-
read系统调用源码分析
文章目录
- 基本知识
- read系统调用源码分析
- 设计思想
- 一、入口函数
- 二、`vfs_read`函数
- 三、`do_sync_read`
- 四、`generic_file_aio_read`
- 五、`do_generic_file_read`函数
- 六、`mpage_readpages`
- 七、`do_mpage_readpage`函数
- 八、`mpage_bio_submit`
- 九、`submit_bio`
- 十、`generic_make_request`
- 十一、`__generic_make_request`
- 十二、`__make_request`函数
- 十三、`add_acct_request`
- 十四、`__blk_run_queue`
- 十五、`request_fn`
- 十六、块设备驱动
- 心得体会
基本知识
前言
先介绍一些基本概念,免得后期太乱了,后面有对read的分析,有的代码前面的分析是我结合原有知识分析然后在看源码验证,肯定会有很多错误之处,本篇文章本仅仅自己用来学习使用
一个文件基本的读写流程图
read调用vfs_read函数,VFS先在内核缓冲区进行1次read,如果没有数据,则进入实际文件系统对磁盘进行2次read,这中间会经过通用块,IO调度程序层,块设备驱动程序。
- VFS:是对具体文件系统的封装
- 缓冲层:查找文件,如果在缓冲中直接读取,不在则到具体文件系统中读取
- 映射层(具体文件系统):确定文件的块大小计算请求的数据包含多少个块,确定文件在磁盘具体位置
- 通用块层:读写请求被构成多个或一个bio结构请求
- IO调度层:采用算法将IO请求进行排序
- 块设备:最终对设备进行IO操作
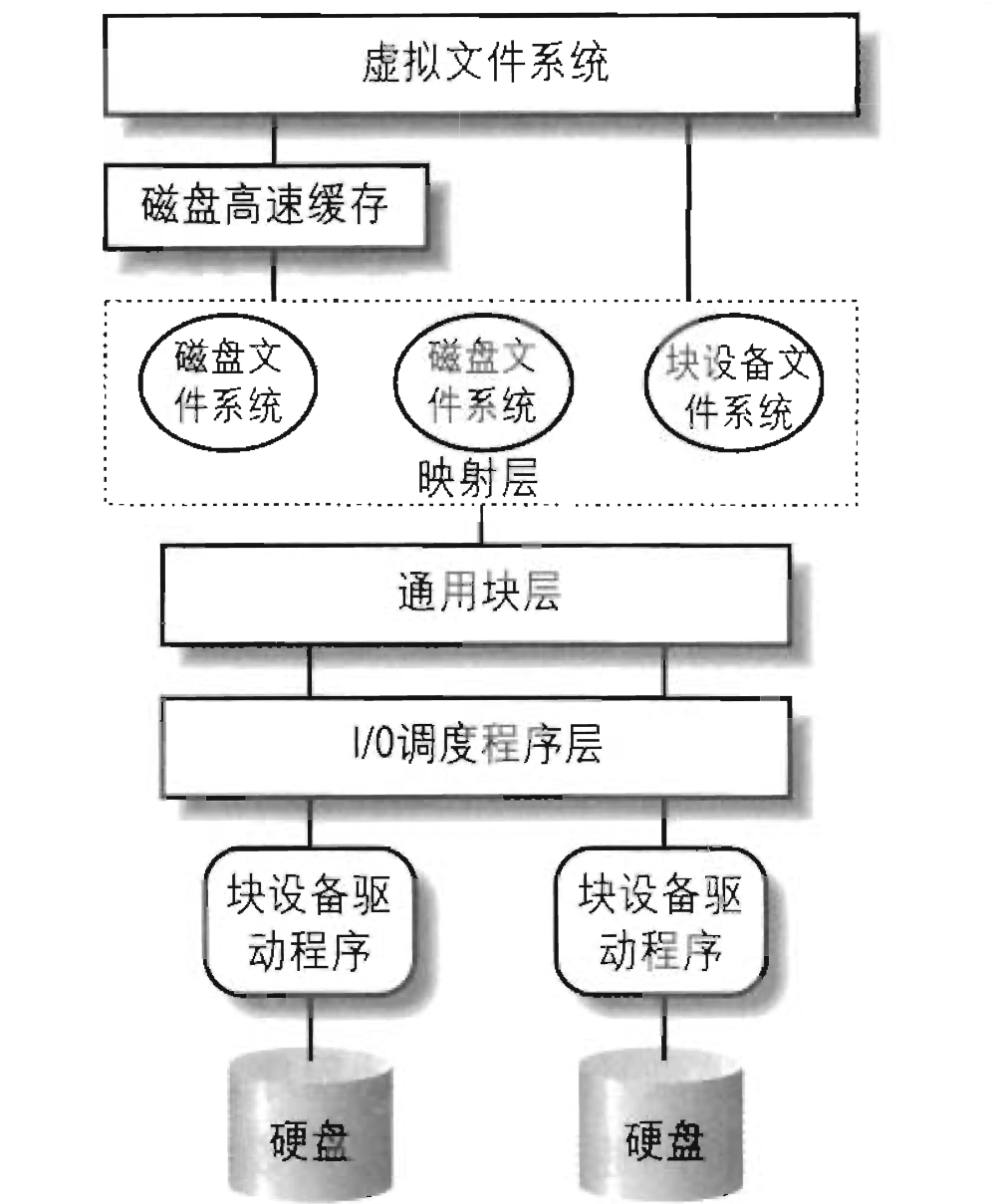

块设备驱动
<1> 块设备(blockdevice)
是一种具有一定结构的随机存取设备,对这种设备的读写是按块进行的,他使用缓冲区来存放暂时的数据,待条件成熟后,从缓存一次性写入设备或者从设备一次性读到缓冲区。
<2> 块设备结构
段:由若干个块组成;是Linux内存管理机制中一个内存页或内存页的一部分;
块:由Linux制定对内核或文件系统等数据处理的基本单位;通常通常为4096个字节,由1个或多个扇区组成;
扇区:块设备的基本单位,是一个固定的硬件单位,制定了设备最少能够传输的数据量;通常在512字节到32768字节之间,默认:512字节;
块是连续扇区的序列,块长度总是扇区长度的整数倍;块的最大长度,受特定体系结构的内存页长度限制;
块设备使用请求队列,缓存并重排读写数据块的请求,用高效的方式读取数据;块设备的每个设备都关联了请求队列;对块设备的读写请求不会立即执行,这些请求会汇总起来,经过协同之后传输到设备;
<3>
block_device和gendisk区别- block_device :
计算机上有一个硬盘,这个硬盘被划分为多个分区,比如一个用于操作系统、一个用于用户数据等。
整个硬盘就是一个 block_device,而每个分区都可以被看作是一个 block_device 的实例,因为它们都是块设备。
block_device 包含了硬盘和每个分区的各种信息,如设备号、分区大小等。 - gendisk 的形象例子:
专注于硬盘这个物理设备本身,而不是每个分区,那么我们可以将硬盘本身描述为一个 gendisk。
gendisk 包含了硬盘的特有信息,比如容量、扇区大小、块设备队列等。它专注于硬盘这个通用块设备。
同步/异步IO
-
同步 I/O:
在同步 I/O 中,一个 I/O 操作会阻塞程序的执行,直到操作完成。这意味着程序会等待 I/O 操作完成后再继续执行下一步。 -
异步 I/O:
在异步 I/O 中,一个 I/O 操作不会阻塞程序的执行。相反,程序可以继续执行其他任务,而不必等待 I/O 操作完成。当 I/O 操作完成时,程序会收到通知,然后可以处理已完成的操作。其实在我理解中比较类似中断机制
请求队列
块设备驱动可以一次传输一个扇区,但块I/O层并不会对一个扇区执行一次独立的I/O操作,因为在磁盘定位一个扇区的位置,是很耗时的工作。
内核尽可能聚集多个扇区,作为一次操作,这样就减少磁头的移动操作。
当内核读或写磁盘数据时,它就创建一个块设备请求,该请求主要描述请求的扇区、操作的类型(读还是写)。然而,当请求创建后,内核并不是立即执行请求,而是I/O操作仅是调度,且在稍后的时间才真正执行I/O操作。
这种延迟读写是提高读写性能的关键,还是一句话,如果一个个字符都要去磁盘读写,开销太大,所以需要积攒很多请求一次读写。
延迟请求的执行,使对块设备的处理变得复杂。例如,假设一个进程打开一个普通的文件,进而文件系统驱动从磁盘上读取文件的inode信息。块设备驱动将请求挂在队列上,进程挂起直到inode数据传输完毕。但块设备驱动本身不能阻塞,因为这样会导致其他访问该磁盘的进程也会被阻塞
为了避免块设备驱动阻塞,每个I/O操作的处理都是异步的。即块设备驱动是中断驱动的,通用块设备层触发I/O调度器来创建一个新块设备请求或者扩大已有的请求,然后结束。过一段时间后,块设备驱动激活并调用
服务例程来选择一个等待的请求,向磁盘控制器发送相应的命令来完成请求。当I/O操作结束时,磁盘控制器发起一个中断,必要时,相应的处理程序又调用服务例程,每个块设备驱动维护自己的请求队列,队列中包含了对该设备的等待请求链表。若磁盘控制器处理多个磁盘,通常每个块设备都会有一个请求队列。在各自的请求队列上进行单独的I/O调度,
read系统调用源码分析
内核版本为Linux2.6
设计思想
通过open我们知道,文件的操作是对
file结构体进行操作,从而操作和file结构体关联的inode,最终达到使用 文件的目的,所以猜测read首先就是怎么找到打开的file结构体,在对file结构体进行读写,一、入口函数
该函数是系统调用read的实现
// 函数名: 实现系统调用read,从文件中读取数据 // 参数: 文件描述符fd,用户空间缓冲区buf,读取的字节数count SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count) { struct file *file; ssize_t ret = -EBADF; // 用于标识是否需要释放文件结构体的标志 int fput_needed; // 获取文件结构体指针,同时获取是否需要释放的标志 file = fget_light(fd, &fput_needed); // 如果成功获取文件结构体指针 if (file) { loff_t pos = file_pos_read(file); // 调用vfs_read函数从文件中读取数据 ret = vfs_read(file, buf, count, &pos); file_pos_write(file, pos); // 释放文件结构体的引用计数 fput_light(file, fput_needed); } return ret; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
(1)
fget_light该函数就是获取
file结构体,肯定是从open返回的fd来获取file结构体的,因为在open中分析过,fd和所创建的file结构体关联在一起// 函数名: 获取轻量级的文件结构体指针 // 参数: 文件描述符fd,用于存储是否需要释放的标志的指针fput_needed struct file *fget_light(unsigned int fd, int *fput_needed) { // 获取当前进程的文件结构体指针 struct files_struct *files = current->files; *fput_needed = 0; // 如果当前进程持有的文件计数为1,说明只有一个引用 if (atomic_read(&files->count) == 1) { // 通过文件描述符在文件结构体数组中查找对应的文件结构体指针 file = fcheck_files(files, fd); if (file && (file->f_mode & FMODE_PATH)) file = NULL; } else { // 否则,当前进程持有的文件计数大于1,需要使用读取复制更新锁(RCU)进行访问 rcu_read_lock(); // 通过文件描述符在文件结构体数组中查找对应的文件结构体指针 file = fcheck_files(files, fd); // 如果找到文件结构体 if (file) { if (!(file->f_mode & FMODE_PATH) && atomic_long_inc_not_zero(&file->f_count)) // 设置需要释放的标志 *fput_needed = 1; else // 没有得到引用,说明文件可能已被释放,置空文件结构体指针 file = NULL; } // 释放读取复制更新锁 rcu_read_unlock(); } return file; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
文件计数(file count)通常是指一个进程打开文件时,与该文件相关的数据结构中的计数值。这个计数值记录了有多少个实体(例如,进程)正在引用这个文件。每次打开文件时,文件计数会增加;每次关闭文件时,文件计数会减少。文件计数的目的是确保在没有引用的情况下能够正确地释放相关的资源
(2)
fput_light// 函数名: 轻量级地释放文件结构体的引用计数 // 参数: 文件结构体指针file,是否需要释放的标志fput_needed static inline void fput_light(struct file *file, int fput_needed) { // 如果需要释放(fput_needed为真),则调用fput函数减少文件引用计数 if (fput_needed) fput(file); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
缓冲区
我们可以看到vfs_read函数有一个参数是buf,它代表用户空间的缓冲区。
程序读取文件并不是每一个字符就必须调用一次read系统调用,因为系统调用的开销太大了,所以就产生了一个缓冲区的概念,用一次read将大量信息读入缓冲区,然后程序从缓冲区读取信息即可
用户缓冲区的目的是为了减少系统调用次数,从而降低read系统调用的开销

从上图可以看到数据从磁盘到用户眼里需要两次read;原因是因为IO操作较内存实在是太慢了我们为了加快速度,将一块内存命名为内核缓冲区
我们在使用read是,会先在内核缓冲区查找有没有文件,如果没有就去磁盘中读取,这个过程当然要包含清空等操作。
二、
vfs_read函数该函数是虚拟文件系统的读取操作,但可以通过
file_operations结构体赋值来实现和真实的文件系统相关联,这是虚拟文件系统的核心,猜测其流程是通过前面找到的file结构体进行读取,先从缓冲区读,如果没有找到则进入真实文件系统进行io读取// 函数名: 在虚拟文件系统中执行读取操作 // 参数: 文件结构体指针file,用户空间缓冲区buf,读取的字节数count,文件位置指针pos ssize_t vfs_read(struct file *file, char __user *buf, size_t count, loff_t *pos) { ssize_t ret; // 检查文件是否有读权限 if (!(file->f_mode & FMODE_READ)) return -EBADF; // 检查文件操作是否存在且支持读取 if (!file->f_op || (!file->f_op->read && !file->f_op->aio_read)) return -EINVAL; // 检查用户空间缓冲区的合法性 if (unlikely(!access_ok(VERIFY_WRITE, buf, count))) return -EFAULT; // 验证文件读取区域是否合法 ret = rw_verify_area(READ, file, pos, count); // 如果验证通过 if (ret >= 0) { count = ret; // 如果文件操作中有read函数,则调用该函数进行读取 if (file->f_op->read) ret = file->f_op->read(file, buf, count, pos); else // 否则,调用同步读取函数 ret = do_sync_read(file, buf, count, pos); // 如果成功读取了数据 if (ret > 0) { // 发送文件访问通知 fsnotify_access(file); // 更新读取字符计数 add_rchar(current, ret); } // 增加系统调用计数 inc_syscr(current); } // 返回读取的字节数或错误码 return ret; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
可以看到
if (!file->f_op || (!file->f_op->read && !file->f_op->aio_read))表示检测读操作,原因是有些文件可能并不支持读取操作,比如一些特殊设备文件、管道、套接字等(1)
file_operations下面是ext4文件系统的
file_operations结构,其中file->f_op->read在该文件系统的实现方法是do_sync_readconst struct file_operations ext4_file_operations = { .llseek = ext4_llseek, .read = do_sync_read, .write = do_sync_write, .aio_read = generic_file_aio_read, .aio_write = ext4_file_write, .unlocked_ioctl = ext4_ioctl, #ifdef CONFIG_COMPAT .compat_ioctl = ext4_compat_ioctl, #endif .mmap = ext4_file_mmap, .open = ext4_file_open, .release = ext4_release_file, .fsync = ext4_sync_file, .splice_read = generic_file_splice_read, .splice_write = generic_file_splice_write, .fallocate = ext4_fallocate, };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
