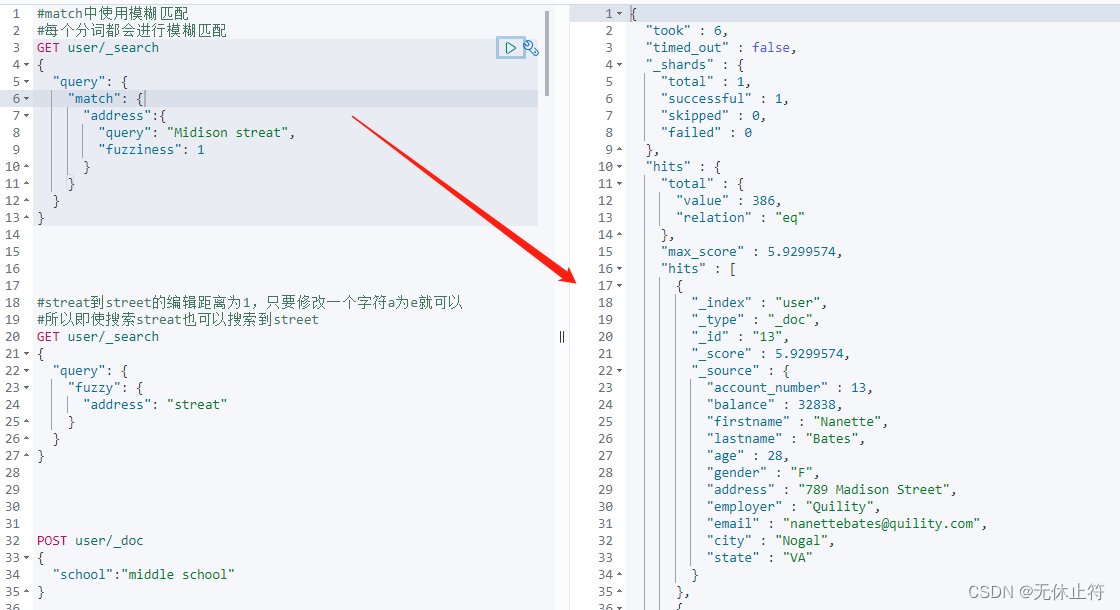
Fuzzy query概念 :返回包含与搜索词相似的词的文档,这些词是由Levenshtein编辑距离度量的编辑距离 :将一个术语转换为另一个术语所需的一个字符的更改次数
#match中使用模糊匹配
#每个分词都会进行模糊匹配
GET user/ _search
{
"query" : {
"match" : {
"address" : {
"query" : "Midison streat" ,
"fuzziness" : 1
}
}
}
}
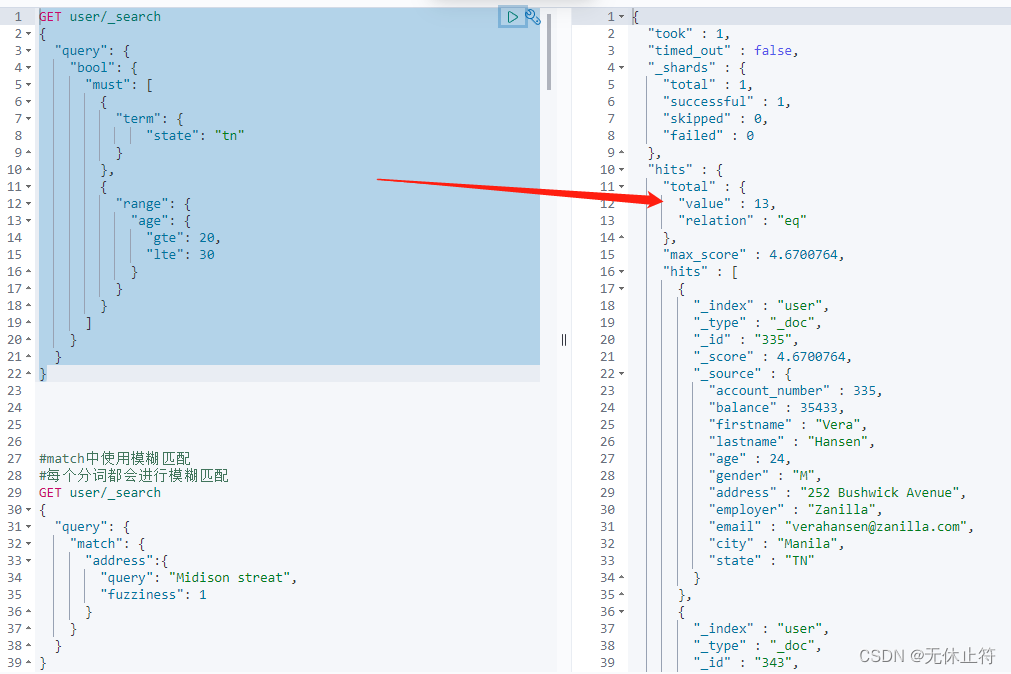
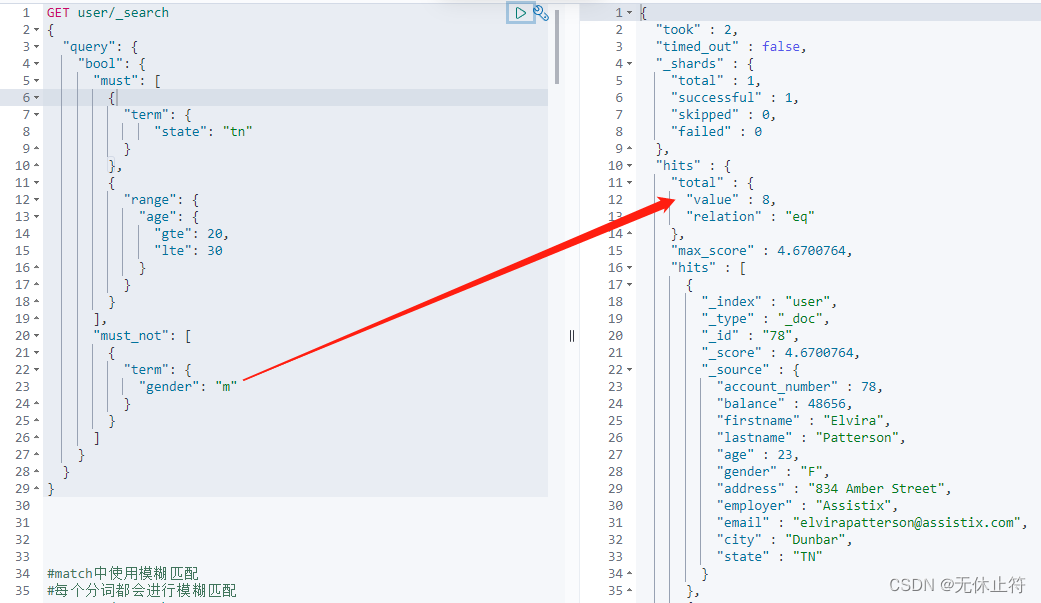
bool查询 :复合查询方法比较多,我们主要使用bool查询;must和should会影响得分,而must not和filter不会影响得分主要用来过滤数据;bool查询采用了一种匹配越多越好的方法,因此每个匹配的must或should子句的分数被加在一起,以提供每个文档的最终得分
must:必须匹配,表示查询条件必须全部满足 should:应该匹配,表示查询条件满足也可以,不满足也可以(满足的得分会高一些) must not:必须不匹配,表示查询条件必须全部不满足 filter:必须匹配,过滤上下文,进行过滤 {
