-
MySQL事务的保证机制
目录
1、数据库事务概述
1.1 基本概念
事务:一组逻辑操作单元,使数据从一种状态变换到另一种状态。
事务处理的原则:保证所有事务都作为一个工作单元来执行,即使出现了故障,都不能改变这种执行方式。当在一个事务中执行多个操作时,要么所有的事务都被提交(commit),那么这些修改就永久地保存下来;要么数据库管理系统将放弃所作的所有修改,整个事务回滚(rollback)到最初状态。
1.2 事务的ACID特性
原子性(atomicity):
原子性是指事务是一个不可分割的工作单位,要么全部提交,要么全部失败回滚。
一致性(consistency):
一致性是指事务执行前后,数据从一个合法性状态变换到另外一个合法性状态。这种状态是语义上的而不是语法上的,跟具体的业务有关。
隔离型(isolation):
事务的隔离性是指一个事务的执行不能被其他事务干扰,即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
持久性(durability):
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来的其他操作和数据库故障不应该对其有任何影响。
持久性是通过事务日志来保证的。日志包括了重做日志和回滚日志。当我们通过事务对数据进行修改的时候,首先会将数据库的变化信息记录到重做日志中,然后再对数据库中对应的行进行修改。这样做的好处是,即使数据库系统崩溃,数据库重启后也能找到没有更新到数据库系统中的重做日志,重新执行,从而使事务具有持久性。
1.3 事务的状态
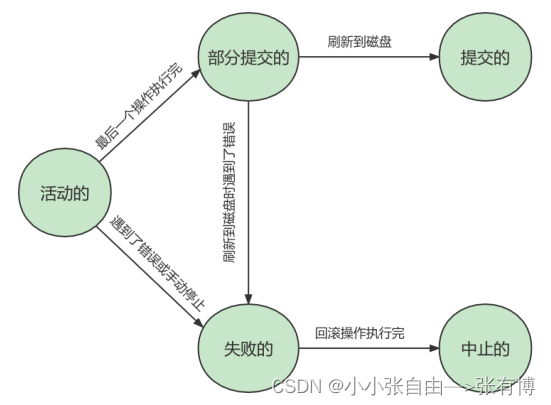
1.4 事务在并发问题下出现的问题以及解决方案
数据库脏读、不可重复读、幻读以及对应的隔离级别_小小张自由—>张有博的博客-CSDN博客
2、四大特性之间的关系
原子性是有undoLog来保证
持久性是由redolog来保证
隔离性是有锁机制和MVCC机制保证
一致性是有以上三个机制保证的。
2.1 持久性:redolog
InnoDB存储引擎是以页为单位来管理存储空间的,在真正访问页面之前,需要把数据在磁盘上的页缓存到内存中的Buffer Pool之后才可以访问。
所有的变更都必须先更新缓冲池中的数据,然后缓冲池中的脏页(脏页:修改后的数据在缓存池中还没有被刷新到磁盘当中)会以一定的频率被刷入磁盘(checkPoint机制),通过缓冲池来优化CPU和磁盘之间的鸿沟,这样就阔以保证整体的性能不会下降的太快。
InnoDB引擎的事物采用了WAL(Write-Ahead Logging),这种技术的思想就是先写日志,再写磁盘,只有日志写入成功,才算是事务提交成功,这里的日志就是redo log。当发生宕机且数据未刷新到磁盘的时候,可以通过redo log来恢复,保证ACID中的D,这就是redo log的作用
2.1.1 redolog的特点
- redo日志是顺序写入磁盘的
- 事务执行过程中,redo log不断记录
- redo日志降低了刷盘频率
- redo日志占用的空间非常小
redolog 称为
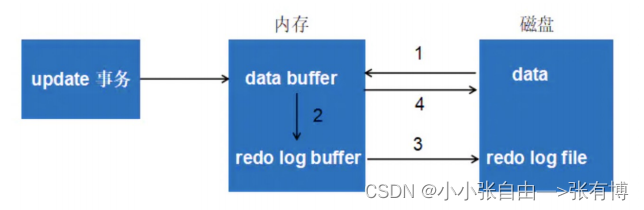
重做日志,提供再写入操作,恢复提交事务修改的页操作,用来保证事务的持久性。2.1.2 redo log整体的使用流程
第1步:先将原始数据从磁盘中读入内存中来,
第2步:修改数据的内存值
第2步:生成一条重做日志并写入redo log buffer,记录的是数据被修改后的值
第3步:当事务commit时,将redo log buffer中的内容刷新到 redo log file,对 redo log file采用追加写的方式
第4步:定期将内存中修改的数据刷新到磁盘中
2.1.3 redo log的刷盘策略
InnoDB给出
innodb_flush_log_at_trx_commit参数,该参数控制 commit提交事务时,如何将 redo log buffer 中的日志刷新到 redo log file 中。它支持三种策略:设置为0:表示每次事务提交时不进行刷盘操作。(系统默认master thread每隔1s进行一次重做日志的同步)
设置为1:表示每次事务提交时都将进行同步,刷盘操作(默认值)
