-
Hive--14---企业级调优2----表的优化
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
表的优化
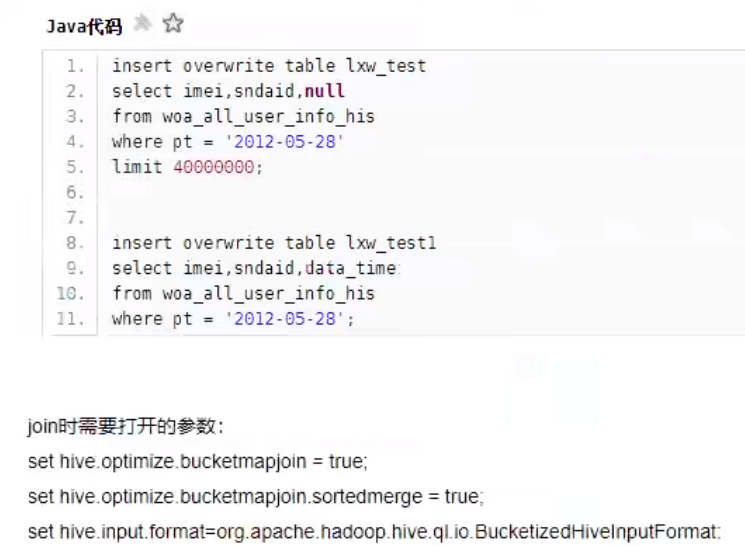
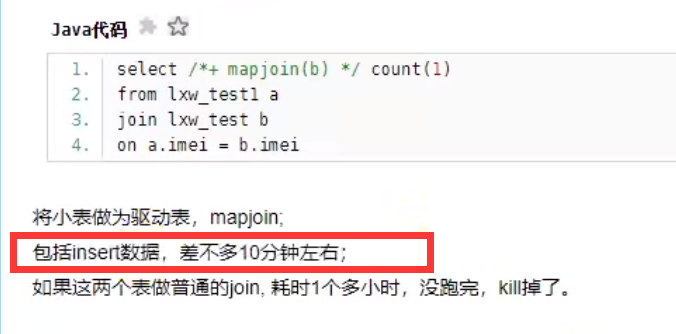
1.小表Join大表(Map JOIN)
多表联查–07— Hash join

