-
【datawhale202206】pyTorch推荐系统:多任务学习 ESMM&MMOE
结论速递
多任务学习是排序模型的一种发展方式,诞生于多任务的背景。实践表明,多任务联合建模可以有效提升模型效果,因其可以:任务互助;实现隐式数据增强;学到通用表达,提高泛化能力(特别是对于一些数据不足的任务);正则化(对于一个任务而言,其他任务的学习对该任务有正则化效果)
目前的多任务联合建模有三种主要的模型形式:hard parameter sharing;soft parameter sharing (MMOE属于这种);任务序列依赖关系建模(ESMM属于这种)
本次学习涉及了两个模型:
- ESMM
ESMM考虑到传统的CVR问题(转化率)存在的问题:样本选择偏差和稀疏数据两个问题,引入任务(CTR)来丰富主任务CVR的数据,同时引入任务(CVCTR)与CTR及主任务CVR形成贝叶斯概率关系。
从而改善了样本稀疏的问题(通过引入数据丰富的CTR),也改善了样本选择偏差的问题(通过引入CVCTR及CTR在loss上形成贝叶斯公式,使得建模落到整个曝光空间)。
在具体的实现上,使用两套网络,一套学习主任务CVR,一套学习CTR,最后对Loss进行处理,Loss为pCTR及由pCTR及pCVR计算得到的pCVCTR的线性叠加。 - MMOE
MMOE则考虑到hard parameter sharing应对多任务不够灵活,需要模型解耦的问题,首先引入门控对任务加以注意,同时考虑到多任务需要分开考虑,引入多门控。使得多任务灵活组合,类似的问题一起解决。
在具体的实现上,由一样的几个DNN作为专家,同样数量的DNN作为门控,然后一起作为feature提取的输入。
前情回顾
0 多任务学习
0.1 定义
多任务学习简单来说是有多个目标函数loss同时学习,与单任务学习的对比可以见下图(来源于收藏|浅谈多任务学习(Multi-task Learning))

与 多目标学习 及 迁移学习 的概念对比如下图。
简单来说,多任务学习是迁移学习的一种,一种比较典型的多任务学习是多目标学习,而目标又分为label和class的形式。
0.2 为什么需要用多任务学习
主要有以下几个原因:
- 来源于业界需求:很多业界的推荐业务天然就是多目标的建模场景,需要多目标共同优化。
如:微信视频号推荐,首页上除了由于视频自动播放带来的“播放时长”、“完播率”(用户播放时长占视频长度的比例)目标之外,还有大量的互动标签,例如“点击好友头像”、“进入主页”、“关注”、“收藏”、“分享”、“点赞”、“评论”等。
我们在推荐的时候应当基于“用户满意度”,但“用户满意度”无法显式地表述出来。
业界一般使用“DAU”、“用户日均使用时长”、“留存率”来作为客观的间接的“用户满意度”(或者说算法工程师绩效)评价指标。而这些指标都是难以通过单一目标建模的,以使用时长为例,长视频播放长度天然大于短视频。所幸的是,虽然没有显式的用户满意度评价指标,但是现在的app都存在类似上述视频号推荐场景的丰富具体的隐式反馈。但这些独立的隐式反馈也存在一些挑战:- 目标偏差:点赞、分享表达的满意度可能比播放要高
- 物品偏差:不同视频的播放时长体现的满意度不一样,有的视频可能哄骗用户看到尾部(类似新闻推荐中的标题党)
- 用户偏差:有的用户表达满意喜欢用点赞,有的用户可能喜欢用收藏
因此我们需要使用多任务学习模型针对多个目标进行预测,并在线上融合多目标的预测结果进行排序。多任务学习也不能直接表达用户满意度,但是可以最大限度利用能得到的用户反馈信息进行充分的表征学习,并且可建模业务之间的关系,从而高效协同学习具体任务。
- 工程便利:不用针对不同的任务训练不同的模型,可以缩短多个模型独立计算的时间需求,方便控制成本。
合并之后,能更高效的利用训练资源和进行模型的迭代升级。
0.3 多任务学习为什么有效
当把业务独立建模变成多任务联合建模之后,有可能带来四种结果:

- 多个任务都出现负迁移,结果无法接受
- 部分任务效果变好,部分任务变差
- 部分任务效果变好,部分任务效果不变
- 多个任务效果都变好
但是目前来说,大多数可以实现多目标的共同提升。这样的结果是如何实现的呢?
