后缀数组
后缀数组的算法可以求出所有后缀的排名,并求出 heighti=lcp(sa[i],sa[i−1]))
利用倍增算法,每一轮求出每个子串 [i,i+2k)
即使用二元组 (sai,sai+2k)
void get_sa(){
for(int i=1;i<=n;i++)c[x[i]=a[i]]++;
for(int i=1;i<=(m='z');i++)c[i]+=c[i-1];
for(int i=n;i>=1;i--)sa[c[x[i]]--]=i;
for(int k=1;k<=n;k<<=1){
int num=0;for(int i=n-k+1;i<=n;i++)y[++num]=i;
for(int i=1;i<=n;i++)if(sa[i]>k)y[++num]=sa[i]-k;
for(int i=1;i<=m;i++)c[i]=0;
for(int i=1;i<=n;i++)c[x[i]]++;
for(int i=1;i<=m;i++)c[i]+=c[i-1];
for(int i=n;i>=1;i--)sa[c[x[y[i]]]--]=y[i];
memcpy(y,x,sizeof x);x[sa[1]]=num=1;
for(int i=2;i<=n;i++)x[sa[i]]=(y[sa[i]]==y[sa[i-1]]&&y[sa[i]+k]==y[sa[i-1]+k]?num:++num);
if((m=num)==n)break;
}
}
其中
for(int i=n-k+1;i<=n;i++)y[++num]=i;
for(int i=1;i<=n;i++)if(sa[i]>k)y[++num]=sa[i]-k;
这两行的意思是这样的,y
由于从 n−k+i
后面的 x
直接放一些我也不会证的结论:
利用最后一个结论,可以快速 O(n)
void get_height(){
for(int i=1;i<=n;i++)rk[sa[i]]=i;
for(int i=1,k=0;i<=n;i++){
if(rk[i]==1)continue;
if(k)k--;int j=sa[rk[i]-1];
while(i+k<=n&&j+k<=n&&a[i+k]==a[j+k])k++;
height[rk[i]]=k;
}
}
注意如果不使用 sa
- 树上后缀排序
考虑问题转移到树上其实是多了一个维度,即第一个关键字,第二关键字,以及它们都相同时会出现第三关键字——编号
那么对三元组 (sai,safai,j,i)
代码中的 rk,y,sa
此时做两边双关键字的基排即可
void dosort(int sa[],int x[],int y[],int m){
for(int i=1;i<=m;i++)c[i]=0;
for(int i=1;i<=n;i++)c[x[i]]++;
for(int i=1;i<=m;i++)c[i]+=c[i-1];
for(int i=n;i>=1;i--)sa[c[x[y[i]]]--]=y[i];
}
void get_sa(){
for(int i=1;i<=n;i++)x[i]=i;
dosort(sa,a,x,'z');
rk[sa[1]]=rkk[sa[1]]=num=1;
for(int i=2;i<=n;i++){
rk[sa[i]]=(a[sa[i-1]]==a[sa[i]]?num:++num);
rkk[sa[i]]=i;
}
for(int k=1,j=0;k<=n;k<<=1,j++){
for(int i=1;i<=n;i++)y[i]=rkk[f[i][j]];
dosort(x,y,sa,n);
dosort(sa,rk,x,n);
swap(rk,x);
rk[sa[1]]=rkk[sa[1]]=num=1;
for(int i=2;i<=n;i++){
rk[sa[i]]=(x[sa[i]]==x[sa[i-1]]&&x[f[sa[i]][j]]==x[f[sa[i-1]][j]]?num:++num);
rkk[sa[i]]=i;
}
}
}
后缀自动机
后缀自动机上存储着一个串的所有后缀,由于所有子串都能通过添加字符变为后缀,所以所有子串也都存储在后缀自动机中
首先平时构建出的结构由两部分组成,一个是 DAG
一个是 parent
后缀自动机之所以能压缩状态,是因为把所有 endpos
定义 endpos(S)
a:1,3,4
ab,b:2
aba,ba:3
abaa,baa,aa:4
对于每一类 endpos
SAM
有这样的性质:所有节点儿子的集合没有交集
对于一个 endpos
而对于每个集合长度 len
有这样的性质:minlen(p)=maxlen(fa(p))+1
而 SAM
有这样的性质:endpos(son[p][w])⊆endpos(fa[p])
利用以上性质可以证明 SAM
对于自动机的构建,目前来看似乎需要改动板子的情形不多,大部分情况直接理解性默写即可
void insert(int w){
