-
主成分分析(Principal Components Analysis, PCA)
主要思想
PCA将 D D D维特征 X = [ x 1 , x 2 , ⋯ , x N ] ∈ R D × N \mathbf{X}=[\mathbf{x}_1, \mathbf{x}_2, \cdots, \mathbf{x}_N]\in\mathbb{R}^{D\times N} X=[x1,x2,⋯,xN]∈RD×N( x i ∈ R D \mathbf{x}_i\in\mathbb{R}^{D} xi∈RD)映射到 d ( d ≪ D ) d(d\ll D) d(d≪D)维空间中( Y = [ y 1 , y 2 , ⋯ , y N ] = W T X ∈ R d × N \mathbf{Y}=[\mathbf{y}_1, \mathbf{y}_2, \cdots, \mathbf{y}_N]=\mathbf{W}^T\mathbf{X}\in\mathbb{R}^{d\times N} Y=[y1,y2,⋯,yN]=WTX∈Rd×N, W = [ w 1 , w 2 , ⋯ , w d ] ∈ R D × d \mathbf{W}=[\mathbf{w}_1,\mathbf{w}_2,\cdots,\mathbf{w}_d]\in\mathbb{R}^{D\times d} W=[w1,w2,⋯,wd]∈RD×d, w i ∈ R D \mathbf{w}_i\in\mathbb{R}^D wi∈RD),使得在降维后的空间中,特征的方差最大,即保留主成分。
推导方法
根据方差最大,可以确定优化目标为
arg max w 1 , w 2 , ⋯ , w d 1 N ∑ j = 1 d ∑ i = 1 N ( w j T x i − w j T x ‾ ) 2w1,w2,⋯,wdargmaxN1j=1∑di=1∑N(wjTxi−wjTx)2\argmax w 1 , w 2 , ⋯ , w d 1 N ∑ j = 1 d ∑ i = 1 N ( w j T x i − w j T x ¯ ) 2
其中
x ‾ = 1 N ∑ i = 1 N x i \overline{\mathbf{x}}=\frac{1}{N}\sum_{i=1}^N{\mathbf{x}_i} x=N1i=1∑Nxi
则,可进一步将优化目标化简为矩阵形式:
arg max w 1 , w 2 , ⋯ , w d 1 N ∑ j = 1 d ∑ i = 1 N ( w j T x i − w j T x ‾ ) 2 arg max w 1 , w 2 , ⋯ , w d ∑ j = 1 d w j T ( 1 N ∑ i = 1 N ( x i − x ‾ ) ( x i − x ‾ ) T ) w jw1,w2,⋯,wdargmaxw1,w2,⋯,wdargmaxN1j=1∑di=1∑N(wjTxi−wjTx)2j=1∑dwjT(N1i=1∑N(xi−x)(xi−x)T)wj\argmax w 1 , w 2 , ⋯ , w d 1 N ∑ j = 1 d ∑ i = 1 N ( w j T x i − w j T x ¯ ) 2 \argmax w 1 , w 2 , ⋯ , w d ∑ j = 1 d w j T ( 1 N ∑ i = 1 N ( x i − x ¯ ) ( x i − x ¯ ) T ) w j
令 X ~ = [ x 1 − x ‾ , x 2 − x ‾ , ⋯ , x N − x ‾ ] ∈ R D × N \widetilde{\mathbf{X}}=\in\mathbb{R}^{D\times N} X =[x1−x,x2−x,⋯,xN−x]∈RD×N,则[ x 1 − x ¯ , x 2 − x ¯ , ⋯ , x N − x ¯ ]