教程中给出的原因有四个,写的比较简略,参考收藏|浅谈多任务学习(Multi-task Learning)举例理解:
- 任务互助:对于某个任务难学到的特征,可通过其他任务学习
比如任务A由于各种限制始终学不好W1,但是任务B却可以轻松将W1拟合到适合任务A所需的状态,A和B搭配,干活儿不累~。
- 隐式数据增强:不同任务有不同的噪声,一起学习可抵消部分噪声
不同任务有不同的噪声,假设不同任务噪声趋向于不同的方向,放一起学习一定程度上会抵消部分噪声,使得学习效果更好,模型也能更鲁棒。NLP和CV中经常通过数据增强的方式来提升单个模型效果,多任务学习通过引入不同任务的数据,自然而言有类似的效果。
- 学到通用表达,提高泛化能力:模型学到的是对所有任务都偏好的权重,有助于推广到未来的新任务
有些任务其实数据集是比较稀疏的,比如短视频转发,大部分人看了一个短视频是不会进行转发这个操作的,这么稀疏的行为,模型是很难学号的(过拟合问题严重),如果把那我们把预测用户是否转发这个稀疏的事情和用户是否点击观看这个经常发生事情放在一起学,一定程度上会缓解模型的过拟合,提高了模型的泛化能力。
从另一个角度来看,对于数据很少的新任务,也解决了所谓的“冷启动问题”。- 正则化:对于一个任务而言,其他任务的学习对该任务有正则化效果
多任务学习通过提供某种先验假设(inductive knowledge)来提升模型效果,这种先验假设通过增加辅助任务(具体表现为增加一个loss)来提供,相比于L1正则更方便(L1正则的先验假设是:模型参数更少更好)。
0.4 多任务学习的基本框架
这一部分内容参考收藏|浅谈多任务学习(Multi-task Learning)。
通常将多任务学习方法分为:hard parameter sharing和soft parameter sharing。区别在于对图1右边MTL那一个方块。
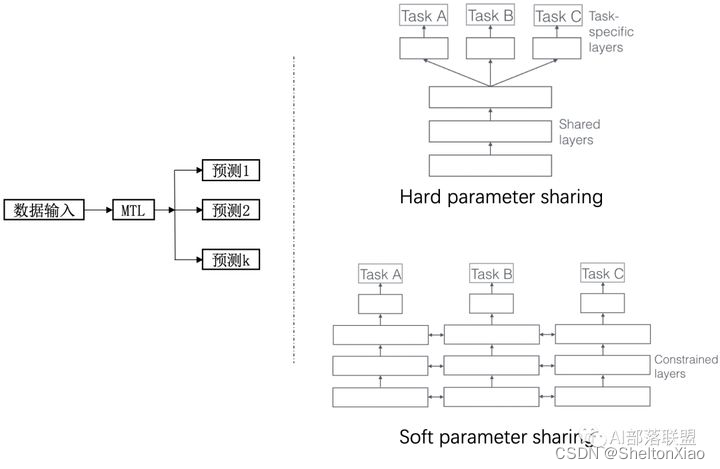
从图中可以看出,分为两种方法- hard parameter sharing(老当益壮的方法)
无论最后有多少个任务,底层参数统一共享,顶层参数各个模型各自独立。由于对于大部分参数进行了共享,模型的过拟合概率会降低,共享的参数越多,过拟合几率越小,共享的参数越少,越趋近于单个任务学习分别学习。
形象理解为:几个人在一张桌子上吃几盘菜,自己碗里有自己的饭(北方吃面的不管了先),共享的就是桌子、几盘菜,不共享的就是自己碗里的,桌子上菜越多,自己碗里的越少,吃腻的概率更小;自己碗里一自己的饭,桌子上没几个菜,一会儿饭就吃腻了orz。
- soft parameter sharing(现代研究的倾向)
底层共享一部分参数,自己还有独特的一部分参数不共享;顶层有自己的参数。所以底层共享的、不共享的参数如何融合到一起送到顶层,也就是研究人员们关注的重点啦。
这里可以放上咱们经典的MMOE模型结构,也就一目了然了。
和最左边(a)的hard sharing相比,(b)和(c)都是先对Expert0-2(每个expert理解为一个隐层神经网络就可以了)进行加权求和之后再送入Tower A和B(还是一个隐层神经网络),通过Gate(还是一个隐藏层)来决定到底加权是多少。

这边记录一个小卡片:聪明的小伙伴看到这个加权求和,是不是立刻就想到Attention啦?要不咱们把这个Gate改为一种Attention?对不同专家的Attention来决定求和权重,那你得想办法设计Attention的query啦,是个有趣的点。0.5 多任务学习的改进方向
主要集中在soft parameter sharing上,主要集中在两个方向上:
- 模型结构设计:哪些参数共享,哪些参数不共享?