设置为2:表示每次事务提交时都只把 redo log buffer 内容写入 page cache,不进行同步。由os自己决定什么时候同步到磁盘文件。
对应的流程图如下
innodb_flush_log_at_trx_commit=0
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OUYuvMFy-1653189800019)(image-20220521190309159.png)]](https://1000bd.com/contentImg/2022/08/12/061815987.png)
innodb_flush_log_at_trx_commit=1
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GsTSQlql-1653189800019)(image-20220521185550761.png)]](https://1000bd.com/contentImg/2022/08/12/061816096.png)
innodb_flush_log_at_trx_commit=2
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oeu3EQLw-1653189800019)(image-20220521190258014.png)]](https://1000bd.com/contentImg/2022/08/12/061816221.png)
2.2 原子性:undolog
被称为回滚日志
redo log是事务持久性的保证,undo log是事务原子性的保证。在事务中更新数据的前置操作其实是要先写入一个 undo log 。
2.2.1 如何理解Undo日志
事务需要保证
原子性,也就是事务中的操作要么全部完成,要么什么也不做。但有时候事务执行到一半会出现一些情况,比如:- 情况一:事务执行过程中可能遇到各种错误,比如
服务器本身的错误,操作系统错误,甚至是突然断电导致的错误。
- 情况二:程序员可以在事务执行过程中手动输入
ROLLBACK语句结束当前事务的执行。
以上情况出现,我们需要把数据改回原先的样子,这个过程称之为
回滚,这样就可以造成一个假象:这个事务看起来什么都没做,所以符合原子性要求。2.2.2 Undo日志的作用
- 作用1:回滚数据
- 作用2:MVCC(undo log链)
2.2.3 undo的存储结构
InnoDB对undo log的管理采用段的方式,也就是
回滚段(rollback segment)。自我理解就是就是回滚点。当时事务报错了之后需要回滚到的初始地方回滚段与事务之间的关系
1.每个事务只会使用一个回滚段,一个回滚段在同一时刻可能会服务于多个事务。
2.当一个事务开始的时候,会制定一个回滚段,在事务进行的过程中,当数据被修改时,原始的数据会被复制到回滚段。
3.回滚段存在于undo表空间中,在数据库中可以存在多个undo表空间,但同一时刻只能使用一个undo表空间。
4. 当事务提交时,InnoDB存储引擎会做以下两件事情:
将undo log放入列表中,以供之后的purge操作
判断undo log所在的页是否可以重用,若可以分配给下个事务使用回滚段中的数据分类
未提交的回滚数据(uncommitted undo information)
已经提交但未过期的回滚数据(committed undo information)
事务已经提交并过期的数据(expired undo information)
undo的类型
在InnoDB存储引擎中,undo log分为:
- insert undo log
- update undo log
2.2.4 undo log的生命周期
假设有2个数值,分别为A=1和B=2,然后将A修改为3,B修改为4
- 1.start transaction;
- 2.记录A=1到undo1og;
- 3.update A=3;
- 4.记录A=3到redo1og;
- 5.记录B=2到undo1og;
- 6.update B 4;
- 7.记录B=4到redo1og;
- 8.将redo1og刷新到磁盘
- 9.commit
