-
Hive3:数据的加载与导出
一、加载数据
在创建表之后,表中没有数据,我们不可能
insert存入数据。
而是,通过数据加载,将HDFS中的数据关联到Hive表中。建表
CREATE TABLE myhive.test_load( dt string comment '时间(时分秒)', user_id string comment '用户ID', word string comment '搜索词', url string comment '用户访问网址' ) comment '搜索引擎日志表' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';SQL语法
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename;OVERWRITE:覆盖原表数据。元数据
00:00:01 1233215666 传智播客 http://www.itcast.cn 00:50:00 2233216666 黑马程序员 http://www.itcast.cn 01:06:00 3233217666 大数据 http://www.itcast.cn 03:36:00 3233218666 hadoop http://www.itcast.cn 19:39:00 2233219666 python http://www.itcast.cn 21:26:00 1233211666 大数据开发 http://www.itcast.cn 23:22:00 6233212666 itheima http://www.itcast.cn方式1、加载本地数据
这种方式,是先将本地数据
上传到HDFS文件系统中,然后,关联到Hive表中。
这里的本地,是指安装Hive的服务器。SQL
LOAD DATA LOCAL INPATH '/home/atguigu/search_log.txt' INTO TABLE myhive.test_load;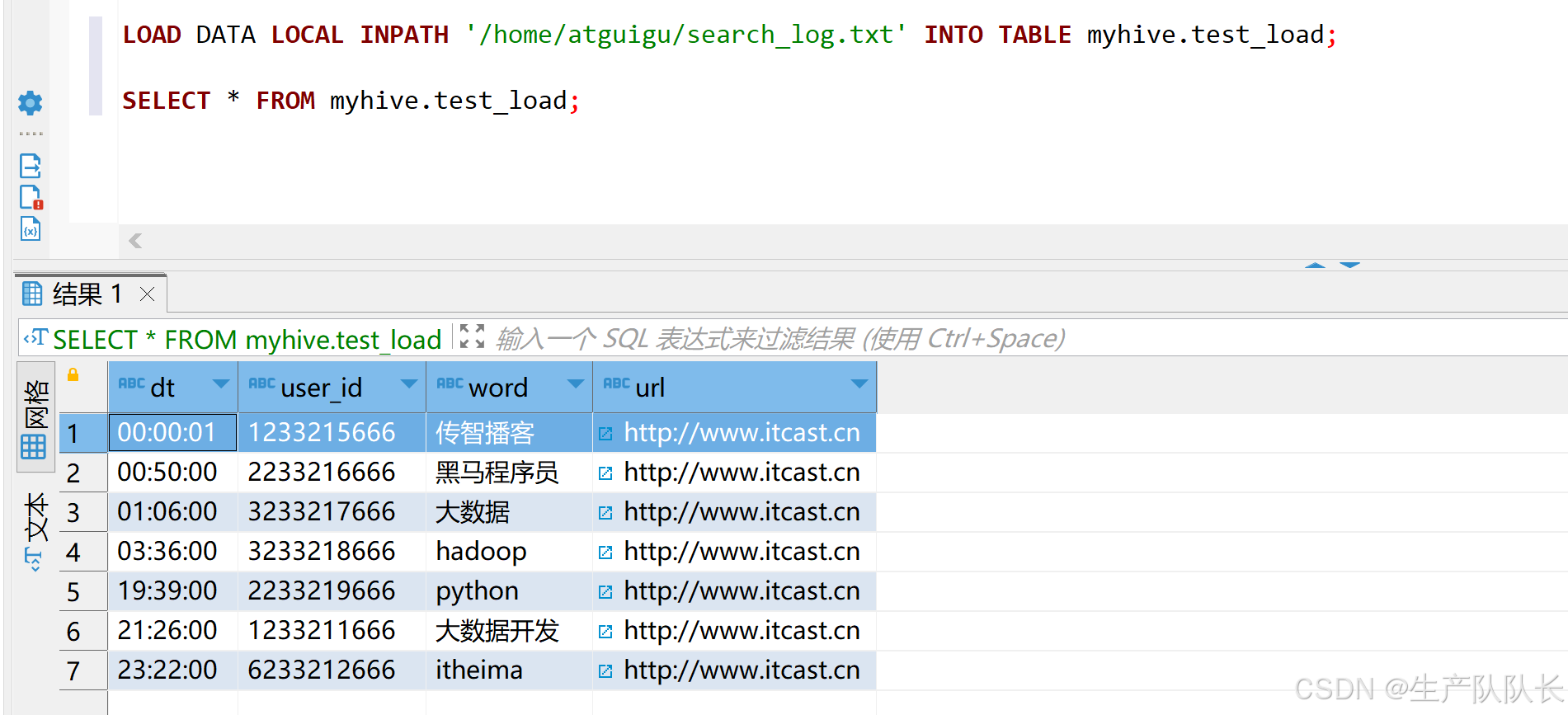
方式2、加载HDFS数据
这种方式,是将
HDFS文件系统重其他目录的数据,Move到Hive表对应的目录中,从而,关联到Hive表中。SQL
此时inpath对应的是HDFS中文件的路径。LOAD DATA INPATH '/tmp/search_log.txt' INTO TABLE myhive.test_load;
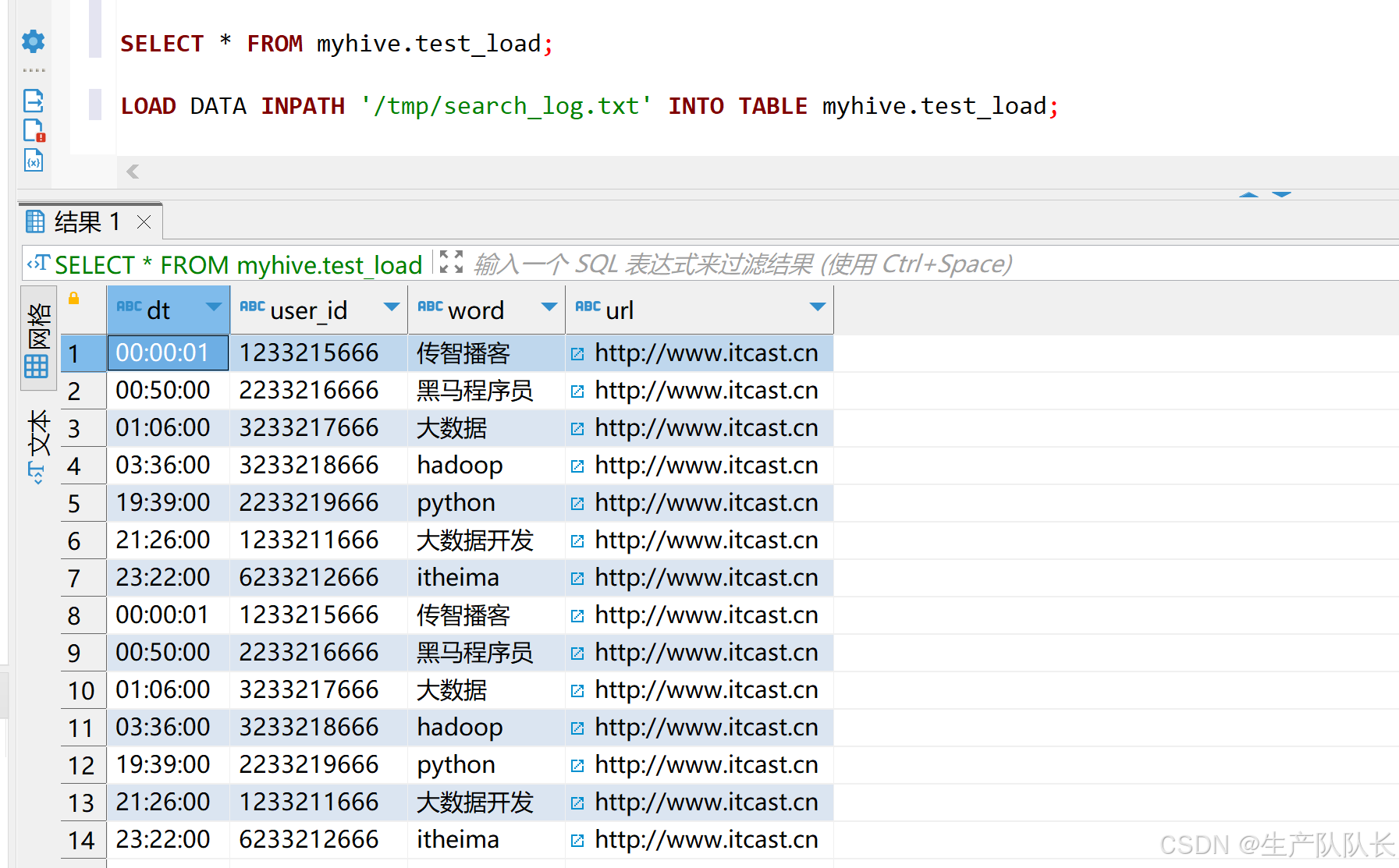
加载后,源文件就不在了。
方式3、INSERT SELECT加载数据
这个方式,和
MySQL语法差不多INSERT [OVERWRITE | INTO] TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;将