又可以进一步细分为两个方向:
- 对共享层进行区分,想办法给每个任务一个独特的共享层融合方式。
以google的SNR模型为例

- 对不同任务,不同共享层级的融合方式进行设计。
以腾讯的PCG PLE网络为例

- MTL的目标loss设计和优化改进
主要解决loss数值有大有小、学习速度有快有慢、更新方向时而相反的问题。最经典的两个工作有UWL(Uncertainty Weight):通过自动学习任务的uncertainty,给uncertainty大的任务小权重,uncertainty小的任务大权重;GradNorm:结合任务梯度的二范数和loss下降梯度,引入带权重的损失函数Gradient Loss,并通过梯度下降更新该权重。
也可以直接将不同任务的loss加权融合。但这样的话本质上不是多目标建模!1 ESMM
不同的目标由于业务逻辑,有显式的依赖关系,例如曝光→点击→转化。用户必然是在商品曝光界面中,先点击了商品,才有可能购买转化。阿里提出了ESMM(Entire Space Multi-Task Model)网络,显式建模具有依赖关系的任务联合训练。该模型虽然为多任务学习模型,但本质上是以CVR为主任务,引入CTR和CTCVR作为辅助任务,解决CVR预估的挑战。
1.1 模型诞生背景
主要是针对传统的CVR问题(转化率)存在的问题:样本选择偏差和稀疏数据。具体的可以用下面这个图说明:
如下图(白色背景是曝光数据,灰色背景是点击行为数据,黑色背景是购买行为数据。传统CVR预估使用的训练样本仅为灰色和黑色的数据)

这会导致两个问题- 样本选择偏差(sample selection bias,SSB):如图所示,
CVR模型的正负样本集合={点击后未转化的负样本+点击后转化的正样本},但是线上预测的时候是样本一旦曝光,就需要预测出CVR和CTR以排序,样本集合={曝光的样本}。构建的训练样本集相当于是从一个与真实分布不一致的分布中采样得到的,这一定程度上违背了机器学习中训练数据和测试数据独立同分布的假设。 - 训练数据稀疏(data sparsity,DS):点击样本只占整个曝光样本的很小一部分,而转化样本又只占点击样本的很小一部分。如果只用点击后的数据训练CVR模型,可用的样本将极其稀疏。
1.2 ESMM模型
在这样的背景下,阿里提出了ESMM,借鉴多任务学习的思路,引入两个辅助任务CTR、CTCVR(已点击然后转化),同时消除以上两个问题。
1.2.1 多任务设计
三个预测任务具体如下:
- pCTR:
p(click=1 | impression); - pCVR(如果用户点击了,会购买的概率):
p(conversion=1 | click=1,impression); - pCTCVR(当用户已经点击的前提下,用户会购买的概率):
p(conversion=1, click=1 | impression) = p(click=1 | impression) * p(conversion=1 | click=1, impression);
以概率的形式描述的。
三个任务之间的关系为:

其中x表示曝光,y表示点击,z表示转化。1.2.2 模型设计
针对这三个任务,设计了如图所示的模型结构:

可以看出特点是:- 分主任务和辅助任务,主任务和辅助任务共享特征,不同任务输出层使用不同的网络
(显然不直接属于0.5提到的方向)
具体为(这里提供了一个前面没有提到的引入CTR的原因:就是主任务CVR数据太稀疏,引入一个数据更丰富的任务来提供一些基础知识)
提供特征表达的迁移学习(embedding层共享)。
CVR和CTR任务的两个子网络共享embedding层,网络的embedding层把大规模稀疏的输入数据映射到低维的表示向量,该层的参数占了整个网络参数的绝大部分,需要大量的训练样本才能充分学习得到。由于CTR任务的训练样本量要大大超过CVR任务的训练样本量,ESMM模型中特征表示共享的机制能够使得CVR子任务也能够从只有展现没有点击的样本中学习,从而能够极大地有利于缓解训练数据稀疏性问题。- 损失函数有特别的设计:将cvr的预测值*ctr的预测值作为ctcvr任务的预测值,利用ctcvr和ctr的label构造损失函数
也就是cvr不显式(指单独作为一项)出现在损失函数中

这样做可以帮助CVR模型在完整样本空间建模,引入贝叶斯公式(条件概率)来说明这一点:

pCVR 可以由pCTR 和pCTCVR推导出。从原理上来说,相当于分别单独训练两个模型拟合出pCTR 和pCTCVR,再通过pCTCVR 除以pCTR 得到最终的拟合目标pCVR 。在训练过程中,模型只需要预测pCTCVR和pCTR,利用两种相加组成的联合loss更新参数。pCVR 只是一个中间变量。而pCTCVR和pCTR的数据是在完整样本空间中提取的,从而相当于pCVR也是在整个曝光样本空间中建模。
用自己的话简单小结:
引入任务(CTR)来丰富主任务CVR的数据,同时考虑到任务(CVCTR)与CTR及主任务CVR的贝叶斯概率关系,也引入。
这样既改善了样本稀疏的问题(通过引入数据丰富的CTR),也改善了样本选择偏差的问题(通过引入CVCTR及CTR在loss上形成贝叶斯公式,使得建模落到整个曝光空间)。这一种多任务学习的模式综合了hard parameter sharing的底层sharing和soft parameter sharing对于loss的改造,但又不完全一样,可以单独称为任务序列依赖关系建模,适用于不同任务之间有一定依赖关系的场景。
1.2.3 模型思考
- 能不能将乘法换成除法?