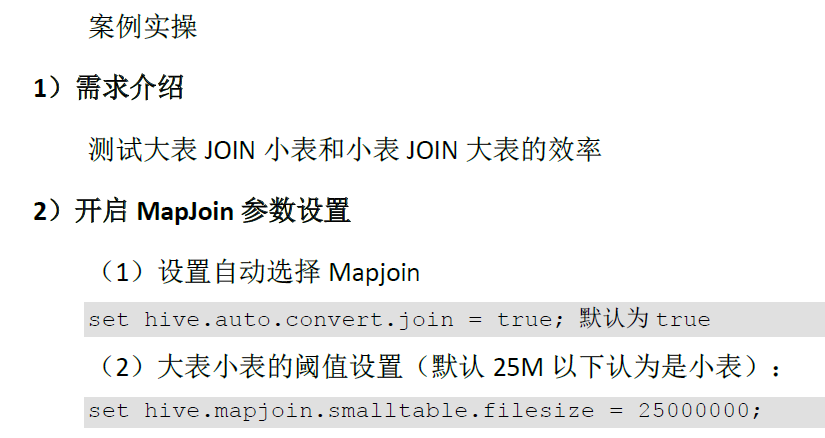
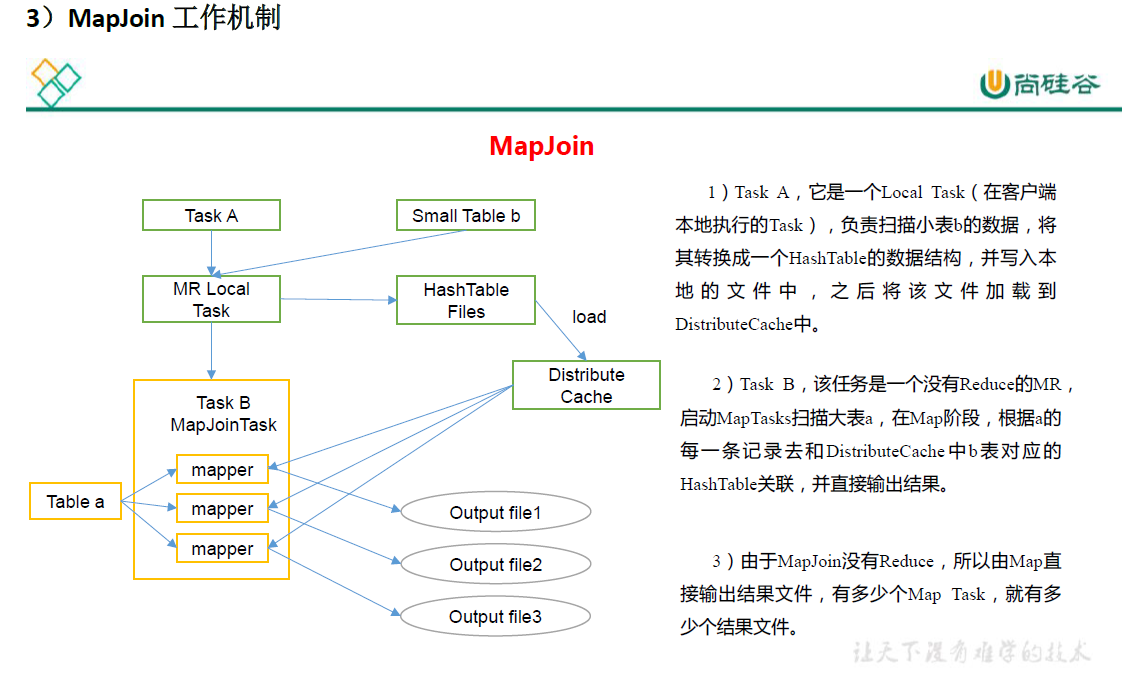
2.空 KEY处理
2.1 空key过滤


2.2 空key转换

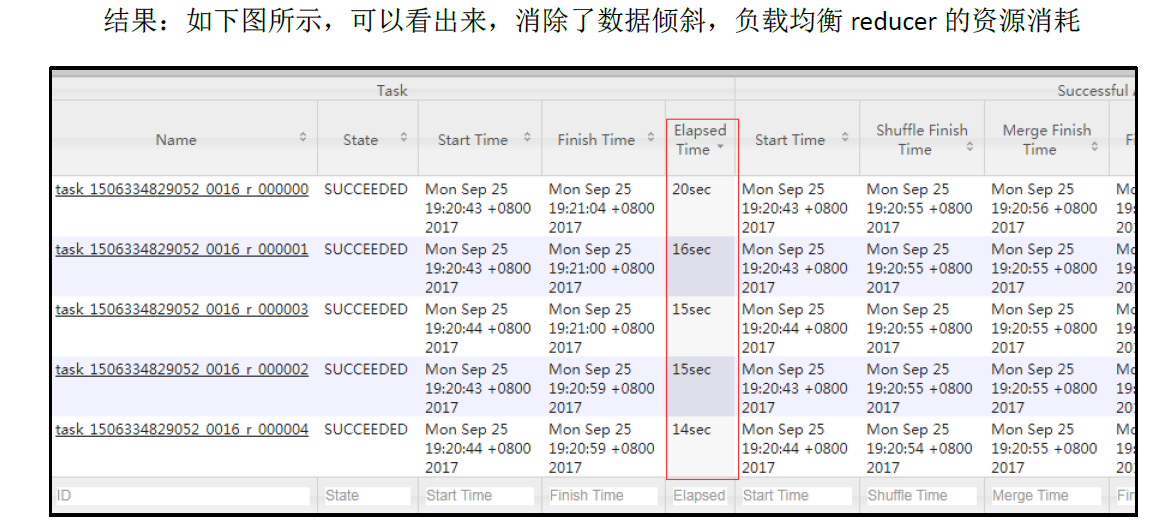
如果null值得数据,是业务需要的, 那么有可能实际跑MR任务的时候会造成数据倾斜