int p=last,np=last=++tot;
siz[tot]=1;len[np]=len[p]+1;
for(;p&&!son[p][w];p=fa[p])son[p][w]=np;
if(!p)fa[np]=1;
else{
int q=son[p][w];
if(len[q]==len[p]+1)fa[np]=q;
else{
int nq=++tot;
fa[nq]=fa[q];for(int i=0;i<26;i++)son[nq][i]=son[q][i];
fa[q]=fa[np]=nq;len[nq]=len[p]+1;
for(;p&&son[p][w]==q;p=fa[p])son[p][w]=nq;
}
}
return ;
}
首先 np
顺着 endpos
如果没有,直接认 1
至于另外的情况如果不满足长度条件会产生的影响,目前还没有看懂,总之应该把 q
update:
经过一番手模以后有了一些新的理解
对于分裂那块,举一个简单的例子,比如插入 abb
前两个字母的时候长这样

再插入一个 b
因此需要把 3
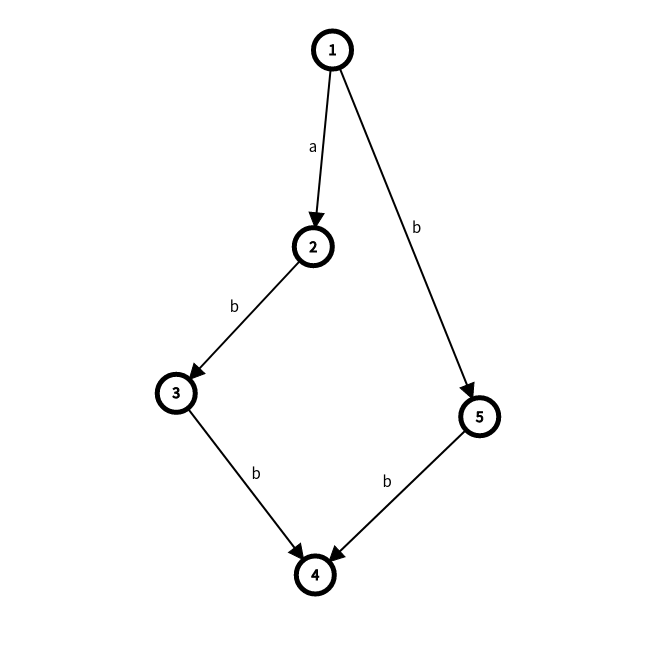
其中 5
一个小 trick
- 线段树合并
如果想要得知某个节点的 endpos
注意要写成不销毁节点的版本,即对于每一个两个树都有的节点都要新建一个节点
这样一来就可以对某一个子串的信息进行利用了,比如要知道 [l,r]
那么假设当前匹配长度为 len
- 广义 SAM
SAM
相当于是每次插入字符时插入到上一个字符的后面
假如直接每个串分别构建会使得不同串的相同子串分叉成两个儿子从而丢失信息,用两种解决方法:
每次加入时特判是否已经存在当前儿子:
if(son[last][w]){
int q=son[last][w];
if(len[q]==len[last]+1)last=q;
else{
int nq=++tot;fa[nq]=fa[q];memcpy(son[nq],son[q],sizeof son[q]);
fa[q]=nq;len[nq]=len[last]+1;
for(;son[last][w]==q;last=fa[last])son[last][w]=nq;
last=nq;
}
return ;
}
也可以对所有串建出 trie
void bfs() {
queue<int> q;q.push(0);pos[0] = 1;
while (!q.empty()) {
int p = q.front();q.pop();
for (int i = 0; i < 26; i++)
if (trie[p][i]) {
pos[trie[p][i]] = insert(pos[p], i);
q.push(trie[p][i]);
}
}
}
广义 SAM
后缀树
后缀树是把所有后缀建出 trie
定义等价类为从根出发沿着 trie
那么有性质 startpos

后缀树的大小不超过 2n
有结论后缀树是反串的 parent
那么树上的边代表的字符串可以由构建 SAM
- 后缀数组与后缀树:后缀树上按照字典序遍历儿子得到的 dfs
dfs 序即为后缀数组,子树结构对应后缀数组的区间结构 - 两个后缀的 lcp
lcp 为两个树上节点的 lcalca ,而这种 lcalca 的合并性与后缀数组 heightheight 数组的合并对应
经典问题
本质不同的子串数
自动机结构:本质不同的子串即为从根出发沿 DAG
树形结构:为每个节点可以表示出的子串范围,即 mxlen−mnlen+1
后缀树:后缀树上从根到每一个点(包括被压缩的)的路径都是本质不同的,那么统计所有树边的长度和即可
后缀数组:答案为总个数减去重复子串个数,而每一对重复子串都可以唯一地表示成两个后缀的 lcp
P2408 不同子串个数,P4070 [SDOI2016]生成魔咒
子串定位:将给定子串定位在 SAM
SAM 上对应的节点
SAM
后缀树:类似地从这个后缀的关键点往上倍增
子串出现次数
树形结构:为子串对应节点的 endpos
后缀数组:在对应的 sa
后缀树:查询子串对应子树的关键点大小即可
最长公共子串
其核心是快速对 T
SAM
后缀数组:类似地转化成求每一个后缀的 LCP
后缀树:接在一起构建后缀树,答案即为最深的子树内同时有两种关键点的点
对于多个串的情况,后缀数组与后缀树都类似,SAM
最长不相交子串
SAM:维护出每个 endpos 的 mnlen 和 mxlen 即可
后缀数组:首先二分答案,然后对分成的块中统计位置的最大最小值
自动机结构:一个子串相当于从起点出发的一条路径,考虑 dp 出走当前节点的所有出边将会产生有多少个子串,把点权设为 1 或出现次数跑反图的拓扑 dp 即可
后缀树:把一个节点的所有儿子排序可以按照字典序遍历到所有子串,统计每种点权意义下的子树大小即可
考虑还是采用经典的分段法,那么在每一段中统计最大、次大、最小、次小值即可
