-
LogStash
序言
我觉得其实可以使用自定义Append的方式来收集日志.然后扔给JMS,在由后台进行消费入库.cuiyaonan2000@163.com
参考资料:
LogStash
Logstash 是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。
根据如上官网的介绍,我们至少知道LogStash采集数据分为3个步骤即(且LogStash更像是一个平台,她的3个步骤,每个都会有多种实现cuiyaonan2000@163.com):
- 输入 对应 Input : 必要插件,负责产生事件(Inputs generate events)
- 筛选 对应 Filter : 非必要插件,负责数据处理与转换(filters modify them)
- 输出 对应 Output : 必要插件,负责数据输出(outputs ship them elsewhere)
输入

对应的输入插件地址:Input plugins | Logstash Reference [8.3] | Elastic
常用的如下所示(我们种类主要的是使用Beats)
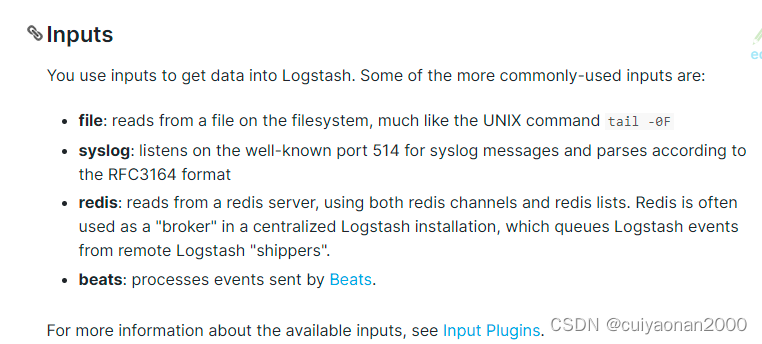
筛选
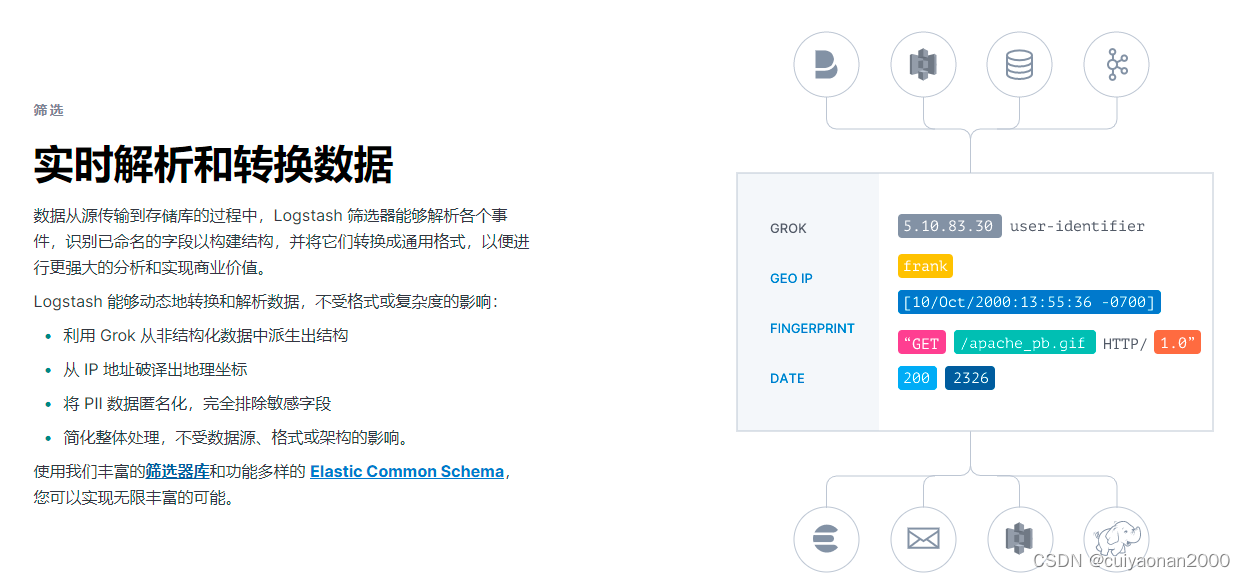
对应的筛选插件地址:Filter plugins | Logstash Reference [8.3] | Elastic
常用的插件地址:

输出
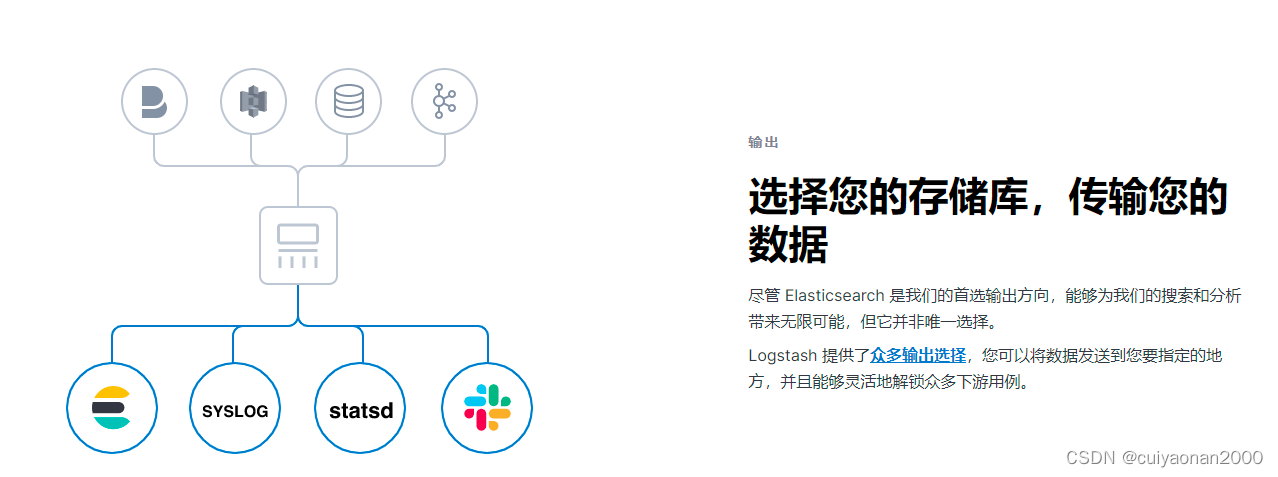
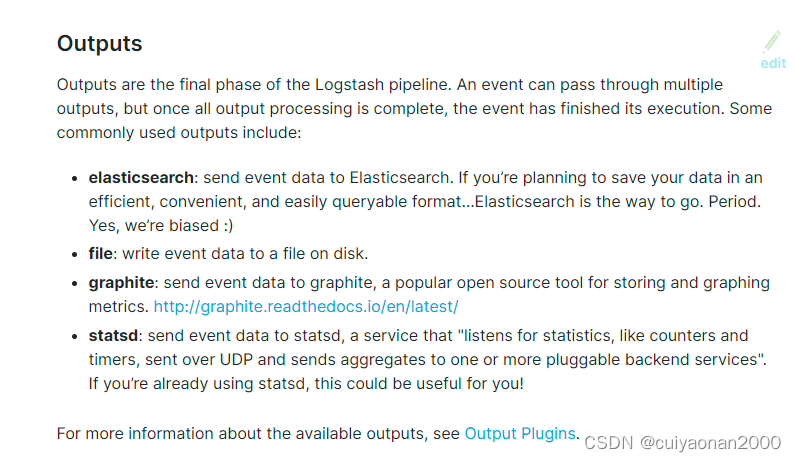
对应的输出插件地址:Output plugins | Logstash Reference [8.3] | Elastic
常用的如下所示:
工作流程