其实考虑到引入CTR及CVCTR的逻辑,模型的构成方式显然不止ESMM一种,除法也是可行的(就是指把单独训练CTR,CVCTR为目标的模型,然后相除)。这里不这样做的原因是pCTR通常比较小,数值容易不稳定。
论文提供了消融实验的结果,表中的DIVISION模型,比起BASE模型直接建模CTCVRR和CVR,有显著提高,但低于ESMM。原因是pCTR 通常很小,除以一个很小的浮点数容易引起数值不稳定问题。
- 网络结构优化,Tower模型更换?两个塔不一致?
这里的基模型采用的是纯MLP模型,事实上业界在使用过程中一般会采用更为先进的模型(例如DeepFM、DIN等),两个塔也完全可以根据自身特点设置不一样的模型。这也是ESMM框架的优势,子网络可以任意替换,非常容易与其他学习模型集成。
ESMM是个框架! - 比loss直接相加更好的方式?
loss直接相加其实也不是严格的多目标问题,真多目标效果可能会更好,所以可以考虑引入动态加权学习机制。 - 更长的序列依赖建模?
有些业务的依赖关系不止有曝光-点击-转化三层,后续的改进模型提出了更深层次的任务依赖关系建模。
阿里的ESMM2: 在点击到购买之前,用户还有可能产生加入购物车(Cart)、加入心愿单(Wish)等行为。

相较于直接学习 click->buy (稀疏度约2.6%),可以通过Action路径将目标分解,以Cart为例:click->cart (稀疏 度为10%),cart->buy(稀疏度为12%),通过分解路径,建立多任务学习模型来分步求解CVR模型,缓解稀疏问题,该模型同样也引入了特征共享机制。1.3 代码实践
1.3.1 基于tf.keras实现
ESMM的实现主要有四个需要关注的点:
- 模型结构:共享底层机制,之后两个独立的Tower网络,分别输出CVR和CTR;
- loss计算:计算loss时只利用CTR与CTCVR的loss;
- 网络更新:CVR Tower完成自身网络更新,CTR Tower同时完成自身网络和Embedding参数更新;
- 模型评估:在评估模型性能时,重点是评估主任务CVR的auc。
下面的代码是用tf.keras实现ESMM
def ESSM(dnn_feature_columns, task_type='binary', task_names=['ctr', 'ctcvr'], tower_dnn_units_lists=[[128, 128],[128, 128]], l2_reg_embedding=0.00001, l2_reg_dnn=0, seed=1024, dnn_dropout=0,dnn_activation='relu', dnn_use_bn=False): features = build_input_features(dnn_feature_columns) inputs_list = list(features.values()) # 拼接sparse和dense输入特征 sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns, l2_reg_embedding,seed) # 模型输入层(也是DNN输入层) dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list) # DNN输出层 ctr_output = DNN(tower_dnn_units_lists[0], dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(dnn_input) cvr_output = DNN(tower_dnn_units_lists[1], dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(dnn_input) # Dense层 ctr_logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(ctr_output) cvr_logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(cvr_output) ctr_pred = PredictionLayer(task_type, name=task_names[0])(ctr_logit) cvr_pred = PredictionLayer(task_type)(cvr_logit) # 计算ctcvr ctcvr_pred = tf.keras.layers.Multiply(name=task_names[1])([ctr_pred, cvr_pred])#CTCVR = CTR * CVR model = tf.keras.models.Model(inputs=inputs_list, outputs=[ctr_pred, cvr_pred, ctcvr_pred]) return model- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
注意上述代码,并未实现论文模型图中提到的field element-wise +模块。该模块实现较为简单,即分别把用户、商品相关特征的embedding求和再拼接,然后输入Tower网络。我们使用数据不具有该属性,暂未区分。
1.3.2 基于rechub的实现
详见github。
首先处理输入特征
from torch_rechub.models.multi_task import ESMM from torch_rechub.basic.features import DenseFeature, SparseFeature col_names = data.columns.values.tolist() dense_cols = ['D109_14', 'D110_14', 'D127_14', 'D150_14', 'D508', 'D509', 'D702', 'D853'] sparse_cols = [col for col in col_names if col not in dense_cols and col not in ['cvr_label', 'ctr_label']] print("sparse cols:%d dense cols:%d" % (len(sparse_cols), len(dense_cols)))- 1
- 2
- 3
- 4
- 5
- 6
- 7
对特征重新命名