三、
do_sync_read可以看到该函数的核心是
filp->f_op->aio_read,所以我们直接看ext4文件系统file_operations结构体的相关成员// 函数名: 执行同步读取操作 // 参数: 文件结构体指针filp,用户空间缓冲区buf,读取的字节数len,文件位置指针ppos ssize_t do_sync_read(struct file *filp, char __user *buf, size_t len, loff_t *ppos) { // 创建一个 iovec 结构体,用于指定读取的缓冲区和长度 struct iovec iov = { .iov_base = buf, .iov_len = len }; // 创建一个 kiocb 结构体,用于表示同步 I/O 控制块 struct kiocb kiocb; ssize_t ret; // 初始化同步 kiocb 结构体 init_sync_kiocb(&kiocb, filp); // 设置 ki_pos 和 ki_nbytes 字段 kiocb.ki_pos = *ppos; kiocb.ki_left = len; kiocb.ki_nbytes = len; // 循环进行同步读取操作 for (;;) { // 调用文件操作的 aio_read 函数进行同步读取 ret = filp->f_op->aio_read(&kiocb, &iov, 1, kiocb.ki_pos); // 如果返回值不是 -EIOCBRETRY,则跳出循环 if (ret != -EIOCBRETRY) break; // 否则,等待重试 wait_on_retry_sync_kiocb(&kiocb); } // 如果返回值是 -EIOCBQUEUED,等待同步 kiocb 完成 if (-EIOCBQUEUED == ret) ret = wait_on_sync_kiocb(&kiocb); // 更新文件位置 *ppos = kiocb.ki_pos; // 返回读取的字节数或错误码 return ret; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
可以看到上面的代码是同步io读取操作,真正调用的是
aio_read进行读取。四、
generic_file_aio_read该代码执行异步io读取操作,
// 函数名: 执行通用的异步 I/O 读取操作 // 参数: kiocb 结构体指针iocb,iovec 结构体数组iov,iovec 数组元素数量nr_segs,文件位置pos ssize_t generic_file_aio_read(struct kiocb *iocb, const struct iovec *iov, unsigned long nr_segs, loff_t pos) { struct file *filp = iocb->ki_filp; // 获取文件结构体指针 ssize_t retval; // 返回值 unsigned long seg = 0; // iov 数组的索引 size_t count; loff_t *ppos = &iocb->ki_pos; // 文件位置指针 struct blk_plug plug; // 块设备插件结构体,用于块设备操作的性能优化 count = 0; // 执行通用的 I/O 段检查,检查 iov 数组的有效性,验证写操作的可行性 retval = generic_segment_checks(iov, &nr_segs, &count, VERIFY_WRITE); if (retval) return retval; blk_start_plug(&plug); // 开始块设备插件,用于性能优化 /* 对于 O_DIRECT,合并 iovecs 并直接到 BIO(块 I/O 操作) */ if (filp->f_flags & O_DIRECT) { loff_t size; struct address_space *mapping; struct inode *inode; mapping = filp->f_mapping; inode = mapping->host; if (!count) goto out; // 跳过 atime 更新 size = i_size_read(inode); if (pos < size) { retval = filemap_write_and_wait_range(mapping, pos, pos + iov_length(iov, nr_segs) - 1); if (!retval) { retval = mapping->a_ops->direct_IO(READ, iocb, iov, pos, nr_segs); } if (retval > 0) { *ppos = pos + retval; count -= retval; } // 如果遇到错误,或者已经读取了所有需要的数据,或者已经到达文件末尾,直接返回 if (retval < 0 || !count || *ppos >= size) { file_accessed(filp); goto out; } } } count = retval; // 遍历 iov 数组进行读取 for (seg = 0; seg < nr_segs; seg++) { read_descriptor_t desc; loff_t offset = 0; // 如果进行了短的直接 I/O 读取,需要跳过已经读取数据的 iov 段 if (count) { if (count > iov[seg].iov_len) { count -= iov[seg].iov_len; continue; } offset = count; count = 0; } // 初始化读取描述符 desc.written = 0; desc.arg.buf = iov[seg].iov_base + offset; desc.count = iov[seg].iov_len - offset; if (desc.count == 0) continue; desc.error = 0; // 调用通用文件读取函数,执行文件读取操作 do_generic_file_read(filp, ppos, &desc, file_read_actor); retval += desc.written; // 处理错误情况 if (desc.error) { retval = retval ?: desc.error; break; } if (desc.count > 0) break; } out: blk_finish_plug(&plug); // 结束块设备插件 return retval; // 返回读取的字节数或错误码 } EXPORT_SYMBOL(generic_file_aio_read); // 导出该函数,使其可在模块间共享- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
1. 块请求
(1)
blk_start_plug该部分是块合并的代码,为了提高IO的性能,将多个IO请求合并,最终减少IO的开销
void blk_start_plug(struct blk_plug *plug) { // 获取当前进程的任务结构体指针 struct task_struct *tsk = current; // 初始化块合并结构体 plug->magic = PLUG_MAGIC; // 设置魔术数字,用于标识结构体是否有效 INIT_LIST_HEAD(&plug->list); // 初始化块合并结构体中的链表 list INIT_LIST_HEAD(&plug->cb_list); // 初始化块合并结构体中的链表 cb_list plug->should_sort = 0; // 初始化块合并结构体的排序标志 /* * 如果这是一个嵌套的块合并,不实际分配它。它将在其自己的地方被刷新。 */ if (!tsk->plug) { /* * 存储顺序在这里不应该是必需的,因为潜在的抢占将意味着一个完整的内存屏障 */ tsk->plug = plug; // 将块合并结构体指针赋给当前任务结构体的 plug 字段 } } EXPORT_SYMBOL(blk_start_plug); // 导出函数,使其他模块或文件可以使用这个函数- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
(2)
blk_plug结构体管理在进行块设备的I/O合并所产生的结构体
struct blk_plug { unsigned long magic; // 用于标识结构体的魔术数字(magic number) struct list_head list; // 创建链表节点,用于连接多个I/O请求的结构体 struct list_head cb_list; // 用于创建另一个链表节点,可能用于额外的管理或控制 unsigned int should_sort; // 一个标志位,指示是否应对I/O请求进行排序 };- 1
- 2
- 3
- 4
- 5
- 6
(3)
blk_finish_plug函数结束合并,同时将合并的数据刷新到块设备。起到泄洪的作用
void blk_finish_plug(struct blk_plug *plug) { // 将块合并列表刷新到块设备 blk_flush_plug_list(plug, false); // 如果当前任务的块合并指针等于给定的块合并结构体指针 if (plug == current->plug) // 将当前任务的块合并指针置为空 current->plug = NULL; } EXPORT_SYMBOL(blk_finish_plug); // 导出函数,使其他模块或文件可以使用这个函数- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
五、
do_generic_file_read函数一个文件的读取就是读取它的page,而page就是address_space在内存的映射,是页缓存和外部设备中文件系统的桥梁。重点就是找到这个映射关系,这就涉及到read的两次读取操作,1次在内存,内存就是page找不到,然后进入文件系统采取2次读,将信息映射到page,中间会涉及内存的换入换出,最后成功找到将数据拷贝到用户缓冲区
error = mapping->a_ops->readpage(filp, page)该行代码将会启动实际的读取操作,这个结合具体文件系统分析// 函数名: 执行通用的文件读取操作 // 参数: 文件结构体指针filp,文件位置指针ppos,读取描述符结构体指针desc,读取处理函数指针actor static void do_generic_file_read(struct file *filp, loff_t *ppos, read_descriptor_t *desc, read_actor_t actor) { struct address_space *mapping = filp->f_mapping; // 获取文件映射结构体指针 struct inode *inode = mapping->host; // 获取文件对应的inode结构体指针 struct file_ra_state *ra = &filp->f_ra; // 获取文件读取预取状态结构体指针 pgoff_t index; pgoff_t last_index; pgoff_t prev_index; unsigned long offset; /* offset into pagecache page */ unsigned int prev_offset; int error; index = *ppos >> PAGE_CACHE_SHIFT; // 计算当前位置在页表中的页索引 prev_index = ra->prev_pos >> PAGE_CACHE_SHIFT; // 获取上一次预读取的位置在页表中的页索引 prev_offset = ra->prev_pos & (PAGE_CACHE_SIZE-1); // 获取上一次预读取的位置在页内的偏移量 last_index = (*ppos + desc->count + PAGE_CACHE_SIZE-1) >> PAGE_CACHE_SHIFT; // 计算要读取的数据范围的最后一页的索引 offset = *ppos & ~PAGE_CACHE_MASK; // 计算当前位置在页内的偏移量 for (;;) { struct page *page; pgoff_t end_index; loff_t isize; unsigned long nr, ret; cond_resched(); // 调度检查 find_page: // 查找并获取页缓存中的页 page = find_get_page(mapping, index); if (!page) { // 如果页不存在,则进行预读取 page_cache_sync_readahead(mapping, ra, filp, index, last_index - index); // 再次查找获取页 page = find_get_page(mapping, index); if (unlikely(page == NULL)) goto no_cached_page; } // 如果页已经标记为预读取,进行异步预读取 if (PageReadahead(page)) { page_cache_async_readahead(mapping, ra, filp, page, index, last_index - index); } // 如果页不是最新的,跳转到处理不是最新的页的部分 if (!PageUptodate(page)) { if (inode->i_blkbits == PAGE_CACHE_SHIFT || !mapping->a_ops->is_partially_uptodate) goto page_not_up_to_date; // 尝试获取页锁 if (!trylock_page(page)) goto page_not_up_to_date; /* 如果在获取锁之前页已经被截断,则跳转到处理页不是最新的部分 */ if (!page->mapping) goto page_not_up_to_date_locked; /* 如果页的部分数据不是最新的,则跳转到处理页不是最新的部分 */ if (!mapping->a_ops->is_partially_uptodate(page, desc, offset)) goto page_not_up_to_date_locked; // 解锁页 unlock_page(page); } page_ok: /* * 在知道页是最新的之后,必须检查 i_size。 * 在检查之后允许我们计算 "nr" 的正确值, * 这意味着页的零填充部分不会被复制回用户空间 * (除非另一个截断扩展文件 - 这是期望的)。 */ isize = i_size_read(inode); // 读取文件大小 end_index = (isize - 1) >> PAGE_CACHE_SHIFT; // 计算文件末尾页的索引 // 如果文件大小为0,或者当前页索引大于文件末尾页的索引,则释放页并跳转到结束 if (unlikely(!isize || index > end_index)) { page_cache_release(page); goto out; } /* nr 是从这一页复制到用户空间的最大字节数 */ nr = PAGE_CACHE_SIZE; // 如果当前页是文件末尾页,计算要复制的字节数 if (index == end_index) { nr = ((isize - 1) & ~PAGE_CACHE_MASK) + 1; // 如果要复制的字节数小于等于当前偏移量,释放页并跳转到结束 if (nr <= offset) { page_cache_release(page); goto out; } } nr = nr - offset; /* 如果用户可能使用任意虚拟地址写入此页,需要在内核端读取页之前注意潜在的别名问题。 */ if (mapping_writably_mapped(mapping)) flush_dcache_page(page); /* * 当顺序读取多次访问同一页时,仅在第一次标记为已访问。 */ if (prev_index != index || offset != prev_offset) mark_page_accessed(page); prev_index = index; /* * 现在,我们有了页,它是最新的,所以现在可以将它复制到用户空间... * * actor 函数返回实际使用的字节数。 * 注意!这可能与我们填充的用户缓冲区量不同(可能存在填充等),因此我们只能在这里更新 "ppos" * (actor 函数必须更新用户缓冲区指针和剩余计数)。 */ ret = actor(desc, page, offset, nr); offset += ret; index += offset >> PAGE_CACHE_SHIFT; offset &= ~PAGE_CACHE_MASK; prev_offset = offset; page_cache_release(page); // 如果实际使用的字节数等于要复制的字节数且还有剩余未读取的数据,则继续循环 if (ret == nr && desc->count) continue; goto out; page_not_up_to_date: /* 获取对页的独占访问权... */ error = lock_page_killable(page); // 如果获取页锁失败,则跳转到读取错误处理 if (unlikely(error)) goto readpage_error; page_not_up_to_date_locked: /* 如果在获取锁之前页已经被截断,则释放页并继续查找下一页 */ if (!page->mapping) { unlock_page(page); page_cache_release(page); continue; } /* 如果其他进程已经填充了它,则解锁页并跳转到处理页已经是最新的部分 */ if (PageUptodate(page)) { unlock_page(page); goto page_ok; } readpage: /* * 以前的 I/O 错误可能是由于临时故障引起的,例如多路径错误。 * 如果 readpage 失败,PG_error 将再次设置。 */ ClearPageError(page); /* 启动实际读取。读取将解锁页。 */ error = mapping->a_ops->readpage(filp, page); // 如果读取成功,但页仍不是最新的,则加锁页,标记为错误,释放页并跳转到读取错误处理 if (unlikely(error)) { if (error == AOP_TRUNCATED_PAGE) { page_cache_release(page); goto find_page; } goto readpage_error; } // 如果页仍不是最新的,则加锁页,标记为错误,并跳转到读取错误处理 if (!PageUptodate(page)) { error = lock_page_killable(page); if (unlikely(error)) goto readpage_error; if (!PageUptodate(page)) { // 如果页的映射被清除,则继续查找下一页 if (page->mapping == NULL) { unlock_page(page); page_cache_release(page); goto find_page; } // 解锁页,缩小预读取大小,并设置错误码为 -EIO unlock_page(page); shrink_readahead_size_eio(filp, ra); error = -EIO; goto readpage_error; } unlock_page(page); } // 跳转到处理页是最新的部分 goto page_ok; readpage_error: /* 啊呼!同步读取错误发生。报告它 */ desc->error = error; // 释放页并跳转到结束 page_cache_release(page); goto out; no_cached_page: /* * 好吧,它没有缓存,因此我们需要创建一个新的页。 */ page = page_cache_alloc_cold(mapping); if (!page) { // 如果分配内存失败,则设置错误码并跳转到结束 desc->error = -ENOMEM; goto out; } // 将页添加到页缓存,并获取页锁 error = add_to_page_cache_lru(page, mapping, index, GFP_KERNEL); // 如果添加到页缓存失败,则释放页并继续查找下一页 if (error) { page_cache_release(page); if (error == -EEXIST) goto find_page; // 设置错误码并跳转到结束 desc->error = error; goto out; } // 跳转到执行页读取 goto readpage; } out: // 更新预读取状态的上一次位置 ra->prev_pos = prev_index; ra->prev_pos <<= PAGE_CACHE_SHIFT; ra->prev_pos |= prev_offset; // 更新文件位置,并标记文件为已访问 *ppos = ((loff_t)index << PAGE_CACHE_SHIFT) + offset; file_accessed(filp); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
1. 页缓存
该结构体用于描述系统中的物理内存页面。每个
struct page结构体通常代表内核中的一页物理内存struct page { unsigned long flags; /* 原子标志,一些可能会异步更新 */ atomic_t _count; /* 使用计数,见下文 */ union { atomic_t _mapcount; /* 在内存映射中映射的pte的计数, * 用于显示页面何时被映射 * 并限制反向映射搜索。 */ struct { /* SLUB分配器相关 */ u16 inuse; u16 objects; }; }; union { struct { unsigned long private; /* 映射私有的不透明数据: * 通常用于buffer_heads * 如果PagePrivate设置; * 用于swp_entry_t如果PageSwapCache; */ struct address_space *mapping; /* 如果低位清零,指向 * inode的address_space,或者为NULL。 * 如果页面映射为匿名内存, * 低位设置,指向anon_vma对象: */ }; #if USE_SPLIT_PTLOCKS spinlock_t ptl; #endif struct kmem_cache *slab; /* SLUB分配器:指向slab的指针 */ struct page *first_page; /* 复合页面的尾部页面 */ }; union { pgoff_t index; /* 映射内的偏移量。 */ void *freelist; /* SLUB分配器:空闲列表,需要持有slab锁 */ }; struct list_head lru; /* 页面出列表,例如活动列表 * 受zone->lru_lock保护! */ #if defined(WANT_PAGE_VIRTUAL) void *virtual; /* 内核虚拟地址(如果没有映射,即高端内存为NULL) */ #endif /* WANT_PAGE_VIRTUAL */ #ifdef CONFIG_WANT_PAGE_DEBUG_FLAGS unsigned long debug_flags; /* 对其使用原子位操作 */ #endif #ifdef CONFIG_KMEMCHECK /* * kmemcheck希望跟踪页面中每个字节的状态; * 这是一个指向这样一个状态块的指针。如果未跟踪,则为NULL。 */ void *shadow; #endif };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
2. 内存和文件的映射
(1)
address_space结构体描述文件在内存中的映射,每个
struct address_space结构体代表文件的地址空间,它维护了文件在内存中的映射信息。page 就像书的页,address_space 就像每一本书。只不过这些数据结构更侧重管理文件方面,就像file一样
struct address_space { struct inode *host; /* owner: inode, block_device */ struct radix_tree_root page_tree; /* radix tree of all pages */ spinlock_t tree_lock; /* and lock protecting it */ unsigned int i_mmap_writable;/* count VM_SHARED mappings */ struct prio_tree_root i_mmap; /* tree of private and shared mappings */ struct list_head i_mmap_nonlinear;/*list VM_NONLINEAR mappings */ spinlock_t i_mmap_lock; /* protect tree, count, list */ unsigned int truncate_count; /* Cover race condition with truncate */ unsigned long nrpages; /* number of total pages */ pgoff_t writeback_index;/* writeback starts here */ const struct address_space_operations *a_ops; /* methods */ unsigned long flags; /* error bits/gfp mask */ struct backing_dev_info *backing_dev_info; /* device readahead, etc */ spinlock_t private_lock; /* for use by the address_space */ struct list_head private_list; /* ditto */ struct address_space *assoc_mapping; /* ditto */ struct mutex unmap_mutex; /* to protect unmapping */ } __attribute__((aligned(sizeof(long))));- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
(2)