arg max w 1 , w 2 , ⋯ , w d ∑ j = 1 d w j T ( 1 N ∑ i = 1 N ( x i − x ‾ ) ( x i − x ‾ ) T ) w j arg max w 1 , w 2 , ⋯ , w d ∑ j = 1 d w j T X ~ X ~ T N w j arg max w 1 , w 2 , ⋯ , w d t r a c e ( W T X ~ X ~ T N W )w1,w2,⋯,wdargmaxw1,w2,⋯,wdargmaxw1,w2,⋯,wdargmaxj=1∑dwjT(N1i=1∑N(xi−x)(xi−x)T)wjj=1∑dwjTNX X Twjtrace(WTNX X TW)\argmax w 1 , w 2 , ⋯ , w d ∑ j = 1 d w j T ( 1 N ∑ i = 1 N ( x i − x ¯ ) ( x i − x ¯ ) T ) w j \argmax w 1 , w 2 , ⋯ , w d ∑ j = 1 d w j T X ~ X ~ T N w j \argmax w 1 , w 2 , ⋯ , w d t r a c e ( W T X ~ X ~ T N W )
一般来说引入 W T W = I \mathbf{W}^T\mathbf{W}=\mathbb{I} WTW=I的约束,这样能确保只关注 w i \mathbf{w}_i wi的方向而不是尺度大小,并且对任意 i ≠ j i\neq j i=j w i \mathbf{w}_i wi和 w j \mathbf{w}_j wj都是不相关的,从而能够保留更多的原数据信息。新的优化目标为
arg max W t r a c e ( W T X ~ X ~ T N W ) s . t . W T W = IWargmax s.t.trace(WTNX X TW)WTW=I\argmax W t r a c e ( W T X ~ X ~ T N W ) s . t . W T W = I
采用拉格朗日乘子的方法求解以上优化问题,引入 Λ ∈ R d × d \mathbf{\Lambda}\in\mathbb{R}^{d\times d} Λ∈Rd×d,由于约束条件是对称的,因此 Λ \mathbf{\Lambda} Λ也满足 Λ T = Λ \mathbf{\Lambda}^T=\mathbf{\Lambda} ΛT=Λ,则
L ( W , Λ ) = − t r a c e ( W T X ~ X ~ T N W ) + t r a c e ( Λ ( W T W − I ) ) L\left( \mathbf{W},\mathbf{\Lambda } \right) =-trace\left( \mathbf{W}^T\frac{\mathbf{\tilde{X}\tilde{X}}^T}{N}\mathbf{W} \right) +trace\left( \mathbf{\Lambda }\left( \mathbf{W}^T\mathbf{W}-\mathbb{I} \right) \right) L(W,Λ)=−trace(WTNX~X~TW)+trace(Λ(WTW−I))
则
∂ L ( W , Λ ) ∂ W = − 2 X ~ X ~ T N W + 2 W Λ = 0 X ~ X ~ T N W = W Λ [ X ~ X ~ T N w 1 , ⋯ , X ~ X ~ T N w d ] = [ w 1 , ⋯ , w d ] [ λ 11 λ 12 ⋯ λ 1 d λ 21 λ 22 ⋯ λ 2 d ⋮ ⋮ ⋱ ⋮ λ d 1 λ d 2 ⋯ λ d d ] \frac{\partial L\left( \mathbf{W},\mathbf{\Lambda } \right)}{\partial \mathbf{W}}=-2\frac{\mathbf{\tilde{X}\tilde{X}}^T}{N}\mathbf{W}+2\mathbf{ W\Lambda}=0 \\ \frac{\mathbf{\tilde{X}\tilde{X}}^T}{N}\mathbf{W}=\mathbf{W\Lambda } \\ \left[ \frac{\mathbf{\tilde{X}\tilde{X}}^T}{N}\mathbf{w}_1,\cdots ,\frac{\mathbf{\tilde{X}\tilde{X}}^T}{N}\mathbf{w}_d \right] =\left[ \mathbf{w}_1,\cdots ,\mathbf{w}_d \right] \left[\right] \\ ∂W∂L(W,Λ)=−2NX~X~TW+2WΛ=0NX~X~TW=WΛ[NX~X~Tw1,⋯,NX~X~Twd]=[w1,⋯,wd]⎣ ⎡λ11λ21⋮λd1λ12λ22⋮λd2⋯⋯⋱⋯λ1dλ2d⋮λdd⎦ ⎤λ 11 λ 12 ⋯ λ 1 d λ 21 λ 22 ⋯ λ 2 d ⋮ ⋮ ⋱ ⋮ λ d 1 λ d 2 ⋯ λ d d
