-
缓存技术使用
一. http请求缓存技术
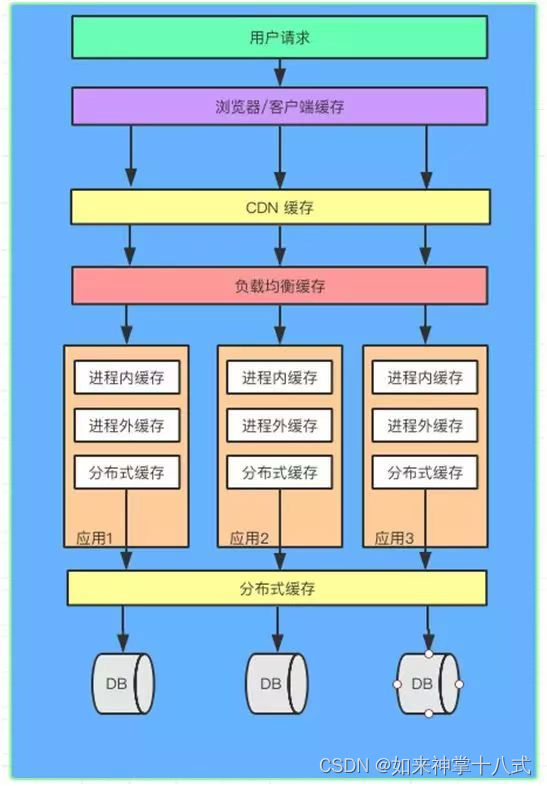
从用户请求数据到数据返回,数据经过了浏览器,CDN,代理服务器,应用服务器,以及数据库各个环节。每个环节都可以运用缓存技术。
- 从浏览器/客户端开始请求数据,通过 HTTP 配合 CDN 获取数据的变更情况,到达代理服务器(Nginx)可以通过反向代理获取静态资源。
- 再往下来到应用服务器可以通过进程内(堆内)缓存,分布式缓存等递进的方式获取数据。如果以上所有缓存都没有命中数据,才会回源到数据库。
缓存的请求顺序是:用户请求 → HTTP 缓存 → CDN 缓存 → 代理服务器缓存 → 进程内缓存 → 分布式缓存 → 数据库。
看来在技术的架构每个环节都可以加入缓存。

二. 多级缓存设计方案为啥需要做多级缓存
1,某些数据不希望任何一条用户的请求请求到数据库,sql查询速度及性能都不好接受。
2,某些业务逻辑计算量巨大,api接口耗时太久会拖慢整个网站,用户体验很差对于以上两点,很容易想到方案就是预热数据,即通过定时任务的执行提前并且按照一定频率把数据同步或计算到缓存中。我们自定义了注解*@PreHeat*来解决这个问题
- @Target({ElementType.METHOD})
- @Retention(RetentionPolicy.RUNTIME)
- public @interface PreHeat {
- }
这个注解很关键,两级缓存架构都要依靠他来实现。
3,某些缓存到redis中的数据量很大,每次调用它的时候仍然需要序列化过程,同样会在一定程度上拖慢api
这个时候就需要本地缓存了,它不需要序列化的过程,所以速度又可以提升了。
关于本地缓存的选型,如下图所见

Caffeine作为一个基于java8的高性能缓存库,比前几代的Guava,Ehcahe性能提升了很多,无论是从read还是write上,我们选用缓存的第一当然是性能提升了。
4,系统可用性提升,如果redis宕机的情况下,还有本地缓存可以支撑一段时间。
二 多级缓存架构
系统的缓存架构如下:

流程描述:
需要缓存的数据都抽象成相应的service api(或者dao层api),方法上添加@PreHeat注解(注解上可以添加各种参数来控制各种细粒度化访问),访问这种接口时,会在springaop的切面Aspect到本地缓存中拿值,如果本地缓存中没有值,就去读redis的数据,将redis的数据set到本地缓存同时返回数据。
定时任务执行器每5分钟执行一次,扫描指定包下的所有含有@PreHeat注解的方法,将mysql数据(或者是耗时较久的函数计算)set到redis。需要注意的是定时任务执行器只会在一台机器的一个项目上(或者单独的项目)上执行,所以不能直接把mysql的数据直接刷到本地缓存。其它服务器部署的项目拿不到。而通过write到分布式的redis,而API自己触发本地缓存的write,可以保证每台机器的每个项目都刷新到。
总结及问题
经过以上缓存架构的改造,线上影响的接口api相应平均耗时下架10 - 100 ms不等,P99等指标页好看了许多。但是目前还存在明显问题:
数据的刷新有对应的延迟。从定时任务刷新数据到redis,再到api被请求刷新到本地缓存,数据库被更改的数据到用户请求到,有一定的延迟。
后面需要考虑增加缓存刷新机制,做到缓存实时刷新。另外其他设计,待完善。。。。。。。。
-
相关阅读:
Jmeter redis连接测试
处理火狐浏览器地址栏点击出现 百度/58同城/爱淘宝 链接
Python使用总结之Python-docx操作Word文件(添加、编辑和删除文档内容,在文档中插入图片)
Android学习笔记 9. PopupWindow
acwing算法提高之图论--最小生成树的扩展应用
vscode插件开发(二)插件结构
Hadoop源码阅读(三):HDFS上传
【代码源】每日一题 国家铁路
数据存储全方案----详解持久化技术
前端综合面试题【看这一篇就够了】
- 原文地址:https://blog.csdn.net/t194978/article/details/126201095