Logstash 旨在作为独立组件运行,以将数据加载到 Elasticsearch(以及其他目标系统)。 Logstash 是一个基于插件的组件,这意味着它可以高度扩展它支持的源/目标系统类型以及它可以进行的转换。Logstash 不是集群组件,无法感知其他 Logstash 实例(即不支持集群,无法进行横向扩展cuiyaonan2000@163.com)。 通过跨实例负载平衡数据,可以使用多个 Logstash 实例来满足高可用性和扩展需求。如果你想了解如何实现这个,你可以参阅文章 “Elastic:负载均衡在 Elastic Stack 中的应用”。
一些重要概念:
- Logstash 实例是一个正在运行的 Logstash 进程。建议在 Elasticsearch 的单独主机上运行 Logstash,以确保两个组件有足够的计算资源可用。
- 管道(pipeline)是配置为处理给定工作负载的插件集合。一个 Logstash 实例可以运行多个管道(彼此独立)
- 输入插件(input plugins)用于从给定的源系统中提取或接收数据。
- 过滤器插件(filter plugin)用于对传入事件应用转换和丰富。
- 输出插件(output plugin)用于将数据加载或发送到给定的目标系统
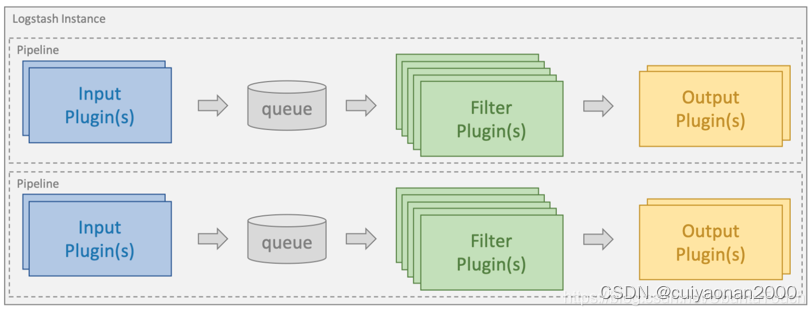
目前的主流工作模式
从上面我们可以看出来,Beats 的数据可以有如下的三种方式导入到 Elasticsearch 中:
- Beats ==> Elasticsearch : 直接跳过了Logstash 的数据转换和过滤的插件功能
- Beats ==> Logstash ==> Elasticsearch : 增加了Logstash的数据转换和过滤的插件功能
- Beats ==> Kafka ==> Logstash ==> Elasticsearch : 因为Logstash是单机的所以,需要JMS来缓冲下数据cuiyaonan2000@163.com
Logstash 通过运行一个或多个 Logstash 管道作为 Logstash 实例的一部分来处理 ETL 工作负载。
部署
下载地址:Past Releases of Elastic Stack Software | Elastic 注意选择命运中的版本,否则o(╥﹏╥)o
标准Input与标准OutPut测试
解压安装包后直接在bin目录下执行