"query" : {
"bool" : {
"must" : [
] ,
"should" : [
] ,
"must_not" : [
] ,
"filter" : [
] ,
}
}
}
GET user/ _search
{
"query" : {
"bool" : {
"must" : [
{
"term" : {
"state" : "tn"
}
} ,
{
"range" : {
"age" : {
"gte" : 20 ,
"lte" : 30
}
}
}
] ,
"must_not" : [
{
"term" : {
"gender" : "m"
}
}
] ,
"should" : [
{
"match" : {
"firstname" : "Decker"
}
}
] ,
"filter" : [
{
"range" : {
"age" : {
"gte" : 25 ,
"lte" : 30
}
}
}
]
}
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46
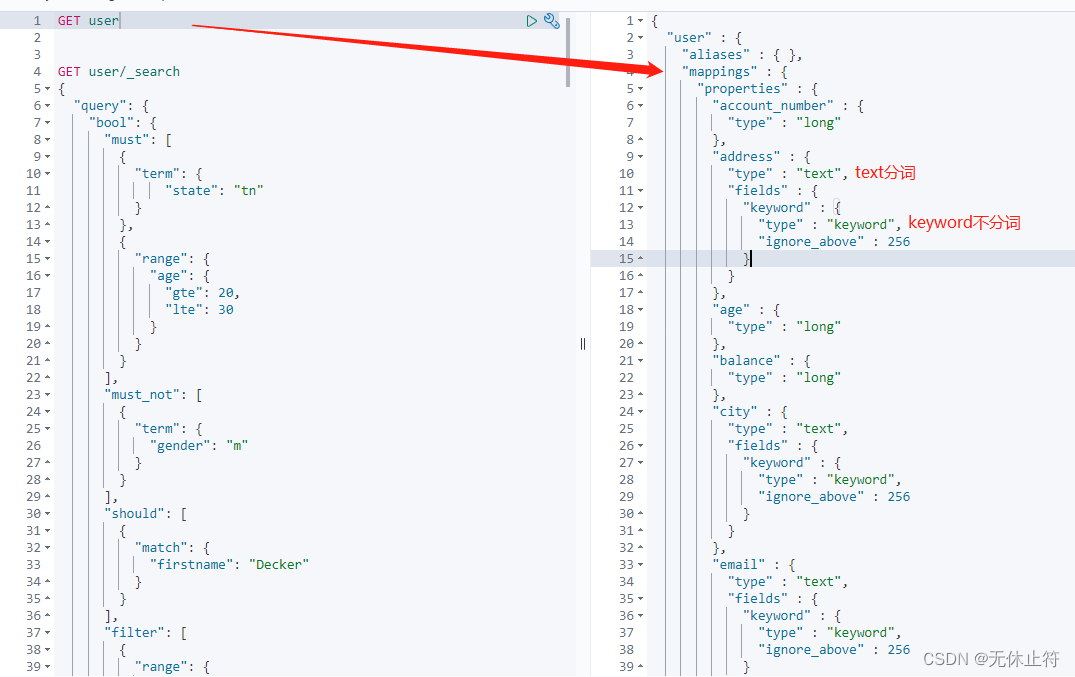
