-
kaggle电子邮件分类xgboost建模可视化模型评估混淆矩阵范例
目录
概述
在这篇博客中,我们将探索使用机器学习技术对电子邮件进行分类的任务,即将电子邮件分类为“垃圾邮件”或“正常邮件”。所谓“垃圾邮件”,指的是未经请求或不受欢迎的电子邮件;而“正常邮件”则指合法的电子邮件。我们将采用强大的XGBoost分类器,构建一个健壮的模型来执行此分类任务。
这篇博客将详细介绍从数据预处理到模型训练及评估的整个过程,使用Kaggle竞赛中的代码示例,帮助小伙伴们理解如何实现一个电子邮件分类系统。
依赖环境
这个项目所依赖的环境主要囊括了Python编程语言及一系列强大的库,这些库用于数据处理、可视化、文本处理、以及机器学习建模和评估。以下是详细的依赖环境描述:
-
Python:作为编程基础,Python提供了一个广泛支持的平台,适合数据分析、机器学习和自然语言处理。
-
数据处理库:
- NumPy:提供对多维数组的广泛支持,是进行科学计算的基础库。
- Pandas:强大的数据结构和分析工具,特别适合处理和分析表格式数据。
-
可视化工具:
- Matplotlib:一个广泛使用的Python绘图库,适用于创建静态、动态、交互式的图形。
- Seaborn:基于Matplotlib的高级可视化库,专注于统计图形的制作,简化了很多绘图任务。
- WordCloud:用于生成词云,直观展示文本数据中的主要词汇。
-
自然语言处理(NLP)工具:
- NLTK (Natural Language Toolkit):提供易于使用的接口,用于处理和分析人类语言数据,包括停用词列表、分词器、词干提取器等。
-
机器学习库:
- XGBoost:一个高效的实现梯度提升框架的库,特别适用于大规模机器学习任务。
- Scikit-learn:包含了几乎所有常用机器学习算法的库,提供了数据预处理、模型训练和评估工具,如标签编码、特征向量化、数据分割、性能评估指标等。
-
其他工具:
- Re:提供正则表达式的功能,用于文本数据的搜索和替换操作。
- Warnings:用于控制Python中的警告输出,确保代码整洁。
代码解读
库的导入
- import os
- import warnings
- import numpy as np
- import pandas as pd
- #--------------------------------------------------------------------------------------#
- import seaborn as sns
- import matplotlib.pyplot as plt
- from wordcloud import WordCloud
- #--------------------------------------------------------------------------------------#
- import re
- import nltk
- nltk.download('stopwords')
- from nltk.corpus import stopwords
- from nltk.tokenize import word_tokenize
- from nltk.stem.porter import PorterStemmer
- import nltk
- nltk.download('punkt')
- #--------------------------------------------------------------------------------------#
- from xgboost import XGBClassifier
- from sklearn.preprocessing import LabelEncoder
- from sklearn.feature_extraction.text import CountVectorizer
- from sklearn.model_selection import train_test_split
- from sklearn.metrics import accuracy_score, confusion_matrix, classification_report, roc_curve, auc
- #--------------------------------------------------------------------------------------#
- warnings.filterwarnings("ignore")
这段代码是为了准备和设置机器学习项目“电子邮件分类”所必须的Python环境和库。下面是各部分的详细解读和作用:
-
基础库导入:
os:用于操作系统级别的接口,比如文件路径操作。warnings:用于控制警告的输出。numpy(缩写为np):提供高性能的多维数组对象及对这些数组的操作。pandas(缩写为pd):提供数据结构和数据分析工具,便于数据操作和分析。
-
数据可视化库:
seaborn(缩写为sns)和matplotlib.pyplot(缩写为plt):用于数据的可视化。WordCloud:用于生成词云,这在文本分析中可以直观地展示文本数据中词频的重要性。