在1-8步骤的任意一步系统宕机,事务未提交,该事务就不会对磁盘上的数据做任何影响。
如果在8-9之间宕机,恢复之后可以选择回滚,也可以选择继续完成事务提交,因为此时redo logi已经持久化。
若在9之后系统宕机,内存映射中变更的数据还来不及刷回磁盘,那么系统恢复之后,可以根据redo log:把数据刷回磁盘。
redo log与 undo log工作流程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6q8vCYne-1653189800019)(image-20220522111009244.png)]](https://1000bd.com/contentImg/2022/08/12/061816414.png)
在更新Buffer Pool中的数据之前,我们需要先将该数据事务开始之前的状态写入Undo Logl中。假设更新到一半出错了,我们就可以通过Undo Log来回滚到事务开始前。
2.2.5 undo log的细节生成过程
对于InnoDB引擎来说,每个行记录除了记录本身的数据之外,还有几个隐藏的列:
DB_ROW_ID:如果没有为表显式的定义主键,并且表中也没有定义唯一索引,那么InnoDB会自动为表添加一个row_id的隐藏列作为主键。
DB_TRX_ID:每个事务都会分配一个事务ID,当对某条记录发生变更时,就会将这个事务的事务ID写入tx_id中。
DB_ROLL_PTR:回滚指针,本质上就是指DB_ROLL_PTR向undo log的指针。
我们进行回滚使用的就是DB_ROLL_PTR,回滚指针
2.2.6 undo log是如何回滚的
以上面的例子来说,假设执行rollback,那么对应的流程应该是这样:通过undo no=3的日志把id=2的数据删除
通过undo no=2的日志把id=1的数据的deletemark还原成0
通过undo no=1的日志把id=1的数据的name还原成Tom
通过undo no=0的日志把id=1的数据删除
2.2.6 undo log的删除
针对于insert undo log
因为insert操作的记录,只对事务本身可见,对其他事务不可见。故该undo log可以在事务提交后直接删除,不需要进行purge操作。
针对于update undo log
该undo log可能需要提供MVCC机制,因此不能在事务提交时就进行删除。提交时放入undo log链表,等待purge线程进行最后的删除。
purge线程两个主要作用是:清理undo页和清除page里面带有Delete_Bit标识的数据行。
在InnoDB中,事务中的Delete操作实际上并不是真正的删除掉数据行,而是一种Delete Mark操作,在记录上标识Delete._Bit,而不删除记录。是一种"假删除",只是做了个标记r真正的删除工作需要后台purge线程去完成。
3、小结
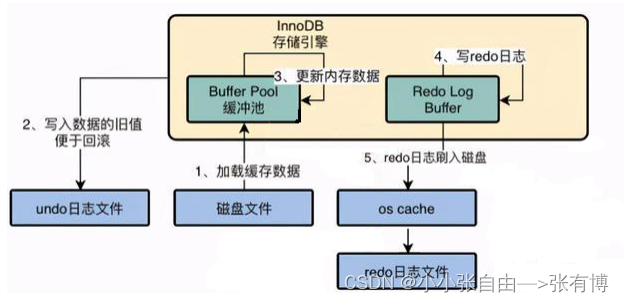
看图:很好的介绍了redo log与undo log之间的关系。
undo log是逻辑日志,对事务回滚时,只是将数据库逻辑地恢复到原来的样子。
redo log是物理日志,记录的是数据页的物理变化,undo log不是redo log的逆过程。
下篇文章介绍隔离性的保证方式:锁机制和MVCC机制
如果本篇博客对您有一定的帮助,大家记得留言+点赞+收藏哦
-
相关阅读:
Android 图片加载框架Glide源码详解
QFusion数据库管理平台数据库集群创建及管理
【Web安全】注入攻击
<input> 实现输入框只能输入数字(个人认为最好的)
【ACMMM】Semi-supervised Deep Multi-view Stereo,FaceChain团队联合出品
【Hack The Box】linux练习-- Valentine
Jmeter系列-线程组的执行顺序(10)
活动预告丨EMNLP 2022半监督和强化对话系统研讨会12月7日线上召开!
【selenium自动化过程中的api抓包】browsermobproxy的安装和配置
菜单栏程序坞APP的实现2(全面优化)
- 原文地址:https://blog.csdn.net/promsing/article/details/126207813