-
springboot集成整合kafka
前言
先去spring官网查看一下版本兼容情况 spring.io,了解用法。

同时也可以从文档中获取更多的最新信息和版本差别体现,比如不同版本创建主题的方式,消息回调的方式等等 Apache Kafka spring官方文档项目搭建
配置依赖
核心依赖<dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency>- 1
- 2
- 3
- 4
yml配置spring: kafka: bootstrap-servers: 192.168.150.129:9092 producer: # 消息序列化 key-serializer: org.apache.kafka.common.serialization.StringSerializer value-serializer: org.apache.kafka.common.serialization.StringSerializer retries: 0 # 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1) acks: 1 #每当多个记录被发送到同一分区时,生产者将尝试将记录一起批量处理为更少的请求,默认值为16384(单位字节) batch-size: 16384 #生产者可用于缓冲等待发送到服务器的记录的内存总字节数,默认值为3355443 buffer-memory: 33554432 consumer: #用于标识此使用者所属的使用者组的唯一字符串,默认消费组,也可以不指定,直接在监听器中指定 group-id: test-group # earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费 # latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据 # none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常 auto-offset-reset: earliest #消费者的偏移量将在后台定期提交,默认值为true enable-auto-commit: false #如果'enable-auto-commit'为true,则消费者偏移自动提交给Kafka的频率(以毫秒为单位),默认值为5000。 auto-commit-interval: 100 #密钥的反序列化器类,实现类实现了接口org.apache.kafka.common.serialization.Deserializer key-deserializer: org.apache.kafka.common.serialization.StringDeserializer #值的反序列化器类,实现类实现了接口org.apache.kafka.common.serialization.Deserializer value-deserializer: org.apache.kafka.common.serialization.StringDeserializer listener: #手动ack消息确认机制,手动调用Acknowledgment.acknowledge()后立即提交,一般使用这种 ack-mode: manual_immediate- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
提示:消息序列化这里用的是自带的,你也可以自己实现,主要继承 Serializer 和 Deserializer接口即可,然后在yml配置类路径即可提示如果kafka安装位置不在本机,注意一下几点,否则项目会连不上kafka:
1、记得开放9092端口,重启防火墙;
2、一定要修改kafka服务端配置文件server.properties中的这两个属性,来允许外网连接。

创建主题、生产、消费者
创建主题topic/** * @author: zhouwenjie * @description: * @create: 2022-05-23 17:37 **/ @Component public class KafkaTopic { @Bean public NewTopic topic1() { return TopicBuilder.name("test_topic1") .build(); } @Bean public NewTopic topic2() { return TopicBuilder.name("test_topic2") .replicas(1) .build(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
创建测试接口/** * @author: zhouwenjie * @description: * @create: 2022-05-23 17:48 **/ @RestController @RequestMapping("/kafka") public class KafkaProducerController { @Autowired private KafkaTemplate<String, String> kafkaTemplate; @RequestMapping("/kafkaSend") @Transactional public void add2(@RequestParam(name = "topicName") String topicName, @RequestParam(name = "value") String value) { //从 2.5 版开始,您可以使用 aKafkaSendCallback而不是 ListenableFutureCallback,从而更容易提取 failed ProducerRecord,避免需要强制转换Throwable kafkaTemplate.send(topicName,value).addCallback(new KafkaSendCallback<String,String>(){ @Override public void onSuccess(SendResult<String, String> result) { System.out.println("消费发送成功 offset:" + result.getRecordMetadata().offset()); } @Override public void onFailure(KafkaProducerException ex) { ProducerRecord<Object, Object> record = ex.getFailedProducerRecord(); } }); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
当然如果你不想每次发消息都写回调的重复逻辑代码,我们可以继承
ProducerListener,重写回调逻辑编写通用回调逻辑
/** * @author: zhouwenjie * @description: * @create: 2022-05-23 17:59 **/ @Component public class MyProducerListener implements ProducerListener<String,String> { @Override public void onSuccess(ProducerRecord<String, String> producerRecord, RecordMetadata recordMetadata) { System.out.println("消费发送成功 offset:" + recordMetadata.offset()); } @Override public void onError(ProducerRecord<String, String> producerRecord, Exception exception) { System.out.println("消费发送失败 内容:" + producerRecord.value()+",消费发送失败 分区:" + producerRecord.partition()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
注入bin
@Bean public KafkaTemplate<String, String> stringTemplate(MyProducerListener myProducerListener,ProducerFactory<String, String> pf) { KafkaTemplate<String, String> kafkaTemplate = new KafkaTemplate<String, String>(pf); kafkaTemplate.setProducerListener(myProducerListener); return kafkaTemplate; }- 1
- 2
- 3
- 4
- 5
- 6
修改生产者接口代码
/** * @author: zhouwenjie * @description: * @create: 2022-05-23 17:48 **/ @RestController @RequestMapping("/kafka") public class KafkaProducerController { @Autowired private KafkaTemplate<String, String> kafkaTemplate; @RequestMapping("/kafkaSend") @Transactional public void add2(@RequestParam(name = "topicName") String topicName, @RequestParam(name = "value") String value) { kafkaTemplate.send(topicName,value); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
如此即可实现回调逻辑的提取。
创建消费者/** * @author: zhouwenjie * @description: * @create: 2022-05-23 11:53 **/ @Component public class KafkaConsumer { @KafkaListener(topics = "test_topic1") public void consumer1(ConsumerRecord<String, String> record, Acknowledgment ack) throws InterruptedException { System.out.println("===================================================================================="); System.out.println("监听test_topic1"); System.out.println(LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")) + "接收到kafka消息,partition:" + record.partition() + ",offset:" + record.offset() + "value:" + record.value()); TimeUnit.SECONDS.sleep(1); ack.acknowledge(); } @KafkaListener(topics = "test_topic2") public void consumer2(ConsumerRecord<String, String> record, Acknowledgment ack) throws InterruptedException { System.out.println("===================================================================================="); System.out.println("监听test_topic2"); System.out.println(LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")) + "接收到kafka消息,partition:" + record.partition() + ",offset:" + record.offset() + "value:" + record.value()); TimeUnit.SECONDS.sleep(1); ack.acknowledge(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
测试
访问接口测试

