-
基于flowable的upp(统一流程平台)运行性能优化
经过一年规模化应用,近期现场反馈出现运行性能问题。其实,我们在构建upp系统时,已经知道了在一定时间点后会出现性能问题,但迫于团队整体研发平衡,以及对当前计算机性能的评估,就停留了下来。
当下,到了解决相关问题的时候了。
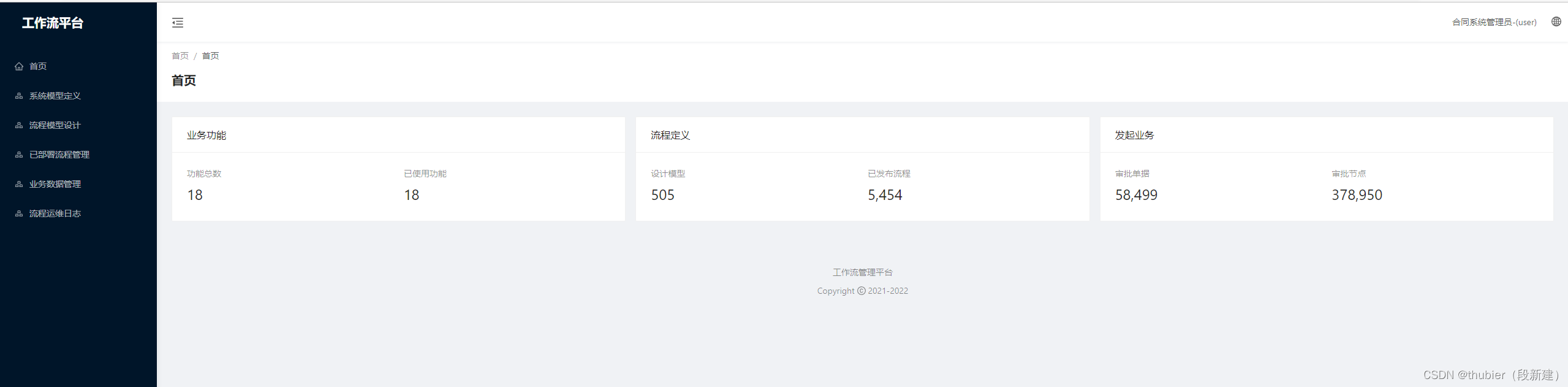
经过一年的线上运行,接入流程平台的业务功能有16类,定义了505条流程,经过5454次的部署操作。已经发起的单据有58499个,进行了378950次的执行审批。基本当前的运行数据及集团化功能实际验证,upp系统的功能应该覆盖了业务全流程。所以,在最近完成的代理审批加持下,upp功能性研发以接近尾声,后续将基于upp进行深入的应用:如全运营流程风险预警/事前合规审查等业务的集成。
针对upp系统的性能问题,我们必须从原理上进行分析:upp的内核时flowable6.5,在此基础上引入符合中国国情的业务处理,最终形成了符合合同/案件/法务/风险-合规 业务的流程处理平台,再进一步解决业务系统接入,将形成较为通用的(upp)统一流程平台。
所以,性能问题的解决,需要对flowable数据模型进行分析.