-
文本处理和自然语言处理库:
re:提供正则表达式的工具,用于文本字符串的搜索和替换。nltk:自然语言处理工具包,提供文本处理的库和功能。- 下载
stopwords和punkt:这些是nltk的组件,stopwords用于获取常见的无关词(如the, is等),punkt用于分词。 stopwords、word_tokenize、PorterStemmer:用于文本预处理,如去除停用词、分词和词干提取。
- 下载
-
机器学习模型和评估工具:
XGBClassifier:XGBoost的分类器,是一个高效的实现梯度增强算法的库。LabelEncoder:用于将标签标准化,即将文本标签转换为数值型。CountVectorizer:用于将文本数据转换为向量,常用于文本的特征提取。train_test_split:用于将数据集分割为训练集和测试集。accuracy_score,confusion_matrix,classification_report,roc_curve,auc:用于模型评估,计算准确率、混淆矩阵、分类报告、接收操作特征曲线(ROC)和曲线下面积(AUC)。
-
警告控制:
warnings.filterwarnings("ignore"):用于忽略警告信息,让输出结果更清洁。
这些代码块的整合提供了一套完整的工具,用于文本数据的预处理、特征工程、模型训练和评估,从而实现高效的垃圾邮件与正常邮件的分类。
数据读取
读取数据并展示前5行。
- # load the dataset
- dataset = pd.read_csv('./email_classification.csv')
- # display the dataset
- dataset.head()
扇形图可视化统计
- fig, ax = plt.subplots(figsize=(10, 5))
- labels = dataset['label'].value_counts().index
- sizes = dataset['label'].value_counts().values
- colors = sns.color_palette('pastel')
- wedges, texts, autotexts = ax.pie(sizes, colors = colors,
- autopct = '%1.1f%%', startangle = 140,
- explode = (0.1, 0), wedgeprops = dict(edgecolor = 'black'))
- ax.set_title('Distribution of Labels', fontsize = 16, fontweight = 'bold')
- ax.axis('equal')
- ax.legend(wedges, labels, loc = "best", fontsize = 12)
- for text in texts:
- text.set_fontsize(12)
- text.set_fontweight('bold')
- for autotext in autotexts:
- autotext.set_fontsize(12)
- autotext.set_fontweight('bold')
- plt.tight_layout()
- plt.show()

这段代码是用来在Python中通过Matplotlib和Seaborn库绘制饼图,展示数据集中不同类别(标签)的分布。以下是代码中每一部分的功能和作用:
-
设置画布和轴:
fig, ax = plt.subplots(figsize=(10, 5)):创建一个图形对象fig和一个轴对象ax,设置图形的尺寸为宽10英寸、高5英寸。
-
准备饼图数据:
labels = dataset['label'].value_counts().index:获取数据集中label列的值的类别,并作为饼图的标签。sizes = dataset['label'].value_counts().values:获取每个类别的数量,作为饼图的大小。colors = sns.color_palette('pastel'):使用Seaborn库生成一个淡色调的配色方案。
-
绘制饼图:
- 饼图是通过
ax.pie()函数绘制的,其中:sizes参数指定了饼图每部分的大小。colors参数指定了每部分的颜色。autopct='%1.1f%%'参数用于显示每部分占总体的百分比。startangle=140参数指定饼图开始的角度。explode=(0.1, 0)参数使第一部分稍微突出以突显。wedgeprops=dict(edgecolor='black')参数用于设置饼图每部分的边缘颜色。
wedges,texts,autotexts分别存储饼图的扇形部分、标签文本和百分比文本。
- 饼图是通过
-
设置标题和图形属性:
ax.set_title('Distribution of Labels', fontsize=16, fontweight='bold'):设置图表的标题及其字体大小和粗细。ax.axis('equal'):确保饼图是圆的。
