-
亚马逊云AI应用科技创新下的Amazon SageMaker使用教程
目录
Amazon SageMaker简介
亚马逊SageMaker是一种完全托管的机器学习服务。借助 SageMaker,数据科学家和开发人员可以快速、轻松地构建和训练机器学习模型,然后直接将模型部署到生产就绪托管环境中。它提供了一个集成的 Jupyter 编写 Notebook 实例,供您轻松访问数据源以便进行探索和分析,因此您无需管理服务器。此外,它还可以提供常见的机器学习算法,这些算法经过了优化,可以在分布式环境中高效处理非常大的数据。借助对bring-your-own-algorithms和框架的本地支持,SageMaker提供灵活的分布式训练选项,可根据您的特定工作流程进行调整。可以从 SageMaker Studio 或 SageMaker 控制台中单击几下鼠标按钮以启动模型,以将该模型部署到安全且可扩展的环境中。
Amazon SageMaker在控制台的使用
-
创建Amazon SageMaker
在亚马逊云科技首页,我们登录账号之后在搜索栏输入Amazon SageMaker之后,我们点击第一个服务进入Amazon SageMaker服务选在控制面板。

-
进入服务的控制面板之后我们选择我们的服务设备
我们这里选择笔记本实例,当然要是有其他需求的小伙伴可以自行选择其他,因为我们这里时笔记本所以我就选择的时笔记本实例。然后点击创建笔记本实例即可进行下一步。

-
进入笔记本实例设置里面需要填入一下信息:
-
-
笔记本实例名称
-
笔记本实例类型
-
Elastic Inference
-
平台标识符
-
生命周期配置
-
卷大小
-
最低IMDS版本等
-