什么是mapping :
mapping类似于数据库中的表结构定义schema; mapping在es中用于定义索引中的字段的名称定义字段的数据类型,比如字符串、数字、布尔、倒排索引的相关配置,比如设置某个字段为不被索引、记录position等; 在es早期版本,一个索引下是可以有多个type,从7.0开始,一个索引只有一个type,也可以说一个type有一个mapping定义 带keyword查询 自定义类型 PUT usertest
{
"mappings" : {
"properties" : {
"age" : {
"type" : "integer"
} ,
"name" : {
"type" : "text"
} ,
"desc" : {
"type" : "keyword"
}
}
}
}
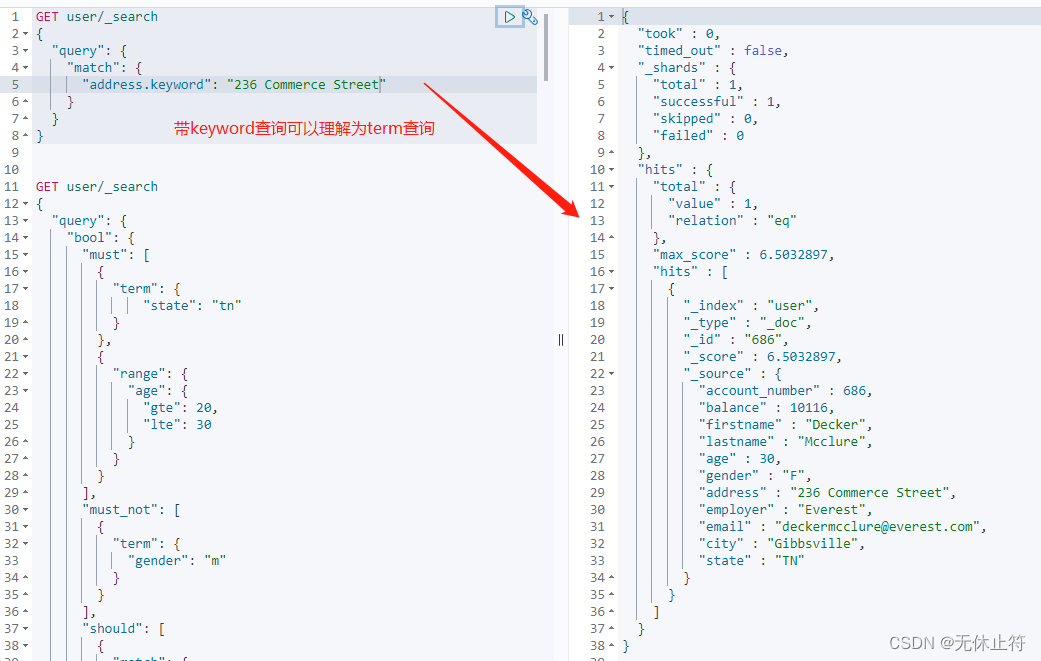
我们来查看如下的场景 :为什么match查询keyword的desc,可以查询到结果analyzer由三部分组成
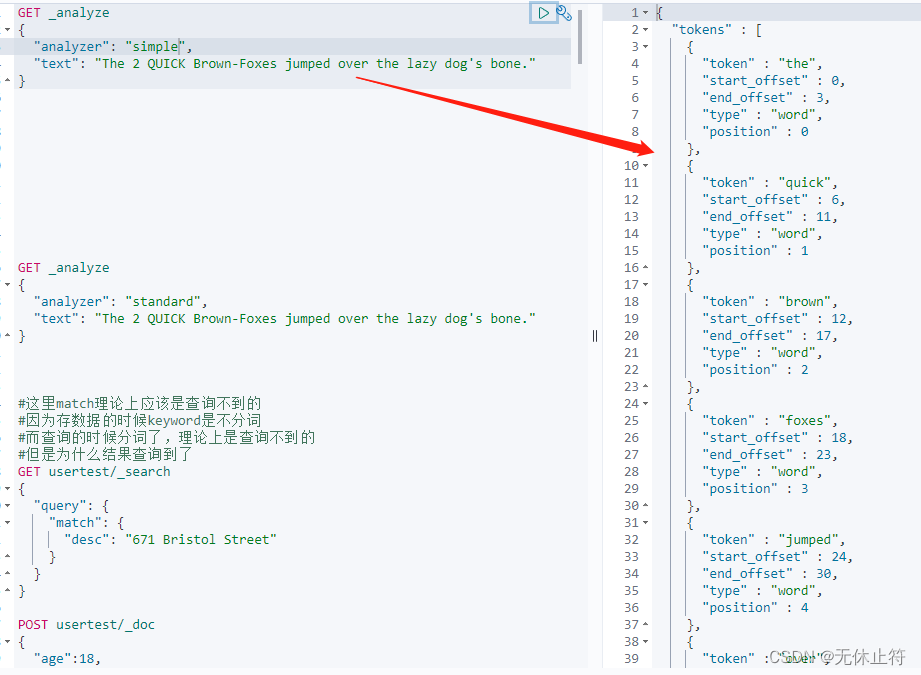
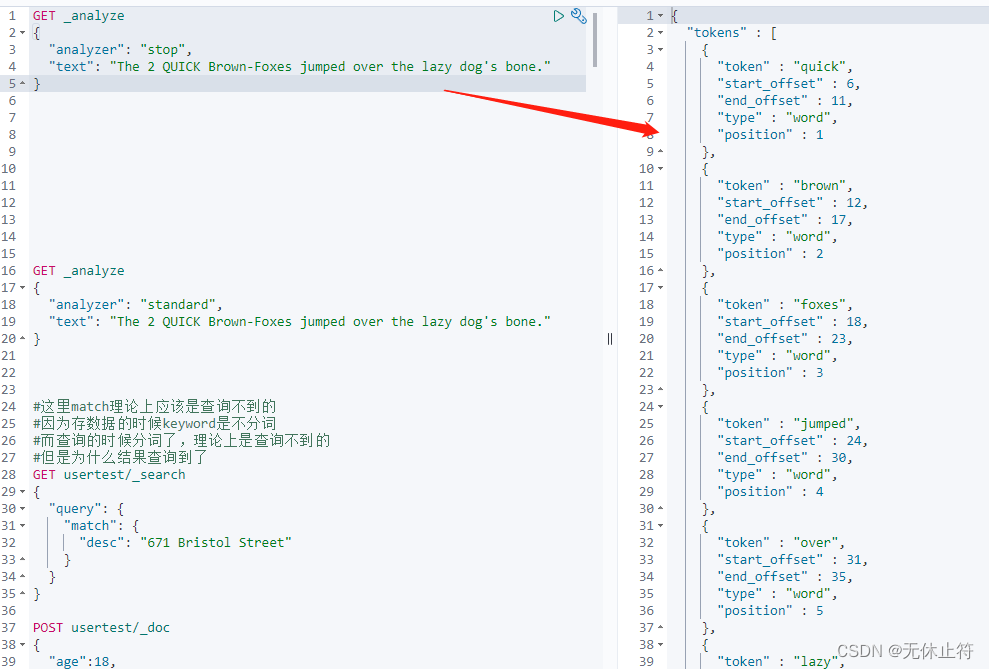
