-
TorchScript 解读(四):Torch jit 中的别名分析
目录
TorchScript 系列继续更新啦,让大家久等啦。在之前的学习中,我们已经掌握了 torch jit 的一些基本概念、学会了如何将一个使用 python 编写的模型转换为 torchscript 以及 ONNX;并且已经可以使用一些易用的工具生成 pass, 对模型进行优化啦。
OpenMMLab:TorchScript 解读(一):初识 TorchScript99 赞同 · 11 评论文章正在上传…重新上传取消
OpenMMLab:TorchScript 解读(二):Torch jit tracer 实现解析44 赞同 · 2 评论文章正在上传…重新上传取消
OpenMMLab:TorchScript 解读(三):jit 中的 subgraph rewriter28 赞同 · 0 评论文章正在上传…重新上传取消
有些读者更是可以写一些更复杂、功能更强大的 pass 以满足优化需求,但是更复杂的代码也就意味着更多的潜在风险,比如 Data Hazards。而别名分析就是一个帮助我们回避一些风险、写出更安全 pass 的工具,今天我们带大家一起来认识一下。
什么是别名分析
Torch jit 中内置了非常多的 pass 以帮助我们完成各式各样的优化,用户也可以定义自己的 pass 来实现特定的目的。这种灵活性给我们优化模型带来了便利,但是它也不是没有限制的。以下面的代码和对应的可视化图片为例:
- def forward(self, x, y):
- x = x + 1
- x.add_(x)
- return x + y
- # graph(%self : __torch__.TestModel,
- # %x.1 : Tensor,
- # %y.1 : Tensor):
- # %4 : int = prim::Constant[value=1]() # create_model.py:19:16
- # %x0.1 : Tensor = aten::add(%x.1, %4, %4) # create_model.py:19:12
- # %8 : Tensor = aten::add_(%x0.1, %x0.1, %4) # create_model.py:20:8
- # %11 : Tensor = aten::add(%x0.1, %y.1, %4) # create_model.py:21:15
- # return (%11)

神经网络会构成一个计算图 Graph,原则上一个 Graph 中的 Node 如果不能通过任何路径到达输出节点,那么这就是一个无用的节点,可以被优化(删除)掉。比如上图中的
add_节点。这种优化通常被称为死代码消除(DeadCodeElimination)。通过代码可知,add_节点是一个 inplace 运算,会更新 x 的值,如果删除它会造成错误的计算结果。从上面代码中的第 11 行可以看到,
add_的输出为%8,如果我们知道%8实际与它的输入%x0.1共享同样的内存空间,那么我们就会避免去删除这个节点,保证优化的正确性。这就是别名分析(AliasAnalysis)的作用。我们可以用下面的代码来验证下:
- #include <torch/csrc/jit/ir/alias_analysis.h>
- #include <torch/script.h>
- int main(int argc, char* argv[]) {
- auto model = torch::jit::load(argv[1]); // 读取模型
- auto graph = model.get_method("forward").graph(); // 提取计算图
- torch::jit::AliasDb aliasdb(graph); // 创建AliasDb对象
- aliasdb.dump(); // 可视化分析结果
- return 0;
- }
这个程序使用 PyTorch 提供的别名分析工具 AliasDb 对输入的模型的 forward 函数的 Graph 进行分析,并且可视化分析结果。我们输入刚才的模型,结果如下:
- ===1. GRAPH===
- graph(%self : __torch__.TestModel,
- %x.1 : Tensor,
- %y.1 : Tensor):
- %4 : int = prim::Constant[value=1]() # create_model.py:19:16
- %x0.1 : Tensor = aten::add(%x.1, %4, %4) # create_model.py:19:12
- %8 : Tensor = aten::add_(%x0.1, %x0.1, %4) # create_model.py:20:8
- %11 : Tensor = aten::add(%x0.1, %y.1, %4) # create_model.py:21:15
- return (%11)
- ===2. ALIAS DB===
- %x.1 points to: WILDCARD for type Tensor
- %y.1 points to: WILDCARD for type Tensor
- %8 points to: %x0.1
- %self points to: WILDCARD for type __torch__.TestModel
- ===3. Writes===
- %8 : Tensor = aten::add_(%x0.1, %x0.1, %4) # create_model.py:20:8
- %x0.1,
可以看到在 ALIAS DB 下有这么一条:
%8 points to: %x0.1。通过这个工具就可以知道,%8实际引用了%x0.1的值,而%x0.1参与了网络输出的计算,因此%8的计算不应该被删除。AliasDb
AliasDb 是 PyTorch 提供的别名分析工具,在 AliasDb 的帮助下,我们可以分析计算图中各个数据节点的关系,以避免潜在的错误优化。
MemoryDAG