SELECT查询语句的结果插入到其它表中,被SELECT查询的表可以是内部表或外部表。
注意:列字段要对齐,否则数据错乱。示例:
INSERT INTO TABLE tbl1 SELECT * FROM tbl2; INSERT OVERWRITE TABLE tbl1 SELECT * FROM tbl2;二、导出数据
基本语法:
insert overwrite [local] directory 'path' select_statement1 FROM from_statement;方式1、INSERT OVERWRITE
将查询的结果导出到本地 - 使用默认列分隔符
insert overwrite local directory '/home/hadoop/export1' select * from test_load ;将查询的结果导出到本地 - 指定列分隔符
insert overwrite local directory '/home/hadoop/export2' row format delimited fields terminated by '\t' select * from test_load;将查询的结果导出到
HDFS文件系统中(不带local关键字)insert overwrite directory '/tmp/export' row format delimited fields terminated by '\t' select * from test_load;方式2、HIVE SHELL
基本语法:(
hive -f/-e 执行语句或者脚本 > file)bin/hive -e "select * from myhive.test_load;" > /home/hadoop/export3/export4.txt bin/hive -f export.sql > /home/hadoop/export4/export4.txt注意:
shell中的重定向符号>只能捕获程序的标准输出。 -
相关阅读:
Java如何使用for each遍历LinkedList链表集合中的元素呢?
【OpenVINO™】在 MacOS 上使用 OpenVINO™ C# API 部署 Yolov5
centos7安装redis4.0.10环境以及配置使用
wireshark 流量抓包例题重现
Gin框架: 控制器, 中间件的分层设计案例
HTML5期末考核大作业 基于HTML+CSS+JavaScript仿王者荣耀首页 游戏网站开发 游戏官网设计与实现
redis分布式锁和看门狗的实现
k3s 离线部署指南
Vue3.0跨端Web SDK访问微信小程序云储存,文件上传路径不存在/文件受损无法显示问题(已解决)
实现打印功能
- 原文地址:https://blog.csdn.net/Brave_heart4pzj/article/details/141095561