-
TensorFlow识别4种简单人眼神态(Vgg16)
活动地址:CSDN21天学习挑战赛
1.数据处理
数据集地址:传送门(提取码:86uu )
1.1.数据介绍
一共4种眼部神态,分别是闭眼,朝前,朝左,朝右看,数据介绍如下图:
Eye_dataset ├── close_look │ └── eye_closed (XXX).XXX(1,148 张图片,共4.15 MB) │ ├── forward_look │ └── forward_look (XXX).XXX(1,038 张图片,共7.37 MB) │ ├── left_look │ └── left_(XXX).XXX(1,049 张图片,共11.0 MB) │ ├── right_look └── └── right_(XXX).XXX(1,073 张图片,共9.69 MB)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
1.2.导入数据
查看tensorflow版本:
import tensorflow as tf tf.__version__- 1
- 2
版本:
'2.9.1'科普一下 Keras 和 PyTorch 的优劣:(详细可看:传送门)
在某些情况下,需要在特定的机器学习领域中寻找特定的模型。
例如,当进行目标检测比赛时,想要实现 DETR(Facebook 的 Data-Efficient transformer),结果发现大部分资源都是用 PyTorch 编写的,因此在这种情况下,使用 PyTorch 更加容易。
另外,PyTorch 的代码实现更长,因为它们涵盖了许多底层细节,这既是优点也是缺点。当你是初学者时先学习低层级的细节,然后再使用更高层级的 API(例如 Keras)非常有帮助。
但是,这同时也是一个缺点,因为你会发现自己迷失于许多细节和相当长的代码段中。因此,从本质上讲,如果你的工作期限很紧,最好选择 Keras 而不是 PyTorch。
设置GPU环境:
import tensorflow as tf gpus = tf.config.list_physical_devices("GPU") if gpus: tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用 tf.config.set_visible_devices([gpus[0]],"GPU") # 打印显卡信息,确认GPU可用 print(gpus)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
输出:
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]简单介绍我配置的环境:
我电脑支持的cuda(打开nvidia(桌面右键)->选择左下角的系统信息->组件)

nvcc -V查看下载的CUDA版本:
之后安装cuDNN,注册后到官网下载即可:

首先
cd C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4\extras\demo_suite,之后执行bandwidthTest.exe
执行
deviceQuery.exe
出现上图这2个PASS,即为cuDNN安装成功
导入并查看数据:
对于随机数种子的使用,可看:Tensorflow应用–tf.set_random_seed 的用法
import matplotlib.pyplot as plt # 支持中文 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 import os,PIL # 设置随机种子尽可能使结果可以重现 import numpy as np np.random.seed(1) # 设置随机种子尽可能使结果可以重现 import tensorflow as tf # tf.random.set_seed:设置全局随机种子 tf.random.set_seed(1) import pathlib data_dir = "E:\demo_study\jupyter\Jupyter_notebook\Recognition-of-eye-state-based-on-CNN\Eye_dataset" data_dir = pathlib.Path(data_dir) # */*的意思为获取文件夹下的所有文件及它们的子文件 # https://blog.csdn.net/Crystal_remember/article/details/116804009 image_count = len(list(data_dir.glob('*/*'))) print("图片总数为:",image_count)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
输出:
图片总数为: 43081.3.数据预处理
初始化参数:
batch_size = 8 img_height = 224 img_width = 224- 1
- 2
- 3
使用
image_dataset_from_directory方法将磁盘中的数据加载到tf.data.Dataset中函数原型:
tf.keras.preprocessing.image_dataset_from_directory( directory, labels="inferred", label_mode="int", class_names=None, color_mode="rgb", batch_size=32, image_size=(256, 256), shuffle=True, seed=None, validation_split=None, subset=None, interpolation="bilinear", follow_links=False, )- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
官网介绍:tf.keras.utils.image_dataset_from_directory