label_cols = ['cvr_label', 'ctr_label', "ctcvr_label"] #the order of 3 labels must fixed as this used_cols = sparse_cols #ESMM only for sparse features in origin paper item_cols = ['129', '205', '206', '207', '210', '216'] #assumption features split for user and item user_cols = [col for col in used_cols if col not in item_cols] user_features = [SparseFeature(col, data[col].max() + 1, embed_dim=16) for col in user_cols] item_features = [SparseFeature(col, data[col].max() + 1, embed_dim=16) for col in item_cols]- 1
- 2
- 3
- 4
- 5
- 6
再调用模型定义。其中对应的参数为:
user_features指用户侧的特征,只能传入sparse类型(论文中需要分别对user和item侧的特征进行sum_pooling操作)item_features指用item侧的特征,只能传入sparse类型cvr_params指定CVR Tower中MLP层的参数ctr_params指定CTR Tower中MLP层的参数
model = ESMM(user_features, item_features, cvr_params={"dims": [16, 8]}, ctr_params={"dims": [16, 8]})- 1
为了完成训练,需要构建dataloader
构建dataloader通常由
- 构建输入字典(字典的键为定义模型时采用的特征名,值为对应特征的数据)
- 通过字典构建相应的dataset和dataloader
这里借助rechub内置类
DataGenerator实现:from torch_rechub.utils.data import DataGenerator x_train, y_train = {name: data[name].values[:train_idx] for name in used_cols}, data[label_cols].values[:train_idx] x_val, y_val = {name: data[name].values[train_idx:val_idx] for name in used_cols}, data[label_cols].values[train_idx:val_idx] x_test, y_test = {name: data[name].values[val_idx:] for name in used_cols}, data[label_cols].values[val_idx:] dg = DataGenerator(x_train, y_train) train_dataloader, val_dataloader, test_dataloader = dg.generate_dataloader(x_val=x_val, y_val=y_val, x_test=x_test, y_test=y_test, batch_size=1024)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
对于多任务的训练,需要设置任务类型,优化器超参数和优化策略。借助
MLTrainer实现。from torch_rechub.trainers import MTLTrainer device = 'cuda' if torch.cuda.is_available() else 'cpu' learning_rate = 1e-3 epoch = 1 #10 weight_decay = 1e-5 save_dir = '../examples/ranking/data/ali-ccp/saved' if not os.path.exists(save_dir): os.makedirs(save_dir) #任务类型定义 task_types = ["classification", "classification"] #CTR与CVR均为二分类任务 mtl_trainer = MTLTrainer(model, task_types=task_types, optimizer_params={"lr": learning_rate, "weight_decay": weight_decay}, n_epoch=epoch, earlystop_patience=1, device=device, model_path=save_dir) mtl_trainer.fit(train_dataloader, val_dataloader) auc = mtl_trainer.evaluate(mtl_trainer.model, test_dataloader)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2 MMOE
MMOE是2018年谷歌提出的,全称是Multi-gate Mixture-of-Experts, 对于多个优化任务,引入了多个专家进行不同的决策和组合,最终完成多目标的预测。解决的是硬共享里面如果多个任务相似性不是很强,底层的embedding学习反而相互影响,最终都学不好的痛点。
2.1 模型诞生背景
综合前面的0.4和1.2.2,可以小结多任务模型的三种范式:
- hard parameter sharing
这种方法最大的优势是Task越多, 单任务更加不可能过拟合,即可以减少任务之间过拟合的风险。 但是劣势也非常明显,就是底层强制的shared layers难以学习到适用于所有任务的有效表达。 尤其是任务之间存在冲突的时候。 - soft parameter sharing
在多任务学习时,给不同的tower分配不同的权重,那么这样对于不同的任务,可以允许使用底层不同的专家组合去进行预测,相较于上面所有任务共享底层,这个方式显得更加灵活 - 任务序列依赖关系建模
MMOE提出的动机之一,在于应对hard parameter sharing的一个问题:不能很好的权衡特定任务的目标与任务之间的冲突关系。
2.2 MMOE模型的理论及细节
模型结构如下:
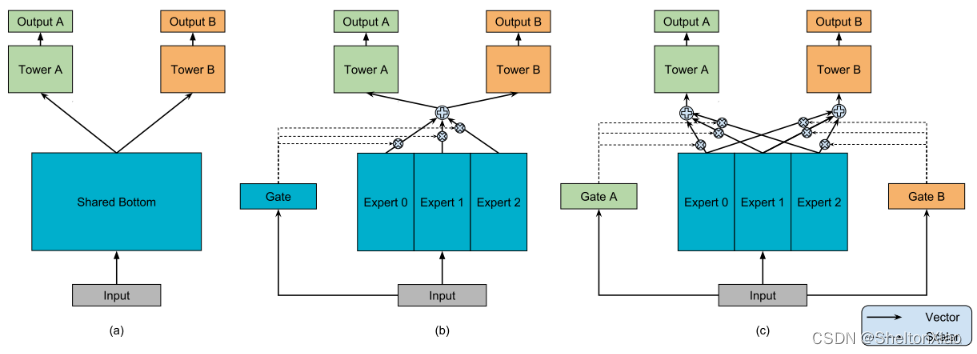
2.2.1 混合专家模型MOE
首先来谈谈MOE,就是对应结构图中间的那个。
常规的hard parameter sharing可以视为共享的专家,任务之间可能无法很好地收敛,就无法训练出一个很好的专家。那么,多个专家如何呢?