①.Character Filter(字符过滤器):Character Filter字符过滤器接收原始的输入文本,对字符序列进行过滤(如去掉HTML标签,转换阿拉伯数字等);一个analyzer分析器可以有0或n个按顺序执行的字符过滤器 ②.Tokenizer(分词器):将经过处理的文本流分解/分词为单个令牌/术语(token, term, word);标记器也要记录每个term的顺序/位置,以及该术语所表示的原始单词的开始和结束字符偏移量。一个analyzer分析器有且只有一个分词器 ③.Token Filters(词条过滤器):词条过滤器接收词条流,并可以对通过的词条进行增删改(如:将词条转小写,删除停止词,引入同义词条等);词条过滤器不可以更改每个词条的位置或字符偏移量;一个analyzer分析器可以有0或n个按顺序执行的单词过滤器 Elasticsearch内置的分词器 Standard Analyzer GET _analyze
{
"analyzer" : "standard" ,
"text" : "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
Simple Analyzer :按照非字母切分,非字母则会被去除;小写处理GET _analyze
{
"analyzer" : "simple" ,
"text" : "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
Stop Analyzer :小写处理;停用词过滤(the,a,is)GET _analyze
{
"analyzer" : "stop" ,
"text" : "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
Whitespace Analyzer :按空格切分(注意没有大写转小写)GET _analyze
{
"analyzer" : "whitespace" ,
"text" : "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
Keyword Analyzer :不分词,当成一整个term输出GET _analyze
{
"analyzer" : "keyword" ,
"text" : "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
Patter Analyzer :通过正则表达式进行分词;默认是\W+(非字母进行分隔)GET _analyze
{
