-
lnmp架构之mysql的主从复制(一)
一、为什么要进行主从复制
主从复制、读写分离一般是一起使用的。目的很简单,就是为了提高数据库的并发性能。你想,假设是单机,读写都在一台MySQL上面完成,性能肯定不高。如果有三台MySQL,一台mater只负责写操作,两台salve只负责读操作,性能不就能大大提高了吗?
所以主从复制、读写分离就是为了数据库能支持更大的并发。
随着业务量的扩展、如果是单机部署的MySQL,会导致I/O频率过高。采用主从复制、读写分离可以提高数据库的可用性。
主从复制的作用:
做数据的热备,作为后备数据库,主数据库服务器故障后,可切换到从数据库继续工作,避免数据丢失。
架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的评率,提高单个机器的I/O性能。
读写分离,使数据库能支持更大的并发。在报表中尤其重要。由于部分报表sql语句非常的慢,导致锁表,影响前台服务。如果前台使用master,报表使用slave,那么报表sql将不会造成前台锁,保证了前台速度。1--在从服务器可以执行查询工作(即我们常说的读功能),降低主服务器压力;(主库写,从库读,降压)
2--在从主服务器进行备份,避免备份期间影响主服务器服务;(确保数据安全)
3--当主服务器出现问题时,可以切换到从服务器。(提升性能)二、主从复制的原理
Mysql的主从复制中主要有三个线程:
master(binlog dump thread)、slave(I/O thread 、SQL thread),Master一条线程和Slave中的两条线程。master(binlog dump thread)主要负责Master库中有数据更新的时候,会按照binlog格式,将更新的事件类型写入到主库的binlog文件中。并且,Master会创建log dump线程通知Slave主库中存在数据更新,这就是为什么主库的binlog日志一定要开启的原因。I/O thread线程在Slave中创建,该线程用于请求Master,Master会返回binlog的名称以及当前数据更新的位置、binlog文件位置的副本。然后,将binlog保存在 中继日志(relay log) 中,中继日志也是记录数据更新的信息。SQL线程也是在Slave中创建的,当Slave检测到中继日志有更新,就会将更新的内容同步到Slave数据库中,这样就保证了主从的数据的同步。

三、主从复制的类型
主从复制的过程有不同的策略方式进行数据的同步,主要包含以下几种:
- 「同步策略」:Master会等待所有的Slave都回应后才会提交,这个主从的同步的性能会严重的影响。
- 「半同步策略」:Master至少会等待一个Slave回应后提交。
- 「异步策略」:Master不用等待Slave回应就可以提交。
- 「延迟策略」:Slave要落后于Master指定的时间。
四、异步主从复制
4.1 一主一从主从复制
在上文操作的基础上,首先我们需要再在一个新的虚拟机上安装设置mysql,将server1上编译好的包拷贝到server2上:

将刚刚更改的两个配置文件复制到server2上去:

刚才server1的操作再在server2上再做一遍:


此时server2上的mysql初始化完成,可以正常使用:

此过程可完全按照mysql官网文档来:MySQL :: MySQL 5.7 Reference Manual :: 16 Replication
在server1上:
编辑 /etc/my.cnf :

重启mysqld使之生效:


此时已经在数据目录里生成了二进制日志文件:

此时的二进制日志文件编号为595,因为你所做的操作都会以追加的方式被记录在二进制日志文件内,而编号就是记录操作指令,595就是最后的一个编号。编号可以控制slave端复制的时候从哪开始复制。

在server2上:
在slave备机上可以不设置binlog,可以不用启用binlog。

通过 /etc/init.d/mysqld restart 重启服务。进入数据库设置:
- mysql> CHANGE MASTER TO
- -> MASTER_HOST='source_host_name',
- -> MASTER_USER='replication_user_name',
- -> MASTER_PASSWORD='replication_password',
- -> MASTER_LOG_FILE='recorded_log_file_name',
- -> MASTER_LOG_POS=recorded_log_position;


回到server1上创建数据库:

创建完成后,在server2的数据库上查看server2上也有了刚刚创建的westos库。
注:如果server1上已经建立了数据库、表或者写入了数据。那么server2上也需要先存在这些东西,这是因为二进制文件里记录的是执行的动作,从机来复制这些动作。从机里没有被操作的东西,那就无法执行动作。如果server1的mysql是全新的话,则可以直接继续设置server2。

此数据库是从server1 master上自动复制过去的,但是这种复制是单向的,一般主从复制slave端mysql都要设置成只读模式,不能在slave上写入数据,因为这样的话数据就不同步了。
各个server上的索引文件可以记录各个server上的中继日志:


4.2 一主多从主从复制(线性主从)
上面我们介绍的是一主一从架构,也有一主多从架构,一主多从架构适合于读多写少的情景,即读的请求要远远大于写的请求。我们再扩一个节点做一主多从架构。与刚刚在server2上开启mysql服务类似。下面我们搭建的是 A-->B-->C 的线性一主多从架构:


在server3上,在my.cnf中更改server-id:


此时server3上的mysql初始化完毕。由于我们server3上的数据要从server2上拿,所以在server2上要开启二进制日志文件,并且加上log-slave-updates选项:

设置完成后在server2上也创建了mysql-bin 文件。在server1上再插入数据,查看server2上的mysql-bin 发现在server1上的操作已经被记录了下来。

由于之前server1、2上的数据库已经存储了部分数据,所以我们先把其中的数据库备份出来,导入到server3中:

注:用mysqldump导入时会有一个坑,在导入同名数据库时,会先删除再导入:

先建立一个同名的库,再将数据导入进去。

原来的库导入完成!在server2上创建repl用户并寄予权限:

刷新一下授权表:

在server2上查看master status :

在server3上设置从server2复制数据库信息:
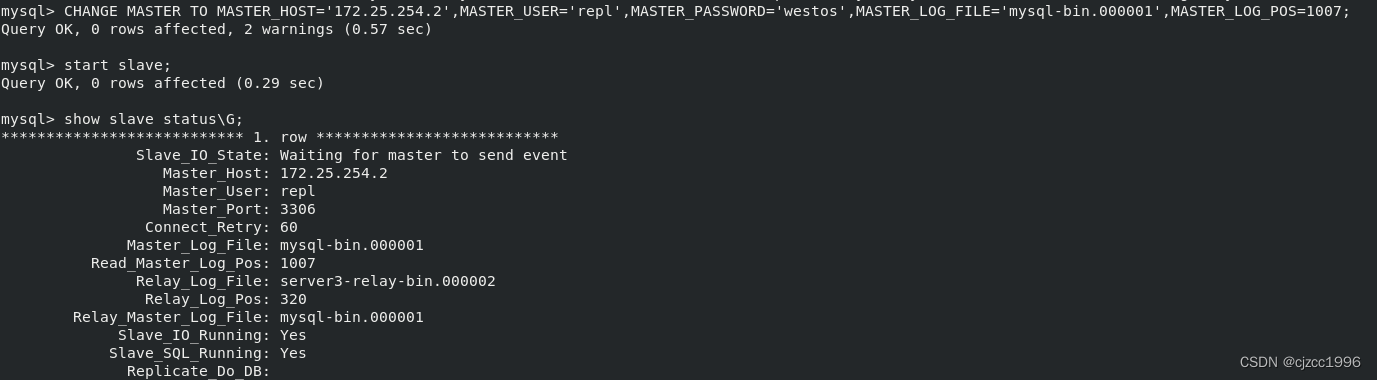
IO和SQL线程均为YES,说明设置没问题。
测试:在server1的数据库上添加信息:

我们可以直接查看server3的数据库是否复制成功,若是复制成功那么server2一定复制成功:

线性的一主多从mysql设置成功!这样设置的好处是可以减小server1端的压力。
mysql默认情况下是以异步的方式将binlog的更新发送到slave端,虽然速度很快,但是此种方式并不关心slave端是否接受到binlog信息,当网络复杂不稳定时就会出问题。
4.3 基于GTID的异步主从复制(非线性)
GTID (Golobal Transaction ID) 是对于一个已提交事务的唯一编号,并且是一个全局(主从复制)唯一的编号。
GTID 复制和传统复制的区别:在启动主从复制时,不需要指定 binlog 文件名和 postion 号,直接 auto 即可。MySQL 会自动读取最后一个 relay,获取到上次已经复制的 GTID 号,从此号码开始向后复制即可。在 MHA 高可用环境下,在主库无法 SSH 时,从库进行数据补偿更加便捷。
在GTID主从复制中,每个mysql数据库上都有一个唯一uuid,每个事务生成一个id,gtid由上面两者组合: uuid+事务id。

使用GTID方式进行主从复制,当master挂掉时,会自动切换到里自己最近的一台slave上。
在server2上关闭slave,将其配置成GTID模式,在server1上打开GTID模式:
server1:


server2:


要先关闭server2的slave端(注:该slave服务是开机自启的,设置时restart完了记得再关闭一次):

可以使用 show slave status\G; 查看slave状态。在server3上同样的配置再来一遍:


测试: 在server1上添加数据:

server2和server3上的数据已经同步。(注:此时我们server2、3的数据都是直接由server1复制来的,不是线性复制了)

当集群的master挂掉后,自动寻找最近的一个slave进行接管,slave变成master后,另外的slave在同步数据时并不需要知道此时复制的binlog号到哪了,因在在采用GTID模式时,就会自动去寻找下一个号是多少。
五、半同步主从复制
此时使用的异步主从复制还有些问题:在整体架构中,IO线程不太稳定,因为默认情况下master采用异步方式发送数据,那么slave端如果没有接受到的话会导致主从数据不一致,此时主从复制就没有存在的意义了。
半同步复制必须要求是GTID的模式。
官方半同步文档说明:MySQL :: MySQL 5.7 Reference Manual :: 16.3.9.1 Semisynchronous Replication Administrative Interface
首先,在所有的server上都要安装相应的plugin插件。
在server1 master端:

在server2、3 slave端下载插件并开启半同步模式:

可以看到我们虽然启动了半同步,但是半同步的状态还是OFF的,即还没有生效。将IO线程重启一下就生效了:

可以在mysql数据库中使用 show plugins; 查看已经安装的插件。在server1 master端设置开启半同步模式:

在master端查看半同步状态,发现已经有两个clients:

上面在mysql上设置的都是临时的热生效的方式,要开机自动生效还是要写到文件里 /etc/my.cnf:
server1 master上:

server2、3 slave上:


测试:
在master上添加数据:


半同步模式一般是要求数据无损。在半同步模式下,当master没有接收到slave端同步信息后发来的ack确认信号,master就认为slave端没有同步信息,这种情况下就能保证不会出现由于网络原因导致的数据不一致。
测试不同步:
先把两个slave端的IO线程停掉:

由于默认设置等待时间为10s,master10秒还没接收到slave发来的信息,就证明同步有问题,当10秒过后整个系统就会退回到异步模式。

当后端的两个slave恢复正常时,它会自动开启半同步模式,并且整个过程中不会有数据丢失。



After-commit异步

After-sync半同步
异步模式和半同步模式的区别在于,异步模式不管slave端是否完成同步,只要Binlog更改就做引擎提交;而半同步模式只有在接收到slave发送过来的ACK确认信号之后,才作引擎提交。注:做完引擎提交后其他所有的用户都能看到你提交的内容。
-
相关阅读:
一文搞懂 连接池,线程池,内存池,异步请求池 ,学会实现异步效果
Hive之grouping sets用法详解
深入剖析多层双向LSTM的输入输出
一文快速带你了解 KMM 、 Compose 和 Flutter 的现状
基于TM的遥感数据的叶面积指数估算解决方案及或取途径
OpenAI“杀疯了”,GPT–4o模型保姆级使用教程!一遍就会!
【Vue.js 3.0源码】Teleport 组件:如何脱离当前组件渲染子组件?
实例分割计算指标TP,FP,FN,F1(附代码)
shared library
ImageGear for .NET v26.3
- 原文地址:https://blog.csdn.net/cjzcc1996/article/details/125461122