X ~ X ~ T N w i = [ w 1 , ⋯ , w d ] [ λ 1 i ⋮ λ d i ] w i T X ~ X ~ T N w i = λ i i \frac{\mathbf{\tilde{X}\tilde{X}}^T}{N}\mathbf{w}_i=\left[ \mathbf{w}_1,\cdots ,\mathbf{w}_d \right] \left[\right] \\ \mathbf{w}_i^T\frac{\mathbf{\tilde{X}\tilde{X}}^T}{N}\mathbf{w}_i=\lambda _{ii} NX~X~Twi=[w1,⋯,wd]⎣ ⎡λ1i⋮λdi⎦ ⎤wiTNX~X~Twi=λiiλ 1 i ⋮ λ d i
以上优化问题的最终结果,实质上就是 X ~ X ~ T N \frac{\widetilde{\mathbf{X}}\widetilde{\mathbf{X}}^T}N NX X T的最大的 d d d特征值( λ 11 , λ 22 , ⋯ , λ d d \lambda _{11}, \lambda _{22}, \cdots, \lambda _{dd} λ11,λ22,⋯,λdd)所对应的特征向量。import matplotlib.pyplot as plt import numpy as np from sklearn import datasets from sklearn.decomposition import PCA def plot_2d(X_r, y, target_names, name): plt.subplot(1,2,1 if 'Sklearn' in name else 2) colors = ["navy", "turquoise", "darkorange"] lw = 2 for color, i, target_name in zip(colors, [0, 1, 2], target_names): plt.scatter( X_r[y == i, 0], X_r[y == i, 1], color=color, alpha=0.8, lw=lw, label=target_name ) plt.legend(loc="best", shadow=False, scatterpoints=1) plt.xlabel(f"{name} of IRIS dataset") def sklearn_pca(X, y, target_names): pca = PCA(n_components=2) X_r = pca.fit(X).transform(X) print(pca.explained_variance_) plot_2d(X_r, y, target_names, 'Sklearn PCA') return X_r def my_pca(X, y, target_names): n_components=2 # 去中心化 N = X.shape[0] X_mean = np.mean(X, axis=0) X_ = X - X_mean # 构建协方差矩阵 XX = 1. / N * np.matmul(X_.T, X_) # 求特征向量 values, vectors = np.linalg.eig(XX) idxs = np.argsort(values) W = vectors[:,[idxs[-i] for i in range(1,n_components+1)]] X_r = np.matmul(X_, W) X_r[:,1] = - X_r[:,1] #确保与sklearn得到的结果一致 plot_2d(X_r, y, target_names, 'My Imple. PCA') return X_r if __name__ == '__main__': iris = datasets.load_iris() X = iris.data y = iris.target target_names = iris.target_names plt.figure() X_r1 = sklearn_pca(X, y, target_names) X_r2 = my_pca(X, y, target_names) print(np.sum(np.abs(X_r1 - X_r2))) plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68

