-
【pytorch源码分析--torch执行流程与编译原理】

背景
- 解读torch源码方便算子开发
- 方便后续做torch 模型性能开发
基本介绍
代码库
- https://github.com/pytorch/pytorch

模块介绍
-
aten: A Tensor Library的缩写。与Tensor相关的内容都放在这个目录下。如Tensor的定义、存储、Tensor间的操作(即算子/OP)等

可以看到在aten/src/Aten目录下,算子实现都在native/目录中。其中有CPU的算子实现,以及CUDA的算子实现(cuda/)等 -
torch: 即PyTorch的前端代码。我们用户在import torch时实际引入的是这个目录。
其中包括前端的Python文件,也包括高性能的c++底层实现(csrc/)。为实现Python和c++模块的打通,这里使用了pybind作为胶水。在python中使用torch._C.[name]实际调用的就是libtorch.so中的c++实现,而PyTorch在前端将其进一步封装为python函数供用户调用 -
c10、caffe2:移植caffe后端,c10指的是caffe tensor library,相当于caffe的aten。
PyTorch1.0完整移植了caffe2的源码,将两个项目进行了合并。引入caffe的原因是Pytorch本身拥有良好的前端,caffe2拥有良好的后端,二者在开发过程中拥有大量共享代码和库。简而言之,caffe2是一个c++代码,实现了各种设备后端逻辑 -
tools:用于代码自动生成(codegen),例如autograd根据配置文件实现反向求导OP的映射。
-
scripts:一些脚本,用于不同平台项目构建或其他功能性脚本
小结
- PyTorch源码中,最重要的两个目录是aten和torch目录
- aten(A Tensor Library)目录主要是和Tensor相关实现的目录,包括算子的具体实现
- torch目录是PyTorch前端及其底层实现,用户import torch即安装的这个目录
torch前端与后端
-
PyTorch 中,前端指的是 PyTorch 的 Python 接口,
-
后端指的是 PyTorch 的底层 C++ 引擎,它负责执行前端指定的计算
-
后端引擎也负责与底层平台(如 GPU 和 CPU)进行交互,并将计算转换为底层平台能够执行的指令
-


-
编译后的torch前端接口没有csrc后端接口,该部分c++内容(csrc目录)并没有被复制过来,而是以编译好的动态库文件(_C.cpython-*.so)
前后端交互流程
- 我们以torch.Tensor为例
import torch torch.Tensor- 1
- 2


结论是对应实现在 torch/csrc/autograd/python_variable.cpp中,而这个是通过编译后的so包实现_C调用,因为pyi是一个python存根文件,只有定义没有实现,实现都在python_variable.cpp中
- 看看对应c++的实现逻



小结
- PyTorch前端主要是python API,在设计上采用Pythonic式的编程风格,可以让用户像使用python一样使用PyTorch
- 而后端主要指C++ API,其对外提供的C++接口,也可以一定程度上实现PyTorch的大部分功能,而且更适用于嵌入式等场景
- 而前端主要是通过pybind调用的后端c++实现,具体是c++被编译成_C.[***].so动态库,然后python调用torch._C实现调用c++中的函数
动态图与静态图
一个主流的训练框架需要有两大特征:
-
实现类似numpy的张量计算,可以使用GPU进行加速;
-
实现带自动微分系统的深度神经网络
静态图
- 在TensorFlow1.x中,我们如果需要执行计算,需要建立一个session,并执行session.run()来执行
import tensorflow as tf a = tf.ones(5) b = tf.ones(5) c = a + b sess = tf.Session() print(sess.run(c))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 其整个过程其实是将计算过程构成了一张计算图,然后运行这个图的根节点。这样先构成图,再运行图的方式我们称为静态图或者图模式
动态图
- 在PyTorch中,我们可以在计算的任意步骤直接输出结果(当然最新的ensorflow已经支持动态模式)
- PyTorch每一条语句是同步执行的,即每一条语句都是一个(或多个)算子,被调用时实时执行。这种实时执行算子的方式我们称为动态图或算子模式
import tensorflow as tf a = tf.ones(5) b = tf.ones(5) c = a + b print(c) # tf.Tensor([2. 2. 2. 2. 2.], shape=(5,), dtype=float32)- 1
- 2
- 3
- 4
- 5
- 6
import torch a = torch.ones(5) b = torch.ones(5) c = a + b print(c) # tensor([2., 2., 2., 2., 2.])- 1
- 2
- 3
- 4
- 5
- 6
小结
- 动态图的优点显而易见,可以兼容Python式的编程风格,实时打印编程结果,用户友好性做到最佳;
- 静态图则在性能方面有一定优势,即在整个图执行前,可以将整张图进行编译优化,通过融合等策略改变图结构,从而实现较好的性能
- PyTorch原生支持动态图,但是也在静态图方面做了诸多尝试,例如 torchscript(jit.script、jit.trace)、TorchDynamo、torch.fx、LazyTensor
图原理

