-
100天精通Python(爬虫篇)——第45天:lxml库与Xpath提取网页数据

每篇前言
-
🏆🏆作者介绍:Python领域优质创作者、华为云享专家、阿里云专家博主、2021年CSDN博客新星Top6
- 🔥🔥本文已收录于Python全栈系列专栏:《100天精通Python从入门到就业》
- 📝📝此专栏文章是专门针对Python零基础小白所准备的一套完整教学,从0到100的不断进阶深入的学习,各知识点环环相扣
- 🎉🎉订阅专栏后续可以阅读Python从入门到就业100篇文章;还可私聊进两百人Python全栈交流群(手把手教学,问题解答); 进群可领取80GPython全栈教程视频 + 300本计算机书籍:基础、Web、爬虫、数据分析、可视化、机器学习、深度学习、人工智能、算法、面试题等。
- 🚀🚀加入我一起学习进步,一个人可以走的很快,一群人才能走的更远!


一、爬虫提取网页数据的流程图

二、lxml库
lxml是XML和HTML的解析器,其主要功能是解析和提取XML和HTML中的数据;,是一款高性能的python HTML、XML解析器,也可以利用XPath语法,来定位特定的元素及节点信息
1. 下载安装
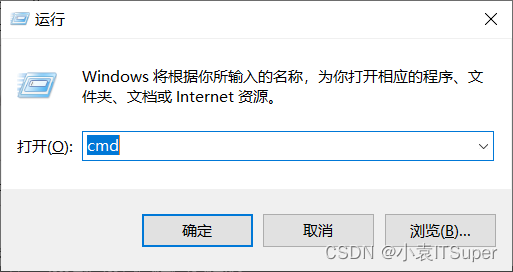
1. window电脑点击
win键+ R,输入:cmd
2. 安装
lxml,输入对应的pip命令:pip install lxml,我已经安装过了出现版本就安装成功了
2. 解析HTML网页
主要使用的lxml库中的etree类
案例1:解析HTML字符串
from lxml import etree text = ''' <html><body> <div class="key"> <div class="name">无羡</div> <div class="age">20</div> <div class="address">四川</div> </div> </body></html> ''' # 开始初始化 html = etree.HTML(text) # 这里需要传入一个html形式的字符串 print(html) print(type) # 将字符串序列化为html字符串 result = etree.tostring(html).decode('utf-8') print(result) print(type(result))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
输出结果:
<Element html at 0x1f7fa7f2a80> <class 'type'> <html><body> <div class="key"> <div class="name">无羡</div> <div class="age">20</div> <div class="address">四川</div> </div> </body></html> <class 'str'>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
案例2:读取并解析HTML文件
创建一个html文件

from lxml import etree # 将html文件进行读取 html = etree.parse('1.html') # 将html内容序列化 result = etree.tostring(html).decode('utf-8') print(result) print(type(result)) html = etree.HTML(result) # 这里需要传入一个html形式的字符串 print(html) print(type)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
输出结果:
<html><body> <div class="key"> <div class="name">无羡</div> <div class="age">20</div> <div class="address">四川</div> </div> </body></html> <class 'str'> <Element html at 0x17dffaa4c40> <class 'type'>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
lxml库掌握以上内容即可!
三、Xpath介绍
XPath (XML Path Language) 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
1. 选取节点
最常用的路径表达式:
表达式 说明 nodename选取此节点的所有子节点。 /从根节点选取。 //从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 .选取当前节点。 ..选取当前节点的父节点。 @选取属性。 案例:
表达式 说明 bookstore选取 bookstore 元素的所有子节点。 /bookstore选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! bookstore/book选取属于 bookstore 的子元素的所有 book 元素。 //book选取所有 book 子元素,而不管它们在文档中的位置。 bookstore//book选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 //@lang选取名为 lang 的所有属性。 2. 谓语
谓语用来查找某个特定的节点或者包含某个指定的值的节点,被嵌在方括号中。
路径表达式 说明 /bookstore/book[1]选取属于 bookstore 子元素的第一个 book 元素。 /bookstore/book[last()]选取属于 bookstore 子元素的最后一个 book 元素。 /bookstore/book[last()-1]选取属于 bookstore 子元素的倒数第二个 book 元素。 /bookstore/book[position()<3]选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 //title[@lang]选取所有拥有名为 lang 的属性的 title 元素。 //title[@lang=’eng’]选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 /bookstore/book[price>35.00]选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 /bookstore/book[price>35.00]/title选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 3. 选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
通配符 说明 *匹配任何元素节点。 @*匹配任何属性节点。 node()匹配任何类型的节点。 案例:
路径表达式 说明 /bookstore/*选取 bookstore 元素的所有子元素。 //*选取文档中的所有元素。 html/node()/meta/@*选择html下面任意节点下的meta节点的所有属性 //title[@*]选取所有带有属性的 title 元素。 4. 选取若干路径
通过在路径表达式中使用
“|”运算符,您可以选取若干个路径。案例:

5. Chrome插件 XPath Helper安装使用
免费下载地址:Chrome插件Xpath_helper.zip
一. 安装:
-
1.、解压压缩包
-
2、打开chrome页面,点击:右上角三个点 > 更多工具 > 扩展程序
-
3、点击
加载已解压的扩展程序,选择压缩包的路径

- 3、将插件固定在左上角

- 4、重启谷歌浏览器
二、使用:
-
快捷键ctrl+shift+X 开启 xpath-helper插件。或者点击左上角图标

-
定位爬取的内容:按住
x键,移动鼠标在爬取内容上即可显示标签路径

6. Xpath实战
新建一个
hello.html文件:<!-- hello.html --> <div> <ul> <li class="item-0"><a href="link1.html">first item</a></li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-1"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </ul> </div>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
1. 获取所有的
<li>标签:from lxml import etree html = etree.parse('hello.html') print(type(html)) # 显示etree.parse() 返回类型 result = html.xpath('//li') print(result) # 打印<li>标签的元素集合 print(len(result)) print(type(result)) print(type(result[0]))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
输出结果:
<type 'lxml.etree._ElementTree'> [<Element li at 0x1014e0e18>, <Element li at 0x1014e0ef0>, <Element li at 0x1014e0f38>, <Element li at 0x1014e0f80>, <Element li at 0x1014e0fc8>] 5 <type 'list'> <type 'lxml.etree._Element'>- 1
- 2
- 3
- 4
- 5
2. 继续获取
<li>标签的所有class属性:from lxml import etree html = etree.parse('hello.html') result = html.xpath('//li/@class') print(result)- 1
- 2
- 3
- 4
- 5
- 6
输出结果:
['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0']- 1
3. 继续获取
<li>标签下hre 为link1.html的<a>标签:from lxml import etree html = etree.parse('hello.html') result = html.xpath('//li/a[@href="link1.html"]') print(result)- 1
- 2
- 3
- 4
- 5
- 6
输出结果:
[<Element a at 0x10ffaae18>]- 1
4. 获取
<li>标签下的所有<span>标签:from lxml import etree html = etree.parse('hello.html') #result = html.xpath('//li/span') #注意这么写是不对的: #因为 / 是用来获取子元素的,而 <span> 并不是 <li> 的子元素,所以,要用双斜杠 result = html.xpath('//li//span') print(result)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
输出结果:
[<Element span at 0x10d698e18>]- 1
5. 获取
<li>标签下的<a>标签里的所有class:from lxml import etree html = etree.parse('hello.html') result = html.xpath('//li/a//@class') print(result)- 1
- 2
- 3
- 4
- 5
- 6
输出结果:
['blod']- 1
6. 获取最后一个
<li>的<a>的href:from lxml import etree html = etree.parse('hello.html') result = html.xpath('//li[last()]/a/@href') # 谓语 [last()] 可以找到最后一个元素 print(result)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出结果:
['link5.html']- 1
7. 获取倒数第二个元素的内容:
from lxml import etree html = etree.parse('hello.html') result = html.xpath('//li[last()-1]/a') # text 方法可以获取元素内容 print(result[0].text)- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出结果:
fourth item- 1
8. 获取
class值为bold的标签名:from lxml import etree html = etree.parse('hello.html') result = html.xpath('//*[@class="bold"]') # tag方法可以获取标签名 print(result[0].tag)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出结果:
span- 1
-
-
相关阅读:
java 网络编程Socket
2023高教社杯数学建模国赛的工具箱准备
Spring——和IoC相关的特性
【Vue】vue2适配移动端 vue创建移动端项目
Mybatis的collection三层嵌套查询(验证通过)
Python:线性查找法
中文编程工具开发语言开发的实际案例:触摸屏点餐软件应用场景实例
Vue监视数据的原理
【计算机组成 课程笔记】7.1 存储层次结构概况
计算机毕业设计——网络游戏虚拟交易平台的设计与实现
- 原文地址:https://blog.csdn.net/yuan2019035055/article/details/125583136
