-
CS224W6.2——深度学习基础
在本文中,我们回顾了深度学习的概念和技术,这些概念和技术对理解图神经网络至关重要。从将机器学习表述为优化问题开始,介绍了目标函数、梯度下降、非线性和反向传播的概念。
1. 大纲

这篇我们主要讲第一部分深度学习的基础。
2. 优化问题
我们将机器学习问题、监督学习问题看作是优化问题:

我们需要学习这样一个映射函数:将输入 x x x映射为输出的预测标签 y y y。
将这样的函数学习表述为一个优化过程。

有两件重要的是:
- 通过优化参数 Θ \Theta Θ,最小化损失函数 L \mathcal{L} L。
- 损失函数用来测量真实值与预测值之间的差距。
2.1 举例损失函数
交叉熵损失函数:

讨论多分类问题:
比如5分类问题,表示5种颜色,我们用one-hot编码表示。
我们要在某种意义上对它进行建模,使用 f ( x ) f(x) f(x)这是将某个函数 g ( x ) g(x) g(x)经过 S o f t m a x ( ) Softmax() Softmax()函数,得到一个预测5分类的概率,这些概率之和为1。
现在要衡量这个预测的质量。
通过单点的交叉熵损失函数 C E ( y , f ( x ) ) CE(y,f(x)) CE(y,f(x))得到的值越小,就表示预测值与真实的one-hot值越接近。
然后将所有单点的损失相加就得到了总的损失: L = ∑ ( x , y ) ∈ T CE ( y , f ( x ) ) \mathcal{L}=\sum_{(x,y)\in\mathcal{T}}\operatorname{CE}(y,f(x)) L=∑(x,y)∈TCE(y,f(x)),这是所有训练样本的真实值与预测值之间的总差异。
而我们想要的就是找到一个合适的函数 f ( x ) f(x) f(x)去最小化真实值与预测值之间的总差异。
3. 如何优化目标函数?

经典的优化目标函数是通过梯度下降,所以梯度的概念很重要:
某个定点的梯度是一个方向,该方向是函数的最快增长速率。
现在,我们可以对损失函数进行“询问”,关于我的参数 Θ \Theta Θ,我应该朝着哪个方向?(梯度相反的方向)改变我的参数 Θ \Theta Θ使损失 L \mathcal{L} L减少最多。
4. 梯度下降

上面是最基础的梯度下降版本,重复更新模型参数,直至收敛。
最基础的梯度下降有一些问题,所以后续提出了随机梯度下降(SGD):

传统的梯度下降每一轮迭代都需要计算所有点的梯度,计算量太大,而SGD只计算一部分。
4.1 对于SGD的一些概念

- 首先是batch_size的概念,它是我们评估梯度数据的子集,(不是在整个训练数据集上评估梯度——GD,而是在训练集的一小部分——SGD),batch_size的大小是每一批次数据点的数量,通常我们喜欢更大的batch_size,但更大的batch_size会使优化变慢。
- 其次是iteration的概念,SGD的一个迭代(iteration),是SGD的一个步骤,我们在给定的batch_size的数据点上评估梯度。迭代次数是:数据集大小/batch_size。
- 最后是epoch的概念,它是对数据集的全面遍历。
这种小批量训练的思想是深度学习的核心。
5. 如何获得目标函数?
对于简单的模型:

5.1 反向传播

反向传播的概念:使用链式法则,来传播中间步骤的梯度,最终获得关于模型参数损失的梯度。
举例:


5.2 非线性变换
目前为止只使用了简单的两层神经网络,而 W 2 W 1 W_2W_1 W2W1可以表示为另一个矩阵,它依然可以表示为一层的线性变换。

这意味着,我们通过两侧的线性变换依然得到的是一个线性模型,没有获得更多的表达能力。
而如果我们引入非线性变换,实际上增加了模型的表示能力。这将我们引向多层感知机的概念(MLP)。
5.3 MLP
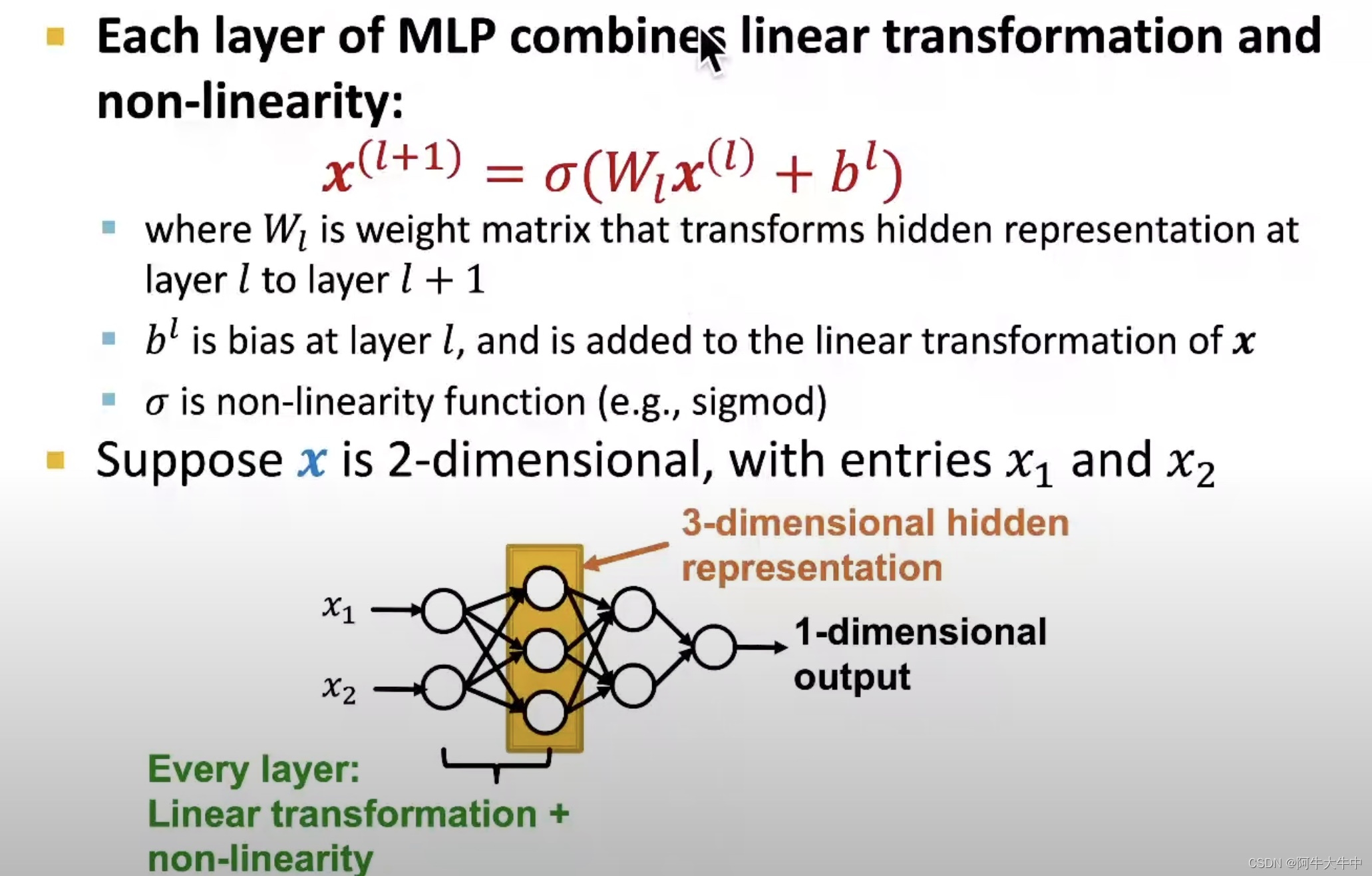
6. 总结

-
相关阅读:
Faust勒索病毒数据恢复|金蝶、用友、管家婆、OA、速达、ERP等软件数据库恢复
斐波那契数列树形结构js
java毕业设计病房管理系统mybatis+源码+调试部署+系统+数据库+lw
嵌入式linux系统中设备树基础知识
基于51单片机DHT11温湿度测量仪protues仿真设计(源码+仿真+讲解视频+设计报告)
nSoftware IPWorks IoT 2022 Java 22.0.8 Crack
安信可Ai-WB1系列AT指令连接MQTT阿里云物联网平台
含文档+PPT+源码等]精品基于Nodejs实现的医院患者服务系统[包运行成功]
Spring的bean装配和bean的自动装配
【云原生】Kubernetes(K8S)与数据库
- 原文地址:https://blog.csdn.net/weixin_46351593/article/details/134360671