如果按照正序求解是一个分裂问题,那么采用类似并查集的时光倒流套路倒序求解,变成了每次合并区间就很好维护了
代码
#includesize();i++){
int x=ex[p][i];
int xx=find(x-1);
int yy=find(x);
sum+=calc_val(siz[xx]+siz[yy])-calc_val(siz[xx])-calc_val(siz[yy]);
fa[xx]=yy;
siz[yy]+=siz[xx];
int d[6]={-inf,mx[xx],cmx[xx],mx[yy],cmx[yy]};
sort(d+1,d+5);
// for(int i=1;i<=4;i++)cout<
// cout<
mx[yy]=d[4];
cmx[yy]=d[3];
int b[6]={-inf,mn[xx],cmn[xx],mn[yy],cmn[yy]};
sort(b+1,b+5);
// for(int i=1;i<=4;i++)cout<
// cout<
mn[yy]=b[1];
cmn[yy]=b[2];
val=max(val,max(mx[yy]*cmx[yy],mn[yy]*cmn[yy]));
}
ans[p]=make_pair(sum,val);
if(val==-inf)ans[p].second=0;
return ;
}
signed main(){
n=read();
scanf("%s",s+1);
for(int i=1;i<=n;i++)a[i]=read();
m=122;
get_sa();
get_height();
for(int i=2;i<=n;i++)ex[height[i]].push_back(i);
for(int i=1;i<=n;i++){
fa[i]=i;
siz[i]=1;
mx[i]=mn[i]=a[sa[i]];
cmx[i]=-inf;
cmn[i]=inf;
}
for(int i=n-1;i>=0;i--)calc(i);
for(int i=0;iprintf ("%lld %lld\n",ans[i].first,ans[i].second);
return 0;
}
后缀数组:首先转化一下先算出自己内部的 lcp 最后减去,就不用关心从哪个串来的了。那么就是要算出所有区间的 height 的 min 之和,可以用单调栈方便解决
后缀树:这题的公式给的非常奇怪,考虑其实际意义,如果放到后缀树上,那么代表着两个后缀节点的路径长度,统计这个东西就好了,即为 w∗sizu(n−sizu)
代码
#include
m=122;
get_sa();
get_height();
sta[0]=1;
for(int i=2;i<=n;i++){
// cout<
while(tp&&height[sta[tp]]>=height[i])r[sta[tp]]=i-1,tp--;
sta[++tp]=i;
l[i]=sta[tp-1]+1;
}
while(tp)r[sta[tp]]=n,tp--;
for(int i=2;i<=n;i++){
// cout<
ans-=2ll*height[i]*(r[i]-i+1)*(i-l[i]+1);
}
cout<return 0;
}
仍然是匹配的模式,考虑循环同构的处理方法
相当于长度扩展一倍,每次要求长度小于 len
由于本质不同的只算一次,那么后缀自动机上的每个节点打时间戳去重即可
代码
#include
for(int i=1;i<=tot;i++)to[len[i]]++;
for(int i=1;i<=tot;i++)to[i]+=to[i-1];
for(int i=1;i<=tot;i++)id[to[len[i]]--]=i;
for(int i=tot;i>=1;i--)siz[fa[id[i]]]+=siz[id[i]];
// for(int i=1;i<=tot;i++)cout<
cin>>m;
for(int t=1;t<=m;t++){
scanf("%s",a+1);n=strlen(a+1);ans=0;
for(int i=1,p=1,nowlen=0;i2 ;i++){
int w=a[(i-1)%n+1]-'a';
if(!son[p][w]){for(;p&&!son[p][w];p=fa[p]);nowlen=len[p];}
if(!p){p=1;continue;}
p=son[p][w];nowlen++;
while(nowlen>n){
nowlen--;
if(nowlen<=len[fa[p]])p=fa[p];
}
if(nowlen>=n&&vis[p]!=t)ans+=siz[p],vis[p]=t;//,cout<<"hhh "<
//cout<
}
printf("%d\n",ans);
}
return 0;
}
这次多了区间的限制
考虑还是跑出长度 f[i],那么对于区间 [l,r] 相当于是查询 max{min(f[i],i−l+1)}