分区策略详解
分区概念
简而言之:分区就是对topic主题的划分,为了实现更高的吞吐率,发送给主题的消息将会被划分到不同的分区里,也就是说,主题是由多个分区组成的。

设置分区数量
进入kafka安装目录,修改
server.properties,默认是1,可以根据需要修改成合适的值,记住,分区并不是越多越好,要根据机器的性能来测试出最佳参数,可以参考 Kafka分区数量设置详解。

注意:这里设置的是自动创建主题下的默认分区数量,如果你是手动创建主题,则不生效。
自动创建:也就是说生产者在发消息之前,并没有创建主题,主题由系统根据指定的主题名称自动创建;
手动创建:在项目启动或者命令行创建主题的时候,指定分区数量,不指定默认为1。以下为手动创建示例:
bin/kafka-topics.sh --create --topic quickstart-events --partitions 4 --replication-factor 2 --bootstrap-server localhost:9092- 1
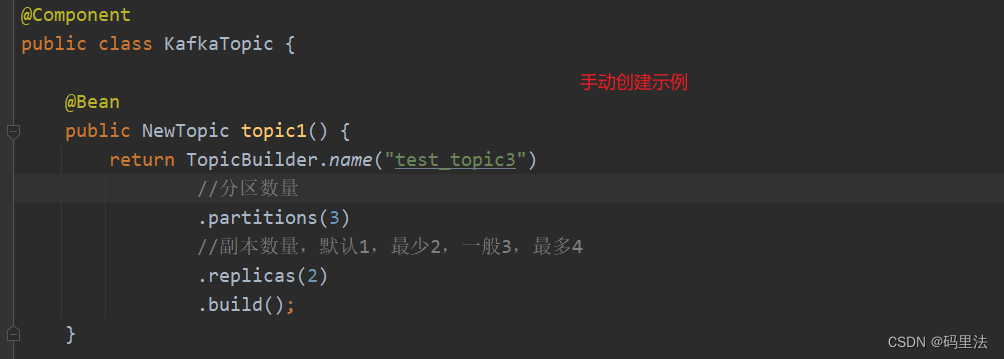
小提示:设置分区和副本数量的时候,切记复制因子比broker 代理个数大 , 则会报错(Replication factor: 2 larger than available brokers: 1)。
其中副本数量就是复制因子,服务器集群数量就是broker 代理。
例如我现在只在一台机器上部署了kafka,那么replicas只能设置为1,或者不设置,默认为1,像上图所示设置就会报错。以下为自动创建示例:
bin/kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092- 1
直接发送不提前创建主题

