-
2.14日学习打卡----初学Zookeeper(一)
2.14日学习打卡
Zookeeper概念
一. 集中式到分布式

单机架构
一个系统业务量很小的时候所有的代码都放在一个项目中就好了,然后这个项目部署在一台服务器上,整个项目所有的服务都由这台服务器提供。

缺点:
- 服务性能存在瓶颈
- 不可伸缩性
- 代码量庞大,系统臃肿,牵一发动全身
- 单点故障问题
集群架构
单机处理到达瓶颈的时候,你就把单机复制几份,这样就构成了一个集群。

集群存在的问题:
当你的业务发展到一定程度的时候,你会发现一个问题无论怎
么增加节点,貌似整个集群性能的提升效果并不明显了。这时
候,你就需要使用分布式架构了。什么是分布式

分布式架构就是将一个完整的系统,按照业务功能,拆分成一个个独立的子系统,在分布式结构中,每个子系统就被称为“服务”。这些子系统能够独立运行在web容器中,它们之间通过RPC方式通信。分布式的优势:
- 系统之间的耦合度大大降低,可以独立开发、独立部署、独立测试,系统与系统之间的边界非常明确,排错也变得相当容易,开发效率大大提升。
- 系统之间的耦合度降低,从而系统更易于扩展。我们可以针对性地扩展某些服务。
- 服务的复用性更高。比如,当我们将用户系统作为单独的服务后,该公司所有的产品都可以使用该系统作为用户系统,无需重复开发
三者区别

总结:
将一套系统拆分成不同子系统部署在不同服务器上(这叫分布式),然后部署多个相同的子系统在不同的服务器上(这叫集群)。
集群:多个人在一起作同样的事 。
分布式 :多个人在一起作不同的事 。二. CAP定理

分布式系统正变得越来越重要,大型网站几乎都是分布式的。分布式系统的最大难点,就是各个节点的状态如何同步。CAP 定理是这方面的基本定理,也是理解分布式系统的起点。分布式系统的三个指标
- Consistency(一致性)
- Availability (可用性)
- Partition tolerance (分区容错性)
它们的第一个字母分别是 C、A、P。
这三个指标不可能同时做到。这个结论就叫做 CAP 定理。
分区容错性
大多数分布式系统都分布在多个子网络。每个子网络就叫做一个区。分区容错的意思是,区间通信可能失败。比如,一台服务器放在中国,另一台服务器放在美国,这就是两个区,它们之间可能无法通信
结论:
分区容错无法避免,因此可以认为 CAP 的 P 总是成立。CAP 定
理告诉我们,剩下的 C 和 A 无法同时做到。一致性
写操作之后的读操作,必须返回该值。举例来说,某条记录是 v0,用户向 G1 发起一个写操作,将其改为 v1。

接下来,用户的读操作就会得到 v1。这就叫一致性。

问题是,用户有可能向 G2 发起读操作,由于 G2 的值没有发生变化,因此返回的是 v0。G1 和 G2 读操作的结果不一致,这就不满足一致性了。

为了让 G2 也能变为 v1,就要在 G1 写操作的时候,让 G1 向 G2 发送一条消息,要求 G2 也改成 v1。

可用性
只要收到用户的请求,服务器就必须给出回应。

解释:
用户可以选择向 G1 或 G2 发起读操作。不管是哪台服务器,只要收到请求,就必须告诉用户,到底是 v0 还是 v1,否则就不满足可用性。一致性和可用性的矛盾

解释:
如果保证 G2 的一致性,那么 G1 必须在写操作时,锁定 G2 的读操作和写操作。只有数据同步后,才能重新开放读写。锁定期间,G2 不能读写,没有可用性不。一致性和可用性如何选择
- 一致性
特别是涉及到重要的数据,就比如钱,商品数量,商品价格。 - 可用性
网页的更新不是特别强调一致性,短时期内,一些用户拿到老版本,另一些用户拿到新版本,问题不会特别大。
三. 什么是Zookeeper

分布式架构
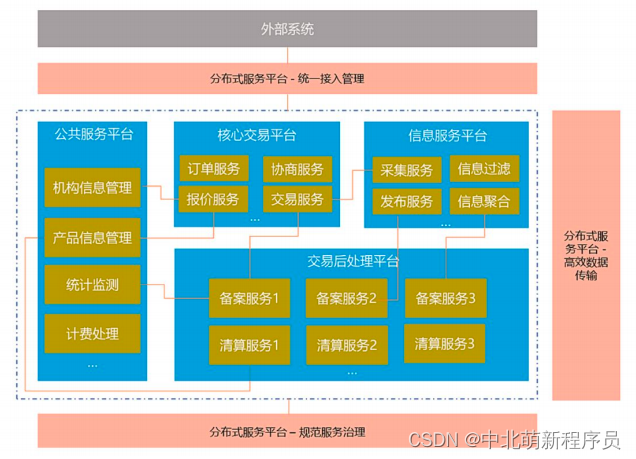
多个节点协同问题:
- 每天的定时任务由谁哪个节点来执行?
- RPC调用时的服务发现?
- 如何保证并发请求的幂等
这些问题可以统一归纳为多节点协调问题,如果靠节点自身进
行协调这是非常不可靠的,性能上也不可取。必须由一个独立
的服务做协调工作,它必须可靠,而且保证性能。一个应用程序,涉及多个进程协作时,`业务逻辑代码中混杂有大量复杂的进程协作逻辑。