对于
validation_split项,官网解释:Optional float between 0 and 1, fraction of data to reserve for validation.对于
subset项,官网解释:Subset of the data to return. One of “training” or “validation”. Only used ifvalidation_splitis set.这部分代码:
train_ds = tf.keras.preprocessing.image_dataset_from_directory( data_dir, #WindowsPath('E:/demo_study/jupyter/Jupyter_notebook/Recognition-of-eye-state-based-on-CNN/Eye_dataset') validation_split=0.2, subset="training", seed=12, image_size=(img_height, img_width), batch_size=batch_size)- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出:
Found 4308 files belonging to 4 classes. Using 3447 files for training.- 1
- 2
同理配置验证集:
val_ds = tf.keras.preprocessing.image_dataset_from_directory( data_dir, validation_split=0.2, subset="validation", seed=12, image_size=(img_height, img_width), batch_size=batch_size)- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出:
Found 4308 files belonging to 4 classes. Using 861 files for validation.- 1
- 2
我们可以通过
class_names输出数据集的标签,标签将按字母顺序对应于目录名称class_names = train_ds.class_names print(class_names) class_names = val_ds.class_names print(class_names)- 1
- 2
- 3
- 4
输出:
['close_look', 'forward_look', 'left_look', 'right_look'] ['close_look', 'forward_look', 'left_look', 'right_look']- 1
- 2
1.4.可视化数据
plt.figure(figsize=(10, 5)) # 图形的宽为10高为5 plt.suptitle("数据展示") for images, labels in train_ds.take(1): for i in range(8): ax = plt.subplot(2, 4, i + 1) plt.imshow(images[i].numpy().astype("uint8")) plt.title(class_names[labels[i]]) plt.savefig('pic1.jpg', dpi=600) #指定分辨率保存 plt.axis("off")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
结果:

查看图像和标签各自的数据格式:for image_batch, labels_batch in train_ds: print(image_batch.shape) print(labels_batch.shape) break- 1
- 2
- 3
- 4
输出:
(8, 224, 224, 3) (8,)- 1
- 2
解释:
Image_batch是形状(8, 224, 224, 3)的张量,即一批形状是240x240x3的8张图片(最后一维指的是彩色通道RGB)Label_batch是形状(8,)的张量,即对应8张图片的标签
1.5.配置数据集
shuffle(): 打乱数据,详细可参考:数据集shuffle方法中buffer_size的理解prefetch():预取数据,加速运行,详细可参考:Better performance with the tf.data APIcache():将数据集缓存到内存当中,加速运行推荐一篇博客:【学习笔记】使用tf.data对预处理过程优化
prefetch()功能详细介绍:它使得训练步骤的预处理和模型执行部分重叠起来,原来是:
prefetch()之后是:
当然,不这么处理也可以的AUTOTUNE = tf.data.AUTOTUNE train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE) val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)- 1
- 2
- 3
- 4
2.网络设计
2.1.vgg16简单介绍
具体可看论文:Very Deep Convolutional Networks for Large-Scale Image Recognition
VGG-16 架构如下:

具体过程:(借鉴自:深度学习——VGG16模型详解)- 输入图像尺寸为224x224x3,经64个通道为3的3x3的卷积核,步长为1,padding=same填充,卷积两次,再经ReLU激活,输出的尺寸大小为224x224x64
- 经max pooling(最大化池化),滤波器为2x2,步长为2,图像尺寸减半,池化后的尺寸变为112x112x64
- 经128个3x3的卷积核,两次卷积,ReLU激活,尺寸变为112x112x128
- max pooling池化,尺寸变为56x56x128