-
添加图例:
ax.legend(wedges, labels, loc="best", fontsize=12):为饼图添加图例,位置自动调整为最佳。
-
格式化文本:
- 使用循环对标签文本和百分比文本的字体大小和粗细进行设置,增强可读性。
-
显示图形:
plt.tight_layout():自动调整子图参数,使之填充整个图形区域并使标题等不重叠。plt.show():显示图形。
词云图可视化
- ham_text_data = dataset[dataset['label'] == 'ham']['email'].values
- spam_text_data = dataset[dataset['label'] == 'spam']['email'].values
- all_ham_text = ' '.join(ham_text_data)
- all_spam_text = ' '.join(spam_text_data)
- wordcloud_ham = WordCloud(width = 400, height = 400, background_color = 'white').generate(all_ham_text)
- wordcloud_spam = WordCloud(width = 400, height = 400, background_color = 'white').generate(all_spam_text)
- plt.figure(figsize=(15, 6))
- # ham emails
- plt.subplot(1, 2, 1)
- plt.imshow(wordcloud_ham, interpolation = 'bilinear')
- plt.title('Word Cloud for Ham Emails', fontsize = 16)
- plt.axis('off')
- # spam emails
- plt.subplot(1, 2, 2)
- plt.imshow(wordcloud_spam, interpolation = 'bilinear')
- plt.title('Word Cloud for Spam Emails', fontsize = 16)
- plt.axis('off')
- plt.tight_layout()
- plt.show()

这段脚本旨在通过词云展示数据集中标记为“正常邮件”(ham)和“垃圾邮件”(spam)的电子邮件中最频繁出现的词汇。以下是脚本操作的具体步骤解析:
-
数据提取:
ham_text_data和spam_text_data是数组,包含分别标记为 'ham' 和 'spam' 的电子邮件内容。通过基于 'label' 列过滤数据集来实现。
-
文本聚合:
all_ham_text和all_spam_text是通过将各自类别的所有电子邮件内容连接起来生成的字符串。这提供了一个单一的文本块,用于生成词云。
-
词云生成:
- 为 'ham' 和 'spam' 邮件分别创建了两个
WordCloud对象。这些对象设置为400x400像素,背景颜色为白色。 - 使用各类别聚合文本调用
generate方法,根据词频产生词云视觉展示。
- 为 'ham' 和 'spam' 邮件分别创建了两个
-
可视化设置:
plt.figure(figsize=(15, 6))设置了一个特定大小的图形,以适应子图。
-
为每个类别设置子图:
- 脚本使用
plt.subplot(1, 2, 1)为 'ham' 邮件指定第一个子图,plt.subplot(1, 2, 2)为 'spam' 邮件指定第二个子图。 - 使用
plt.imshow显示词云图像,interpolation='bilinear'用于平滑显示效果。 - 为每个子图添加标题,使用
plt.axis('off')隐藏坐标轴,使展示更加清晰。
- 脚本使用
-
最后调整和显示:
plt.tight_layout()自动调整子图间距,确保没有重叠。plt.show()在屏幕上渲染图形。
分布条形图可视化
- spam_lengths = [len(email.split()) for email in dataset[dataset['label'] == 'spam']['email']]
- ham_lengths = [len(email.split()) for email in dataset[dataset['label'] == 'ham']['email']]
- fig, axes = plt.subplots(1, 2, figsize = (18, 6))
- # spam emails
- sns.histplot(spam_lengths, bins = 20, color = 'red', kde = True, ax = axes[0])
- axes[0].set_title('Histogram of Spam Email Lengths')
- axes[0].set_xlabel('Email Length (Number of Words)')