说明自己实现的方法与sklearn内核一致。核技巧
利用 ϕ \phi ϕ将 x i ∈ R D \mathbf{x}_i\in\mathbb{R}^D xi∈RD映射到高维度空间,得到 X ϕ = [ ϕ ( x 1 ) , ϕ ( x 2 ) , ⋯ , ϕ ( x N ) ] \mathbf{X}_\phi=[\phi(\mathbf{x}_1), \phi(\mathbf{x}_2), \cdots, \phi(\mathbf{x}_N)] Xϕ=[ϕ(x1),ϕ(x2),⋯,ϕ(xN)],在该高维空间中进行PCA操作。首先,去中心化
X ϕ ~ = [ ϕ ( x 1 ) − ϕ ( x ) ‾ , ϕ ( x 2 ) − ϕ ( x ) ‾ , ⋯ , ϕ ( x N ) − ϕ ( x ) ‾ ] \widetilde{\mathbf{X}_\phi}=\left[\phi(\mathbf{x}_1)-\overline{\phi(\mathbf{x})}, \phi(\mathbf{x}_2)-\overline{\phi(\mathbf{x})}, \cdots, \phi(\mathbf{x}_N)-\overline{\phi(\mathbf{x})}\right] Xϕ =[ϕ(x1)−ϕ(x),ϕ(x2)−ϕ(x),⋯,ϕ(xN)−ϕ(x)]
其中
ϕ ( x ) ‾ = 1 N ∑ i = 1 N ϕ ( x i ) \overline{\phi(\mathbf{x})}=\frac{1}{N}\sum_{i=1}^N\phi(\mathbf{x}_i) ϕ(x)=N1i=1∑Nϕ(xi)
则
X ϕ ~ X ϕ ~ T N = 1 N ∑ i = 1 N ( ϕ ( x i ) − 1 N ∑ j = 1 N ϕ ( x j ) ) ( ϕ ( x i ) − 1 N ∑ j = 1 N ϕ ( x j ) ) TNXϕ Xϕ T=N1i=1∑N(ϕ(xi)−N1j=1∑Nϕ(xj))(ϕ(xi)−N1j=1∑Nϕ(xj))TX ϕ ~ X ϕ ~ T N = 1 N ∑ i = 1 N ( ϕ ( x i ) − 1 N ∑ j = 1 N ϕ ( x j ) ) ( ϕ ( x i ) − 1 N ∑ j = 1 N ϕ ( x j ) ) T
需计算以上矩阵的特征向量 w k \mathbf{w}_k wk(对应第 k k k大的特征值为 λ k \lambda_k λk所对应的特征向量)
1 N ∑ i = 1 N ( ϕ ( x i ) − 1 N ∑ j = 1 N ϕ ( x j ) ) ( ϕ ( x i ) − 1 N ∑ j = 1 N ϕ ( x j ) ) T w k = λ k w kN1i=1∑N(ϕ(xi)−N1j=1∑Nϕ(xj))(ϕ(xi)−N1j=1∑Nϕ(xj))Twk=λkwk1 N ∑ i = 1 N ( ϕ ( x i ) − 1 N ∑ j = 1 N ϕ ( x j ) ) ( ϕ ( x i ) − 1 N ∑ j = 1 N ϕ ( x j ) ) T w k = λ k w k
所以
w k = [ ∑ i = 1 N ϕ ( x i ) T w k − 1 N ∑ j = 1 N ϕ ( x j ) T w k N λ k ϕ ( x i ) ] = ∑ i = 1 N α k i ϕ ( x i )wk=[i=1∑NNλkϕ(xi)Twk−N1∑j=1Nϕ(xj)Twkϕ(xi)]=i=1∑Nαkiϕ(xi)\begin{aligned} \mathbf{w}_k&=\left[ \sum_{i=1}^N{ {\color{red} \frac{\phi (\mathbf{x}_i)^T\mathbf{w}_k-\frac{1}{N}\sum_{j=1}^N{\phi (\mathbf{x}_j)^T\mathbf{w}_k}}{N\lambda _k}}\phi (\mathbf{x}_i)} \right]\\ &=\sum_{i=1}^N{ {\color{red} \alpha _{ki}}\phi (\mathbf{x}_i)}\\ \end{aligned}