随机分布空 null 值

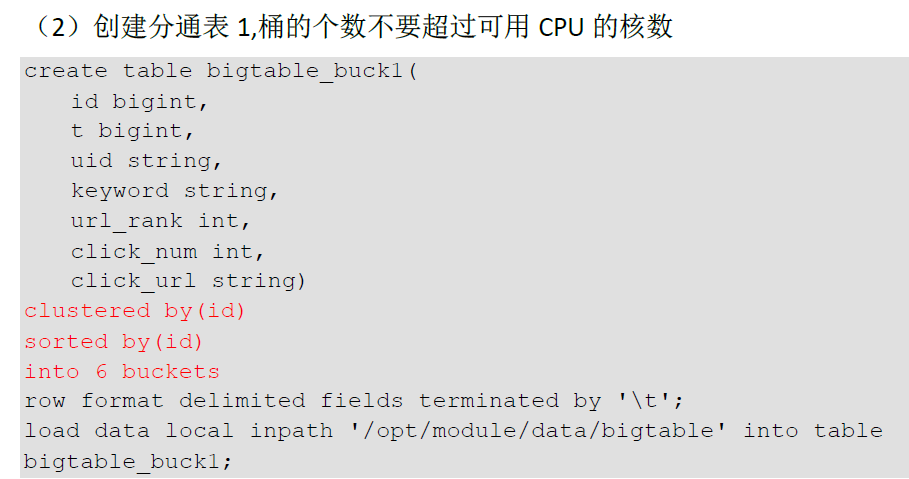
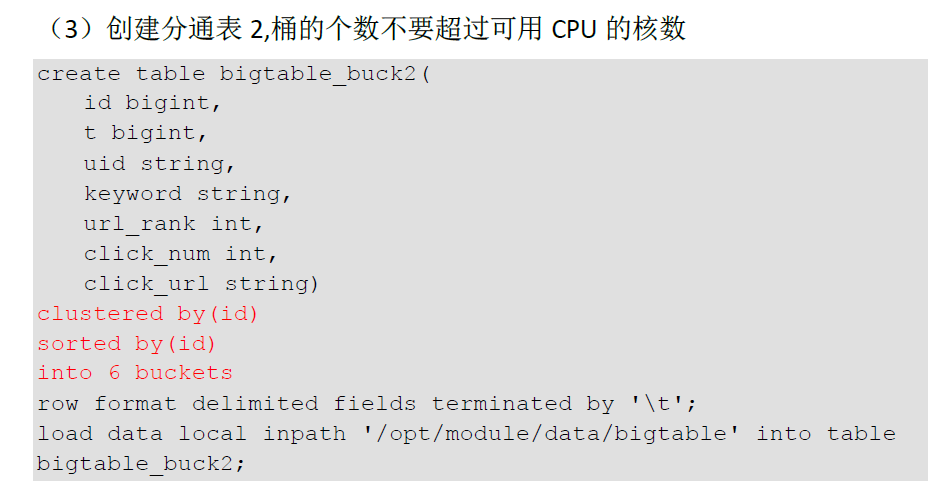
3. SMB(Sort Merge Bucket join)-----分桶表 join
如果2个表join,都是数据量特表大的表, 化大为小, 用join 字段进行分桶拆分,效率会高很多
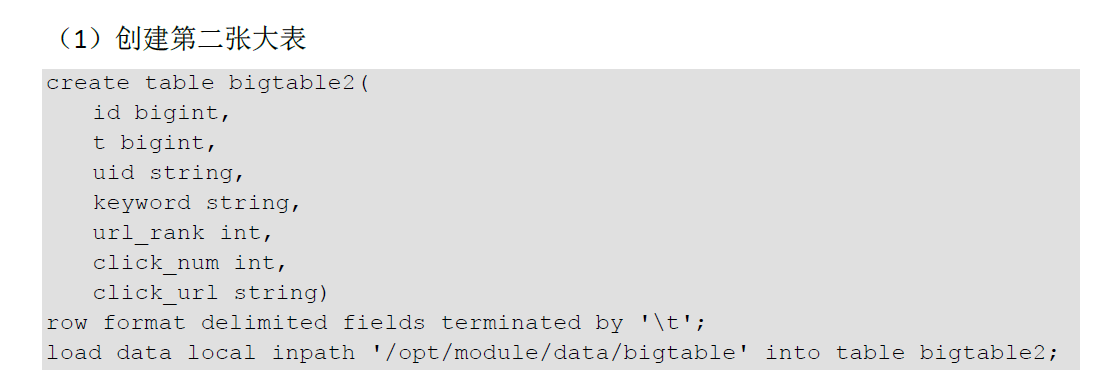

