-
Redis常见基本类型(5)-List, Set
List
命令小结
命令及解释 时间复杂度 lpush/rpush key value[key value...](向右/左端插入元素) O(k), k是元素个数 linsert key before | after pivot value(在某个坐标之前/右插入元素) O(n), n是pivot距离头尾的距离 lrange start end(获取从start到end部分的元素) O(s + n): s是start的偏移量, n是end-start llen key(求当前列表的长度) O(1) lindex key index(求列表中某一个下标的元素) O(n), n 是索引的偏移量 lpop/rpop key(删除左/右侧元素) O(1) lrem key count value(从value开始, 删除count个元素) O(k), k是元素个数 ltrim key start end(截取(并留下)start到end部分的列表元素,闭区间) O(k), k是元素个数 lbpop/rbpop(删除左/右侧元素阻塞版) O(1) 内部编码
现在主要是使用quicklist的方式: 相当于链表和压缩列表的结合. 整体还是链表, 链表中的每个元素是一个压缩列表, 每个压缩列表都不宜过大(元素数量小于512, 每个元素小于64byte), 再通过链式连接.
使用场景
消息队列
如图所示: Redis可以使用lpush + brpop命令结合形成典型的生产者消费者模型队列. 生产者通过lpush向消息队列中插入元素, 多个客户端在消息队列另一边利用brpop取走数据.

分频道的消息队列
就是说不同的消费者在不同的队列中获取元素, 消费者通过brpop不同的键值, 从而在不同频道上获取信息. (比如在b站中, 弹幕信息是一个消息队列, 收藏信息是一个消息队列, 评论信息是一个消息队列).

Set
集合类型也是用来存储元素的, 与列表不同的是, 集合中的元素不是有顺序的(所谓有顺序, 就比如在列表它是怎么插入的, 就可以以相同的顺序拿出元素), 然后集合不能存储重复元素(列表可以存储重复元素). Redis中除了支持集合内增删查改操作, 同时还支持多个集合取交集, 并集, 差集, 合理地使用好集合类型, 能在实际开发中解决很多问题.
基本指令
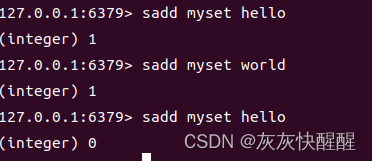
sadd
向集合中插入一个/多个元素. 注: 重复的元素无法添加到set中.
语法:
sadd key member [member...]
时间复杂度: O(1)
返回值: 本次添加成功的元素个数.
smembers
获取一个set中的所有元素, 注意: 元素间的排序是无序的.
语法:
smembers key
时间复杂度: O(N)
返回值: 所有元素的列表.

sismember
判断一个元素是否在元素中
语法:
sismember key member
时间复杂度: O(1)
返回值: 1表示元素在set中, 0表示元素不在set中或者key不存在.
scard
获取set包含的元素数目.
语法:
scard key
时间复杂度: O(1)
返回值: set内的元素个数.
spop
从set中删除并返回一个/多个元素. 注意: 由于set内的元素是无序的, 所以取出哪个元素实际是未定义行为, 即可看作随机的.
语法:
spop key [count]
时间复杂度: O(count)
返回值: 取出的元素.

smove
将一个元素从源set取出并放入目标set中.
语法:
smove source destination member
时间复杂度:O(1)
返回值: 1表示成功, 0表示失败.

srem
将指定元素从set 中删除.
语法:
srem key member [member ...]
时间复杂度: O(N), N是要删除的元素个数
返回值: 本次操作删除的元素个数.
集合间操作
回顾一下高一学的集合的几个概念:
假设有key1(a, b, c, d, e, f), key2(a, c, f, h, i)两个集合.
交集: a, b中都包含的元素, 即 a, c, f
并集: a, b所有的元素, 即a, b, c, d, e, f, h, i
差集: 两个集合之间的差异, 集合a的差集b(记作a-b), 即属于集合a而不属于集合b的元素
a-b: b, d, e
b-a: h, i
sinter
获取给定set交集中的元素.
语法:
sinter key [key ...]
时间复杂度: O(M * N), N是最小的集合元素个数, M是最大的集合元素个数.
返回值: 交集的元素.

sinterstore
获取给定set的交集中的元素并保存到目标set中.
语法:
sinterstore destination key [key ...]
返回值: 交集的元素个数
sunion
获取给定set的并集中的元素.
语法:
sunion key [key ...]
时间复杂度: O(N), N为给定的所有集合中总的元素个数.
返回值: 并集元素.

sunionstore
与sinterstore使用基本一致, 将并集放入目标set中.
sdiff
获取给定set的差集中的元素.
语法:
sdiff key [key ...]
时间复杂度: O(N), N为给定的所有集合中总的元素个数.
返回值: 差集的元素.

sdiffstore
与sinterstore作用基本一致, 获取给定set中的差集, 并放入目标set中.
-
相关阅读:
什么是响应式设计?响应式设计的基本原理是什么?如何兼容低版本的 IE?
css自学框架之消息弹框
7 步保障 Kubernetes 集群安全
SpringBoot 3.0 新特性,内置声明式HTTP客户端
goland报错:“package command-line-arguments is not a main package”解决方案
Swift 中的动态成员查找
uniapp 小程序实现图片宽度100%、高度自适应的效果
推荐 系统
Apache 基金会年度报告 | ShardingSphere 代码提交量位列前十
SpringBoot整合sql数据源
- 原文地址:https://blog.csdn.net/asdssadddd/article/details/139117212