抛开任务关系, 我们发现一个专家在多任务学习上的表达能力很有限,于是乎,尝试引入多个专家,这就慢慢的演化出了混合专家模型。
MMOE模型的第一个特点就是:混合专家模型
公式表达如下
y = ∑ i = 1 n g ( x ) i f i ( x ) y= \sum_{i=1}^{n}{g(x)_i f_i(x)} y=i=1∑ng(x)ifi(x)其中
f i ( x ) f_i(x) fi(x)
是每个专家的输出在此基础上再加上一个门控网络机制,就是注意力网络,来学习各个专家对应的权重 ∑ i = 1 n g ( x ) i \sum_{i=1}^{n}g(x)_i i=1∑ng(x)i
虽然感觉这个东西,无非就是在单个专家的基础上多引入了几个全连接网络,然后又给这几个全连接网络加权,但其中蕴含了好几个厉害的思路。
- 模型集成思想: 这个东西很像bagging的思路,即训练多个模型进行决策,这个决策的有效性显然要比单独一个模型来的靠谱一点,不管是从泛化能力,表达能力,学习能力上,应该都强于一个模型
- 注意力思想: 为了增加灵活性, 为不同的模型还学习了重要性权重,这可能考虑到了在学习任务的共性模式上, 不同的模型学习的模式不同,那么聚合的时候,显然不能按照相同的重要度聚合,所以为各个专家学习权重,默认了不同专家的决策地位不一样。这个思想目前不过也非常普遍了。
- multi-head机制: 从另一个角度看, 多个专家其实代表了多个不同head, 而不同的head代表了不同的非线性空间,之所以说表达能力增强了,是因为把输入特征映射到了不同的空间中去学习任务之间的共性模式。可以理解成从多个角度去捕捉任务之间的共性特征模式。
思考:教程的理解其实蛮有意思的,但是和前面看到的收藏|浅谈多任务学习(Multi-task Learning)的理解,其实这里可能是注意力思想的体现,但是不能称为注意力机制,注意力机制更注重一个实现的过程(query的设计)?
到此为止,就是MOE,混合专家模型,但是MOE只包含一个门控,一个门控并不是很灵活。
因为这所有的任务,最终只能选定一组专家组合,即这个专家组合是在多个任务上综合衡量的结果,并没有针对性了。 如果这些任务都比较相似,那就相当于用这一组专家组合确实可以应对这多个任务,学习到多个相似任务的共性。 但如果任务之间差的很大,这种单门控控制的方式就不行了,因为此时底层的多个专家学习到的特征模式相差可能会很大,毕竟任务不同,而单门控机制选择专家组合的时候,肯定是选择出那些有利于大多数任务的专家, 而对于某些特殊任务,可能学习的一塌糊涂。
这里感觉依然可以理解为真多目标和伪多目标的区别。
2.2.2 MMOE结构
Multi-gate Mixture-of-Experts(MMOE)在MOE的基础上,对于每个任务都会涉及一个门控网络,对应结构图右边的那个。
这样,对于每个特定的任务,都能有一组对应的专家组合去进行预测。更关键的是,参数量还不会增加太多。公式如下:
y k = h k ( f k ( x ) ) y_k = h^k (f ^k(x)) yk=hk(fk(x))
其中
f k ( x ) = ∑ i = 1 n g k ( x ) i f i ( x ) f ^k(x)= \sum_{i=1}^{n}{g^k(x)_i f_i(x)} fk(x)=i=1∑ngk(x)ifi(x)
k k k表示任务的个数。每个门控网络都是一个注意力网络:
g k ( x ) = s o f t m a x ( W g k x ) g^k(x) = softmax(W_{gk}x) gk(x)=softmax(Wgkx)
W g k W_{gk} Wgk表示权重矩阵, n n n是专家的个数, d d d是特征的维度。教程分享了一些理解
- MMOE是针对每个任务都单独有个门控选择专家组合,那么即使任务冲突了,也能根据不同的门控进行调整,选择出对当前任务有帮助的专家组合。所以,我觉得单门控做到了针对所有任务在专家选择上的解耦,而多门控做到了针对各个任务在专家组合选择上的解耦。
- 多门控机制能够建模任务之间的关系了。如果各个任务都冲突, 那么此时有多门控的帮助, 此时让每个任务独享一个专家,如果任务之间能聚成几个相似的类,那么这几类之间应该对应的不同的专家组合,那么门控机制也可以选择出来。如果所有任务都相似,那这几个门控网络学习到的权重也会相似,所以这种机制把任务的无关,部分相关和全相关进行了一种统一。
- 灵活的参数共享, 这个我们可以和hard模式或者是针对每个任务单独建模的模型对比,对于hard模式,所有任务共享底层参数,而每个任务单独建模,是所有任务单独有一套参数,算是共享和不共享的两个极端,对于都共享的极端,害怕任务冲突,而对于一点都不共享的极端,无法利用迁移学习的优势,模型之间没法互享信息,互为补充,容易遭受过拟合的困境,另外还会增加计算量和参数量。 而MMOE处于两者的中间,既兼顾了如果有相似任务,那就参数共享,模式共享,互为补充,如果没有相似任务,那就独立学习,互不影响。 又把这两种极端给进行了统一。
- 训练时能快速收敛,这是因为相似的任务对于特定的专家组合训练都会产生贡献,这样进行一轮epoch,相当于单独任务训练时的多轮epoch。
理解好像有点点绕路了,其实可能确实是一个大道至简的想法,多任务需要模型解耦,就引入单门控专家,多任务需要专家解耦,就多门控专家。这样使得多任务灵活组合,类似的问题一起解决。专家负责问题共性学习,门控判断是否共性?