上述多进程协作逻辑,有 2 个特点:
- 处理复杂
- 处理逻辑可重用
因此,考虑将多进程协作的共性问题拎出,作为基础设施,让 RD 更加专注业务逻辑开发,即:
Zookeeper从何而来
ZooKeeper最早起源于雅虎研究院的一个研究小组。在当时,研究人员发现,在雅虎内部很多大型系统基本都需要依赖一个类似的系统来进行分布式协调,但是这些系统往往都存在分布式单点问题。
解决:
雅虎的开发人员就试图开发一个通用的无单点问题的分布式协
调框架,以便让开发人员将精力集中在处理业务逻辑上。Zookeeper介绍
ZooKeeper是一个开放源代码的分布式协调服务。ZooKeeper的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。

说明:
Zookeeper顾名思义就是动物园管理员。 因为Hadoop生态各个项目都是动物得图标。 所以很符合管理员得形象。四. 应用场景

数据发布/订阅
数据发布/订阅的一个常见的场景是配置中心,发布者把数据发布到ZooKeeper 的一个或一系列的节点上,供订阅者进行数据订阅,达到动态获取数据 的目的。

ZooKeeper 采用的是推拉结合的方式。
推: 服务端会推给注册了监控节点的客户端 Wathcer 事件通知
拉: 客户端获得通知后,然后主动到服务端拉取最新的数据实现的思路
mysql.driverClassName=com.mysql.jdbc.Driver dbJDBCUrl=jdbc:mysql://127.0.0.1/runzhlliu username=root password=123456- 1
- 2
- 3
- 4
具体流程:
- 把配置信息写到一个 Znode 上,例如
/DBConfiguration - 客户端启动初始化阶段读取服务端节点的数据,并且注册一个数据变更的 Watcher
- 配置变更只需要对 Znode 数据进行 set 操作,数据变更的通知会发送到客户端,客户端重新获取新数据,完成配置动态修改
负载均衡
负载均衡是一种手段,用来把对某种资源的访问分摊给不同的设备,从而减轻单点的压力。

实现的思路:

命名服务命名服务就是提供名称的服务。ZooKeeper 的命名服务有两个应用方面。

功能:
- 提供类 JNDI 功能,可以把系统中各种服务的名称、地址以及目录信息存放在 ZooKeeper,需要的时候去 ZooKeeper 中读取
- 制作分布式的序列号生成器
分布式协调/通知
分布式协调/通知服务是分布式系统中不可缺少的一个环节,是将不同的分布式组件有机结合起来的关键所在。对于一个在多台机器上部署运行的应用而言,通常需要一个协调者(Coordinator)来控制整个系统的运行流程

五. 为什么选择Zookeeper

随着分布式架构的出现,越来越多的分布式应用会面临数据一致性问题。很遗憾的是,在解决分布式数据一致性上,除了ZooKeeper之外,目前还没有一个成熟稳定且被大规模应用的解决方案。

主要:
ZooKeeper无论从易用性还是稳定性上来说,都已经达到了一
个工业级产品的标准。ZooKeeper是免费的,你无须为它支付任何费用。这点对于一个小型公司,尤其是初创团队来说,无疑是非常重要的。
广泛应用
最后,ZooKeeper已经得到了广泛的应用。诸如Hadoop、HBase、Storm、kafka等越来越多的大型分布式项目都将Zookeeper作为核心组件。
六. 基本概念

集群角色
通常在分布式系统中,构成一个集群的每一台机器都有自己的角色,最典型的集群模式就是Master/Slave模式(主备模式)。在这种模式中,我们把能够处理所有写操作的机器称为Master机器,把所有通过异步复制方式获取最新数据,并提供读服务的机器称为Slave机器。
概念颠覆:
而在ZooKeeper中,这些概念被颠覆了。它没有沿用传统的MasterlSlave概念,而是引入了Leader、Follower和 Observer三种角色。数据节点(znode)
在谈到分布式的时候,我们通常说的“节点”是指组成集群的每一台机器

在ZooKeeper中节点分为两类
- 第一类同样是指构成集群的机器,我们称之为机器节点
- 第二类则是指数据模型中的数据单元,我们称之为数据节点——ZNode。
ZooKeeper将所有数据存储在内存中,数据模型是一棵树。
Watcher监听机制
Watcher(事件监听器),是ZooKeeper 中的一个很重要的特性。

注意:
ZooKeeper 允许用户在指定节点上注册一些Watcher,并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知到感兴趣的客户端上去,该机制是ZooKeeper实现分布式协调服务的重要特性。ACL权限控制
ZooKeeper 采用ACL (Access Control Lists)策略来进行权限控
制,类似于UNIX文件系统的权限控制。ZooKeeper定义了如下5种
权限。- CREATE: 创建子节点的权限
- READ: 获取节点数据和子节点列表的权限
- WRITE: 更新节点数据的权限
- DELETE: 删除子节点的权限
- ADMIN: 设置节点ACL的权限
注意:
create和delete这两种权限都是针对子节点的权限控制。如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,大家的支持就是我坚持下去的动力!

-
相关阅读:
Java 如何让HashMap集合按照key进行排序呢?
Win11不能拖拽图片到任务栏软件上快速打开怎么办
又一个新指标可以写,氧化平衡评分,源自膳食以及生活方式
【css | loading】各种简单的loading特效
登录远程SQLServer
hdlbits系列verilog解答(7458芯片)-10
CRM系统如何进行公海池线索分配自动化?
初识JavaScript
CODESYS以文件形式保存RETAIN变量
vue3实现导出Excel(2)
- 原文地址:https://blog.csdn.net/m0_74436895/article/details/136134069