上篇文章介绍了如何创建合适的MySQL索引,今天再一块学一下如何更规范、更合理的使用MySQL?
合理规范的使用MySQL,可以大大减少开发工作量和线上问题,并提升SQL查询性能。
我精心总结了这16条MySQL规约,分享给大家,欢迎评论指正。
1. 禁止使用select *
阿里开发规范中,有这么一句话:

**select *** 会查询表中所有字段,如果表中的字段有更改,必须修改SQL语句,不然就会执行错误。
查询出非必要的字段,徒增磁盘IO和网络延迟。
2. 用小表驱动大表
关联查询的时候,先用小表查到结果,再用结果去大表查询,可以大大减少连接次数。
比如我们要查询某个部门下的员工,由于部门数量远远小于员工数量。我们可以把部门表当作驱动表,员工表当作被驱动表。
查询SQL类似这样:
select * from department
inner join employee
on department.id=employee.department_id
where department_name='部门1';
3. join关联表不宜过多
join关联表禁止超过3张,join关联过多,不但会增加查询时间,降低查询性能,还会产生临时表缓存结果数据,推荐拆成多条小SQL执行。
另外关联字段的类型一定要保持一致,并且在每张表都要建立关联字段的索引。
4. 禁止使用左模糊或者全模糊查询
当我们在SQL查询使用左模糊或者全模糊匹配的时候,类似下面这样:
# 左模糊查询
select * from user where name='%一灯';
# 全模糊查询
select * from user where name='%一灯%';
根据B+树的特性,即使我们在name字段上建立了索引,查询的时候也是无法用到索引的。
5. 索引访问类型至少达到range级别
索引访问类型常见的有这几个级别,从上到下,性能由好到差。
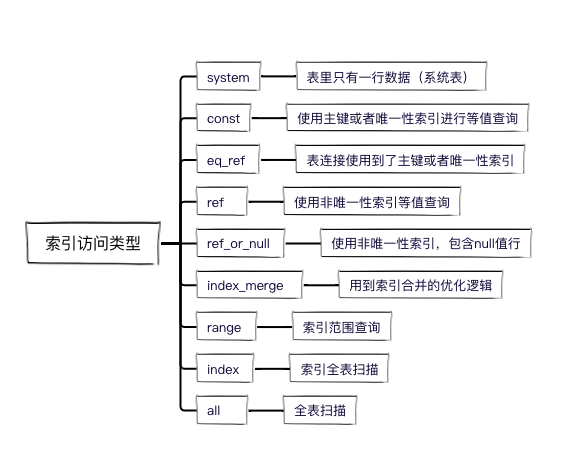
要求SQL索引访问类型至少要达到range级别,最好到const级别。
6. 更优雅的使用联合索引
由于联合索引有最左匹配原则,所以需要优先把区分度高的字段放在最左边第一列。
比如要统计用户表中生日字段和性别字段区分度,可以这样统计:
select
count(distinct birthday)/count(*),
count(distinct gender)/count(*)
from user;

值越大,区分度越高。
出道面试题,下面这条SQL该怎么创建联合索引:
select a from table_name where b=1 order by c;
SQL中用到abc三个字段,创建联合索引的顺序是(b,c,a)。
这道题还涉及到另一个知识点,SQL执行的顺序:
from > on > join > where > group by > having > select > distinct > order by > limit
7. 注意避免深分页
MySQL深分页的时候,查询性能较差。
select * from user where name='一灯' limit 10000,10;
我们可以采用子查询的方式进行优化:
select * from user
where id in (
select id from user
where name='一灯'
limit 10000,10
);
这样可以减少非聚簇索引回表查询的次数。
8. 单表字段不要超过30个
当单表字段数量过多的时候,加载大量数据也会拖慢查询性能。
如果字段超过30个,不用看,肯定是表设计的不合理。
这时候,可以拆成多张表,用垂直分表的方式,进行冷热字段分离。
9. 枚举字段不要使用字符类型
字符类型会占用更多的存储空间,当我们想要存储枚举值或者表示是否的时候,可以采用tinyint数值类型,最好采用无符号整数unsigned tinyint。
10. 小数类型禁止使用float和double
在存储和计算的时候,float 和 double 都存在精度损失的问题,无法得到正确的结果。
所以在涉及到存储小数的时候,必须使用decimal类型。
11. 所有字段必须设置默认值且不允许为null
字段允许为null,会占用额外的存储空间。
索引并不会索引null值,所以查询null值的时候无法用到索引。
当数值类型允许为null,返回给映射实体类的时候还可能会报空指针异常。
12. 必须创建主键,最好是有序数值类型
如果我们自己没有给表设置主键,InnoDB会自动增加一列隐藏的主键,我们无法使用到,并且也占用的更多的存储空间,所以建表的时候,必须设置主键。
有序数值更适合做主键,插入数据的时候,由于是有序的,不会频繁调整B+树结构,性能更好。
13. 快速判断是否存在某条记录
一般我们判断表中是否存在某条记录的时候,会使用count函数,然后判断返回值是否大于1。
select count(*) from user where name='一灯';
InnoDB存储引擎并没有像MyIsAm那样缓存表的总行数,每次查询都是实时计算的,耗时较长。
我们可以采用limit加快查询效率:
select id from user where name='一灯' limit 1;
limit 1表示匹配到一条就返回,查询效率更好,结果集只返回id,还可以用到覆盖索引。
14. in条件中数量不宜过多
in条件中数量不要超过1000个,不然耗时会非常长,可以拆成多批次查询。
15. 禁止创建预留字段
无法通过预留字段的名称判断这个字段是干嘛用的。
预留字段的类型不一定合适。
无法为预留字段创建合适的索引。
16. 单表索引数不要超过5个
创建适当的索引可以提高查询效率,但是过多的索引,不但占用更多存储空间,还会拖慢更新SQL的性能。
所以,索引好用,适度即可。
知识点总结:

文章持续更新,可以微信搜一搜「 一灯架构 」第一时间阅读更多技术干货。