- 经256个3x3的卷积核,三次卷积,ReLU激活,尺寸变为56x56x256
- max pooling池化,尺寸变为28x28x256
- 经512个3x3的卷积核,三次卷积,ReLU激活,尺寸变为28x28x512
- max pooling池化,尺寸变为14x14x512
- 经512个3x3的卷积核,三次卷积,ReLU,尺寸变为14x14x512
- max pooling池化,尺寸变为7x7x512
- 然后Flatten(),将数据拉平成向量,变成一维51277=25088。
- 再经过两层1x1x4096,一层1x1x1000的全连接层(共三层),经ReLU激活
- 最后通过softmax输出1000个预测结果
从上面的过程可以看出VGG网络结构还是挺简洁的,都是由小卷积核、小池化核、ReLU组合而成,简化图如下(也是本文所用的网络结构):

2.2.进行训练
调用官方vgg16网络模型
model = tf.keras.applications.VGG16() # 打印模型信息 model.summary()- 1
- 2
- 3
即下图的D模型:
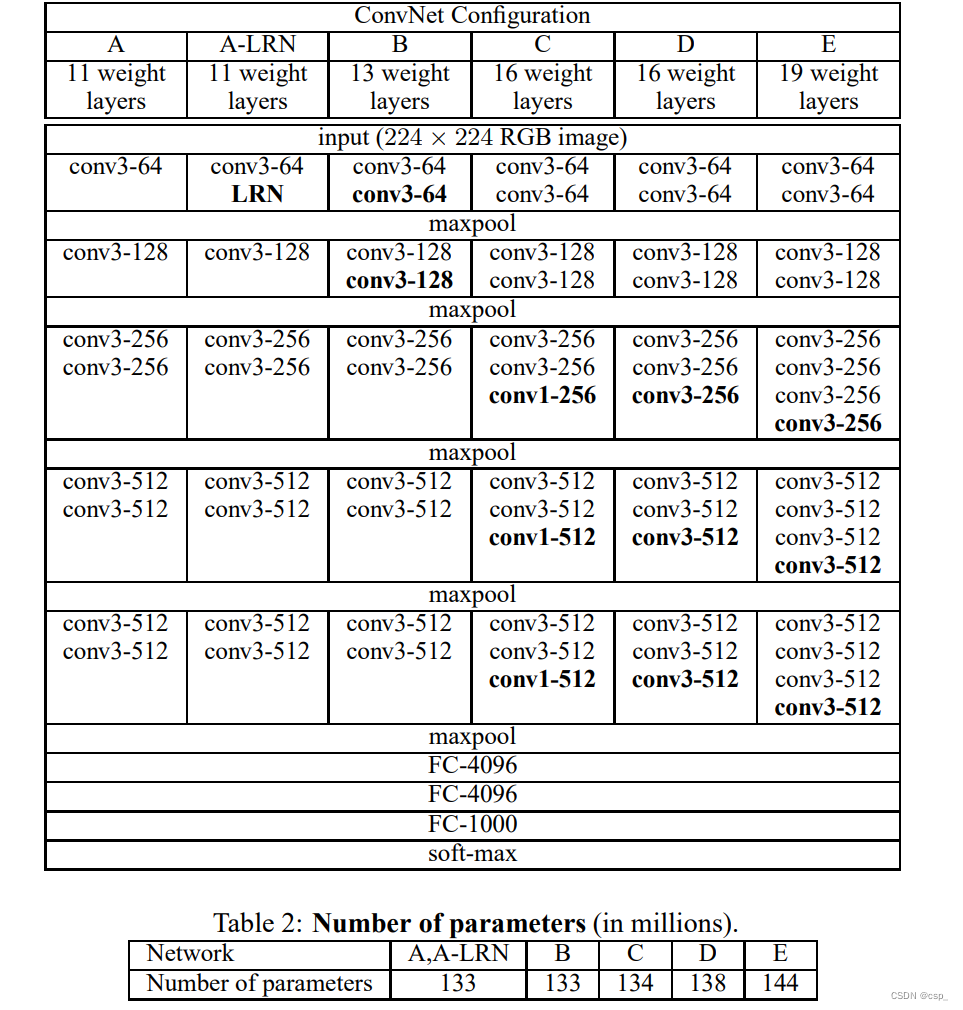
输出:
Model: "vgg16" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, 224, 224, 3)] 0 block1_conv1 (Conv2D) (None, 224, 224, 64) 1792 block1_conv2 (Conv2D) (None, 224, 224, 64) 36928 block1_pool (MaxPooling2D) (None, 112, 112, 64) 0 block2_conv1 (Conv2D) (None, 112, 112, 128) 73856 block2_conv2 (Conv2D) (None, 112, 112, 128) 147584 block2_pool (MaxPooling2D) (None, 56, 56, 128) 0 block3_conv1 (Conv2D) (None, 56, 56, 256) 295168 block3_conv2 (Conv2D) (None, 56, 56, 256) 590080 block3_conv3 (Conv2D) (None, 56, 56, 256) 590080 block3_pool (MaxPooling2D) (None, 28, 28, 256) 0 block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160 block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808 block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808 block4_pool (MaxPooling2D) (None, 14, 14, 512) 0 block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808 block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808 block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808 block5_pool (MaxPooling2D) (None, 7, 7, 512) 0 flatten (Flatten) (None, 25088) 0 fc1 (Dense) (None, 4096) 102764544 fc2 (Dense) (None, 4096) 16781312 predictions (Dense) (None, 1000) 4097000 ================================================================= Total params: 138,357,544 Trainable params: 138,357,544 Non-trainable params: 0 _________________________________________________________________- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
设置动态学习率
# 设置初始学习率 initial_learning_rate = 1e-4 lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay( initial_learning_rate, decay_steps=20, # 注意这里是指 steps,不是指 epochs decay_rate=0.96, # lr经过一次衰减就会变成 decay_rate*lr staircase=True) # 将指数衰减学习率送入优化器 optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
模型的编译
- 损失函数(loss):用于衡量模型在训练期间的准确率,这里用
sparse_categorical_crossentropy,原理与categorical_crossentropy(多类交叉熵损失 )一样,不过真实值采用的整数编码(例如第0个类用数字0表示,第3个类用数字3表示,官方可看:tf.keras.losses.SparseCategoricalCrossentropy) - 优化器(optimizer):决定模型如何根据其看到的数据和自身的损失函数进行更新,这里是
Adam(官方可看:tf.keras.optimizers.Adam) - 评价函数(metrics):用于监控训练和测试步骤,本次使用
accuracy,即被正确分类的图像的比率(官方可看:tf.keras.metrics.Accuracy)