创建分通表 桶的个数不要超过可用 CPU的核数
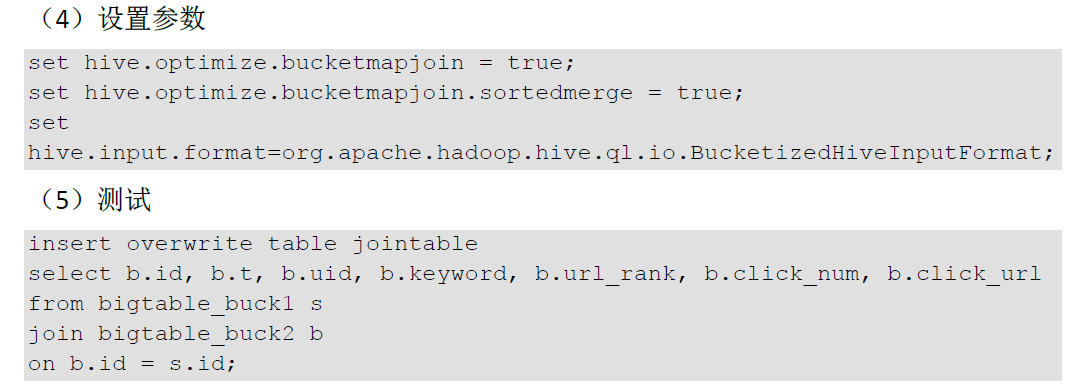
案例

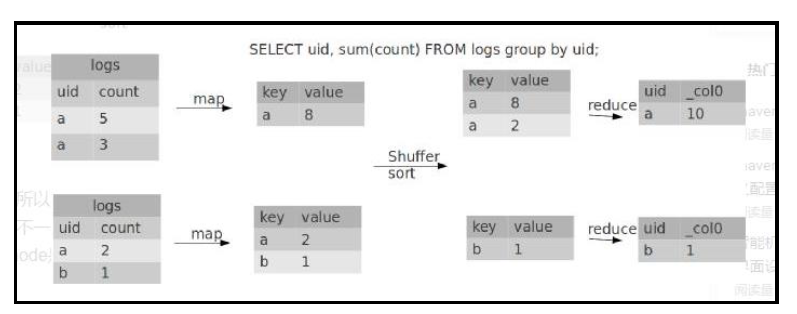
