-
深度学习系列60: 大模型文本理解和生成概述
参考网络课程:https://www.bilibili.com/video/BV1UG411p7zv/?p=98&spm_id_from=pageDriver&vd_source=3eeaf9c562508b013fa950114d4b0990
1. 概述
包含理解和分类两大类问题,对应的就是BERT和GPT两大类模型;而交叉领域则对应T5

2. 信息检索(IR)

2.1 传统方法:BM25
传统IR方法BM25基于tf-idf,介绍如下

根据单词去匹配有两类问题:有时候同一个词有很多意思;有时候同一个意思使用完全不同的词表达的;这样就会产生precision和recall两方面的问题。2.2 大模型方法
大模型IR的逻辑如下:将查询q和文档库D都输入神经网络,得到q的向量和D中所有d的向量,然后查询和q相似度最高的d。

大模型IR方法有两种:cross-encoder和dual-encoder。

一般会分两步:先使用右边的de进行粗筛,然后使用左边的ce进行精排。


3. 知识问答
3.1 理解类QA

举个例子,我们英语考试的阅读理解:

传统模型如下:

一个具体的实现方法如下:

有了大模型之后,整体的架构变得极为简单:

下面是一个基于BERT的例子,把问题和reference输入bert,然后把cls的embedding拿出来,接上一个分类层即可。
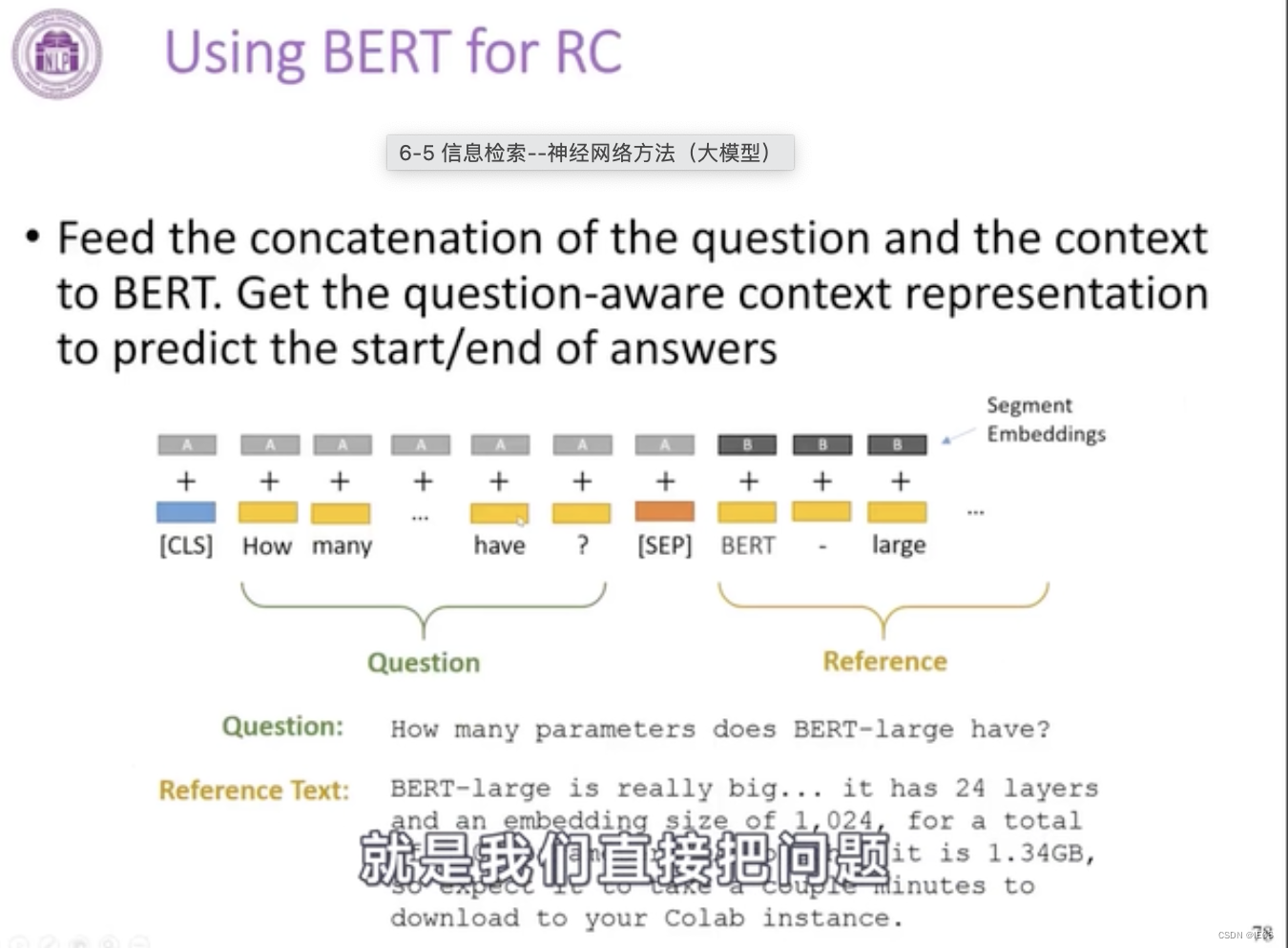
还有一种更简单的prompt learning的方式:

3.2 开放类QA

包括两类:
1) 生成式问答


2)检索式问答


第一步的检索工作,可以使用大模型来训练:



3.3 微调代码
下面是使用openDelta进行微调知识问答的例子:






4. 文本生成

4.1 语言建模LM



大模型中的seq2seq代表是BART和T5,使用下面的方法,学习到了很强的填空能力

GPT是自回归的模型,结构上是把transformer的decoder单独拿出来。GPT学习到的是预测下一个词的能力

而BERT则是非回归的模型,结构上可以理解为transformer的encoder。没有时序关系,因此可以做上下文理解任务。

4.2 解码过程
LM的结果是词表的概率分布,我们需要解码成人类可读的语言
从最简单的greedy decoding开始:

这种myopic的方法,效果只能说是一般。
第二种是beam search的方法:



第三种是不追求概率最大,而是以一定概率去随机解码

temperature是softmax之前处以的一个数,这个数字越大的话,采样就越平均,也就是随机性增加了(多样性增加了,但是可能不相关)。

4.3 可控文本生成
有3类方法

4.3.1 prompt方法
可以在输入文本前面加prompt

也可以在模型前加prefix(也就是prefix-tuning的做法)

4.3.2 修改概率分布
使用正样本和负样本生成器来知道原模型:

4.3.3 直接修改模型结构
如下图,有两个encoder,其中一个用来编码guidance,并且会先解码,其结果再和source文本编码的结果一起进行解码

4.4 测评
BLUE指的是生成的文本的n-gram有多少与token的text是相似的,其中BP是对短句的惩罚,然后N一般取4,也就是计算1-gram到4-gram的相似度平均值。
PPL指的是生成目标概率的负相关系数。
ROUTE是一个基于recall-oriented来进行计算的方法



-
相关阅读:
Splunk: 使用btool 后台检查alert / fields / macros 配置
第04章 逻辑架构【1.MySQL架构篇】【MySQL高级】
如何跳出forEach循环
Oracle数据库开发-外部表应用
形态学笔记:侵蚀+膨胀+开运算+闭运算+形态学梯度+顶帽运算+黑帽运算
在MM32F5微控制器上使用外扩SRAM作为主内存
脚手架开发流程详解
springboot265基于Spring Boot的库存管理系统
“我在 iPhone 上,创建了个 ChatGPT 快捷方式,这也太万能了……”
开源数据库postgresql在统信系统上的离线安装shell脚本
- 原文地址:https://blog.csdn.net/kittyzc/article/details/136144838