model.compile(optimizer=optimizer, loss ='sparse_categorical_crossentropy', metrics =['accuracy'])- 1
- 2
- 3
训练模型
epochs = 10 history = model.fit( train_ds, validation_data=val_ds, epochs=epochs )- 1
- 2
- 3
- 4
- 5
- 6
这里 s t e p step step( i t e r a t i o n iteration iteration)的个数为: s t e p = ⌈ e x a m p l e N u m s ∗ e p o c h b a t c h s i z e ⌉ = ⌈ 3447 ∗ 1 8 ⌉ = 431 step=\lceil \dfrac{exampleNums∗epoch }{batch size}\rceil=\lceil \dfrac{3447∗1}{8}\rceil=431 step=⌈batchsizeexampleNums∗epoch⌉=⌈83447∗1⌉=431
输出:
Epoch 1/10 431/431 [==============================] - 266s 604ms/step - loss: 0.4236 - accuracy: 0.8567 - val_loss: 0.1470 - val_accuracy: 0.9501 Epoch 2/10 431/431 [==============================] - 254s 589ms/step - loss: 0.0895 - accuracy: 0.9698 - val_loss: 0.0959 - val_accuracy: 0.9721 Epoch 3/10 431/431 [==============================] - 254s 589ms/step - loss: 0.0406 - accuracy: 0.9881 - val_loss: 0.0923 - val_accuracy: 0.9733 Epoch 4/10 431/431 [==============================] - 253s 587ms/step - loss: 0.0215 - accuracy: 0.9942 - val_loss: 0.1004 - val_accuracy: 0.9733 Epoch 5/10 431/431 [==============================] - 253s 587ms/step - loss: 0.0161 - accuracy: 0.9951 - val_loss: 0.0996 - val_accuracy: 0.9791 Epoch 6/10 431/431 [==============================] - 253s 587ms/step - loss: 0.0133 - accuracy: 0.9962 - val_loss: 0.1016 - val_accuracy: 0.9779 Epoch 7/10 431/431 [==============================] - 253s 587ms/step - loss: 0.0116 - accuracy: 0.9965 - val_loss: 0.1027 - val_accuracy: 0.9779 Epoch 8/10 431/431 [==============================] - 253s 587ms/step - loss: 0.0109 - accuracy: 0.9971 - val_loss: 0.1033 - val_accuracy: 0.9779 Epoch 9/10 431/431 [==============================] - 253s 587ms/step - loss: 0.0106 - accuracy: 0.9971 - val_loss: 0.1036 - val_accuracy: 0.9779 Epoch 10/10 431/431 [==============================] - 253s 587ms/step - loss: 0.0104 - accuracy: 0.9971 - val_loss: 0.1036 - val_accuracy: 0.9779- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
3.模型评估
3.1.准确率评估
Accuracy与Loss图
acc = history.history['accuracy'] val_acc = history.history['val_accuracy'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(epochs) plt.figure(figsize=(12, 4)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label='Training Accuracy') plt.plot(epochs_range, val_acc, label='Validation Accuracy') plt.legend(loc='lower right') plt.title('Training and Validation Accuracy') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label='Training Loss') plt.plot(epochs_range, val_loss, label='Validation Loss') plt.legend(loc='upper right') plt.title('Training and Validation Loss') plt.savefig('pic2.jpg', dpi=600) #指定分辨率保存 plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23