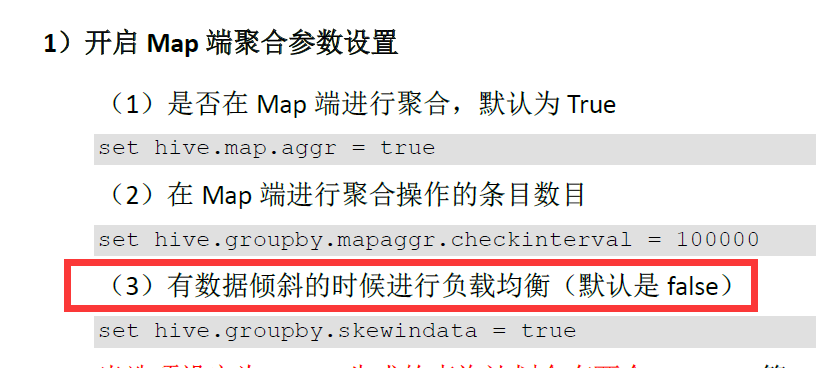
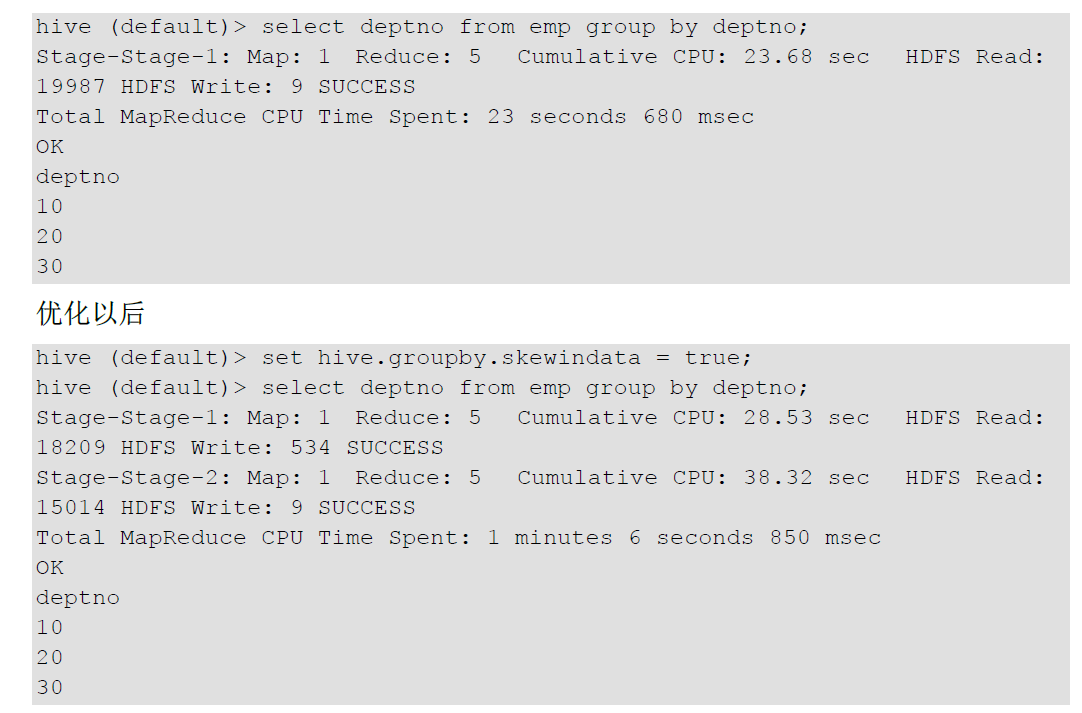
4.Group By
默认情况下,Map阶段同一 key数据分发给一个reduce,当一个key数据过大时就倾斜了