address_space_operations结构体// 结构体定义:address_space_operations,表示与地址空间相关的操作集合 struct address_space_operations { // 将页面写回到存储介质(写回脏页)的操作 int (*writepage)(struct page *page, struct writeback_control *wbc); // 从存储介质中读取一页到内存的操作 int (*readpage)(struct file *, struct page *); // 从给定地址空间中写回一些脏页的操作 int (*writepages)(struct address_space *, struct writeback_control *); // 标记页面为脏页,返回是否成功标记 int (*set_page_dirty)(struct page *page); // 从文件中读取一页或多页的操作 int (*readpages)(struct file *filp, struct address_space *mapping, struct list_head *pages, unsigned nr_pages); // 开始对页的写入操作 int (*write_begin)(struct file *, struct address_space *mapping, loff_t pos, unsigned len, unsigned flags, struct page **pagep, void **fsdata); // 完成对页的写入操作 int (*write_end)(struct file *, struct address_space *mapping, loff_t pos, unsigned len, unsigned copied, struct page *page, void *fsdata); // 获取文件中指定地址空间的块映射(避免使用) sector_t (*bmap)(struct address_space *, sector_t); // 使页失效的操作 void (*invalidatepage)(struct page *, unsigned long); // 释放页的操作 int (*releasepage)(struct page *, gfp_t); // 释放页的内存的操作 void (*freepage)(struct page *); // 直接 I/O 操作,绕过页缓存进行数据传输 ssize_t (*direct_IO)(int, struct kiocb *, const struct iovec *iov, loff_t offset, unsigned long nr_segs); // 获取用于直接执行的内存块 int (*get_xip_mem)(struct address_space *, pgoff_t, int, void **, unsigned long *); // 将页面的内容迁移到指定的目标 int (*migratepage)(struct address_space *, struct page *, struct page *); // 清理页的操作 int (*launder_page)(struct page *); // 检查页面是否部分更新 int (*is_partially_uptodate)(struct page *, read_descriptor_t *, unsigned long); // 处理移除页面时的错误 int (*error_remove_page)(struct address_space *, struct page *); };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
(3)ext4文件系统的
address_space_operationsstatic const struct address_space_operations ext4_ordered_aops = { .readpage = ext4_readpage, // 读取单页 .readpages = ext4_readpages, // 读取多页 .writepage = ext4_writepage, // 写入单页 .write_begin = ext4_write_begin, // 开始写入 .write_end = ext4_ordered_write_end, // 结束有序写入 .bmap = ext4_bmap, // 块映射 .invalidatepage = ext4_invalidatepage, // 使页无效 .releasepage = ext4_releasepage, // 释放页 .direct_IO = ext4_direct_IO, // 直接 I/O 操作 .migratepage = buffer_migrate_page, // 迁移页 .is_partially_uptodate = block_is_partially_uptodate, // 检查部分是否已更新 .error_remove_page = generic_error_remove_page, // 移除错误页 };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
(4)
ext4_readpagesstatic int ext4_readpages(struct file *file, struct address_space *mapping, struct list_head *pages, unsigned nr_pages) { return mpage_readpages(mapping, pages, nr_pages, ext4_get_block); }- 1
- 2
- 3
- 4
- 5
- 6
2.
file_read_actor函数该部分的调用是
ret = actor(desc, page, offset, nr);所调用的函数,这就是将页面的数据换到用户空间,在我的理解中就是你把内核缓冲区的数据放入用户缓冲区中,所以重点就在怎么把信息放入page结构体中,下面的代码就是将数据放入page结构体中/* * 文件读取的执行器,用于将页面的数据传输到用户空间 * 参数: * - desc: 读取操作的描述符,包含有关操作的信息 * - page: 要读取的页面 * - offset: 在页面中的偏移量,表示从页面的哪个位置开始读取 * - size: 要读取的字节数 */ int file_read_actor(read_descriptor_t *desc, struct page *page, unsigned long offset, unsigned long size) { char *kaddr; unsigned long left, count = desc->count; // 如果要读取的字节数大于剩余的字节数,调整 size if (size > count) size = count; /* * 在进行 kmap 之前,检查读取目标的页面是否可写。 * 由于在读取操作中,目标页面可能会发生缺页异常,因此进行此检查。 */ if (!fault_in_pages_writeable(desc->arg.buf, size)) { // 使用 kmap_atomic 将页面映射到内核地址空间 kaddr = kmap_atomic(page, KM_USER0); // 使用 __copy_to_user_inatomic 将数据从内核拷贝到用户空间 left = __copy_to_user_inatomic(desc->arg.buf, kaddr + offset, size); // 解除页面的内核映射 kunmap_atomic(kaddr, KM_USER0); // 如果成功拷贝完所有数据,跳转到 success 标签 if (left == 0) goto success; } /* 如果无法使用原子操作方式拷贝数据,则使用传统方式 */ // 使用 kmap 将页面映射到内核地址空间 kaddr = kmap(page); // 使用 __copy_to_user 将数据从内核拷贝到用户空间 left = __copy_to_user(desc->arg.buf, kaddr + offset, size); // 解除页面的内核映射 kunmap(page); // 如果拷贝未完成,更新错误码并调整 size if (left) { size -= left; desc->error = -EFAULT; } // 成功时的标签 success: // 更新描述符中的信息:剩余字节数、已写入字节数、目标缓冲区指针 desc->count = count - size; desc->written += size; desc->arg.buf += size; // 返回实际拷贝的字节数 return size; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
六、
mpage_readpages在ext4文件系统进行读取页的操作,间接调用
ext4_get_block(),真的搞清楚数据在硬盘里面的摆列位置,并依据这个信息,转化出来一个个的bio,然后提交请求因为前面都是page,现在的目的是找到page在文件系统中的映射,也就是内存和文件系统的桥梁
address_space现在我们就进入通用块层了,这里就需要
bio结构体,表示块设备 I/O 操作的数据结构,bio结构体包含一个指向block_device的指针int mpage_readpages(struct address_space *mapping, struct list_head *pages, unsigned nr_pages, get_block_t get_block) { struct bio *bio = NULL; // 用于构建 BIO(块 I/O 操作) unsigned page_idx; sector_t last_block_in_bio = 0; struct buffer_head map_bh; // 用于存储映射的缓冲区头 unsigned long first_logical_block = 0; struct blk_plug plug; // 用于块层次的 I/O 提交 blk_start_plug(&plug); // 启动块层次的 I/O 插件 map_bh.b_state = 0; // 初始化映射缓冲区头状态 map_bh.b_size = 0; // 初始化映射缓冲区头大小 for (page_idx = 0; page_idx < nr_pages; page_idx++) { struct page *page = list_entry(pages->prev, struct page, lru); prefetchw(&page->flags); // 预取页面标志 list_del(&page->lru); // 从LRU链表中删除页 // 将页添加到页缓存中,如果成功,则执行多页读取 if (!add_to_page_cache_lru(page, mapping, page->index, GFP_KERNEL)) { bio = do_mpage_readpage(bio, page, nr_pages - page_idx, &last_block_in_bio, &map_bh, &first_logical_block, get_block); } page_cache_release(page); // 释放页面引用 } BUG_ON(!list_empty(pages)); // 如果页链表不为空,则发出 BUG 警告 // 如果构建了 BIO,则提交多页读取的 BIO if (bio) mpage_bio_submit(READ, bio); blk_finish_plug(&plug); // 结束块层次的 I/O 插件 return 0; } EXPORT_SYMBOL(mpage_readpages); // 导出该函数,使其可供其他模块使用- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
(1)
bio结构体bio是块 I/O 操作的描述符,用于表示对块设备的读写请求。而
block_device是硬盘这些块设备的抽象,在我的理解里bio和block_device的关系和inode和file关系类似,bio是file结构体每个块I/O请求都通过一个或多个
bio结构体表示。每个请求包含一个或多个块,这些块存储在bio_vec结构体数组中说到底,
bio表示的就是每次读写请求所抽象出来的数据结构/* * bio 结构体是块层和底层(即驱动程序和堆叠驱动程序)I/O 的主要单元。 */ struct bio { sector_t bi_sector; /* 设备地址,以 512 字节扇区为单位 */ struct bio *bi_next; /* 请求队列链接 */ struct block_device *bi_bdev; unsigned long bi_flags; /* 状态、命令等 */ unsigned long bi_rw; /* 最低位 READ/WRITE,最高位优先级 */ unsigned short bi_vcnt; /* bio_vec 的数量 */ unsigned short bi_idx; /* bvl_vec 中的当前索引 */ /* 物理地址合并后的 BIO 中的段数 */ unsigned int bi_phys_segments; unsigned int bi_size; /* 剩余的 I/O 计数 */ /* * 为了跟踪最大段大小,我们考虑此 bio 中第一个和最后一个可合并段的大小。 */ unsigned int bi_seg_front_size; unsigned int bi_seg_back_size; unsigned int bi_max_vecs; /* 最大的 bvl_vecs 数量 */ unsigned int bi_comp_cpu; /* 完成 CPU */ atomic_t bi_cnt; /* 引用计数 */ struct bio_vec *bi_io_vec; /* 实际的 vec 列表 */ bio_end_io_t *bi_end_io; void *bi_private; #if defined(CONFIG_BLK_DEV_INTEGRITY) struct bio_integrity_payload *bi_integrity; /* 数据完整性 */ #endif bio_destructor_t *bi_destructor; /* 析构函数 */ /* * 我们可以内联一些 vec 到 bio 的末尾,以避免为少量的 bio_vec 进行双重分配。 * 此成员显然必须保持在 bio 的最末尾。 */ struct bio_vec bi_inline_vecs[0]; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
(2)