"analyzer" : "pattern" ,
"text" : "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
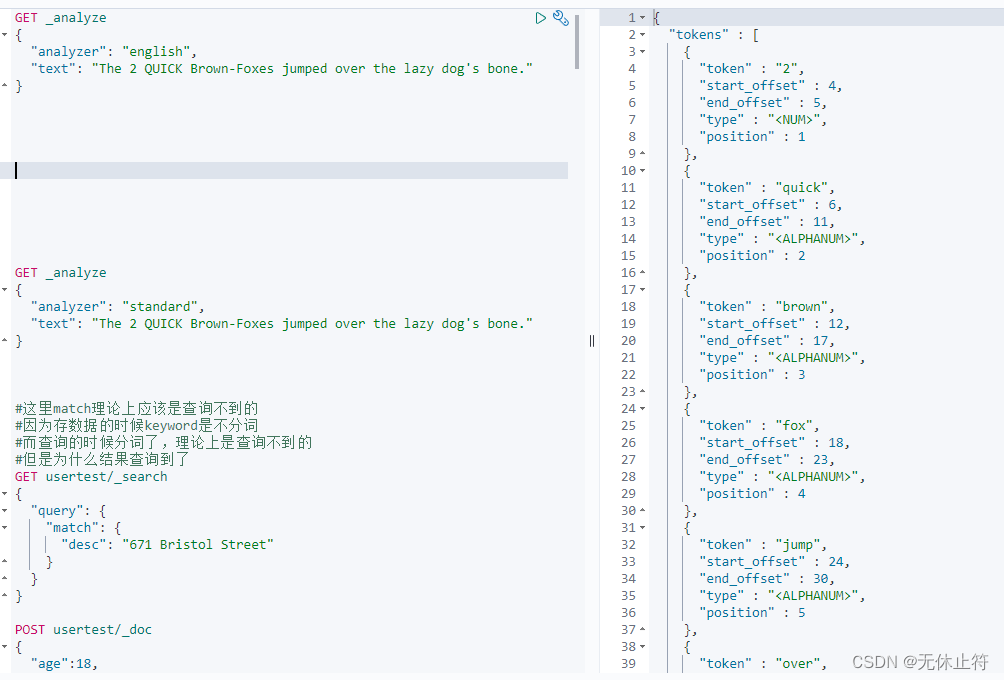
Language Analyzer :语言分析器;中文分词要比英文分词要难,英文都以空格分隔,中文理解通常需要上下文理解才能有正确的理解,比如“苹果,不大好吃”和“苹果,不大,好吃”,这两句意思完全不一样GET _analyze
{
"analyzer" : "english" ,
"text" : "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
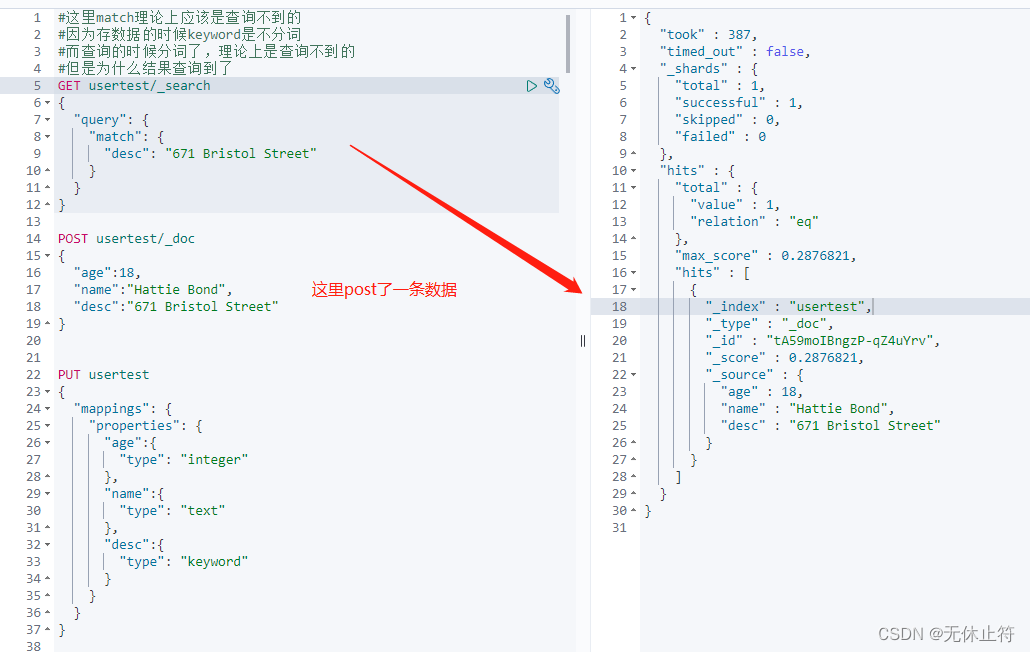
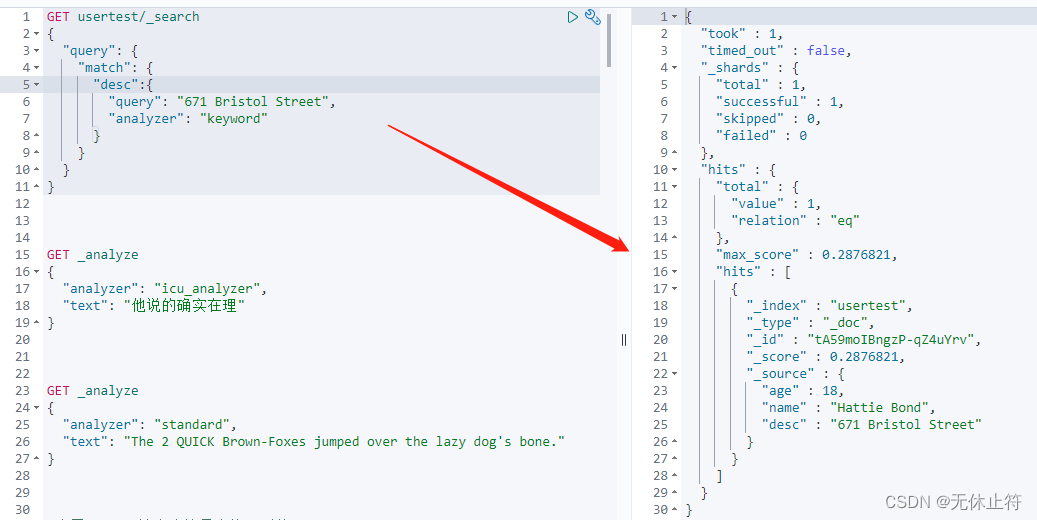
指定Analyzer 查询也可以指定Analyzer GET usertest/ _search
{
"query" : {
"match" : {
"desc" : {
"query" : "671 Bristol Street" ,
"analyzer" : "keyword"
}
}
}
}