发现内层多了个 min 不好处理,由于 f[i] 每次加一具有单调性,那么可以先二分答案,使得每一个都不受限制,然后用 ST 表查询区间最大值
代码
#include-1;
}
for(int j=1;j<=t;j++){
for(int i=1;i<=n;i++){
f[i][j]=max(f[i][j-1],f[i+po[j-1]][j-1]);
}
}
return ;
}
int main(){
// freopen("P6640_6.in","r",stdin);
// freopen("my.out","w",stdout);
scanf("%s%s",a+1,b+1);n=strlen(a+1),m=strlen(b+1);
for(int i=1;i<=m;i++)insert(b[i]-'a');
for(int i=1,p=1,nowlen=0;i<=n;i++){
int w=a[i]-'a';
if(!son[p][w]){
for(;p!=1&&!son[p][w];p=fa[p]);
nowlen=len[p];
}
if(son[p][w])p=son[p][w],nowlen++;
f[i][0]=nowlen;
// cout<
}
// return 0;
pre();t=read();int cnt=0;
// cout<<"hhhh"<
while(t--){
cnt++;l=read(),r=read();
int lx=l,rx=r+1,pos=r+1;
while(lxint mid=lx+rx>>1;
if(mid-f[mid][0]+1>=l)rx=mid;
else lx=mid+1;
}
// cout<<"hhh "<
// if(lx+1-f[lx+1][0]+1>=l)lx++;
// cout<
// if(cnt==565)lx++,cout<
printf("%d\n",max(ask(lx,r),lx-l));
}
return 0;
}
考虑没有区间限制的暴力做法:对 S 的 SAM 跑 T 进行匹配,跑到第一个没有匹配项的地方找到比 T 大的转移,如果都能匹配上,那么往回退,直到有一个满足条件的
现在有了区间的限制,如果能判断后缀自动机上的这个节点的 endpos 集合中有没有当前区间内的点就可以正常做了,那么直接在 parent 树上线段树合并维护 endpos 集合即可
代码
#include
edge[++cnt].nxt=hd[u];
edge[cnt].to=v;
hd[u]=cnt;
return ;
}
struct Seg{
int l,r,son[2];
}t[maxn*40];
int change(int p,int l,int r,int w){
if(!p)p=++tot;t[p].l=l,t[p].r=r;
// cout<
if(l==r)return p;
int mid=l+r>>1;
if(w<=mid)t[p].son[0]=change(t[p].son[0],l,mid,w);
else t[p].son[1]=change(t[p].son[1],mid+1,r,w);
return p;
}
int merge(int p,int q){
if(!p||!q)return p+q;
int np=++tot;t[np].l=t[p].l,t[np].r=t[p].r;
t[np].son[0]=merge(t[p].son[0],t[q].son[0]);
t[np].son[1]=merge(t[p].son[1],t[q].son[1]);
return np;
}
bool ask(int p,int l,int r,int ll,int rr){
// cout<
if(!p)return false;
if(t[p].l>=l&&t[p].r<=r)return true;
int mid=ll+rr>>1;
if(l<=mid&&ask(t[p].son[0],l,r,ll,mid))return true;
if(r>mid&&ask(t[p].son[1],l,r,mid+1,rr))return true;
return false;
}
void dfs(int u){
if(endpos[u])rt[u]=change(rt[u],1,n,endpos[u]);//,cout<
for(int i=hd[u];i;i=edge[i].nxt){
int v=edge[i].to;
dfs(v);rt[u]=merge(rt[u],rt[v]);
}
return ;
}
bool check(int p,int l,int r,int len){
// cout<
if(l+len>r)return false;
return ask(rt[p],l+len,r,1,nn);
}
int main(){