- axes[0].set_ylabel('Density')
- # ham emails
- sns.histplot(ham_lengths, bins = 20, color = 'blue', kde = True, ax = axes[1])
- axes[1].set_title('Histogram of Ham Email Lengths')
- axes[1].set_xlabel('Email Length (Number of Words)')
- axes[1].set_ylabel('Density')
- plt.show()

这段代码通过创建直方图来分析和比较标记为“垃圾邮件”(spam)和“正常邮件”(ham)的电子邮件的长度(即邮件中的单词数量)。以下是代码的具体分析:
-
数据准备:
spam_lengths和ham_lengths是列表,分别包含标记为 'spam' 和 'ham' 的电子邮件的长度。长度是通过将每封邮件的内容(字符串)分割成单词列表,并计算列表的长度来获取的。
-
设置画布和子图:
- 使用
plt.subplots(1, 2, figsize = (18, 6))创建一个包含一行两列的子图布局,并设置整个图形的尺寸为18x6英寸。这样可以并排显示两个直方图,便于比较。
- 使用
-
绘制垃圾邮件的直方图:
- 在第一个子图(
axes[0])中使用sns.histplot函数绘制spam_lengths的直方图。设置bins为20,颜色为红色,并开启核密度估计(kde=True)以平滑显示频率分布。 - 设置标题为 "Histogram of Spam Email Lengths"。
- 设置x轴标签为 "Email Length (Number of Words)",表明直方图的x轴代表邮件的单词数量。
- 设置y轴标签为 "Density",表示直方图的y轴显示密度而非纯计数。
- 在第一个子图(
-
绘制正常邮件的直方图:
- 在第二个子图(
axes[1])中使用同样的sns.histplot函数绘制ham_lengths的直方图,设置与垃圾邮件相同的bins、颜色为蓝色和核密度估计。 - 设置标题为 "Histogram of Ham Email Lengths"。
- X轴和Y轴的标签设置与垃圾邮件直方图相同。
- 在第二个子图(
-
显示图形:
- 使用
plt.show()命令来显示整个图形。这样可以直观地比较垃圾邮件和正常邮件的长度分布,观察两者在长度上的差异。
- 使用
数据预处理
- # create preprocessor
- def preprocessor(text):
- text = re.sub('[^a-zA-Z]', ' ', text)
- text = word_tokenize(text.lower())
- text = [PorterStemmer().stem(word) for word in text if not word in set(stopwords.words('english'))]
- text = ' '.join(text)
- return text
- # initialize labelEncoder & countVectorizer
- encoder = LabelEncoder()
- vectorizer = CountVectorizer()
- # clean all the emails
- dataset['email'] = dataset['email'].apply(preprocessor)
- # encode the labels
- dataset['label'] = encoder.fit_transform(dataset['label'])
- # display the modified dataset
- dataset.head()
这段代码主要涉及电子邮件文本数据的预处理、标签的编码处理以及特征向量化的初始化。具体步骤和作用如下:
-
文本预处理函数(
preprocessor):- 输入是一段文本(电子邮件内容),首先使用正则表达式
re.sub('[^a-zA-Z]', ' ', text)将非字母字符替换为空格,以去除数字和标点符号。 - 将文本转换为小写并分词,使用
word_tokenize(text.lower())。 - 接下来,对每个单词应用词干提取(stemming),同时过滤掉英语停用词(如"is", "and", "the"等),使用
PorterStemmer().stem(word)。 - 最后,将处理后的单词列表重新组合成字符串,返回处理后的文本。
- 输入是一段文本(电子邮件内容),首先使用正则表达式
-
标签编码器和计数向量化器的初始化:
encoder = LabelEncoder():初始化标签编码器,用于将文本标签(如"spam", "ham")转换为整数。vectorizer = CountVectorizer():初始化计数向量化器,用于将文本转换成数值向量,便于机器学习模型处理。
-
清洗所有电子邮件:
dataset['email'] = dataset['email'].apply(preprocessor):将预处理函数应用到数据集的'email'列上,对每封电子邮件进行清洗。