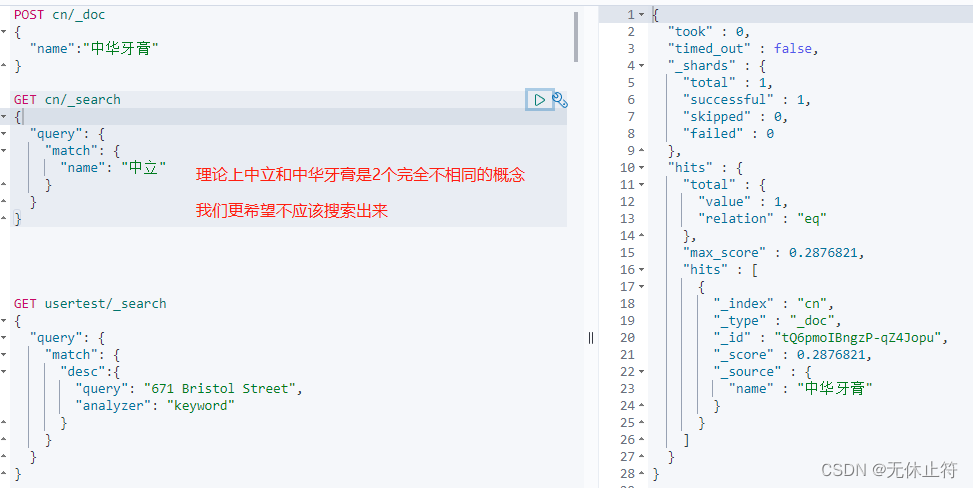
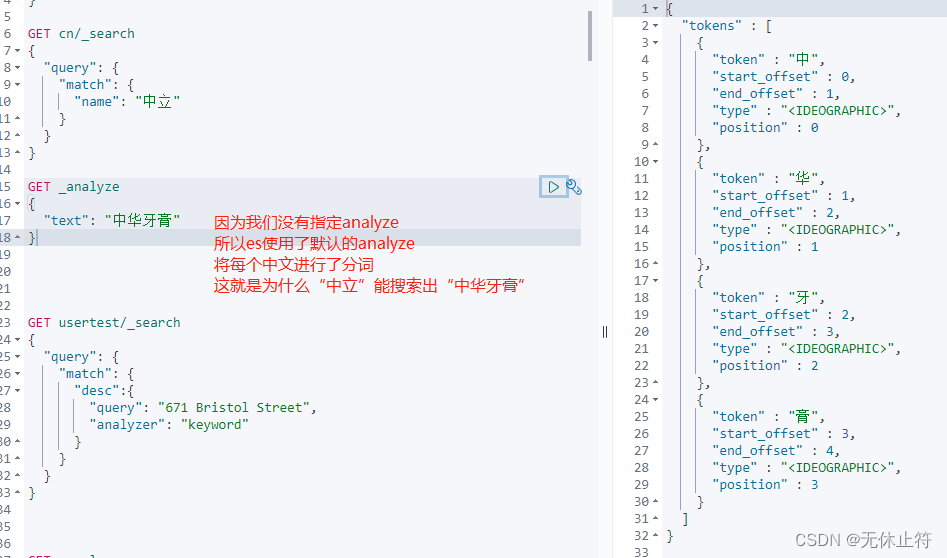
POST cn/ _doc
{
"name" : "中华牙膏"
}
GET cn/ _search
{
"query" : {
"match" : {
"name" : "中立"
}
}
}
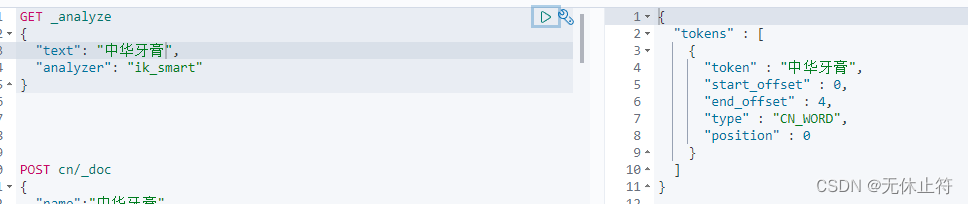
GET _analyze
{
"text" : "中华牙膏"
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
将复杂问题转换为数学问题 :机器学习中NLP就是如此,文本都是一些【非结构化数据】,先将这些数据转化为【结构化数据】,结构化数据就可以转换为【数学问题】,而分词就是转化的第一步词是一个比较合适的粒度 :
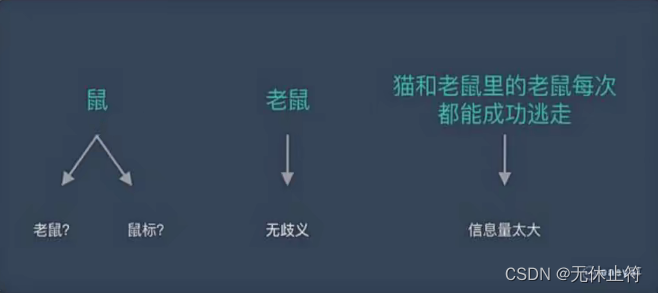
词是表达完整含义的最小单位; 字的粒度太小,无法表达完整含义,如“鼠”可以是“老鼠”也可以是“鼠标”; 而句的粒度太大,承载的信息量多,很难复用,比如“传统方法要分词,一个重要原因是传统方法对远距离依赖的建模能力较弱” 中文分词工具 :根据github上的star排名