-
设置好之后进入创建IAM角色控制面板,完成创建角色。
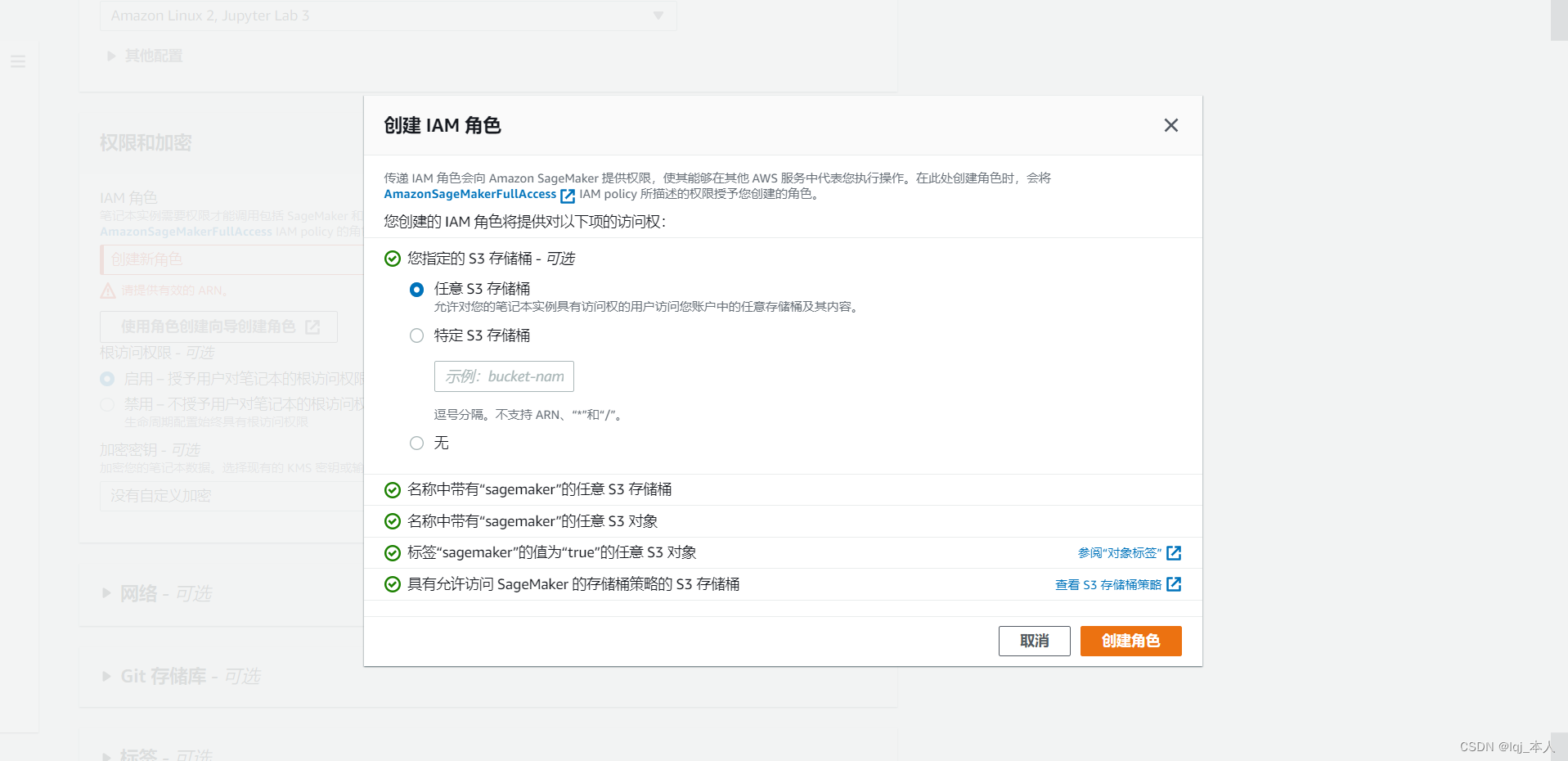
-
创建完成之后返回笔记本实例控制面板,完成笔记本实例的创建。
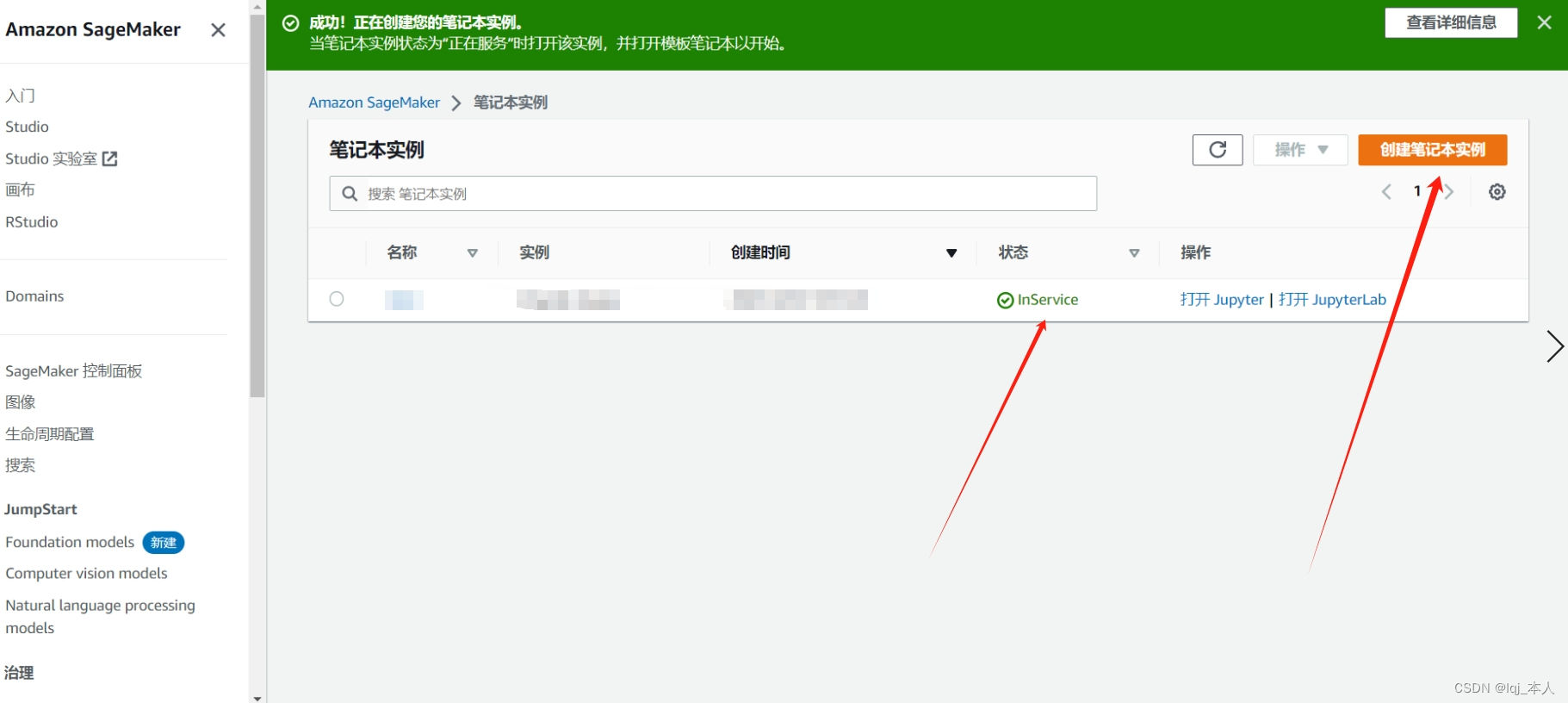
-
下载好代码(ipynb)文件之后,我们在笔记本实例页面点击“打开Jupyter”,然后上传代码。选择好文件后,点击蓝色的“Upload”按键,即可完成上传。然后我们打开刚刚上传的notebook,可以看到该文件就是一个完整的Stable Diffusion训练代码,这里我们的run kernel选择conda_pytorch_38或conda_pytorch_39,因为机器学习代码是用pytorch写的。