其中 α k i = ( ϕ ( x i ) T w k − 1 N ∑ j = 1 N ϕ ( x j ) T w k ) / ( N λ k ) \alpha_{ki}=\left( \phi (\mathbf{x}_i)^T\mathbf{w}_k-\frac{1}{N}\sum_{j=1}^N{\phi (\mathbf{x}_j)^T\mathbf{w}_k}\right)/(N\lambda_k) αki=(ϕ(xi)Twk−N1∑j=1Nϕ(xj)Twk)/(Nλk),则下面将求出相应的 α k i \alpha_{ki} αki,将上式带入公式(5),可得
1 N ∑ i = 1 N ( ϕ ( x i ) − 1 N ∑ j = 1 N ϕ ( x j ) ) ( ϕ ( x i ) − 1 N ∑ j = 1 N ϕ ( x j ) ) T ∑ i = 1 N α k i ϕ ( x i ) = λ k ∑ i = 1 N α k i ϕ ( x i ) 1 N ( X ϕ X ϕ T − 1 N X ϕ 1 N × 1 1 N × 1 T X ϕ T ) X ϕ α k = λ k X ϕ α k 1 N ( X ϕ T X ϕ X ϕ T X ϕ α k − X ϕ T X ϕ 1 N × 1 1 N × 1 T N X ϕ T X ϕ α k ) = λ k X ϕ T X ϕ α kN1i=1∑N(ϕ(xi)−N1j=1∑Nϕ(xj))(ϕ(xi)−N1j=1∑Nϕ(xj))Ti=1∑Nαkiϕ(xi)N1(XϕXϕT−N1Xϕ1N×11N×1TXϕT)XϕαkN1(XϕTXϕXϕTXϕαk−XϕTXϕN1N×11N×1TXϕTXϕαk)=λki=1∑Nαkiϕ(xi)=λkXϕαk=λkXϕTXϕαk1 N ∑ i = 1 N ( ϕ ( x i ) − 1 N ∑ j = 1 N ϕ ( x j ) ) ( ϕ ( x i ) − 1 N ∑ j = 1 N ϕ ( x j ) ) T ∑ i = 1 N α k i ϕ ( x i ) = λ k ∑ i = 1 N α k i ϕ ( x i ) 1 N ( X ϕ X ϕ T − 1 N X ϕ 1 N × 1 1 N × 1 T X ϕ T ) X ϕ α k = λ k X ϕ α k 1 N ( X ϕ T X ϕ X ϕ T X ϕ α k − X ϕ T X ϕ 1 N × 1 1 N × 1 T N X ϕ T X ϕ α k ) = λ k X ϕ T X ϕ α k
而核矩阵 K = X ϕ T X ϕ \mathbf{K}=\mathbf{X}_\phi^T\mathbf{X}_\phi K=XϕTXϕ,所以
1 N ( K K α k − K 1 N × 1 1 N × 1 T N K α k ) = λ k K α k 1 N ( I − 1 N × N N ) K α k = λ k α k K ~ α k = λ k α kN1(KKαk−KN1N×11N×1TKαk)N1(I−N1N×N)KαkK αk=λkKαk=λkαk=λkαk1 N ( K K α k − K 1 N × 1 1 N × 1 T N K α k ) = λ k K α k 1 N ( I − 1 N × N N ) K α k = λ k α k K ~ α k = λ k α k
那么可以求出 K ~ \widetilde{\mathbf{K}} K 的第 k k k大的特征值 λ k \lambda_k λk所对应的特征向量 α k \alpha_k αk,从而得到
w k = X ϕ α k \mathbf{w}_k=\mathbf{X}_\phi\alpha_k wk=Xϕαk
对一个新的数据 x n e w \mathbf{x}_{new} xnew,降维到 w k \mathbf{w}_k wk的维度