为什么多任务学习为什么是有效的呢? 这里整理一个看到比较不错的答案:
多任务学习有效的原因是引入了归纳偏置,两个效果:- 互相促进: 可以把多任务模型之间的关系看作是互相先验知识,也称为归纳迁移,有了对模型的先验假设,可以更好提升模型的效果。解决数据稀疏性其实本身也是迁移学习的一个特性,多任务学习中也同样会体现
- 泛化作用:不同模型学到的表征不同,可能A模型学到的是B模型所没有学好的,B模型也有其自身的特点,而这一点很可能A学不好,这样一来模型健壮性更强
这个小卡片回顾了前面0.3的内容哈。
2.3 代码实现
2.3.1 基于torch.nn的MMOE复现
实现涉及几个要点:
- 模型输入:sparse feature和dense feature数据封装一起处理
- 多专家:都是DNN
- 多门控网络:门控网络个数和任务数相同,门控网络也是DNN,接收输入,得到专家个输出作为每个专家的权重,把每个专家的输出加权组合得到门控网络最终的输出,放到列表中作为下一步的输入
- feature学习(毕竟是排序模型):为每个任务建立tower,学习特定的feature信息。同样也是DNN;最后得到最终的输出。
具体代码如下:
def MMOE(dnn_feature_columns, num_experts=3, expert_dnn_hidden_units=(256, 128), tower_dnn_hidden_units=(64,), gate_dnn_hidden_units=(), l2_reg_embedding=0.00001, l2_reg_dnn=0, dnn_dropout=0, dnn_activation='relu', dnn_use_bn=False, task_types=('binary', 'binary'), task_names=('ctr', 'ctcvr')): num_tasks = len(task_names) # 构建Input层并将Input层转成列表作为模型的输入 input_layer_dict = build_input_layers(dnn_feature_columns) input_layers = list(input_layer_dict.values()) # 筛选出特征中的sparse和Dense特征, 后面要单独处理 sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns)) dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), dnn_feature_columns)) # 获取Dense Input dnn_dense_input = [] for fc in dense_feature_columns: dnn_dense_input.append(input_layer_dict[fc.name]) # 构建embedding字典 embedding_layer_dict = build_embedding_layers(dnn_feature_columns) # 离散的这些特特征embedding之后,然后拼接,然后直接作为全连接层Dense的输入,所以需要进行Flatten dnn_sparse_embed_input = concat_embedding_list(sparse_feature_columns, input_layer_dict, embedding_layer_dict, flatten=False) # 把连续特征和离散特征合并起来 dnn_input = combined_dnn_input(dnn_sparse_embed_input, dnn_dense_input) # 建立专家层 expert_outputs = [] for i in range(num_experts): expert_network = DNN(expert_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=2022, name='expert_'+str(i))(dnn_input) expert_outputs.append(expert_network) expert_concat = Lambda(lambda x: tf.stack(x, axis=1))(expert_outputs) # 建立多门控机制层 mmoe_outputs = [] for i in range(num_tasks): # num_tasks=num_gates # 建立门控层 gate_input = DNN(gate_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=2022, name='gate_'+task_names[i])(dnn_input) gate_out = Dense(num_experts, use_bias=False, activation='softmax', name='gate_softmax_'+task_names[i])(gate_input) gate_out = Lambda(lambda x: tf.expand_dims(x, axis=-1))(gate_out) # gate multiply the expert gate_mul_expert = Lambda(lambda x: reduce_sum(x[0] * x[1], axis=1, keep_dims=False), name='gate_mul_expert_'+task_names[i])([expert_concat, gate_out]) mmoe_outputs.append(gate_mul_expert) # 每个任务独立的tower task_outputs = [] for task_type, task_name, mmoe_out in zip(task_types, task_names, mmoe_outputs): # 建立tower tower_output = DNN(tower_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=2022, name='tower_'+task_name)(mmoe_out) logit = Dense(1, use_bias=False, activation=None)(tower_output) output = PredictionLayer(task_type, name=task_name)(logit) task_outputs.append(output) model = Model(inputs=input_layers, outputs=task_outputs) return model- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