-
编码标签:
dataset['label'] = encoder.fit_transform(dataset['label']):使用标签编码器将'email'列的标签转换为数值型标签。
-
显示修改后的数据集:
dataset.head():显示数据集的前几行,以查看修改和处理后的结果。
划分数据集
- # extract features and target
- X = vectorizer.fit_transform(dataset['email']).toarray()
- y = dataset.iloc[:, -1].values
- # split the dataset
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
- # print the shape of train/test features and labels
- print(f'\nShape of Training Features (X_train) --> {X_train.shape} and \
- Training Labels (y_train) --> {y_train.shape}')
- print(f'\nShape of Testing Features (X_train) --> {X_test.shape} and \
- Testing Labels (y_test) --> {y_test.shape}')
这段代码主要进行了特征提取、目标变量的确定、数据集的分割,以及打印训练集和测试集的维度信息。具体步骤和作用如下:
-
特征提取和目标变量确定:
X = vectorizer.fit_transform(dataset['email']).toarray():使用之前初始化的计数向量化器对电子邮件文本数据进行转换,生成一个数值特征矩阵X。fit_transform方法首先拟合数据(学习词汇表),然后将文本数据转换为词频矩阵,并使用toarray()将稀疏矩阵转换为常规数组。y = dataset.iloc[:, -1].values:提取数据集最后一列的值作为目标变量y。这里假设最后一列是经过编码的标签("spam"或"ham")。
-
数据集分割:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0):使用train_test_split函数将数据集划分为训练集和测试集,其中测试集占总数据的20%(由test_size=0.2参数确定),random_state=0保证了每次运行代码时数据划分的一致性。
-
打印训练集和测试集的维度:
- 打印训练集特征
X_train和标签y_train的维度,以及测试集特征X_test和标签y_test的维度。 print语句用于显示各数据集的形状(shape),形状信息帮助确认数据是否正确分割,以及每部分的数据量是否符合预期。
- 打印训练集特征
模型训练
- # initialize the classifier
- model = XGBClassifier()
- # train the model
- model.fit(X_train, y_train)
-
初始化分类器:
model = XGBClassifier():创建一个XGBoost分类器的实例。XGBoost是一种基于梯度提升算法的强大机器学习模型,广泛用于各种分类问题,特别是在处理大规模数据集时表现出色。
-
训练模型:
model.fit(X_train, y_train):使用训练数据集X_train(特征)和y_train(标签)来训练模型。这一步骤涉及模型通过学习数据中的模式来调整其内部参数,以便能够有效地预测新数据的标签。
模型预测和评估
- # predict the labels
- y_pred_train = model.predict(X_train)
- y_pred_test = model.predict(X_test)
- # display the accuracy
- print(f'Train Accuracy : {accuracy_score(y_train, y_pred_train) * 100:.2f} %')
- print(f'Test Accuracy : {accuracy_score(y_test, y_pred_test) * 100:.2f} %')
-
预测标签:
y_pred_train = model.predict(X_train):使用训练好的XGBoost模型对训练数据集X_train进行预测,得到训练集的预测结果y_pred_train。y_pred_test = model.predict(X_test):使用同一模型对测试数据集X_test进行预测,得到测试集的预测结果y_pred_test。
-
显示准确率:
accuracy_score(y_train, y_pred_train) * 100:计算训练集的预测准确率,即预测正确的样本数占总样本数的比例,结果以百分比形式显示。通过accuracy_score函数比较实际标签y_train和预测标签y_pred_train。accuracy_score(y_test, y_pred_test) * 100:计算测试集的预测准确率,这个指标非常重要,因为它表示模型在未见过的数据上的表现。print函数用于输出训练准确率和测试准确率,格式化输出为两位小数的百分比形式。
ROC曲线评估
- fpr, tpr, thresholds = roc_curve(y_test, y_pred_test)
- roc_auc = auc(fpr, tpr)
- plt.figure()
- plt.plot(fpr, tpr, color = 'darkorange', lw = 2, label = 'ROC curve (area = %0.2f)' % roc_auc)
- plt.plot([0, 1], [0, 1], color = 'navy', lw = 2, linestyle = '--')
- plt.xlabel('False Positive Rate')
- plt.ylabel('True Positive Rate')
- plt.title('Receiver Operating Characteristic (ROC)')
- plt.legend(loc = 'lower right')
- plt.grid(False)
- plt.show()
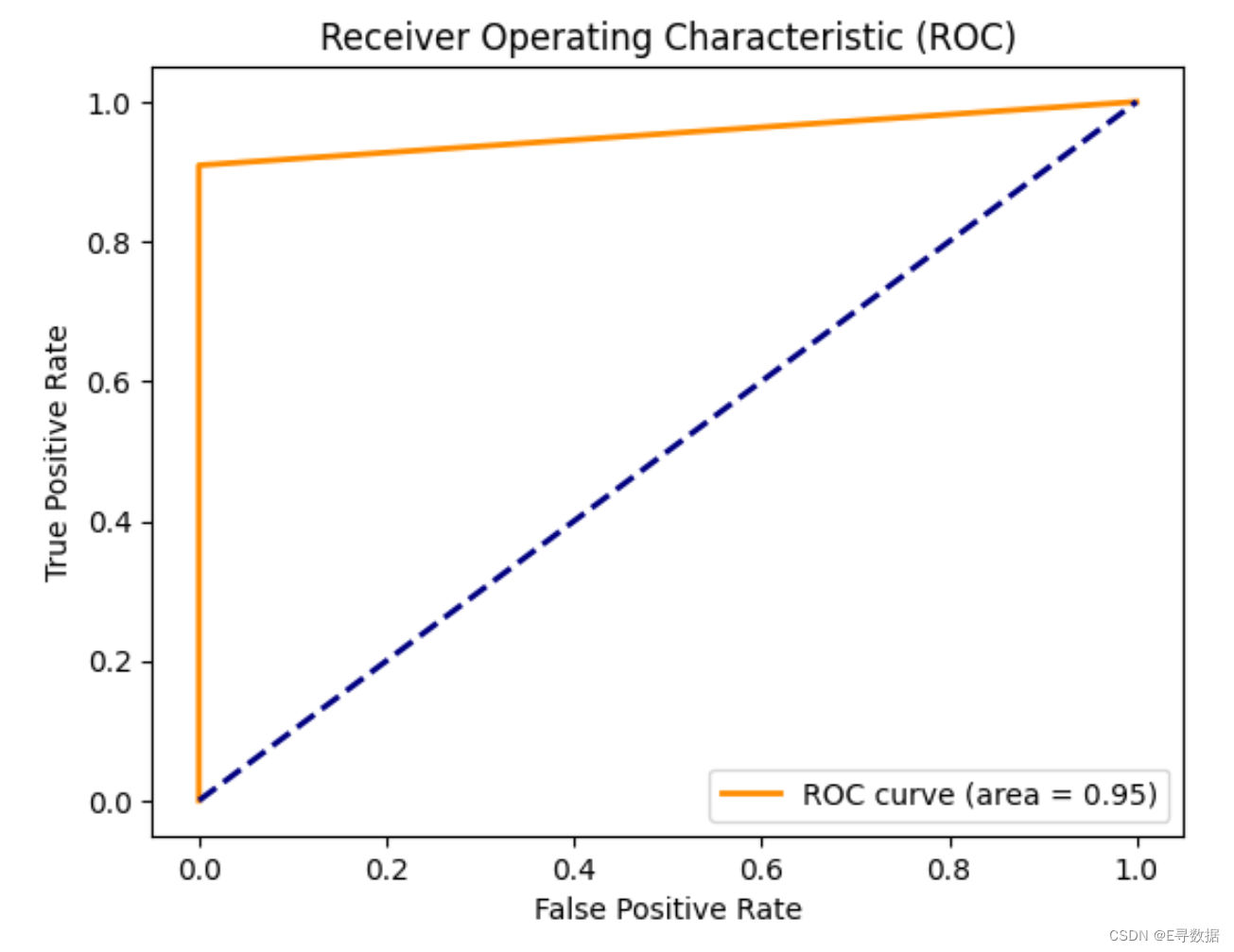
这段代码用于生成和显示接收者操作特征(ROC)曲线,以评估分类模型在区分垃圾邮件和正常邮件时的性能。具体步骤和绘图解释如下:
-
计算ROC曲线的坐标:
fpr, tpr, thresholds = roc_curve(y_test, y_pred_test):通过roc_curve函数计算测试集中的假阳性率(False Positive Rate, FPR)和真阳性率(True Positive Rate, TPR)。y_test是真实的标签,而y_pred_test是模型预测的标签。
-
计算曲线下面积(AUC):
roc_auc = auc(fpr, tpr):使用auc函数计算ROC曲线下的面积,这个面积值(AUC)是分类性能的一个重要指标,值越接近1表示分类效果越好。
-
绘制ROC曲线:
plt.figure():创建一个新的图形。plt.plot(fpr, tpr, color = 'darkorange', lw = 2, label = 'ROC curve (area = %0.2f)' % roc_auc):绘制ROC曲线,使用深橙色,线宽为2,并在图例中显示AUC值。plt.plot([0, 1], [0, 1], color = 'navy', lw = 2, linestyle = '--'):绘制一条从(0,0)到(1,1)的对角线(虚线),这条线表示随机猜测的结果,任何有意义的分类器的ROC曲线应该位于这条线的上方。
-
设置图表的其它参数:
plt.xlabel('False Positive Rate')和plt.ylabel('True Positive Rate'):设置x轴和y轴的标签。plt.title('Receiver Operating Characteristic (ROC)'):设置图表标题。plt.legend(loc = 'lower right'):添加图例,位置在右下角。plt.grid(False):关闭网格显示。
-
显示图形:
plt.show():显示图形,这有助于直观地理解模型的分类效果,特别是其在区分正类和负类能力上的效能。
通过这样的可视化,可以清晰地评估和比较不同模型的性能,为进一步的模型选择和优化提供依据。
混淆矩阵评估
- conf_matrix = confusion_matrix(y_test, y_pred_test)
- class_labels = ['ham', 'spam']
- plt.figure(figsize=(8, 6))
- sns.heatmap(conf_matrix, annot = True, fmt = 'd',
- cmap = "YlGnBu", xticklabels = class_labels, yticklabels = class_labels)
- plt.title('Confusion Matrix')
- plt.xlabel('Predicted')
- plt.ylabel('Actual')
- plt.show()

这段代码创建了一个混淆矩阵的可视化图表,用以展示分类模型在预测垃圾邮件和正常邮件时的性能表现。具体步骤和图表的解释如下:
-
生成混淆矩阵:
conf_matrix = confusion_matrix(y_test, y_pred_test):使用confusion_matrix函数计算模型对测试集y_test的预测结果y_pred_test的混淆矩阵。混淆矩阵是一个表格,显示了实际类别与预测类别的匹配程度。
-
图表设置:
plt.figure(figsize=(8, 6)):设置图形的大小为8x6英寸。sns.heatmap(conf_matrix, annot = True, fmt = 'd', cmap = "YlGnBu", xticklabels = class_labels, yticklabels = class_labels):使用Seaborn库的heatmap函数绘制混淆矩阵。这里设置:annot=True表示在格子里显示具体数值。fmt='d'表示数值的格式为整数。cmap="YlGnBu"设置颜色映射为蓝绿色调。xticklabels和yticklabels设置x轴和y轴的标签为类别名称("ham"和"spam")。
-
图表标签和标题:
plt.title('Confusion Matrix'):设置图表的标题。plt.xlabel('Predicted'):设置x轴的标签为“预测”。plt.ylabel('Actual'):设置y轴的标签为“实际”。
-
显示图形:
plt.show():显示图形。混淆矩阵的可视化有助于直观地理解模型在各个类别上的预测准确性和误差类型,例如将多少实际的“ham”错误地预测为“spam”,反之亦然。
这种可视化是评估分类模型性能的重要工具,尤其在处理不平衡数据集时,可以清晰地显示模型在少数类和多数类上的表现差异。
多维度交叉评估
- report = classification_report(y_test, y_pred_test, output_dict = True)
- df_report = pd.DataFrame(report).transpose()
- df_report = df_report.rename(index={'0': 'ham', '1': 'spam'})
- plt.figure(figsize = (10, 6))
- sns.heatmap(df_report.iloc[:-1, :-1], annot = True, cmap = "YlGnBu", fmt = ".2f")
- plt.title('Classification Report')
- plt.xlabel('Metrics')
- plt.ylabel('Classes')
- plt.show()

这段代码主要用于生成和显示分类报告的热图,以评估模型在分类“ham”和“spam”时的详细性能指标。具体步骤和图表的解释如下:
-
生成分类报告:
report = classification_report(y_test, y_pred_test, output_dict=True):使用classification_report函数生成关于预测性能的报告,其中output_dict=True参数使得报告以字典形式返回,便于进一步处理成DataFrame。
-
转换报告为DataFrame:
df_report = pd.DataFrame(report).transpose():将字典格式的报告转换为DataFrame,并进行转置操作,使得行标签成为类别和总结指标,列标签成为性能度量。
-
重命名索引:
df_report = df_report.rename(index={'0': 'ham', '1': 'spam'}):因为原始的类别标签是数字,这里将其重命名为对应的文本标签("ham"和"spam"),以提高报告的可读性。
-
绘制热图:
plt.figure(figsize=(10, 6)):设置图形大小为10x6英寸。sns.heatmap(df_report.iloc[:-1, :-1], annot=True, cmap="YlGnBu", fmt=".2f"):使用Seaborn库的heatmap函数绘制分类报告的热图。这里设置:df_report.iloc[:-1, :-1]表示选择除了最后一行和最后一列之外的数据,通常最后一行为"accuracy",最后一列为支持的样本数量("support")。annot=True表示在格子里显示数值。cmap="YlGnBu"设置颜色映射为蓝绿色调。fmt=".2f"设置数值格式为保留两位小数的浮点数。
-
设置图表的标签和标题:
plt.title('Classification Report'):设置图表的标题。plt.xlabel('Metrics'):设置x轴的标签为“度量”。plt.ylabel('Classes'):设置y轴的标签为“类别”。
-
显示图形:
plt.show():显示图形。此热图为每个类别展示了准确率(precision)、召回率(recall)、F1分数等重要指标,为评估模型在不同类别上的表现提供了详细视图。
配套源码和数据集
xgboost邮件分类配套数据集和源码下载地址
-
-
相关阅读:
数字滚动动效(纯HTML5版和Vue版本)
esp8266网页控制RGB灯颜色
详解数仓的向量化执行引擎
Nginx正向代理,反向代理,负载均衡
【EMC专题】浪涌抗扰度测试
WordPress SMTP邮件发送插件 Easy WP SMTP
客户端和服务器不支持常用的SSL协议版本或密码套件
Allegro基本规则设置指导书之Spacing规则设置
基于Springboot外卖系统07:员工分页查询+ 分页插件配置+分页代码实现
STM32_IIC
- 原文地址:https://blog.csdn.net/qq_42452134/article/details/137952126