bio_vec结构体该结构体描述的是一个特定的段:段所在的物理页、块在物理页中的偏移量、从给定偏移量开始的块长度
/** * bv_page: 指向数据所在的页的指针,即物理内存页面 * bv_len: 数据段的长度,从 bv_page 开始的有效数据长度 * bv_offset: 数据在 bv_page 中的偏移量,指定了在 bv_page 页面中从哪个位置开始存储有效数据 */ struct bio_vec { struct page *bv_page; unsigned int bv_len; unsigned int bv_offset; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
可以看到
bio_vec和page之间的关系

七、
do_mpage_readpage函数该函数来自
mpage_readpages函数的调用,在ext4文件系统实现页读取时,就会调用到该函数。该部分代码的作用就是将块设备的读取转换成bio请求,方便后期直接提交bio请求,而不用提交块设备的相关信息
static struct bio * do_mpage_readpage(struct bio *bio, struct page *page, unsigned nr_pages, sector_t *last_block_in_bio, struct buffer_head *map_bh, unsigned long *first_logical_block, get_block_t get_block) { struct inode *inode = page->mapping->host; const unsigned blkbits = inode->i_blkbits; const unsigned blocks_per_page = PAGE_CACHE_SIZE >> blkbits; const unsigned blocksize = 1 << blkbits; sector_t block_in_file; sector_t last_block; sector_t last_block_in_file; sector_t blocks[MAX_BUF_PER_PAGE]; unsigned page_block; unsigned first_hole = blocks_per_page; struct block_device *bdev = NULL; int length; int fully_mapped = 1; unsigned nblocks; unsigned relative_block; // 如果页面已经有缓冲区,则跳到混淆(confused)标签 if (page_has_buffers(page)) goto confused; // 计算块在文件中的位置和最后的块号 block_in_file = (sector_t)page->index << (PAGE_CACHE_SHIFT - blkbits); last_block = block_in_file + nr_pages * blocks_per_page; last_block_in_file = (i_size_read(inode) + blocksize - 1) >> blkbits; if (last_block > last_block_in_file) last_block = last_block_in_file; page_block = 0; // 使用上次 get_blocks 调用的结果首先映射块 nblocks = map_bh->b_size >> blkbits; if (buffer_mapped(map_bh) && block_in_file > *first_logical_block && block_in_file < (*first_logical_block + nblocks)) { unsigned map_offset = block_in_file - *first_logical_block; unsigned last = nblocks - map_offset; for (relative_block = 0; ; relative_block++) { if (relative_block == last) { clear_buffer_mapped(map_bh); break; } if (page_block == blocks_per_page) break; blocks[page_block] = map_bh->b_blocknr + map_offset + relative_block; page_block++; block_in_file++; } bdev = map_bh->b_bdev; } // 对该页面执行更多的 get_blocks 调用,直到完成该页面的映射 map_bh->b_page = page; while (page_block < blocks_per_page) { map_bh->b_state = 0; map_bh->b_size = 0; // 如果块在文件中且在页面的范围内,则获取块信息 if (block_in_file < last_block) { map_bh->b_size = (last_block-block_in_file) << blkbits; if (get_block(inode, block_in_file, map_bh, 0)) goto confused; *first_logical_block = block_in_file; } // 如果块未被映射,则标记未完全映射 if (!buffer_mapped(map_bh)) { fully_mapped = 0; if (first_hole == blocks_per_page) first_hole = page_block; page_block++; block_in_file++; continue; } // 如果缓冲区已经更新,则将数据映射到页面的缓冲区 if (buffer_uptodate(map_bh)) { map_buffer_to_page(page, map_bh, page_block); goto confused; } // 如果是连续的块,则添加到 blocks 数组 if (first_hole != blocks_per_page) goto confused; /* hole -> non-hole */ if (page_block && blocks[page_block-1] != map_bh->b_blocknr-1) goto confused; nblocks = map_bh->b_size >> blkbits; for (relative_block = 0; ; relative_block++) { if (relative_block == nblocks) { clear_buffer_mapped(map_bh); break; } else if (page_block == blocks_per_page) break; blocks[page_block] = map_bh->b_blocknr+relative_block; page_block++; block_in_file++; } bdev = map_bh->b_bdev; } // 如果存在空洞,填充零,并设置页面为已更新 if (first_hole != blocks_per_page) { zero_user_segment(page, first_hole << blkbits, PAGE_CACHE_SIZE); if (first_hole == 0) { SetPageUptodate(page); unlock_page(page); goto out; } } else if (fully_mapped) { SetPageMappedToDisk(page); } // 如果存在前一个 BIO 并且上一个 BIO 的最后一个块不是当前 blocks 数组的第一个块的前一个块,则提交上一个 BIO if (bio && (*last_block_in_bio != blocks[0] - 1)) bio = mpage_bio_submit(READ, bio); // 分配新的 BIO alloc_new: if (bio == NULL) { bio = mpage_alloc(bdev, blocks[0] << (blkbits - 9), min_t(int, nr_pages, bio_get_nr_vecs(bdev)), GFP_KERNEL); if (bio == NULL) goto confused; } // 将页面添加到 BIO 中 length = first_hole << blkbits; if (bio_add_page(bio, page, length, 0) < length) { bio = mpage_bio_submit(READ, bio); goto alloc_new; } // 计算相对块数 relative_block = block_in_file - *first_logical_block; nblocks = map_bh->b_size >> blkbits; // 如果达到缓冲区边界并且相对块数等于块数,则提交 BIO if ((buffer_boundary(map_bh) && relative_block == nblocks) || (first_hole != blocks_per_page)) bio = mpage_bio_submit(READ, bio); else *last_block_in_bio = blocks[blocks_per_page - 1]; out: return bio; confused: if (bio) bio = mpage_bio_submit(READ, bio); if (!PageUptodate(page)) block_read_full_page(page, get_block); else unlock_page(page); goto out; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
八、
mpage_bio_submit该函数就是提交
bio请求。/** * rw: 读取(READ)或写入(WRITE)操作 * bio: 待提交的 BIO 结构 */ static struct bio *mpage_bio_submit(int rw, struct bio *bio) { // 设置 BIO 的结束 I/O 回调函数为 mpage_end_io bio->bi_end_io = mpage_end_io; // 提交 BIO submit_bio(rw, bio); // 返回 NULL,表示提交成功 return NULL; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
九、
submit_bio该函数设置
bio->bi_rw的值,即确定数据传输方向。若属于正常的读写数据,就在提交任务之前,更新I/O统计信息。然后调用generic_make_request。/** * submit_bio - 将 BIO 提交给块设备层进行 I/O * @rw: 读取(READ)或写入(WRITE),或者是预读(READA) * @bio: 描述 I/O 操作的 &struct bio 结构 * * submit_bio() 的目的与 generic_make_request() 非常相似,它使用该函数来完成大部分工作。 * 这两者都是相当底层的接口;@bio 必须经过预设置并准备好进行 I/O 操作。 */ void submit_bio(int rw, struct bio *bio) { // 获取 BIO 所涉及的扇区数 int count = bio_sectors(bio); // 将 rw 标志合并到 BIO 的 bi_rw 字段中 bio->bi_rw |= rw; /* * 如果是普通的读取/写入操作或者带有数据的屏障,提交之前进行正常的计数处理。 */ if (bio_has_data(bio) && !(rw & REQ_DISCARD)) { if (rw & WRITE) { // 写操作时更新页面交换计数 count_vm_events(PGPGOUT, count); } else { // 读操作时更新页面交换计数,并记录读取的字节数 task_io_account_read(bio->bi_size); count_vm_events(PGPGIN, count); } // 在块转储开启时输出块 I/O 操作的调试信息 if (unlikely(block_dump)) { char b[BDEVNAME_SIZE]; printk(KERN_DEBUG "%s(%d): %s block %Lu on %s (%u sectors)\n", current->comm, task_pid_nr(current), (rw & WRITE) ? "WRITE" : "READ", (unsigned long long)bio->bi_sector, bdevname(bio->bi_bdev, b), count); } } // 调用 generic_make_request 函数提交 BIO generic_make_request(bio); } EXPORT_SYMBOL(submit_bio);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
十、
generic_make_request块设备请求队列的获取