./logstash -e 'input {stdin{}} output {stdout{}}'经过漫长等待,录入 cuiyaonan2000@163.com logstash马上就会返回
- {
- "host" => "localhost.localdomain",
- "@timestamp" => 2022-08-12T06:38:56.609Z,
- "message" => "cuiyaonan2000@163.com",
- "@version" => "1"
- }
正式启动
上面的只是用来测试,正式应用的时候,我们需要配置 input,filter,output.所以需要一个配置文件来记录,方便我们每次的执行.
配置文件格式为:
- input {
- heartbeat {
- interval => 10
- type => "heartbeat"
- }
- }
- output {
- stdout {
- codec => rubydebug
- }
- }
使用如下的命令执行
./bin/logstash -f heartbeat.conf #heartbeat.conf 就是配置文件修改配置文件不重启
- #默认检测配置文件的时间是3秒,可以进行设置
- ./bin/logstash -f heartbeat.conf #heartbeat.conf 就是配置文件 --config.reload.automatic --config.reload.interval
-
相关阅读:
Java面向对象项目三:开发团队调度软件
事件循环机制-Event-Loop
解决Oracle SQL语句性能问题——SQL语句改写(分析函数、with as、union及or)
25、业务层标准开发(也就是service)
VUE 文件导出下载
SpringBoot和MybatisPlus的多数据源配置及两者的区别
【C++】一文简练总结【多态】及其底层原理&具体应用(21)
python-切换镜像源和使用PyCharm进行第三方开源包安装
Go语言的IO库那么多纠结该如何选择
第十七篇:稳定性之告警体系
- 原文地址:https://blog.csdn.net/cuiyaonan2000/article/details/126253846