jieba Hanlp IK Stanford分词 ansj 分词器 哈工大 LTP KCWS分词器 清华大学THULAC ICTCLAS 英文分词工具
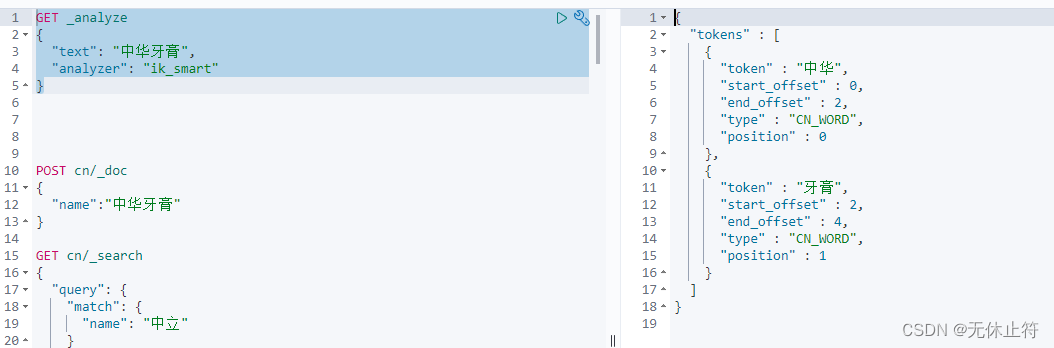
GET _analyze
{
"text" : "中华牙膏" ,
"analyzer" : "ik_smart"
}
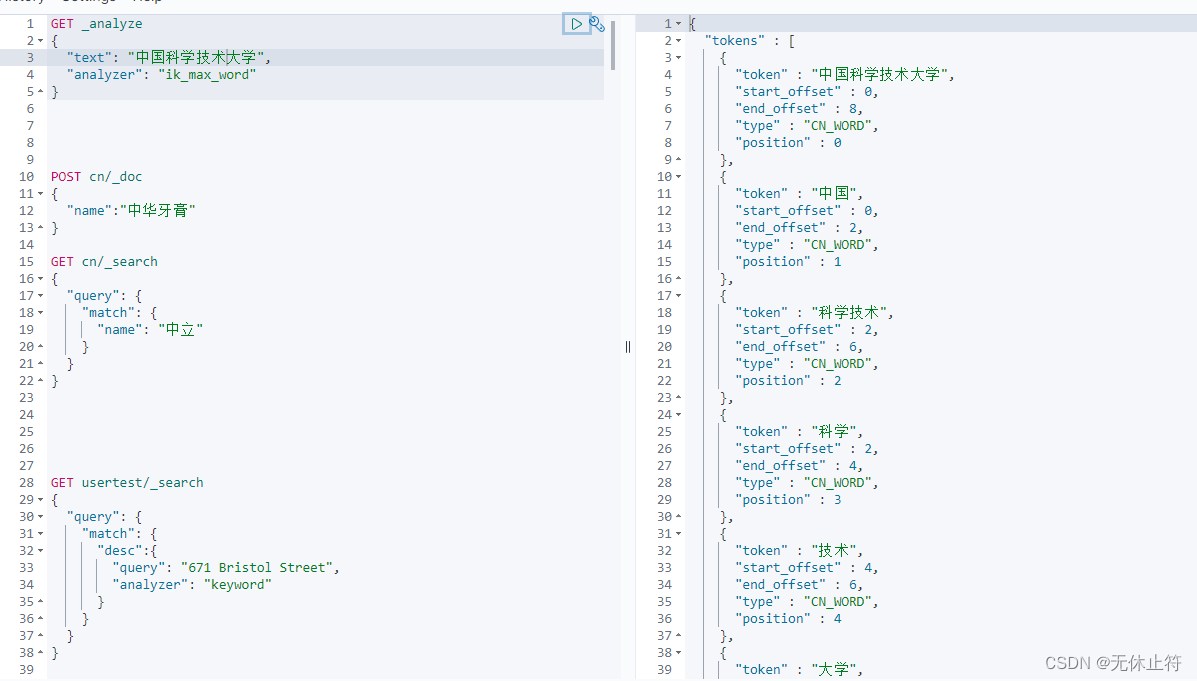
ik_max_word :将所有分词的可能都列举出来GET _analyze
{
"text" : "中国科学技术大学" ,
"analyzer" : "ik_max_word"
}
GET _analyze
{
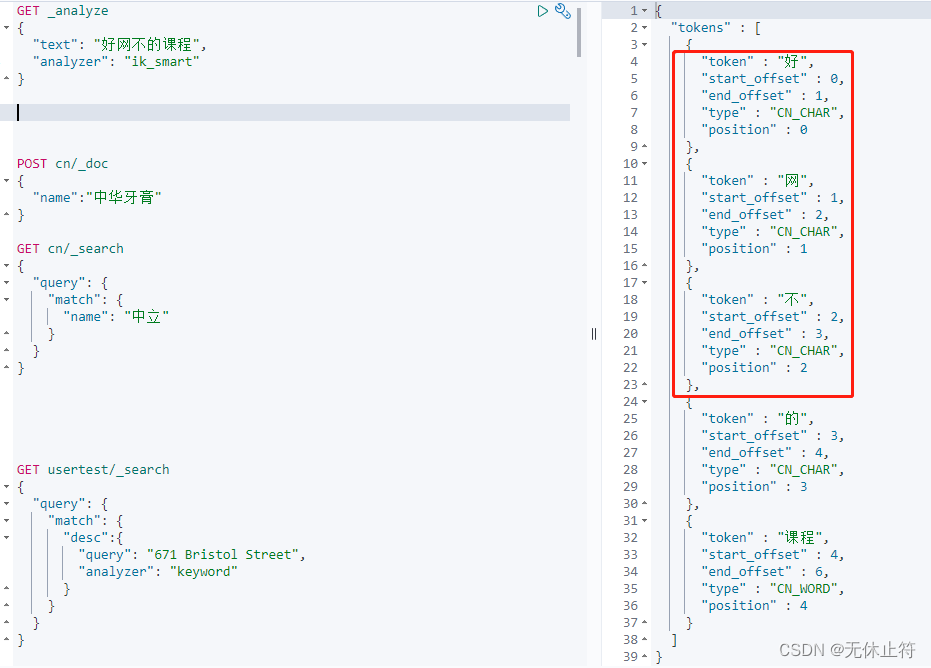
"text" : "好网不的课程" ,
"analyzer" : "ik_smart"
}
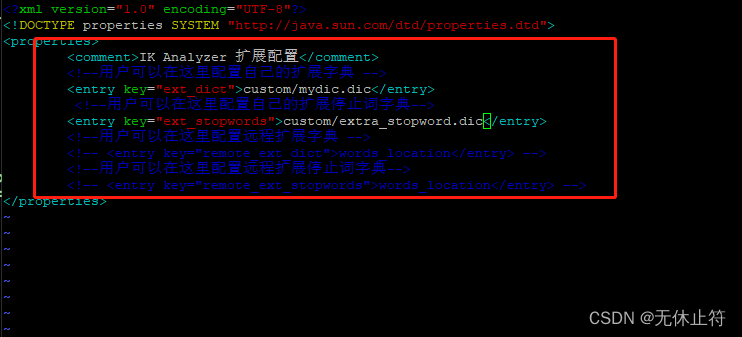
ik定义的词库位置 :我们自定义词库
mydic.dic :添加“好网不”、“中华牙膏”extra_stopword.dic :“的”、“是”、“哟”添加自定义词库到ik中 :