直接监听不提前创建主题

控制台查看结果

分区策略
这里的分区策略主要针对消费者而言的。
默认策略默认分区策略分为三种:RoundRobinAssignor、 RangeAssignor(默认) 、StickyAssignor

- RoundRobinAssignor
轮询策略
适用于消费者订阅的主题都是一样的,也就是说三个消费者全部订阅三个主题,如果订阅不一致,则不适用。- RangeAssignor(默认)
按照消费者总数和分区总数进行整除运算来获得一个跨度,具体计算方法:
假设消费者数量为N,主题分区数量为M,则有当前主题分配数量 = M%N==0? M/N +1 : M/N
不适用于:主题多并且分区无法均分。- StickyAssignor
目标一:分区的分配要尽可能的均匀,分配给消费者者的主题分区数最多相差一个;
目标二:分区的分配尽可能的与上次分配的保持相同。
当两者发生冲突时,第一个目标优先于第二个目标。
鉴于这两个目标,StickyAssignor策略的具体实现 要比RangeAssignor和RoundRobinAssignor这两种分配策略要复杂很多,所以如果主题不多,分区不多的情况下,尽量选择前两种策略。自定义策略
需自行实现 AbstractPartitionAssignor。更详细的讲解可以参考
kafka的分区详解
kafka的消费者分区分配策略修改分区策略-yml形式

项目启动日志分区展示消费者监听逻辑:

注意这里的groupId指定的是消费组,而消费者就是每个监听的方法,也就是上文参考文章中的C0,C1,只不过为了方便讲解区分开来,本质还是属于一个消费组的。
可以看到控制台的输出如下:

生产者分区策略配置分区策略既有消费者端的,也有生者端的 具体参考这里 Kafka分区策略
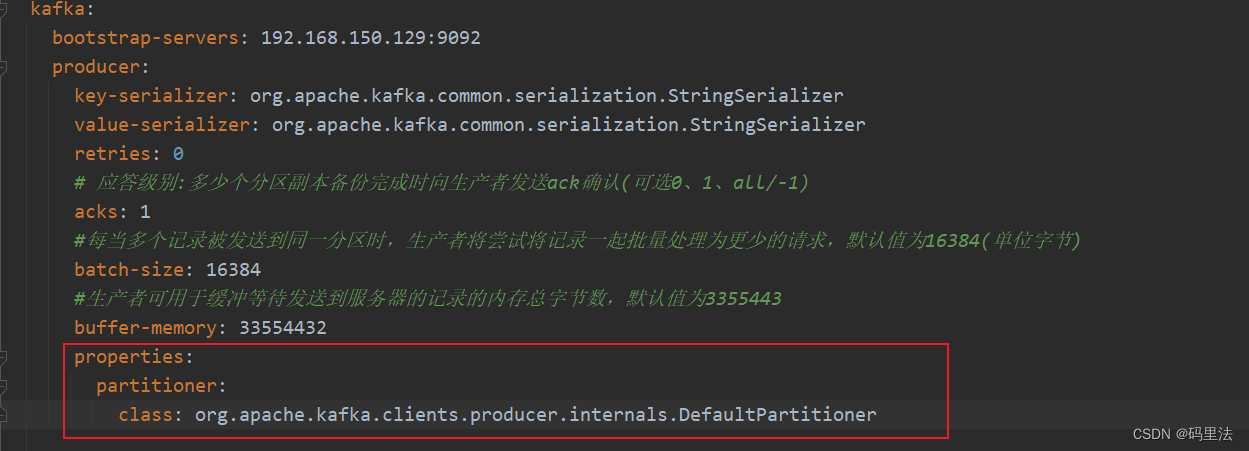
yml配置的怎么写,主要参考这两个配置类的参数。

找到partition相关的参数,比如下边的生产者参数配置

之后直接在yml中配置即可
-
相关阅读:
LabVIEW编程LabVIEW控制C-863.12 水星控制器例程与相关资料
Dockerfile 简介
RHCE之WEB服务器作业
【游戏开发】《Java游戏服务器架构实战》项目在windows上部署
分布式 PostgreSQL 集群(Citus),官方快速入门教程
面向多段落高考阅读理解的答案句抽取方法
Docker运行nginx镜像及docker网络端口映射
计算机毕业设计(附源码)python在线书城管理系统
LearnOpenGL1.3:着色器
u本位合约爆仓清算解决方案建议
- 原文地址:https://blog.csdn.net/zwjzone/article/details/124848105