scanf("%s",a+1);nn=n=strlen(a+1);m=read();
for(int i=1;i<=n;i++)insert(a[i]-'a',i);
for(int i=2;i<=tot;i++)add(fa[i],i);tot=0;dfs(1);
// cout<
while(m--){
l=read(),r=read();scanf("%s",a+1);
int p=1;sta[tp=1]=1;n=strlen(a+1);ans=27;
for(int i=1;i<=n;i++){
int w=a[i]-'a';
int to=son[p][w];
if(to&&check(to,l,r,i-2))sta[++tp]=p=to;
else break;
}
a[n+1]='a'-1;
while(ans==27&&tp>=0){
p=sta[tp];
for(int j=a[tp]-'a'+1;j<26;j++){
if(son[p][j]&&check(son[p][j],l,r,tp-1)){
ans=j;break;
}
}
tp--;
}
// cout<
if(ans==27)puts("-1");
else{
for(int i=1;i<=tp;i++)putchar(a[i]);
putchar(ans+'a');puts("");
}
}
return 0;
}
首先建出后缀树,那么可以按照字符排序儿子,之后得到的 dfs 序即为字典序排序后的结果
由于优先考虑长度,那么求出每种长度的个数以后可以确定答案的长度了
那么用一棵线段树维护当前 dfs 序上的个数,线段树二分就可以了
代码
#includehas[maxn],que[maxn],op[maxn];
ll k,sum[maxn];
pi ans[maxn];
char a[maxn];
ll read(){
ll x=0,f=1;char ch=getchar();
while(!isdigit(ch)){if(ch=='-')f=-1;ch=getchar();}
while(isdigit(ch)){x=x*10+ch-48;ch=getchar();}
return x*f;
}
void insert(int w,int id){
int p=last,np=last=++tot;
len[np]=len[p]+1;siz[np]=1;rig[np]=id;
for(;p&&!son[p][w];p=fa[p])son[p][w]=np;
if(!p)fa[np]=1;
else{
int q=son[p][w];
if(len[q]==len[p]+1)fa[np]=q;
else{
int nq=++tot;fa[nq]=fa[q];rig[nq]=id;
son[nq]=son[q];
// memcpy(son[nq],son[q],sizeof son[q]);
len[nq]=len[p]+1;fa[q]=fa[np]=nq;
for(;p&&son[p][w]==q;p=fa[p])son[p][w]=nq;
}
}
return ;
}
void add(int u,int v,int w){has[u].pb({w,v});has[u].shrink_to_fit();}
void dfs(int u){
sort(has[u].begin(),has[u].end());
for(auto v:has[u]){
dfn[v.se]=++num;rem[num]=v.se;
dfs(v.se);rig[u]=max(rig[u],rig[v.se]);
op[mlen[v.se]].pb({v.se,1});
op[len[v.se]+1].pb({v.se,-1});
}
return ;
}
void build(){
for(int i=2;i<=tot;i++){
cf[mlen[i]=len[fa[i]]+1]++;
cf[len[i]+1]--;
add(fa[i],i,a[rig[i]-mlen[i]+1]);
}
dfs(1);for(int i=1;i<=n;i++)cf[i]+=cf[i-1],sum[i]=sum[i-1]+cf[i];
// for(int i=1;i<=n;i++)cout<
return ;
}
struct Seg{
int l,r,sum;
}t[maxn*4];
void build(int p,int l,int r){
t[p].l=l,t[p].r=r;
if(l==r)return re[l]=p,void();
int mid=l+r>>1;build(p<<1,l,mid),build(p<<1|1,mid+1,r);
}
void change(int p,int w){
p=re[p];t[p].sum+=w;
while(p>>1)p>>=1,t[p].sum+=w;
return ;
}
int ask(int p,int w){