函数主要功能为维护进程bio链表和对__generic_make_request()的直接封装调用。/* * generic_make_request - 将缓冲区提交给块设备进行 I/O 操作 * @bio: 描述内存位置和设备的 &struct bio * * generic_make_request() 用于向块设备提交 I/O 请求。接收描述 I/O 的 &struct bio。 */ void generic_make_request(struct bio *bio) { // 用于堆栈上的 bio_list 结构 struct bio_list bio_list_on_stack; if (current->bio_list) { /* make_request 处于活动状态,将 bio 添加到 bio_list 中 */ bio_list_add(current->bio_list, bio); return; } /* * 以下循环的设计用于保持结构简单,确保只调用一次 __generic_make_request。 * 在进入循环之前,bio->bi_next 为 NULL,因此我们有一个包含单个 bio 的列表。 * 循环模拟从列表中取出 bio,然后调用 __generic_make_request,期间可能递归添加更多的 bios。 */ BUG_ON(bio->bi_next); bio_list_init(&bio_list_on_stack); current->bio_list = &bio_list_on_stack; do { __generic_make_request(bio); bio = bio_list_pop(current->bio_list); } while (bio); current->bio_list = NULL; /* 停用 */ } EXPORT_SYMBOL(generic_make_request); // 导出该函数,使其可供其他模块使用- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
十一、
__generic_make_request__generic_make_request函数会调用块设备的make_request_fn方法。调用
blk_partition_remap函数检查该块设备是否是一个磁盘分区,如果是个分区,则需要做一些转化。调用
q->make_request_fn把bio请求插入到请求队列中。q->make_request_fn把通用块层和I/O调度层连接起来,make_request_fn的值是在块设备驱动在加载时里调用blk_init_queue设置。块设备层的操作也就到这里结束了/** * generic_make_request - 将缓冲区提交给设备驱动程序进行 I/O * @bio: 描述内存和设备上位置的 bio 结构 * * generic_make_request() 用于对块设备进行 I/O 请求。它接收一个描述需要执行的 I/O 的 &struct bio。 * * generic_make_request() 不返回任何状态。请求的成功/失败状态以及完成的通知将通过 bio->bi_end_io 函数(在其他地方进行描述)异步传递。 * * 调用 generic_make_request 的调用者必须确保 bi_io_vec 已设置以描述内存缓冲区,并且 bi_dev 和 bi_sector 已设置以描述设备地址,而 bi_end_io 和可选的 bi_private 已设置以描述完成通知的方式。 * * generic_make_request 和其调用的驱动程序可以在此 bio 与其他 bio 合并时使用 bi_next,可以根据需要更改 bi_dev 和 bi_sector 进行重新映射。因此,在调用 generic_make_request 后不应依赖于这些字段的值。 */ static inline void __generic_make_request(struct bio *bio) { struct request_queue *q; sector_t old_sector; int ret, nr_sectors = bio_sectors(bio); dev_t old_dev; int err = -EIO; might_sleep(); if (bio_check_eod(bio, nr_sectors)) goto end_io; /* * 解析映射直到完成。(驱动程序仍然可以通过明确返回 0 来实现/解析它们自己的堆叠) * * 注意:我们不会为每个新设备重复 blk_size 检查。 * 堆叠驱动程序应该知道自己在做什么。 */ old_sector = -1; old_dev = 0; do { char b[BDEVNAME_SIZE]; q = bdev_get_queue(bio->bi_bdev); if (unlikely(!q)) { printk(KERN_ERR "generic_make_request: 尝试访问不存在的块设备 %s (%Lu)\n", bdevname(bio->bi_bdev, b), (long long) bio->bi_sector); goto end_io; } if (unlikely(!(bio->bi_rw & REQ_DISCARD) && nr_sectors > queue_max_hw_sectors(q))) { printk(KERN_ERR "bio too big device %s (%u > %u)\n", bdevname(bio->bi_bdev, b), bio_sectors(bio), queue_max_hw_sectors(q)); goto end_io; } if (unlikely(test_bit(QUEUE_FLAG_DEAD, &q->queue_flags))) goto end_io; if (should_fail_request(bio)) goto end_io; /* * 如果此设备有分区,则将分区 p 的块 n 重新映射为磁盘的块 n+start(p)。 */ blk_partition_remap(bio); if (bio_integrity_enabled(bio) && bio_integrity_prep(bio)) goto end_io; if (old_sector != -1) trace_block_bio_remap(q, bio, old_dev, old_sector); old_sector = bio->bi_sector; old_dev = bio->bi_bdev->bd_dev; if (bio_check_eod(bio, nr_sectors)) goto end_io; /* * 提前过滤刷新的 bio,以便基于 make_request 的驱动程序不必担心它们。 */ if ((bio->bi_rw & (REQ_FLUSH | REQ_FUA)) && !q->flush_flags) { bio->bi_rw &= ~(REQ_FLUSH | REQ_FUA); if (!nr_sectors) { err = 0; goto end_io; } } if ((bio->bi_rw & REQ_DISCARD) && (!blk_queue_discard(q) || ((bio->bi_rw & REQ_SECURE) && !blk_queue_secdiscard(q)))) { err = -EOPNOTSUPP; goto end_io; } blk_throtl_bio(q, &bio); /* * 如果 bio = NULL,则表示 bio 已被限制,稍后将被提交。 */ if (!bio) break; trace_block_bio_queue(q, bio); ret = q->make_request_fn(q, bio); } while (ret); return; end_io: bio_endio(bio, err); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
(1)
request_queue请求队列结构体ret = q->make_request_fn(q, bio);该句代码是将新请求加入队列的方法
这就是请求队列的结构体,他的任务很艰巨,bio请求就加在请求队列上。每个块设备都有一个请求队列,所以我们在编写请求队列时,会初始化这样一个结构体。struct request_queue { //.... request_fn_proc *request_fn; make_request_fn *make_request_fn; prep_rq_fn *prep_rq_fn; unprep_rq_fn *unprep_rq_fn; merge_bvec_fn *merge_bvec_fn; softirq_done_fn *softirq_done_fn; rq_timed_out_fn *rq_timed_out_fn; dma_drain_needed_fn *dma_drain_needed; lld_busy_fn *lld_busy_fn; //...... };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
(2)
blk_init_allocated_queue_node结构体该句代码将
q->make_request_fn赋值为blk_queue_bio()函数struct request_queue * blk_init_allocated_queue_node(struct request_queue *q, request_fn_proc *rfn, spinlock_t *lock, int node_id) { if (!q) return NULL; q->node = node_id; if (blk_init_free_list(q)) return NULL; q->request_fn = rfn; q->prep_rq_fn = NULL; q->unprep_rq_fn = NULL; q->queue_flags = QUEUE_FLAG_DEFAULT; /* Override internal queue lock with supplied lock pointer */ if (lock) q->queue_lock = lock; /* * This also sets hw/phys segments, boundary and size */ blk_queue_make_request(q, __make_request); q->sg_reserved_size = INT_MAX; /* * all done */ if (!elevator_init(q, NULL)) { blk_queue_congestion_threshold(q); return q; } return NULL; } EXPORT_SYMBOL(blk_init_allocated_queue_node);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
十二、
__make_request函数在Linux通用块设备层介绍向通用块设备发送请求,
generic_make_request触发请求队列的make_request_fn方法来发送一个请求到I/O调度器。对于块设备,该方法由__make_request实现进入IO调度层,就应该会对前面的bio请求进行优先级判断,所以需要请求队列。这和前面的蓄势泄洪牵上了关系
/* * __make_request - 处理块设备的I/O请求 * @q: 块设备的请求队列 * @bio: 描述I/O操作的&struct bio * * __make_request() 是块层次的核心函数,负责处理块设备的I/O请求。 * 该函数接收块设备的请求队列 @q 和描述I/O的 &struct bio @bio。 * * @sync 表示I/O操作是否为同步操作。 * 在处理请求之前,函数检查是否需要将页面反弹到低内存。 * 如果是flush操作,函数加锁并设置 @where 为 ELEVATOR_INSERT_FLUSH,然后跳转到标签 get_rq。 * 接着,检查是否可以与已插入列表合并,如果可以则直接返回。 * * 如果需要合并,则在加锁后调用 elv_merge() 进行合并。 * 如果是后向合并(ELEVATOR_BACK_MERGE),处理后向合并,然后检查是否需要执行进一步的后向合并。 * 如果是前向合并(ELEVATOR_FRONT_MERGE),处理前向合并,然后检查是否需要执行进一步的前向合并。 * 根据是否合并成功,调用相应的 elv_merged_request() 函数。 * * 在标签 get_rq 处,再次检查同步标志并设置相应的 @rw_flags。 * 获取一个空闲请求,可能会睡眠但不会失败。函数返回时队列被解锁。 * * 在释放锁并可能在此处睡眠后,我们的请求可能现在是可合并的,尽管之前它已被证明不可合并。 * 为了提高效率,我们不会担心这种情况。这种情况不会经常发生,而且电梯算法能够处理它。 * * 如果设置了 QUEUE_FLAG_SAME_COMP 标志,或者 bio 标记为 BIO_CPU_AFFINE,则设置请求的 CPU。 * 如果有插件,则根据插件的状态将请求添加到插件列表尾部,并触发插件追踪。 * 如果没有插件,则重新加锁并调用 add_acct_request(),然后运行队列。 * 最后释放锁。 * * 返回值: * 0 表示成功处理 I/O 请求。 */ static int __make_request(struct request_queue *q, struct bio *bio) { const bool sync = !!