flowable数据模型采用了套表的概念,在数据模型命名中基本明确:

从上图中,我们可以发现flowable自己的数据模型在命名时进行了分类,由于flowable是一套独立的中立的流程模型,所以本身就是一套独立的系统:如支持的表单模型act_fo表进行管理,并且基于bpmn规范的基础上,完成了cmmn、dmn规范的整合,让flowablep平台形成了较为全面的标准化商务流程与面向突发事件的数据驱动模型。
upp平台当前使用了bpmn模块,因为单据模型/组织结构等采用了企业级标准主键。
所以,本次性优化将基于act_ge_*、act_de_*,act_re_*,act_ru_*,act_hi_*这五大类表进行分析》
1.act_ge_*

从上图可以知道:act_get_bytearray表如果不进行处理,随着时间的推移,将会层级大量的由运行过程中变量大对象加入的信息。
所以,当我们明确相关流程已经终审,且不再支持终审取回时,我们需要对存储变量相关的信息进行清理。
基于upp的模型设计,分析过程如下:
select * from act_ge_bytearray where DEPLOYMENT_ID_ is null;
select distinct name_ from act_ge_bytearray where DEPLOYMENT_ID_ is null;
select name_,count(*) from act_ge_bytearray where DEPLOYMENT_ID_ is null group by name_
由于变量表区分运行表与历史表,所以需要结合这两张表的信息,进行相关的数据清理。
2.act_de_*

基于以上分析,act_de_*不对业务运行性能进行影响。
