-
34 mysql limit 的实现
前言
这里来看一下 我们常见的 mysql 分页的 limit 的相的处理
这个问题的主要是来自于 之前有一个需要处理 大数据量的数据表的信息, 将数据转移到 es 中
然后就是用了最简单的 “select * from tz_test limit $pageOffset, $pageSize ” 来分页处理
但是由于 数据表的数据量较大, 越到后面的分页, 该页的查询 耗时越大
然后 后面调整了一下 实现思路, 将 mysql 的数据先放到 kafka, 然后基于 kafka 来进行遍历, 然后处理, 然后入库
tz_test 表结构如下
- CREATE TABLE `tz_test` (
- `id` int(11) unsigned NOT NULL AUTO_INCREMENT,
- `field1` varchar(128) DEFAULT NULL,
- PRIMARY KEY (`id`) USING BTREE
- ) ENGINE=InnoDB AUTO_INCREMENT=10000000 DEFAULT CHARSET=utf8
然后 往该数据表中写入 1000_0000 条记录信息
然后 我们来看一下 具体的 limit 的实现, 以及 为什么越到后面的页数 开销越大

遍历的记录
这里我们主要 几个 sql 来进行调试
然后 从以下的这些信息中, 可以看到 为什么越到后面的分页, 查询所需要的开销越大
- select * from tz_test limit 10;
- select * from tz_test limit 100, 10;
- select * from tz_test limit 1000, 10;
select * from tz_test limit 10;
查询结果如下, 可以看到查询的是 主键索引
然后 按照主键排序, 找的 0 – 10 条

遍历的记录如下, 按照主键索引, 依次找的 0 – 10 条

select * from tz_test limit 100, 10;
查询结果如下, 可以看到查询的是 主键索引
然后 按照主键排序, 找的 100 – 110 条
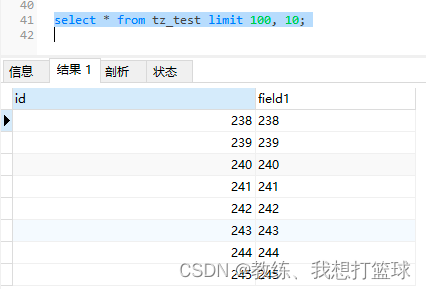
遍历的记录如下, 按照主键索引, 依次找的 100 – 110 条

select * from tz_test limit 1000, 10;
查询结果如下, 可以看到查询的是 主键索引
然后 按照主键排序, 找的 1000 – 1010 条

遍历的记录如下, 按照主键索引, 依次找的 1000 – 1010 条
limit 的实现
explain 以下如下, 可以发现 只要携带的有 limit 基本上都是走 全表扫描, 或者 索引的全部扫描
只是相比于 全表扫描, 索引记录较小, 记录遍历, 记录复制, 以及页面开销 较小
field1 无索引, 仅仅只有 主键索引的情况

field1 增加索引之后

limit $offset, $limit 的过滤
所以 limit 查询会遍历数据表中符合条件的前 ($offset + $limit) 条数据, 然后 之后跳出循环
如下地方是 基于 offset 的过滤
这里的 unit->offset_limit_cnt 就是 $offset 的值, 会先过滤掉 前面 $offset 条符合条件的数据

$limit 结束的限定在这里, 如果发送的数据量 到达期望的数据量, 跳出循环

limit 的优化?
假设 $offset 接近于 $count
然后 没有反方向查询的优化
假设执行 sql 如下 “select * from tz_test limit 9999852, 10;”, 可以看到 依然是根据 主键从小到大依次遍历

假设 $offset 大于 $count
假设执行 sql 如下 “select * from tz_test limit 19999852, 10;”
$offset 是一个 大于当前表记录数量的数字, 可以看出 依然进行了一次 全表扫描

limit $offset, $limit 转换 为条件查询
假设 “select * from tz_test” 走的是 主键索引
如下 sql 可以转换为 “select * from tz_test limit 9990000, 10;”
根据 id 的条件查询 “select * from tz_test where id > 9990138 limit 10;”
“9990138” 为上一个分页的最大的 id 的字段信息, 这里会现根据 主键索引定位到目标记录, 然后再往后 迭代 10 条记录
假设 “select * from tz_test” 走的是 field1索引
如下 sql 可以转换为 “select * from tz_test limit 9990000, 10;”
根据 field1 的条件查询 “select * from tz_test where field1 >= ‘9990138’ and id > 9990138 limit 10;”
“9990138” 为上一个分页的最大的 field1 的字段信息, 这里会现根据 field1索引定位到目标记录, 然后再往后 迭代 10 条记录
完
-
相关阅读:
软件型企业必备的“爆款资质”,千万不要错过!投标加分项!
React入门
ansible入门
1029 旧键盘
9_帖子详情
你不知道的JavaScript-----原生函数
海康机器人工业相机IP设置方式
(delphi11最新学习资料) Object Pascal 学习笔记---第10章第1节(通过引用设置属性)
Linux下的yum和vim
数据结构初步(九)- 栈和队列oj练习
- 原文地址:https://blog.csdn.net/u011039332/article/details/131627917