(bio->bi_rw & REQ_SYNC); // 检查同步标志 struct blk_plug *plug; int el_ret, rw_flags, where = ELEVATOR_INSERT_SORT; // I/O请求插入位置 struct request *req; blk_queue_bounce(q, &bio); // 检查是否需要反弹页面到低内存 if (bio->bi_rw & (REQ_FLUSH | REQ_FUA)) { // 处理flush操作 spin_lock_irq(q->queue_lock); where = ELEVATOR_INSERT_FLUSH; goto get_rq; } if (attempt_plug_merge(current, q, bio)) // 尝试合并插入列表 goto out; spin_lock_irq(q->queue_lock); el_ret = elv_merge(q, &req, bio); // 进行电梯合并 if (el_ret == ELEVATOR_BACK_MERGE) { // 处理后向合并 BUG_ON(req->cmd_flags & REQ_ON_PLUG); if (bio_attempt_back_merge(q, req, bio)) { if (!attempt_back_merge(q, req)) elv_merged_request(q, req, el_ret); goto out_unlock; } } else if (el_ret == ELEVATOR_FRONT_MERGE) { // 处理前向合并 BUG_ON(req->cmd_flags & REQ_ON_PLUG); if (bio_attempt_front_merge(q, req, bio)) { if (!attempt_front_merge(q, req)) elv_merged_request(q, req, el_ret); goto out_unlock; } } get_rq: rw_flags = bio_data_dir(bio); // 获取I/O方向标志 if (sync) rw_flags |= REQ_SYNC; req = get_request_wait(q, rw_flags, bio); // 获取空闲请求 init_request_from_bio(req, bio); // 根据bio初始化请求 if (test_bit(QUEUE_FLAG_SAME_COMP, &q->queue_flags) || bio_flagged(bio, BIO_CPU_AFFINE)) { req->cpu = blk_cpu_to_group(get_cpu()); put_cpu(); } plug = current->plug; if (plug) { if (list_empty(&plug->list)) trace_block_plug(q); else if (!plug->should_sort) { struct request *__rq; __rq = list_entry_rq(plug->list.prev); if (__rq->q != q) plug->should_sort = 1; } req->cmd_flags |= REQ_ON_PLUG; list_add_tail(&req->queuelist, &plug->list); drive_stat_acct(req, 1); } else { spin_lock_irq(q->queue_lock); add_acct_request(q, req, where); __blk_run_queue(q); out_unlock: spin_unlock_irq(q->queue_lock); } out: return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
十三、
add_acct_requeststatic void add_acct_request(struct request_queue *q, struct request *rq, int where) { drive_stat_acct(rq, 1); __elv_add_request(q, rq, where); }- 1
- 2
- 3
- 4
- 5
- 6
(1)
__elv_add_request函数该函数的功能是将bio插入到一个新的请求中
elv_drain_elevator循环调用elevator_dispatch_fn__blk_run_queue运行设备的队列,执行块设备驱动的请求队列处理例程blk_insert_flush()插入新的FLUSH/FUA请求。void __elv_add_request(struct request_queue *q, struct request *rq, int where) { trace_block_rq_insert(q, rq); rq->q = q; BUG_ON(rq->cmd_flags & REQ_ON_PLUG); if (rq->cmd_flags & REQ_SOFTBARRIER) { /* barriers are scheduling boundary, update end_sector */ if (rq->cmd_type == REQ_TYPE_FS || (rq->cmd_flags & REQ_DISCARD)) { q->end_sector = rq_end_sector(rq); q->boundary_rq = rq; } } else if (!(rq->cmd_flags & REQ_ELVPRIV) && (where == ELEVATOR_INSERT_SORT || where == ELEVATOR_INSERT_SORT_MERGE)) where = ELEVATOR_INSERT_BACK; switch (where) { case ELEVATOR_INSERT_REQUEUE: case ELEVATOR_INSERT_FRONT: rq->cmd_flags |= REQ_SOFTBARRIER; list_add(&rq->queuelist, &q->queue_head); break; case ELEVATOR_INSERT_BACK: rq->cmd_flags |= REQ_SOFTBARRIER; elv_drain_elevator(q); list_add_tail(&rq->queuelist, &q->queue_head); /* * We kick the queue here for the following reasons. * - The elevator might have returned NULL previously * to delay requests and returned them now. As the * queue wasn't empty before this request, ll_rw_blk * won't run the queue on return, resulting in hang. * - Usually, back inserted requests won't be merged * with anything. There's no point in delaying queue * processing. */ __blk_run_queue(q); break; case ELEVATOR_INSERT_SORT_MERGE: /* * If we succeed in merging this request with one in the * queue already, we are done - rq has now been freed, * so no need to do anything further. */ if (elv_attempt_insert_merge(q, rq)) break; case ELEVATOR_INSERT_SORT: BUG_ON(rq->cmd_type != REQ_TYPE_FS && !(rq->cmd_flags & REQ_DISCARD)); rq->cmd_flags |= REQ_SORTED; q->nr_sorted++; if (rq_mergeable(rq)) { elv_rqhash_add(q, rq); if (!q->last_merge) q->last_merge = rq; } /* * Some ioscheds (cfq) run q->request_fn directly, so * rq cannot be accessed after calling * elevator_add_req_fn. */ q->elevator->ops->elevator_add_req_fn(q, rq); break; case ELEVATOR_INSERT_FLUSH: rq->cmd_flags |= REQ_SOFTBARRIER; blk_insert_flush(rq); break; default: printk(KERN_ERR "%s: bad insertion point %d\n", __func__, where); BUG(); } } EXPORT_SYMBOL(__elv_add_request)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
十四、
__blk_run_queue函数调用块设备驱动服务例程q->request_fn()来直接处理请求,进行数据读
void __blk_run_queue(struct request_queue *q) { if (unlikely(blk_queue_stopped(q))) return; q->request_fn(q); } EXPORT_SYMBOL(__blk_run_queue);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
十五、
request_fn请求队列处理例程通常是在空的请求队列上插入新的请求后启动。一旦处理例程被激活,块设备驱动程序就会处理请求队列中的请求,直到队列为空
对于SCSI设备,请求处理函数为
scsi_request_fn,即由该函数来负责向SAS/RAID控制器发送上层的I/O请求。下面就是块设备驱动程序的功能了
十六、块设备驱动
1. 设备驱动的引入
文件操作是对设备操作的组织和抽象,而设备操作则是对文件操作的最终实现
这句话很简洁很形象,越学习文件系统越发现文件系统是一种映射关系的集合,它并没有真正在磁盘上进行读写,它只是抽象出数据结构,将隐射关系隐藏起来的一个机制。
2. 标识设备
通过索引节点,主设备号,次设备号明确一个设备
3. 块设备
用户使用块设备一般都是通过文件系统来使用
(1)块设备的特点
字符设备是以字节流为传输单位的
块设备是以块为传输单位的
字符设备按照字节流顺序来访问的
块设备可以随机访问(2)常见的块设备
机械硬盘
- 磁头(head):磁头固定在可移动的机械臂上,用于读写数据
- 磁道(track):每个盘面都有n个同心圆组成,每个同心圆称之为一个磁道
- 柱面(cylinder):n个盘面的相同磁道(位置相同)共同组成一个柱面
- 扇区(sector):在磁盘中心向外画直线,可以将磁道划分为若干弧段,每个磁道的一个弧段称之为一个扇区
4. 相关数据结构
(1)
block_device结构体该结构体是用来管理块设备的
struct block_device { dev_t bd_dev; /* 设备号,不是 kdev_t 类型,而是一个搜索键 */ int bd_openers; /* 打开该设备的计数器 */ struct inode * bd_inode; /* 将被废弃的 inode 指针 */ struct super_block * bd_super; /* 指向超级块的指针 */ struct mutex bd_mutex; /* 打开/关闭的互斥锁 */ struct list_head bd_inodes; /* 与该设备关联的 inode 列表 */ void * bd_claiming; /* 认领该设备的指针 */ void * bd_holder; /* 拥有该设备的指针 */ int bd_holders; /* 拥有该设备的计数器 */ bool bd_write_holder; /* 是否为写保持者 */ #ifdef CONFIG_SYSFS struct list_head bd_holder_disks; /* 与该设备相关的磁盘的列表 */ #endif struct block_device * bd_contains; /* 包含的块设备指针 */ unsigned bd_block_size; /* 块大小 */ struct hd_struct * bd_part; /* 指向分区的指针 */ unsigned bd_part_count; /* 该设备上分区被打开的次数 */ int bd_invalidated; /* 设备是否无效的标志 */ struct gendisk * bd_disk; /* 通用块设备的指针 */ struct list_head bd_list; /* 与其他块设备连接的链表节点 */ /* * 私有数据。必须使用 bd_claim 函数声明拥有该块设备的权利。 * 注意:bd_claim 允许所有者多次声明同一设备,所有者必须小心不要破坏 bd_private 的情况。 */ unsigned long bd_private; /* 冻结进程的计数器 */ int bd_fsfreeze_count; /* 用于冻结的互斥锁 */ struct mutex bd_fsfreeze_mutex; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
(2)
gendisk结构体这个结构体是对硬盘的抽象,有点像inode,而
block_device有点像filestruct gendisk { /* major、first_minor 和 minors 仅为输入参数,不要直接使用。 * 使用 disk_devt() 和 disk_max_parts()。 */ int major; /* 驱动程序的主设备号 */ int first_minor; int minors; /* 最大次设备号,对于不能分区的磁盘,minors=1 */ char disk_name[DISK_NAME_LEN]; /* 主驱动程序的名称 */ char *(*devnode)(struct gendisk *gd, mode_t *mode); unsigned int events; /* 支持的事件 */ unsigned int async_events; /* 异步事件,是所有事件的一个子集 */ /* 指向通过 partno 索引的分区指针数组。 * 受匹配的块设备锁保护,但是 stat 和其他非关键访问使用 RCU。 * 总是通过辅助函数进行访问。 */ struct disk_part_tbl __rcu *part_tbl; struct hd_struct part0; /* 分区0的 hd_struct 结构 */ const struct block_device_operations *fops; /* 块设备操作函数指针 */ struct request_queue *queue; /* 请求队列指针 */ void *private_data; /* 私有数据指针 */ int flags; /* 标志位 */ struct device *driverfs_dev; /* FIXME: 待移除的成员 */ struct kobject *slave_dir; /* 从设备的 kobject 目录 */ struct timer_rand_state *random; /* 随机数生成器状态 */ atomic_t sync_io; /* RAID 同步 I/O 计数器 */ struct disk_events *ev; /* 块设备事件指针 */ #ifdef CONFIG_BLK_DEV_INTEGRITY struct blk_integrity *integrity; /* 数据完整性校验指针 */ #endif int node_id; /* 节点 ID */ };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