3.act_re_*

当前看,对流程运行暂时无影响,但如果流程规模扩展到1w以上,将需要进行相关的处理。
4.act_ru_*
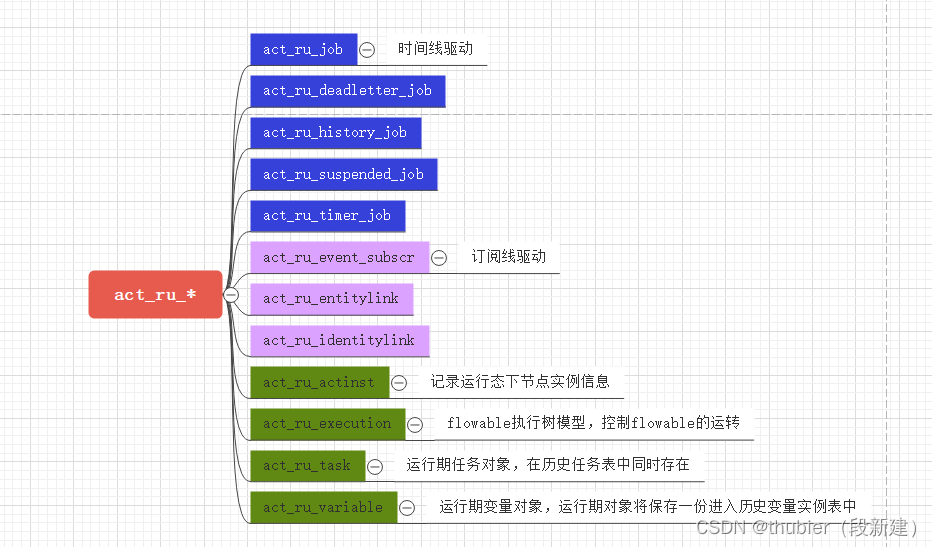
ru表的提出就是为了解决运行性能而存在的,所以基本不需要考虑。但flowable只是我们的一个内核之一,由很多业务将在外围控制流程的接受,如手动终审流程方案等。所以,我们需要提供对外围流程终审方案进行支持,以便让运行库最小化运行。
5.act_hi_*
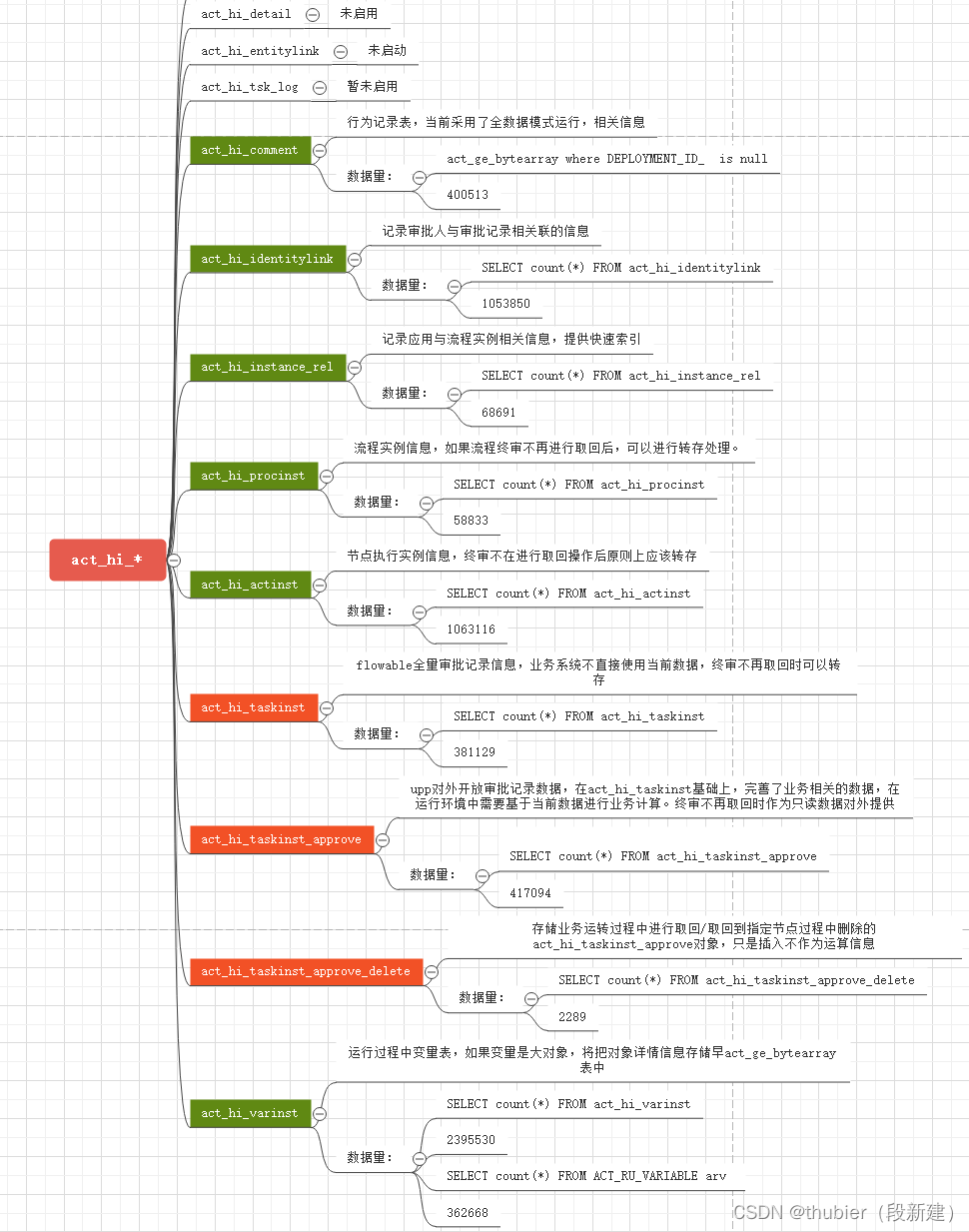
基于当前数据分析,保证flowable运行库数据量最小化,将是优化性能的核心方向。
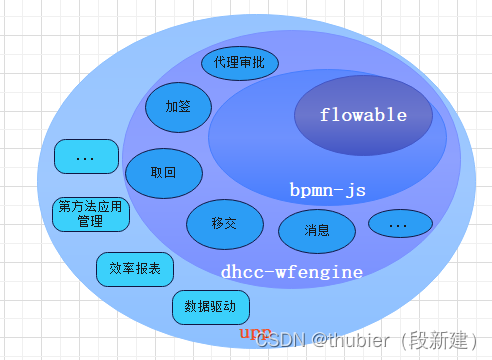
最后,upp平台到底是怎样的一个组织方式,给大家公布下:
-
相关阅读:
MySQL-锁分类-2
京东云开发者| Redis数据结构(二)-List、Hash、Set及Sorted Set的结构实现
CentOS7 设置固定IP地址
Web前端:React有哪些优缺点?
计算机网络 - 概述 选择填空复习题
C语言笔记-17-Linux基础-用户与权限
数据库的概念-数据库、数据库管理系统、数据库系统、数据库管理员、数据库设计人员、开发管理使用数据库系统的人员
springboot供应商管理系统毕业设计源码121518
报错:axios发送的所有请求都是404
骨传导耳机品牌排名前十,盘点最受欢迎的五款TOP级骨传导耳机
- 原文地址:https://blog.csdn.net/tubierr/article/details/126093831