动态图
- 首先PyTorch的动态图是从Python源码下降,拆分成多个python算子调用,具体调用到tensor的OP。经过pybind转换到c++,并通过dispatch机制选择不同设备下的算子实现,最终实现调用的底层设备实现(如Nvidia cudnn、intel mkl等)
静态图
jit.script
- jit.script是在python源码角度分析function的源码,将python code转换为图(torchscript IR格式)。由于是直接从python源码转的,因此有许多python语法无法完备支持,存在转换失败的可能性
jit.trace
- jit.trace则是在c++层面获取算子,在算子调用时记录成图(torchscript IR格式)。由于需要下降到c++,因此需要输入一遍数据真正“执行”一遍。而获取的图具有确定性,即如果图存在分支,则只能被trace记录其中一个分支的计算路线
torch.fx
- python层面算子调用时记录的算子,输出是fx IR格式的图
LazyTensor
- 在算子调用时记录成的图,该调用会截获正常算子的运行,在用户指定同步时再整体运行已积累的图
TorchDynamo
- 将python源码转变成二进制后,通过分析二进制源码,获取分析的算子和图。最新的PyTorch1.14(2.0)中将其作为torch.compile()的主要路线
算子支持与dispatch机制
-
小结训练框架最重要的特点是:
- 支持类似numpy的张量计算,可以使用GPU加速;
- 支持带自动微分系统的深度神经网络;
- 原生支持动态图执行
针对以上问题,提出3个问题:
- PyTorch如何支持CPU、GPU等诸多设备的?
- PyTorch如何实现自动微分的?
- 动态图的原理是什么?
动态图Dispatch机制
import torch a = torch.randn(5, 5) b = torch.randn(5, 5) c = a.add(b) print(c.device) # cpu a = a.to("cuda") b = b.to("cuda") c = a.add(b) print(c.device) # cuda- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 上述示例中,a.add(b)这个算子,无论是cpu设备的tensor还是gpu设备的tensor,都可以得以支持
- 为什么同一个算子在不同设备上都能运行呢?
dispatch机制
- 文档:
https://pytorch.org/tutorials/advanced/dispatcher.html
原理


- 我们可以将Dispatch机制看做一个二维的表结构。其一个维度是各类设备(CPU、CUDA、XLA、ROCM等等),一个维度是各类算子(add、mul、sub等等)。
- PyTorch提供了一套定义(def)、实现(impl)机制,可以实现某算子在某设备(dispatch key)的绑定
aten/src/ATen/core/NamedRegistrations.cpp算子注册机制

例如m.impl()中就是对dispatch key为CPU时neg算子的实现绑定,其绑定了neg_cpu()这个函数
大多数情况我们只需要实现m.impl,并绑定一个实现函数即可-
除了m.def以及m.impl之外,还有m.fallback作为回退
在没有m.impl实现的情况下,默认回退的实现(例如fallback回cpu实现)。这样我们将不需要对cuda实现100%的算子实现,而是优先实现高优先级的算子,减少新设备情况下的开发量,而未被实现的算子则默认被fallback实现 -
实现一个定义算子add覆盖原始add算子(todo)
-
算子配置文件
native_functions.yaml
PyTorch中采用了算子配置文件aten/src/ATen/native/native_functions.yaml,配合codegen模块自动完成整个流程
也就是多有的自动注册流程会基于当前这个yaml配置文件自动生成算子注册方法与python bind实现