if(t[p].l==t[p].r)return t[p].l;
if(t[p<<1].sumreturn ask(p<<1|1,w-t[p<<1].sum);
return ask(p<<1,w);
}
void solve(){
build(1,1,tot);
for(int i=1;i<=n;i++){
for(auto x:op[i])change(dfn[x.fi],x.se);
for(auto x:que[i]){
int pos=ask(1,x.fi);pos=rem[pos];
ans[x.se]=mp(n-rig[pos]+1,n-rig[pos]+i);
}
}
return ;
}
signed main(){
scanf("%s",a+1);n=strlen(a+1);reverse(a+1,a+n+1);
for(int i=1;i<=n;i++)insert(a[i]-'a',i);
build();q=read();
for(int i=1;i<=q;i++){
k=read();
if(k>sum[n]){ans[i]=mp(-1,-1);continue;}
int pos=lower_bound(sum+1,sum+n+1,k)-sum;
que[pos].pb({k-sum[pos-1],i});
}
solve();for(int i=1;i<=q;i++)printf("%d %d\n",ans[i].fi,ans[i].se);
return 0;
}
字符串
题意:定义相似为之多一个位置不同,求所有长度为 m 的子串的相似串个数
考虑两个 m 子串 i,j 如果相似需要满足 lcp(i,j)+lcs(i+m−1,j+m−1)≥m−1
考虑建出两个后缀树,那么就是要统计有多少点对满足两棵树上的 lca 深度之和 ≥m−1
涉及到点对统计问题,考虑使用 dsu on tree 解决
在前缀树上找到一个前缀,设当前枚举的 lca 的深度为 d,那么在后缀树上找到一个最浅的祖先,满足 dep≥m−1−d 即可
这个需要用两个树状数组实现,注意是两个,因为需要得知具体的个数,所以一个区间查询,一个单点查询
单点查询的比较难做,可以把一个数计入贡献的时候减去目前树状数组的值,去除贡献的时候再加上即可
代码
#include0;
}
else for(int i=n;i>=1;i--)insert(a[i]-'a',i);
for(int i=2;i<=tot;i++)has[fa[i]].pb(i);dfs(1);
}
}pre,suf;
void insert(int u){
tr[1].add(suf.dfn[suf.pos[pre.re[u]-m+1]],1);sta[++tp]=u;
ans[pre.re[u]-m+1]-=tr[0].ask(suf.dfn[suf.pos[pre.re[u]-m+1]]);
}
void insert1(int u,int pa){
int to=suf.find(suf.pos[pre.re[u]-m+1],m-1-pre.len[pa]);
ans[pre.re[u]-m+1]+=tr[1].ask(suf.dfn[to],suf.ed[to]);
tr[0].add(suf.dfn[to],suf.ed[to],1);
}
void clear(){
while(tp){
int u=sta[tp];
if(pre.re[u])ans[pre.re[u]-m+1]+=tr[0].ask(suf.dfn[suf.pos[pre.re[u]-m+1]]);
tr[1].add(suf.dfn[suf.pos[pre.re[sta[tp--]]-m+1]],-1);
}
}
void solve(int u,int pa){
if(pre.re[u])insert1(u,pa),sta1.pb(u);
for(int v:pre.has[u])solve(v,pa);
}
void dfs(int u,int op=0){
for(int v:pre.has[u])if(v^pre.son1[u])dfs(v),clear();
if(pre.son1[u])dfs(pre.son1[u],1);
if(pre.re[u])insert1(u,u),insert(u);
for(int v:pre.has[u])if(v^pre.son1[u]){
solve(v,u);
for(int u:sta1)insert(u);
sta1.clear();
}
}
int main(){
// freopen("1.in","r",stdin);
cin>>n>>m;scanf("%s",a+1);t=log2(n*2)+1;
pre.build(0);suf.build(1);
dfs(1);clear();
for(int i=1;i<=n-m+1;i++)printf("%d ",ans[i]);
return 0;
}