w k T ( ϕ ( x n e w ) − 1 N X ϕ 1 N × 1 ) = α k T X ϕ T ϕ ( x n e w ) − 1 N α k T X ϕ T X ϕ 1 N × 1 = α k T K ( ⋅ , x n e w ) − 1 N α k T K 1 N × 1wkT(ϕ(xnew)−N1Xϕ1N×1)=αkTXϕTϕ(xnew)−N1αkTXϕTXϕ1N×1=αkTK(⋅,xnew)−N1αkTK1N×1\begin{aligned} {\color{red} \mathbf{w}_{k}^{T}}\left( \phi \left( \mathbf{x}_{new} \right) -\frac{1}{N}\mathbf{X}_{\phi}1_{N\times 1} \right) &={\color{red} \alpha _{k}^{T}\mathbf{X}_{\phi}^{T}}\phi \left( \mathbf{x}_{new} \right) -\frac{1}{N}{\color{red} \alpha _{k}^{T}\mathbf{X}_{\phi}^{T}}\mathbf{X}_{\phi}1_{N\times 1} \\ &=\alpha _{k}^{T}\mathbf{K}\left( \cdot ,\mathbf{x}_{new} \right) -\frac{1}{N}\alpha _{k}^{T}\mathbf{K}1_{N\times 1} \end{aligned} import matplotlib.pyplot as plt import numpy as np from sklearn import datasets from sklearn.decomposition import PCA, KernelPCA from sklearn.datasets import make_circles from sklearn.model_selection import train_test_split def plot_2d(X, y, X_pca, X_kpca, X_my_kpca): fig, (orig_data_ax, pca_proj_ax, kernel_pca_proj_ax, kernel_pca_proj_ax2) = plt.subplots( ncols=4, figsize=(17, 4) ) orig_data_ax.scatter(X[:, 0], X[:, 1], c=y) orig_data_ax.set_ylabel("Feature #1") orig_data_ax.set_xlabel("Feature #0") orig_data_ax.set_title("Testing data") pca_proj_ax.scatter(X_pca[:, 0], X_pca[:, 1], c=y) pca_proj_ax.set_ylabel("Principal component #1") pca_proj_ax.set_xlabel("Principal component #0") pca_proj_ax.set_title("my Imple. PCA") kernel_pca_proj_ax.scatter(X_kpca[:, 0], X_kpca[:, 1], c=y) kernel_pca_proj_ax.set_ylabel("Principal component #1") kernel_pca_proj_ax.set_xlabel("Principal component #0") _ = kernel_pca_proj_ax.set_title("Sklearn KernelPCA") kernel_pca_proj_ax2.scatter(X_my_kpca[:, 0], X_my_kpca[:, 1], c=y) kernel_pca_proj_ax2.set_ylabel("Principal component #1") kernel_pca_proj_ax2.set_xlabel("Principal component #0") _ = kernel_pca_proj_ax2.set_title("my Imple. KernelPCA") plt.show() def my_pca(X_tr, X_te): n_components=2 # 去中心化 N = X_tr.shape[0] X_mean = np.mean(X_tr, axis=0) X_ = X_tr - X_mean # 构建协方差矩阵 XX = 1. / N * np.matmul(X_.T, X_) # 