模型的各项参数
-
prompt (str or List[str]): 引导图像生成的文本提示或文本列表
-
height (int, optional, 默认为 V1模型可支持到512像素,V2模型可支持到768像素): 生成图像的高度(以像素为单位)
-
width (int, optional, 默认为 V1模型可支持到512像素,V2模型可支持到768像素): 生成图像的宽度(以像素为单位)
-
num_inference_steps (int, optional, defaults to 50): 降噪步数。更多的去噪步骤通常会以较慢的推理为代价获得更高质量的图像
-
guidance_scale (float, optional, defaults to 7.5): 较高的指导比例会导致图像与提示密切相关,但会牺牲图像质量。 如果指定,它必须是一个浮点数。 guidance_scale<=1 被忽略。
-
negative_prompt (str or List[str], optional): 不引导图像生成的文本或文本列表。不使用时忽略,必须与prompt类型一致(不应小于等于1.0)
-
num_images_per_prompt (int, optional, defaults to 1): 每个提示生成的图像数量
pytorch训练绘图部分代码
- # move Model to the GPU
- torch.cuda.empty_cache()
- pipe = pipe.to("cuda")
-
- # V1 Max-H:512,Max-W:512
- # V2 Max-H:768,Max-W:768
-
- print(datetime.datetime.now())
- # 提示词,一句话或者多句话
- prompts =[
- "Dream far away",
- "A singer who is singing",
- ]
- generated_images = pipe(
- prompt=prompts,
- height=512, # 生成图像的高度
- width=512, # 生成图像的宽度
- num_images_per_prompt=1 # 每个提示词生成多少个图像
- ).images # image here is in [PIL format](https://pillow.readthedocs.io/en/stable/)
-
- print(f"Prompts: {prompts}\n")
- print(datetime.datetime.now())
-
- for image in generated_images:
- display(image)
在这里,我们设置了两个提示词:
-
Dream far away:梦想远方
-
A singer who is singing:一个正在唱歌的歌手
生成结构如下:


-
-
相关阅读:
J2EE基础-自定义MVC(下)
2022杭电多校5(总结+补题)
react 跨域的两种方法
面向对象重写理解 求值策略 -共享对象调用 面向对象原则
软件测试面试题:简述bug的生命周期?
基础算法--理解递归
VR博物馆:让博物馆传播转化为品牌影响力
Yolov5 + 界面PyQt5 +.exe文件部署运行
Linux与Windows下编译工具
面试经验—底层软硬件研发工程师
- 原文地址:https://blog.csdn.net/lbcyllqj/article/details/134360213