MemoryDAG 是存储图对象,AliasDb 使用它维护数据间的依赖关系。根据源码 https://github.com/pytorch/pytorch/blob/master/torch/csrc/jit/ir/alias_analysis.h 。AliasDb 接收一个计算图 Graph,然后创建一个存储图 MemoryDAG。这个 MemoryDAG 与 Graph 存在对应关系,如下表所示:
Graph MemoryDAG 图 Graph 对象维护计算图结构,描述计算时的数据流向 MemoryDAG 对象维护存储图结构,描述各元素之间的引用(指向)关系 节点 Node 表示每个独立的计算,输入输出为 Value 对象 Element 表示一个(或多个) Value 对象的数据存储信息,包括他们是否引用其他 Element 边 Use 对象表示 Value 的会被哪些 Node 所使用 MemoryLocations 对象表示 Element 有可能会引用哪些其他 Element 这里有几点需要注意:
- Element 不仅可能指向 Value,也有可能是容器类或通配符等等。
- Element 与 Value 未必是一一对应的关系,比如一个分支结构
if condition: val=A else: val=B让 Element 可能指向 A 与 B 中任意一个。 - 基于上面的原因,MemoryLocations 指向的 Element 也只代表一种可能性。
AliasDb 在接收到一个 Graph 时,会根据各个 Node 的 FunctionSchema 中提供的信息,搭建对应的 MemoryDAG 对象,方便后续的分析。
如果不记得 FunctionSchema 是什么,可以复习一下 Torch jit tracer 实现解析中的基础知识
view的 FunctionSchema 如下:view(Tensor(a) self, int[] size) -> Tensor(a)可以看到第一个参数 self 以及输出中都有一个标记
(a),代表输出可能是参数 self 的一个别名。下面是表示一个计算图 Graph 的代码,以及对应的存储图 MemoryDAG 的可视化图片:
- @torch.jit.script
- def foo(a : Tensor, b : Tensor):
- c = 2 * b
- a += 1
- if a.max() > 4:
- r = a[0]
- else:
- r = b[0]
- return c, r
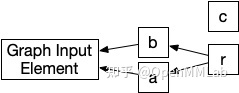
用 AliasDb 可以很轻松地查询一个 Node 会读或写哪些除了输出以外的 Value,如下面的代码所示。这点特别重要,关系到我们之后如何解决数据风险问题(data hazards)。
- ===3. Writes===
- %8 : Tensor = aten::add_(%x0.1, %x0.1, %4) # create_model.py:20:8
- %x0.1,
有很多运算都有可能产出别名,比如对下面代码 1 使用 AliasDb,会发现如代码 2 中所示的一些别名关系。
def forward(self, x, y): # 输入
x = x + 1
x.add_(x) # inplace运算
y = y[0] # slice或select
z = [x, y] # 容器类
w = torch.cat(z)
return w
代码1===2. ALIAS DB===
%x.1 points to: WILDCARD for type Tensor
%8 points to: %x0.1
%z.1 contains: %x0.1%y0.1,
%y.1 points to: WILDCARD for type Tensor
%self points to: WILDCARD for type __torch__.TestModel
%y0.1 points to: %y.1
代码2可以看见,图的输入、inplace 的运算、slice 还有对容器类的使用都会创造别名关系,也不是只有 Tensor 可能存在别名关系,上例中的 z 是一个 list ,它也在 AliasDb 的记录中。那么到底哪些类型会被 AliasDb 所关注呢?
mutable 与通配符集
AliasDb 引入了可修改类型(mutable)与不可修改类型(immutable)的概念。前者指那些内部值可以发生改变的数据类型,比如 Tensor、List 等,可以通过 inplace 运算或 append 等操作在不创建新对象的情况下编辑原来对象的类型。而那些像 int、string 之类的类型则是 immutable 的,AliasDb 可以简单跳过不分析这部分。
Tuple 类型比较特殊,如果内部元素都是 immutable 类型,比如 Tuple[int] ,那么它也是 immutable 类型;如果内部存在 mutable 类型,比如 Tuple[Tensor] ,那么它也会变成 mutable 类型。显然,mutable 类型的 Value 越少,优化成功的可能性越大。
在 mutable 类型的对象中,部分会指向
WILDCARD for type xxx,以下面代码为例:- %x.1 points to: WILDCARD for type Tensor
- %y.1 points to: WILDCARD for type Tensor
- %self points to: WILDCARD for type __torch__.TestModel
这种对象被称为通配符集(wildcardSet),它的含义是“无法判断该值的别名关系”。比如上面代码中,x 和 y 来自外部的输入,仅凭借分析 Graph 是无法确定他们是否共享存储资源的。如果一个对象被标记为指向通配符集,那么很多牵涉到它的优化都应该避免,以防发生错误。
Data Hazards
有了上面的知识后,我们就可以写一些更安全的 pass 了,在写 pass 的过程中,最经常使用到 AliasDb 的地方就是解决数据风险问题(DataHazards)。
举个例子:比如我们希望将某个 Node A 插入到 Node B 之前,如果 B 会修改可变类型参数 x 的值,并且 A 要读 x 修改后的值的话,这种插入就有可能造成错误。如下面的代码所示:
- # 原图,对B的写在对A的读之前
- graph(...):
- ...