求特征向量 values, vectors = np.linalg.eig(XX) idxs = np.argsort(values) W = vectors[:,[idxs[-i] for i in range(1,n_components+1)]] X_r = np.matmul(X_te - X_mean, W) X_r[:,1] = - X_r[:,1] #确保与sklearn得到的结果一致 return X_r def my_kpca(X_tr, X_te, gamma=10): # exp(-||x_i-x_j||^2*gamma) N = X_tr.shape[0] K_tr0 = np.sum(X_tr**2, axis=1, keepdims=True) K_tr0 = np.exp(-(K_tr0 + K_tr0.T - 2 * np.matmul(X_tr, X_tr.T))*gamma) K_ = 1. / N * (K_tr0 - np.ones([N, N]) @ K_tr0 /N) # 求特征向量 values, vectors = np.linalg.eig(K_) idxs = np.argsort(values) alphas = vectors[:,[idxs[-i] for i in range(1,3)]] # N_tr x 2 K_new = np.sum(X_tr**2, axis=1, keepdims=True) + \ np.sum(X_te**2, axis=1, keepdims=True).T - \ 2 * X_tr @ X_te.T K_new = np.exp(-K_new * gamma) # N_tr x N_te X_r = K_new.T @ alphas - 1. / N * np.ones([1, N]) @ K_tr0 @ alphas X_r[:,0] = - X_r[:,0] #确保与sklearn得到的结果一致 X_r[:,1] = - X_r[:,1] #确保与sklearn得到的结果一致 return X_r def sklearn_kpca(X_tr, X_te, gamma=10): kernel_pca = KernelPCA( n_components=None, kernel="rbf", gamma=gamma, fit_inverse_transform=False ) X_test_kernel_pca = kernel_pca.fit(X_train).transform(X_test) return X_test_kernel_pca if __name__ == '__main__': X, y = make_circles(n_samples=1000, factor=0.3, noise=0.05, random_state=0) X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0) X_pca = my_pca(X_train, X_test) X_kpca = sklearn_kpca(X_train, X_test, gamma=10.0) X_my_kpca = my_kpca(X_train, X_test, gamma=10.0) plot_2d(X_test, y_test, X_pca, X_kpca, X_my_kpca)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
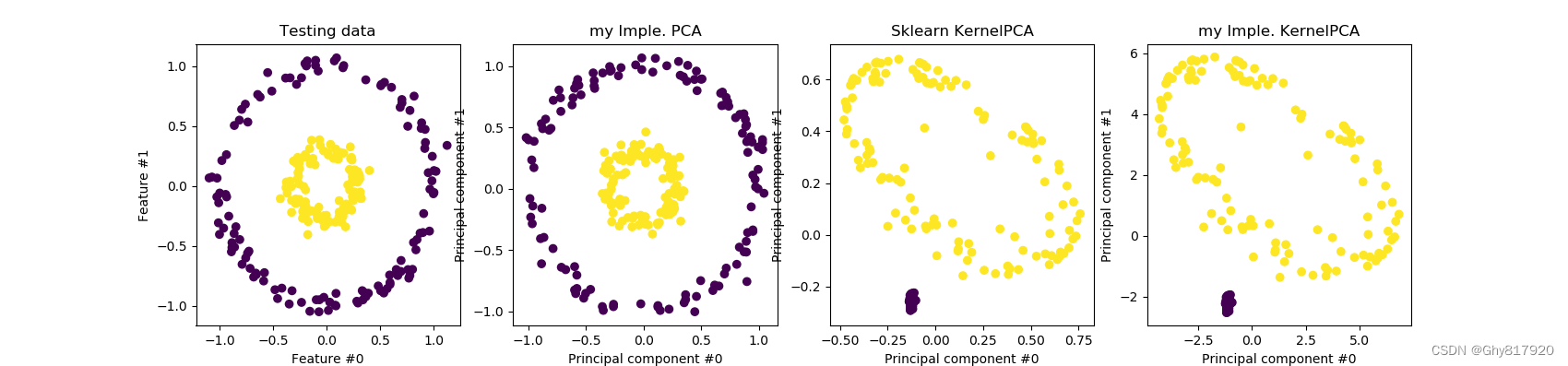
虽然与sklearn的KPCA在倍数上有点出入,但是不想深究了,就这样吧! -
相关阅读:
jmeter mysql 压测
8月25日计算机视觉理论学习笔记——R-FCN、YOLO
OA项目(一)之用户管理[登录+分页查询]
Linux 内核参数:extra_free_kbytes
【无标题】
双线性差值应用
Linux搭建C++开发环境
堪称经典,一个非常适合初学者的机器学习实战案例
[附源码]java毕业设计药品管理系统
提交代码触发Jenkins流水线更新
- 原文地址:https://blog.csdn.net/Ghy817920/article/details/126281319