举例说明
以dot算子为例
- 配置

- 算子实现

上诉代码手动编译后,由codegen会自动生成def、impl的实现,也会自动生成pybind的实现 - build文件夹找到自动生成的代码
pytorch/build/aten/src/ATen/RegisterCPU.cpptorch/csrc/autograd/generated/python_variable_methods.cpp
反向传播
-
dispatch实际是前向算子
-
类似的也有反向算子,配置文件derivatives.yaml,其位于
tools/autograd/derivatives.yaml
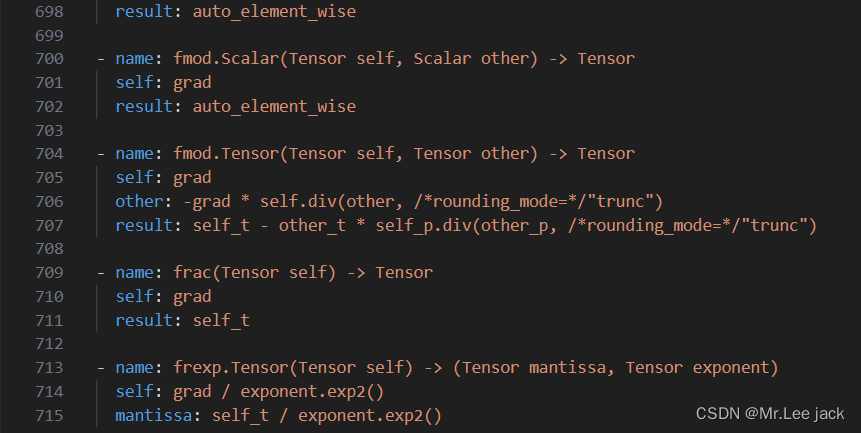
可以看到,每一个算子以“- name:”开头。
然后还包含一个result字段,这个字段其实就是这个算子的求导公式
前向算子会利用codegen自动生成注册部分的代码。同理,反向算子也可以根据算子微分注册表自动生成dispatch注册,然后被绑定到Python的函数中
有关梯度计算请参考
举例说明
- 配置

最后利用codegen根据算子微分注册表自动生成dispatch注册,然后被绑定到Python的函数中
动态图执行过程
- 前向过程
import torch a = torch.ones(5, 5) b = torch.ones(5, 5) c = a + b print(c)- 1
- 2
- 3
- 4
- 5
- 6
实际上在每执行一条python代码时,前向传播的算子都会被实时调用执行
在用户调用某算子(例如dot时),其实调用的是Tensor下的dot()函数实现。其具体实现在c++中,经过pybind和dispatch(选择设备)机制后定位带at::native::dot()函数。而后对于CPU来说,可以调用intel MKL库的mkldnn_matmul()实现- 反向过程
import torch a = torch.ones(5, 5, requires_grad=True) b = torch.ones(5, 5, requires_grad=True) c = (a + b).sum() c.backward() print(c) print(c.grad_fn) # tensor(50., grad_fn=) #- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
在执行loss.backward()时,实际调用执行的是各中间tensor的grad_fn,由于反向计算时会组成一个由grad_fn为节点,next_functions为边的反向图,因此如何高效执行这个图成为一个问题
为了解决这个问题,引入了根据设备数建立的线程池调度引擎总结

- 源码编译:https://github.com/pytorch/pytorch/tree/main#adjust-build-options-optional
# 拉取依赖 git clone --recursive https://github.com/pytorch/pytorch cd pytorch # if you are updating an existing checkout git submodule sync git submodule update --init --recursive # 编包 export CMAKE_PREFIX_PATH=${CONDA_PREFIX:-"$(dirname $(which conda))/../"} python setup.py build --cmake-only ccmake build # or cmake-gui build- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
-
相关阅读:
【golang学习之旅】Go语言常用转义字符
深入研究下Spring Boot Actuator 在kubernetes中探针的应用
数据分析与数据挖掘研究之一
C语言pow函数简单介绍
[报错解决](Error Creating bean with name ‘xxx‘)类问题解决思路
高并发下秒杀商品,你必须知道的9个细节
Leedcode 每日一题: 2760. 最长奇偶子数组
SpringBoot连接redis
编译原理 x - 练习题
【安全狐】Windows隐藏计划任务技术及排查方法
- 原文地址:https://blog.csdn.net/xzpdxz/article/details/134234579