- B: write(x)
- ...
- A: read(x)
- ...
- => # 不合法的转换!A会读取到错误的值!
- graph(...):
- ...
- A: read(x)
- B: write(x)
- ...
确定这一类读取顺序改变是否合法需要知道 Node 间读写的数据空间是否存在重叠。 AliasDb 中提供了
getReads和getWrites函数,传入 Node 作为参数,返回一个 MemoryLocations 对象,表示该 Node 会读/写哪些 mutable 变量,如果对上面的 A 和 B 分别调用getReads和getWrites, 就会发现他们之间的 MemoryLocations 存在重叠(intersects),不应该进行这种交换。如下面代码所示:- auto loc_a = alias_db.getReads(A);
- auto loc_b = alias_db.getWrites(B);
- bool valid = !loc_a.intersects(loc_b);
AliasDb 中提供了函数
moveAfterTopologicallyValid以及moveBeforeTopologicallyValid来帮助我们更轻松地完成这个任务。这个任务在移动前会进行检查,如果发现这个移动是合法的才会进行移动。这里我们首先要介绍一个工作集(WorkingSet)的概念。一个 WorkingSet 是一个 Node 的集合,集合中任意一个 Node 满足:
- 要么与集合中至少一个其他 Node 在 Graph 中有直接连接。
- 要么与集合中至少一个其他 Node 存在读写 MemoryLocations 的 intersects(必须是一个读一个写)。
如果一个集合外的 Node 与 WorkingSet 满足上述关系之一,那么我们称该 Node “依赖于” (dependOn)该 WorkingSet。
WorkingSet 可以协助我们进行合法性检查,考虑 moveAfter 的例子:
假设我们要将
toMove移动到紧贴着movePoint之前,那么存在两种情况:toMove在movePoint之后toMove在movePoint之前
首先我们需要构造一个
WorkingSet,然后将toMove插入该WorkingSet,再遍历所有toMove到movePoint(不包括movePoint)之间的节点 n,如果 n 依赖于该WorkingSet, 那么就把它插入进来。如果是情况 1 ,直接根据下面注释中的方式进行移动:
- // `movePoint` <dependencies> |
- // <dependencies> -> `toMove` | `toMove` 和依赖一起移动
- // `toMove` `movePoint` |
如果是情况 2,也就是
toMove在movePoint之前,那么最后要将toMove从这个WorkingSet中移除。在移除前,要对这个WorkingSet进行合法性检查:- 如果
movePoint依赖于该WorkingSet - 如果该
WorkingSet中(包括toMove)任意节点存在副作用,比如 inplace 运算
如果存在以上两种情况中的任意一种,那么就认为这次移动不合法,移动不会被执行。
合法性检查通过后,就会根据下面注释中的方式进行移动:
- // `toMove` `toMove` |
- // <dependencies> -> `movePoint` | `toMove` 和依赖被分开
- // `movePoint` <dependencies> |
参与移动的包括
WorkingSet中所有的 Node。这样的移动是安全的,不会导致读写冲突。上面介绍的内容被封装在下面的函数中,可以根据返回值判断 move 是否合法:
- bool success = moveBeforeTopologicallyValid(A, B);
- // 如果 move 合法则进行move,返回true。否则不进行任何操作,返回false。
总结
Jit pass 的灵活性给模型优化带来便利的同时也引入了一些风险,而别名分析工具 AliasDb 则是解决这些风险的利器之一。AliasDb 使用 MemoryDAG 管理内存,区分可变与不可变数据类型,帮助我们规避数据风险。结合前两章的知识,大家应该已经对 jit 模型的生成与优化有了一个初步认识。未来我们将会从实际例子出发,介绍 MMDeploy 如何使用这些工具进行模型的优化,敬请期待。
https://github.com/open-mmlab/mmdeploygithub.com/open-mmlab/mmdeploy
-
相关阅读:
机器学习算法系列————决策树(二)
THREE--demo10(地球坐标)
云计算——ACA学习 云计算架构
【Vue】模板语法,插值、指令、过滤器、计算属性及监听属性(内含面试题及毕设等实用案例)上篇
我用PYQT5做的第一个实用的上位机项目(六)
jdk 管理工具比对 jEnv jabba SDKMAN
swagger stub https无法访问
STM32CUBEIDE(11)----输出PWM及修改PWM频率与占空比
软体机器人空间感知技术综述
面向对象基础(二)
- 原文地址:https://blog.csdn.net/qq_39967751/article/details/125634915