-
强化学习之REINFORECE策略梯度算法——已CartPole环境为例
整体代码如下:
- import gym
- import numpy as np
- import torch
- import matplotlib.pyplot as plt
- from tqdm import tqdm
- device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
- print(device)
- def moving_average(a, window_size):
- cumulative_sum = np.cumsum(np.insert(a, 0, 0))
- middle = (cumulative_sum[window_size:] - cumulative_sum[:-window_size]) / window_size
- r = np.arange(1, window_size-1, 2)
- begin = np.cumsum(a[:window_size-1])[::2] / r
- end = (np.cumsum(a[:-window_size:-1])[::2] / r)[::-1]
- return np.concatenate((begin, middle, end))
- class PolicyNetwork(torch.nn.Module):
- def __init__(self,statedim,hiddendim,actiondim):
- super(PolicyNetwork,self).__init__()
- self.cf1=torch.nn.Linear(statedim,hiddendim)
- self.cf2=torch.nn.Linear(hiddendim,actiondim)
- def forward(self,x):
- x=torch.nn.functional.relu(self.cf1(x))
- return torch.nn.functional.softmax(self.cf2(x),dim=1)
- class REINFORCE:
- def __init__(self,statedim,hiddendim,actiondim,learningrate,gamma,device):
- self.policynet=PolicyNetwork(statedim,hiddendim,actiondim).to(device)
- self.gamma=gamma
- self.device=device
- self.optimizer=torch.optim.Adam(self.policynet.parameters(),lr=learningrate)
- def takeaction(self,state):
- state=torch.tensor([state],dtype=torch.float).to(self.device)
- probs=self.policynet(state)
- actiondist=torch.distributions.Categorical(probs)#torch.distributions.Categorical:这是 PyTorch 中用于表示类别分布的类,可以使用 actiondist.sample() 方法从这个分布中随机采样一个类别
- action=actiondist.sample()
- return action.item()
- def update(self,transitiondist):
- statelist=transitiondist['states']
- rewardlist=transitiondist['rewards']
- actionlist=transitiondist['actions']
- G=0
- self.optimizer.zero_grad()
- for i in reversed(range(len(rewardlist))):#从最后一步计算起
- reward=rewardlist[i]
- state=statelist[i]
- action=actionlist[i]
- state=torch.tensor([state],dtype=torch.float).to(self.device)
- action=torch.tensor([action]).view(-1,1).to(self.device)
- logprob=torch.log(self.policynet(state).gather(1,action)) #.gather(1, action) 方法从策略网络的输出中提取对应于特定动作 action 的概率值。这里的 1 表示沿着维度 1(通常对应于动作维度)进行索引。
- G=self.gamma*G+reward
- loss=-logprob*G#每一步的损失函数
- loss.backward()#反向传播计算梯度
- self.optimizer.step()#更新参数,梯度下降
- learningrate=4e-3
- episodesnum=1000
- hiddendim=128
- gamma=0.99
- pbarnum=10
- printreturnnum=10
- device=torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
- env=gym.make('CartPole-v1')
- env.reset(seed=880)
- torch.manual_seed(880)
- statedim=env.observation_space.shape[0]
- actiondim=env.action_space.n
- agent=REINFORCE(statedim=statedim,hiddendim=hiddendim,actiondim=actiondim,learningrate=learningrate,gamma=gamma,device=device)
- returnlist=[]
- for k in range(pbarnum):
- with tqdm(total=int(episodesnum/pbarnum),desc='Iteration %d'%k)as pbar:
- for episode in range(int(episodesnum/pbarnum)):
- g=0
- transitiondist={'states':[],'actions':[],'nextstates':[],'rewards':[]}
- state,_=env.reset(seed=880)
- done=False
- while not done:
- action=agent.takeaction(state)
- nextstate,reward,done,truncated,_=env.step(action)
- done=done or truncated
- transitiondist['states'].append(state)
- transitiondist['actions'].append(action)
- transitiondist['nextstates'].append(nextstate)
- transitiondist['rewards'].append(reward)
- state=nextstate
- g=g+reward
- returnlist.append(g)
- agent.update(transitiondist)
- if (episode+1)%(printreturnnum)==0:
- pbar.set_postfix({'Episode':'%d'%(episodesnum//pbarnum+episode+1),'Return':'%.3f'%np.mean(returnlist[-printreturnnum:])})
- pbar.update(1)
- episodelist=list(range(len(returnlist)))
- plt.plot(episodelist,returnlist)
- plt.xlabel('Episodes')
- plt.ylabel('Returns')
- plt.title('REINFORCE on {}'.format(env.spec.name))
- plt.show()
- mvreturn=moving_average(returnlist,9)
- plt.plot(episodelist,mvreturn)
- plt.xlabel('Episodes')
- plt.ylabel('Returns')
- plt.title('REINFORCE on {}'.format(env.spec.name))
- plt.show()
效果:

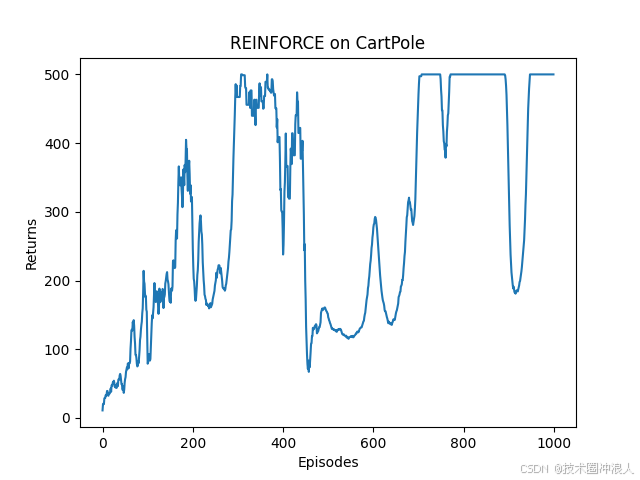
-
相关阅读:
使用PHP对接企业微信审批接口的问题与解决办法(二)
基于当量因子法、InVEST、SolVES模型等多技术融合在生态系统服务功能社会价值评估中的应用及论文写作、拓展分析
QT OpenGL (1)2D Painting Example
【sass】 中使用 /deep/ 修改 elementUI 组件样式报错
Spring底层原理学习笔记--第一讲--(BeanFactory与ApplicaitonContext)
RHCSA 02 - 自启动rootless容器
FPGA设计时序约束一、主时钟与生成时钟
POI版本升级需要调整的代码整理(3.15升级到5.1.0版本)
MyBatis简述
spring框架源码十六、BeanDefinition加载注册子流程
- 原文地址:https://blog.csdn.net/m0_56497861/article/details/141094744