3.2.绘制混淆矩阵
confusion_matrix()介绍可看:sklearn.metrics.confusion_matrixSeaborn:基于Matplotlib核心库进行了更高阶的 API 封装,其优势在配色更加舒服、以及图形元素的样式更加细腻定义一个绘制混淆矩阵图的函数
plot_cm:from sklearn.metrics import confusion_matrix import seaborn as sns import pandas as pd def plot_cm(labels, predictions): # 生成混淆矩阵 conf_numpy = confusion_matrix(labels, predictions) # 将矩阵转化为 DataFrame conf_df = pd.DataFrame(conf_numpy, index=class_names ,columns=class_names) plt.figure(figsize=(8,7)) sns.heatmap(conf_df, annot=True, fmt="d", cmap="BuPu") plt.title('混淆矩阵',fontsize=15) plt.ylabel('真实值',fontsize=14) plt.xlabel('预测值',fontsize=14) plt.savefig('pic3.jpg', dpi=600) #指定分辨率保存- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
取部分验证数据(
.take(1))生成混淆矩阵:val_pre = [] val_label = [] for images, labels in val_ds:#这里可以取部分验证数据(.take(1))生成混淆矩阵 for image, label in zip(images, labels): # 需要给图片增加一个维度 img_array = tf.expand_dims(image, 0) # 使用模型预测图片中的人物 prediction = model.predict(img_array) val_pre.append(class_names[np.argmax(prediction)]) val_label.append(class_names[label])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
输出(图像处理):
1/1 [==============================] - 2s 2s/step 1/1 [==============================] - 0s 23ms/step 1/1 [==============================] - 0s 21ms/step ...- 1
- 2
- 3
- 4
查看一下
conf_numpy变量:conf_numpy = confusion_matrix(val_label, val_pre) conf_numpy- 1
- 2
输出:
array([[223, 0, 0, 0], [ 0, 209, 2, 1], [ 0, 0, 209, 3], [ 1, 9, 3, 201]], dtype=int64)- 1
- 2
- 3
- 4
之后调用
plot_cm()进行绘图:plot_cm(val_label, val_pre)- 1

记得保存模型
# 保存模型 model.save('model/17_model.h5')- 1
- 2
3.3.进行预测
# model = tf.keras.models.load_model('model/17_model.h5') plt.figure(figsize=(20, 10)) # 图形的宽为10高为5 plt.suptitle("预测结果展示") num = -1 for images, labels in val_ds.take(2): for i in range(8): num = num + 1 plt.subplots_adjust(left=None, bottom=None, right=None, top=None , wspace=0.2, hspace=0.2) if num >= 15: break ax = plt.subplot(3, 5, num + 1) # 显示图片 plt.imshow(images[i].numpy().astype("uint8")) # 需要给图片增加一个维度 img_array = tf.expand_dims(images[i], 0) # 使用模型预测图片中的人物 predictions = model.predict(img_array) plt.title("True value: {}\npredictive value: {}".format(class_names[labels[i]],class_names[np.argmax(predictions)])) plt.savefig('pic4.jpg', dpi=600) #指定分辨率保存 plt.axis("off")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
结果(红色框内为预测错误的情况):

-
相关阅读:
三只松鼠、盐津铺子:战略相似,命运迥异
spring学习之@ModelAttribute注解的简介说明
maven
如何利用项目管理软件精准把控项目进度
函数指针知识点记录
vue2 与vue3的差异汇总
(四) Docker镜像
“拳头”重拳出击,Valorant监控来袭,网络环境改善?隐私安全?
软信天成:助力某制造企业建设产品主数据管理平台案例分享
鲍威尔暗示将继续加息以解决通胀问题 有何影响?
- 原文地址:https://blog.csdn.net/qq_45550375/article/details/126281427