2.3.2 基于rechub的实现
详见github。
训练MMOE模型的流程与ESMM模型十分相似
需要注意的是MMOE模型同时支持dense和sparse特征作为输入,以及支持分类和回归任务混合。
from torch_rechub.models.multi_task import MMOE # 定义模型 used_cols = sparse_cols + dense_cols features = [SparseFeature(col, data[col].max()+1, embed_dim=4)for col in sparse_cols] \ + [DenseFeature(col) for col in dense_cols] model = MMOE(features, task_types, 8, expert_params={"dims": [16]}, tower_params_list=[{"dims": [8]}, {"dims": [8]}]) #构建dataloader label_cols = ['cvr_label', 'ctr_label'] x_train, y_train = {name: data[name].values[:train_idx] for name in used_cols}, data[label_cols].values[:train_idx] x_val, y_val = {name: data[name].values[train_idx:val_idx] for name in used_cols}, data[label_cols].values[train_idx:val_idx] x_test, y_test = {name: data[name].values[val_idx:] for name in used_cols}, data[label_cols].values[val_idx:] dg = DataGenerator(x_train, y_train) train_dataloader, val_dataloader, test_dataloader = dg.generate_dataloader(x_val=x_val, y_val=y_val, x_test=x_test, y_test=y_test, batch_size=1024) #训练模型及评估 mtl_trainer = MTLTrainer(model, task_types=task_types, optimizer_params={"lr": learning_rate, "weight_decay": weight_decay}, n_epoch=epoch, earlystop_patience=30, device=device, model_path=save_dir) mtl_trainer.fit(train_dataloader, val_dataloader) auc = mtl_trainer.evaluate(mtl_trainer.model, test_dataloader)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
3 总结
多任务学习是排序模型的一种发展方式,诞生于多任务的背景。
实践表明,多任务联合建模可以有效提升模型效果,因其可以:
- 任务互助
- 实现隐式数据增强
- 学到通用表达,提高泛化能力(特别是对于一些数据不足的任务)
- 正则化(对于一个任务而言,其他任务的学习对该任务有正则化效果)
目前的多任务联合建模有三种主要的模型形式:
- hard parameter sharing
- soft parameter sharing :MMOE属于这种
- 任务序列依赖关系建模:ESMM属于这种
本次学习涉及了两个模型:
- ESMM
ESMM考虑到传统的CVR问题(转化率)存在的问题:样本选择偏差和稀疏数据两个问题,引入任务(CTR)来丰富主任务CVR的数据,同时引入任务(CVCTR)与CTR及主任务CVR形成贝叶斯概率关系。
从而改善了样本稀疏的问题(通过引入数据丰富的CTR),也改善了样本选择偏差的问题(通过引入CVCTR及CTR在loss上形成贝叶斯公式,使得建模落到整个曝光空间)。
在具体的实现上,使用两套网络,一套学习主任务CVR,一套学习CTR,最后对Loss进行处理,Loss为pCTR及由pCTR及pCVR计算得到的pCVCTR的线性叠加。 - MMOE
MMOE则考虑到hard parameter sharing应对多任务不够灵活,需要模型解耦的问题,首先引入门控对任务加以注意,同时考虑到多任务需要分开考虑,引入多门控。使得多任务灵活组合,类似的问题一起解决。
在具体的实现上,由一样的几个DNN作为专家,同样数量的DNN作为门控,然后一起作为feature提取的输入。
参考阅读
- ESMM
-
相关阅读:
ubuntu部署k8s
【毕业设计】基于Stm32的人体心率脉搏无线监测系统 - 单片机 物联网
学习嵌入式可以胜任哪一些行业?
【WinMTR】Windows上winmtr的安装使用方法
iOS16.1开发者预览版Beta3发布:优化壁纸功能
Stream流中的Map与flatMap的区别
C语言经典算法实例3:数组元素排序
2022年湖北劳务资质办理需要准备什么资料?办理劳务需要注意哪些呢?甘建二
STM32F1读取MLX90632非接触式红外温度传感器
Linux安装Samba服务,基于Fedora
- 原文地址:https://blog.csdn.net/qq_40990057/article/details/125492013