(3)
block_device_operations结构体块设备操作结构体,对具体的
block_device进行操作struct block_device_operations { int (*open) (struct block_device *, fmode_t); int (*release) (struct gendisk *, fmode_t); int (*ioctl) (struct block_device *, fmode_t, unsigned, unsigned long); int (*compat_ioctl) (struct block_device *, fmode_t, unsigned, unsigned long); int (*direct_access) (struct block_device *, sector_t, void **, unsigned long *); unsigned int (*check_events) (struct gendisk *disk, unsigned int clearing); /* ->media_changed() 已弃用,请使用 ->check_events() 代替 */ int (*media_changed) (struct gendisk *); void (*unlock_native_capacity) (struct gendisk *); int (*revalidate_disk) (struct gendisk *); int (*getgeo)(struct block_device *, struct hd_geometry *); /* 此回调在持有 swap_lock 和有时持有页表锁的情况下进行 */ void (*swap_slot_free_notify) (struct block_device *, unsigned long); struct module *owner; /* 指向拥有这组操作的内核模块的指针 */ };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
5. 代码实现
自我猜测驱动程序的编写是从请求队列中获取bio请求,然后和硬盘的管理,操作结构体相联系起来,最终达到驱动设备的目的
BASEINCLUDE ?= /lib/modules/$(shell uname -r)/build oops-objs := ramdisk-driver.o KBUILD_CFLAGS +=-g -O0 obj-m := ramdisk_driver.o all : $(MAKE) -C $(BASEINCLUDE) M=$(PWD) modules; install: $(MAKE) -C $(BASEINCLUDE) M=$(PWD) modules_install; clean: $(MAKE) -C $(BASEINCLUDE) M=$(PWD) clean; rm -f *.ko;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
#include#include #include #include #include #include #include #include #include #include #include #define MY_DEVICE_NAME "liudisk" static int mybdrv_ma_no,diskmb=10,disk_size; static char *ramdisk; static struct gendisk *my_gd; static unsigned short sector_size =512; static struct request_queue *my_request_queue; module_param_named(size,diskmb,int ,0); //在虚拟 RAM 磁盘上执行块状 I/O 操作 static int do_bvec(struct page *page, unsigned int len, unsigned int off, unsigned int op, sector_t sector) { void *mem; char *ptr; ptr=ramdisk+(sector<<SECTOR_SHIFT); mem =kmap_atomic(page); if(op_is_write(op)) { pr_info("正在写入扇区:%d,%u个扇区\n", (unsigned int)sector,(unsigned int)(len >> SECTOR_SHIFT)); flush_dcache_page(page); memcpy(ptr,mem+off,len); } else { pr_info("正在读取扇区:%d,%u个扇区\n", (unsigned int)sector,(unsigned int)(len >> SECTOR_SHIFT)); flush_dcache_page(page); memcpy(mem+off,ptr,len); } pr_info("major:%d , first_minor:%d , disk_name:%s\n",my_gd->major,my_gd->first_minor,my_gd->disk_name); kunmap_atomic(mem); return 0; } static blk_qc_t my_request(struct request_queue *q, struct bio *bio) { struct bio_vec bvec; sector_t sector; struct bvec_iter iter; sector =bio->bi_iter.bi_sector; //检查 BIO 的结束扇区是否超过了块设备的容量 if(bio_end_sector(bio)>get_capacity(bio->bi_disk)) goto io_error; bio_for_each_segment(bvec,bio,iter) { unsigned int len =bvec.bv_len; int err; err = do_bvec(bvec.bv_page,len,bvec.bv_offset, bio_op(bio),sector); if(err) goto io_error; sector +=len >> SECTOR_SHIFT; } bio_endio(bio); return BLK_QC_T_NONE; io_error: bio_io_error(bio); return BLK_QC_T_NONE; } static int my_getgeo(struct block_device *bdev, struct hd_geometry *geo) { long size; size=disk_size; size &=~0x3f; geo->cylinders=size>>6; geo->heads=2; geo->sectors=16; geo->start=4; printk("原来你也玩元。。。调用这个函数\n"); return 0; } static const struct block_device_operations mybdrv_fops = { .owner=THIS_MODULE, .getgeo =my_getgeo, }; static int __init my_init(void) { disk_size =diskmb*1024*1024; ramdisk=vmalloc(disk_size); if(!ramdisk) return -ENOMEM; my_request_queue =blk_alloc_queue(GFP_KERNEL); if(my_request_queue==0) { vfree(ramdisk); return -ENOMEM; } blk_queue_make_request(my_request_queue,my_request);//设置块设备请求队列使用的请求函数 blk_queue_max_hw_sectors(my_request_queue,UINT_MAX);//设置块设备请求队列中允许的最大硬件扇区数 blk_queue_physical_block_size(my_request_queue,sector_size);//获取物理块的大小 mybdrv_ma_no = register_blkdev(0,MY_DEVICE_NAME); if(mybdrv_ma_no<0) { pr_err("注册设备失败,返回值:%d\n", mybdrv_ma_no); blk_cleanup_queue(my_request_queue); return mybdrv_ma_no; } //分配gendisk结构体,也就是硬盘的抽象 my_gd =alloc_disk(16); if(!my_gd) { unregister_blkdev(mybdrv_ma_no,MY_DEVICE_NAME); blk_cleanup_queue(my_request_queue); vfree(ramdisk); return -ENOMEM; } my_gd->major=mybdrv_ma_no; my_gd->first_minor=0; my_gd->fops=&mybdrv_fops; strcpy(my_gd->disk_name,MY_DEVICE_NAME); my_gd->queue=my_request_queue; my_gd->flags=GENHD_FL_EXT_DEVT; set_capacity(my_gd,disk_size / sector_size); add_disk(my_gd); pr_info("设备注册成功!!主设备号:%d\n", mybdrv_ma_no); pr_info("硬盘:%d MB\n",diskmb); return 0; } static void __exit my_exit(void) { del_gendisk(my_gd); put_disk(my_gd); unregister_blkdev(mybdrv_ma_no,MY_DEVICE_NAME); pr_info("模块卸载成功!!主设备号:%d\n",mybdrv_ma_no); blk_cleanup_queue(my_request_queue); vfree(ramdisk); } module_init(my_init); module_exit(my_exit); MODULE_AUTHOR("Benshushu"); MODULE_LICENSE("GPL v2"); - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
运行结果

其中被圈起来的就是用户所插入的块设备
创建一个目录并将块设备挂载在其上的操作

你可以看到,在创建文件时底层块设备所进行的操作
下图是添加一些打印语句重新打印的信息


下面使用sudo fdisk /dev/liudisk发现调用了自己的函数,证明自己的函数已经被系统调用

心得体会
本次分析的是read系统调用,可以说很复杂,但也了解到很多,read读取的是缓冲区中的内容,用户想看到磁盘中的数据需要两次read,首先读取内核缓冲区,如果没有则内核缓冲区从磁盘中读。
bio其实是io请求抽象的数据结构,然后把这些请求加到请求队列中,这些请求肯定要划分优先级,所以需要算法进行调度。一旦放入请求队列后,后续的工作将有驱动程序来完成。
其中Page Cache就充当了内核和文件系统之间的缓冲区。当用户再次访问相同的文件数据时,可以直接从页缓存中获取,而无需再次访问磁盘。他其实就是内核缓冲区
文件操作是对设备操作的组织和抽象,而设备操作则是对文件操作的最终实现
这句话很简洁很形象,越学习文件系统越发现文件系统是一种映射关系的集合,它并没有真正在磁盘上进行读写,它只是抽象出数据结构,将隐射关系隐藏起来的一个机制。目前理解文件系统越来越像映射关系的集合,文件是inode,文件名是目录项inode,bio是io读写请求,文件系统就是这些映射关系组合在一起。
体现文件系统为效率而生的一点就是将块请求合并,达到提升IO效率的目的
一个文件的读取就是读取它的page,而page就是address_space在内存的映射,是页缓存和外部设备中文件系统的桥梁。重点就是找到这个映射关系
这一个简单的块设备驱动插入模块函数重点在怎么从请求队列中获取请求并进行IO操作
-
相关阅读:
Nodejs和Node-red的关系
CentOS中使用Docker部署带postgis的postgresql
cmd炫技小方法
Day30、列表、表格与表单
2407. 最长递增子序列 II 线段树
git上传对象文件错误解决方案
算法day24|理论基础77
中国移动物联网开放平台OneNET学习笔记(1)——设备接入(MQTT协议)OneNET Studio篇
微服务 Spring Cloud 5,一图说透Spring Cloud微服务架构
超详细配置Marktext的Picgo-Core图片上传到七牛云图床
- 原文地址:https://blog.csdn.net/weixin_45672701/article/details/134374950