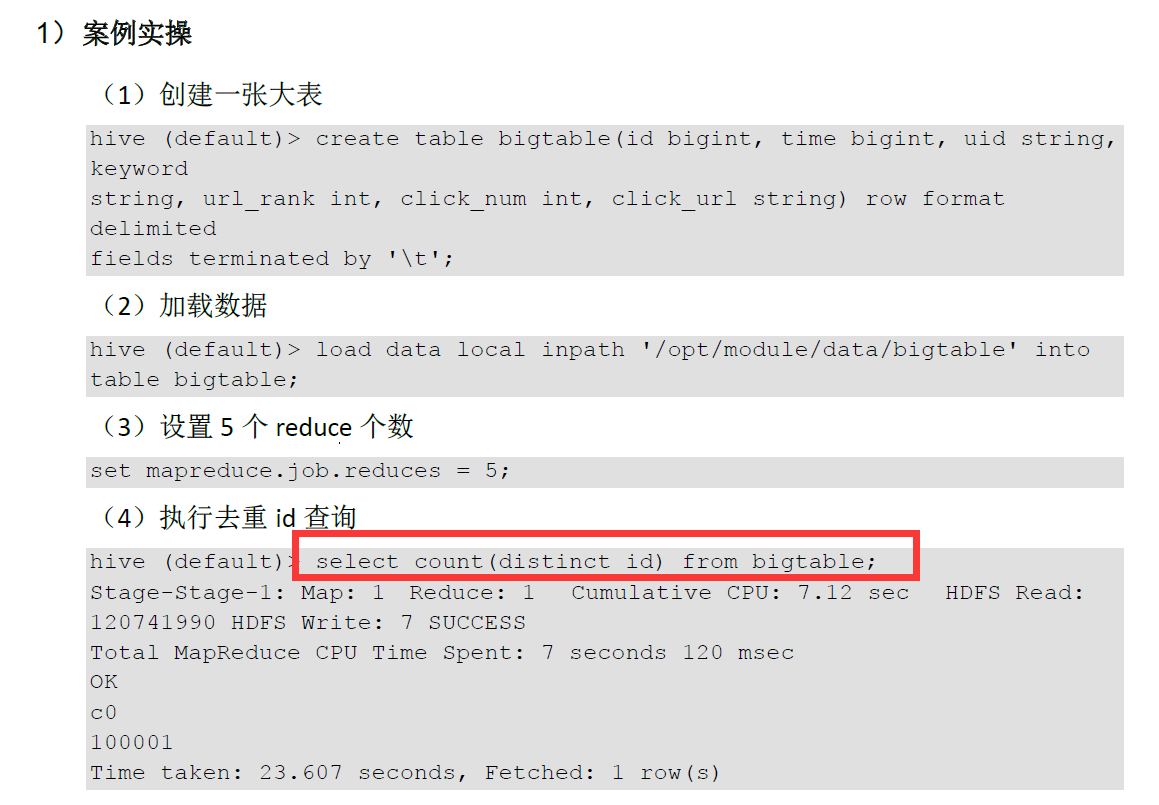
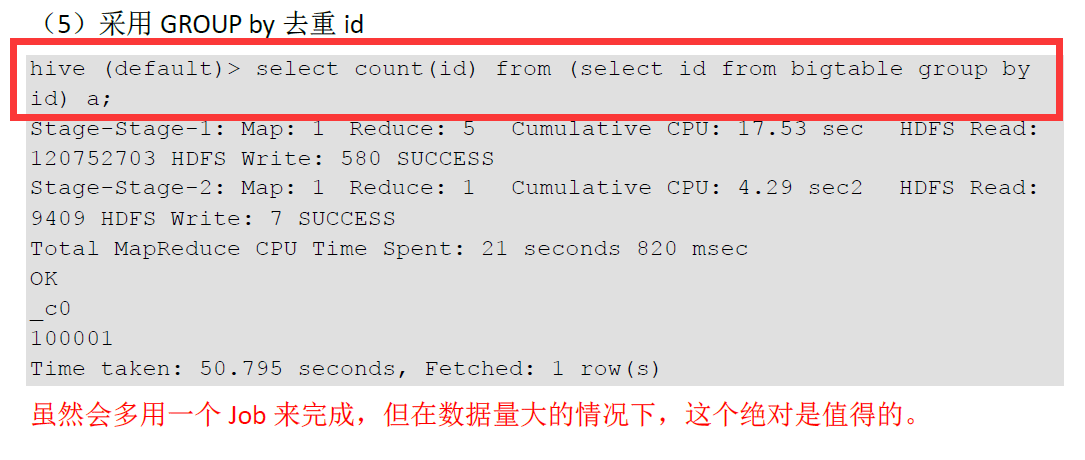
5. Count(Distinct) 去重统计

6. 笛卡尔积

7. 行列过滤



案例1 的执行计划,会先对b表和o表进行id字段过滤,再表关联.
因为框架底层优化器,发现where过滤条件id,正好是表的关联字段 id. 所以会进行谓词下推的优化
- 少用select * ,查询业务需要的字段
- 尽量先对副表进行过滤, 再进行表的关联
8. 表分区,表分桶
-
相关阅读:
React脚手架配置axios代理 (1.配置在package.json, 2.配置在setupProxy.js)
leetcode分类刷题:栈(Stack)(三、下一个更大的数)
[设计模式] 浅谈奇异递归模板模式
docker 安装mongodb 实现 数据,日志,配置文件外挂
5G创新突破 | 紫光展锐5G芯片全球首发R17 NR广播端到端业务演示
synchronized的锁策略及优化过程
tinymce富文本编辑器的使用
Fiddler抓包原理和使用详解
【学懂数据结构】顺序表?链表?我全都要(入门学习)
wpf使用CefSharp.OffScreen模拟网页登录,并获取身份cookie
- 原文地址:https://blog.csdn.net/weixin_48052161/article/details/125473995